
ホームページ >テクノロジー周辺機器 >AI >Llama 3 のトレーニング用に設計、Meta 49,000 H100 クラスターの詳細が発表
Llama 3 のトレーニング用に設計、Meta 49,000 H100 クラスターの詳細が発表

- PHPz転載
- 2024-03-15 11:30:111314ブラウズ
生成的な大規模モデルは、人工知能の分野に大きな変化を引き起こしました。汎用人工知能 (AGI) の実現に対する人々の期待は高まっていますが、大規模なモデルのトレーニングとデプロイに必要なコンピューティング能力も増大しています。髪の毛は巨大です。
たった今、Meta は 2 つの 24,000 GPU クラスター (合計 49,152 個の H100) の発売を発表しました。これは、Meta の人工知能の将来に対する大規模な投資を示しています。
これは、Meta の野心的なインフラストラクチャ計画の一部です。 Meta は、2024 年末までに 350,000 個の NVIDIA H100 GPU を含めてインフラストラクチャを拡張する予定で、これにより、約 600,000 個の H100 に相当するコンピューティング能力が得られます。 Meta は、将来のニーズに応えるためにインフラストラクチャを継続的に拡張することに取り組んでいます。
Meta 氏は次のように強調しました。「私たちはオープン コンピューティングとオープン ソース テクノロジーを断固としてサポートしています。私たちは Grand Teton、OpenRack、PyTorch に基づいてこれらのコンピューティング クラスターを構築しており、今後も業界全体を推進していきます」オープンイノベーション。これらのコンピューティングリソースクラスターを使用して、Llama 3 をトレーニングします。」
チューリング賞受賞者でメタの主任科学者であるヤン・ルカン氏も、ツイートしてこの点を強調しました。
メタは、さまざまな人工知能ワークロードに高スループットと高信頼性を提供するように設計された新しいクラスターのハードウェア、ネットワーク、ストレージ、設計、パフォーマンス、ソフトウェアに関する詳細を共有しました。セックス。
クラスターの概要
Meta の長期ビジョンは、オープンで責任ある汎用人工知能を構築し、広く利用できるようにすることです。皆さんから恩恵を受けています。
2022 年、Meta は 16,000 個の NVIDIA A100 GPU を搭載した AI Research スーパー クラスター (RSC) の詳細を初めて共有しました。 RSC は、Llama および Llama 2 の開発だけでなく、コンピューター ビジョン、NLP、音声認識、画像生成、エンコードなどの高度な人工知能モデルの開発において重要な役割を果たしました。
Meta の最新の AI クラスターは、前のフェーズで得た成功と教訓に基づいて構築されています。 Meta は、包括的な人工知能システムの構築への取り組みを強調し、研究者と開発者の経験と作業効率の向上に重点を置いています。
2 つの新しいクラスターで使用されている高性能ネットワーク ファブリックは、重要なストレージの決定と各クラスターの 24,576 個の NVIDIA Tensor Core H100 GPU と組み合わされて、2 つのクラスターでより大規模なストレージをサポートできるようになります。 RSC クラスターよりも複雑なモデル。
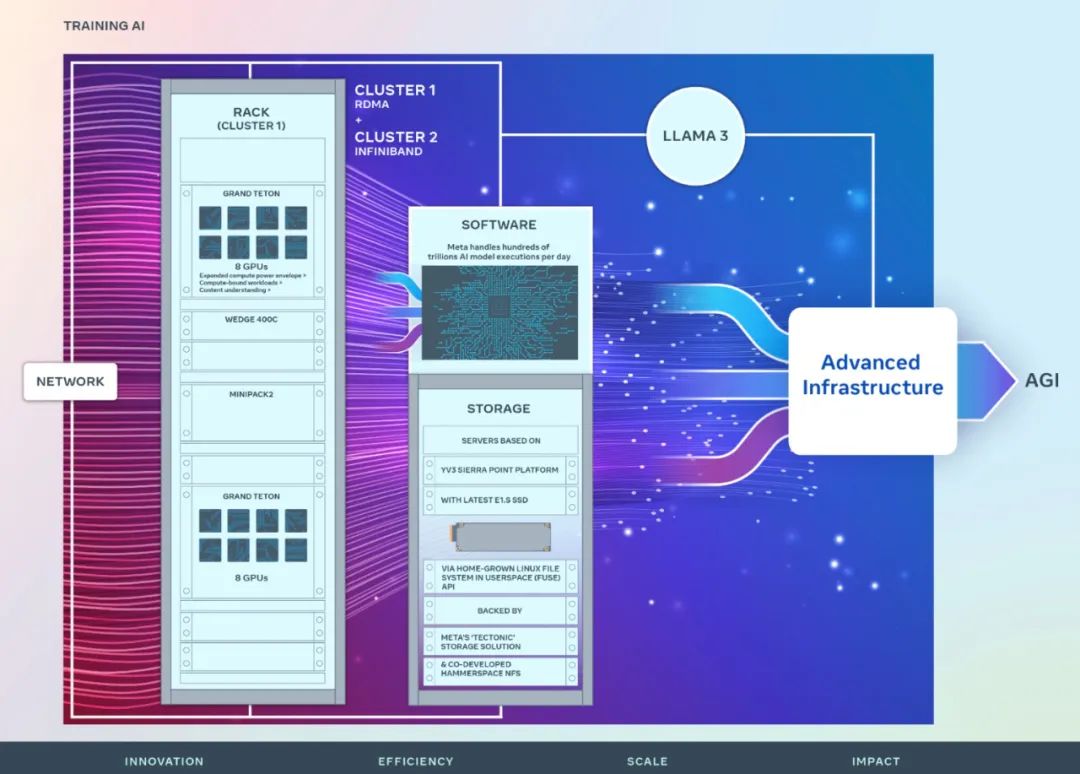
#ネットワーク
メタは毎日何百兆もの人工知能を処理しますモデルを実行します。 AI モデルを大規模に提供するには、高度で柔軟なインフラストラクチャが必要です。
Meta のデータセンターの効率的な運用を確保しながら、人工知能研究者のエンドツーエンドのエクスペリエンスを最適化するために、Meta は Arista 7800、Wedge400、および Minipack2 をベースとした RoCE ベースの RoCE を構築しました。 OCP ラック スイッチ プロトコル、イーサネット経由でリモート ダイレクト メモリ アクセス (RDMA) を実装するクラスター ネットワーク通信プロトコル。もう 1 つのクラスターは、NVIDIA Quantum2 InfiniBand ファブリックを使用します。どちらのソリューションも 400 Gbps エンドポイントを相互接続します。
これら 2 つの新しいクラスターは、大規模なトレーニングに対するさまざまなタイプの相互接続の適合性とスケーラビリティを評価するために使用でき、Meta が将来的に大規模なクラスターを設計および構築する方法を理解するのに役立ちます。ネットワーク、ソフトウェア、モデル アーキテクチャの慎重な共同設計により、Meta は、ネットワークのボトルネックを発生させることなく、大規模な GenAI ワークロードに対して RoCE および InfiniBand クラスターを活用することに成功しました。
コンピューティング
両方のクラスターは、Meta Open GPU ハードウェアによって社内設計された Grand Teton を使用して構築されましたプラットホーム。
Grand Teton は、複数世代の人工知能システムに基づいており、電源、制御、コンピューティング、およびファブリック インターフェイスを単一のシャーシに統合して、全体的なパフォーマンス、信号の整合性、および熱パフォーマンスを向上させます。シンプルな設計で迅速な拡張性と柔軟性を提供し、データセンター フリートに迅速に導入し、容易に保守および拡張できるようにします。
ストレージ
ストレージは人工知能のトレーニングにおいて重要な役割を果たしますが、最も話題にならない側面です。
GenAI トレーニングの取り組みは時間の経過とともによりマルチモーダルになり、大量の画像、ビデオ、テキスト データを消費するようになり、データ ストレージの需要が急速に増大しました。
Meta の新しいクラスターのストレージ展開は、Meta の機能を活用したユーザー空間のローカル Linux ファイル システム (FUSE) API を通じて、AI クラスターのデータとチェックポイントのニーズを満たします。 「Tectonic」分散ストレージ ソリューションがサポートを提供します。このソリューションにより、数千の GPU がチェックポイントを同期的に保存およびロードできるようになり、データのロードに必要な柔軟で高スループットのエクサバイト規模のストレージも提供されます。
Meta は、Hammerspace と協力して、ネットワーク ファイル システム (NFS) の並列展開を開発および実装しています。 Hammerspace を使用すると、エンジニアは数千の GPU を使用してジョブの対話型デバッグを実行できます。
パフォーマンス
メタ 大規模な人工知能クラスターを構築するための原則の 1 つは、パフォーマンスとパフォーマンスを同時に最大化することです。使いやすさ。これは、クラス最高の AI モデルを作成するための重要な原則です。
メタ 人工知能システムの限界に挑戦する場合、設計を拡張する能力をテストする最良の方法は、単純にシステムを構築し、それを最適化して実際にテストすることです (シミュレーターを使用しながら)役に立つので、これまでしかできません)。
この設計では、Meta はどこにボトルネックがあるかを理解するために、小規模クラスターと大規模クラスターのパフォーマンスを比較しました。以下は、多数の GPU が期待される最高のパフォーマンスが得られる通信サイズで相互に通信する場合の、AllGather の全体的なパフォーマンス (0 ~ 100 のスケールで正規化された帯域幅として表されます) を示しています。
大規模クラスターの初期状態のパフォーマンスは、最適化された小規模クラスターのパフォーマンスに比べて低く、一貫性がありません。この問題に対処するために、Meta は、ネットワーク トポロジを認識して内部ジョブ スケジューラを調整する方法にいくつかの変更を加えました。これにより、遅延の利点がもたらされ、ネットワークの上位層へのトラフィックが最小限に抑えられます。
Meta は、ネットワーク利用を最適化するために、NVIDIA Collective Communications Library (NCCL) の変更と連携してネットワーク ルーティング ポリシーも最適化します。これは、大規模なクラスターが小規模なクラスターと同じ期待されるパフォーマンスを達成するのに役立ちます。
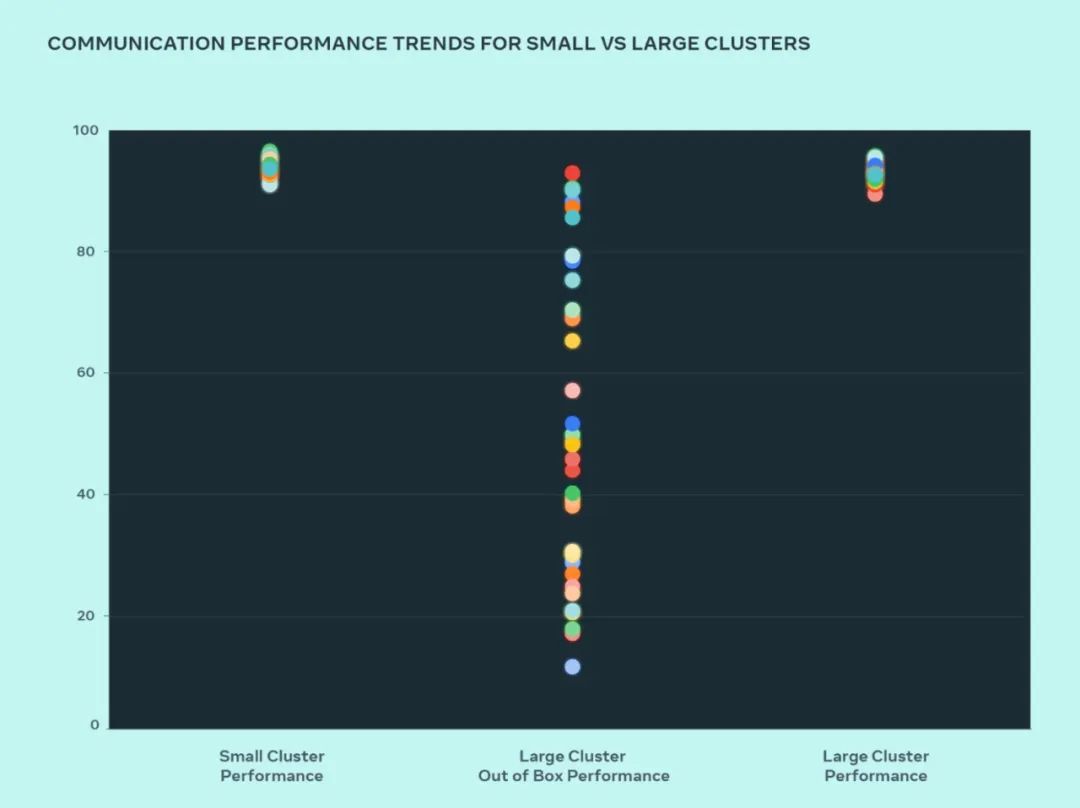
この図から、小規模クラスターのパフォーマンス (全体的な通信帯域幅と使用率) はそのままの状態で 90% に達しますが、最適化されていない大規模クラスターのパフォーマンス使用率は 10% から 90% と非常に低いことがわかります。不定。システム全体 (ソフトウェア、ネットワークなど) を最適化した後、大規模クラスターのパフォーマンスが理想的な 90% の範囲に戻ることがわかりました。
Meta は、内部インフラストラクチャに対するソフトウェアの変更に加えて、進化するインフラストラクチャに適応するためのトレーニング フレームワークやモデルを作成するチームと緊密に連携しています。たとえば、NVIDIA H100 GPU は、8 ビット浮動小数点 (FP8) などの新しいデータ型を使用したトレーニングの可能性を広げます。大規模なクラスターを最大限に活用するには、追加の並列化技術と新しいストレージ ソリューションへの投資が必要です。これにより、チェックポイントを数千レベルで高度に最適化し、数百ミリ秒で実行する機会が得られます。
Meta は、デバッグ可能性が大規模トレーニングの主な課題の 1 つであることも認識しています。トレーニング全体を停止させる誤った GPU を特定することは、大規模な場合には困難です。 Meta は、分散トレーニングの詳細を公開し、問題が発生したときにより迅速かつ簡単な方法で特定できるようにする、非同期デバッグや分散集合フライト レコーダーなどのツールを構築しています。
以上がLlama 3 のトレーニング用に設計、Meta 49,000 H100 クラスターの詳細が発表の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。