
ホームページ >テクノロジー周辺機器 >AI >SOTA をリアルタイムで追加すると、大幅に増加します。 FastOcc: より高速な推論と展開に適した Occ アルゴリズムが登場しました。
SOTA をリアルタイムで追加すると、大幅に増加します。 FastOcc: より高速な推論と展開に適した Occ アルゴリズムが登場しました。

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2024-03-14 23:50:021132ブラウズ
以前書いた&筆者の個人的な理解
自動運転システムにおいて、認識タスクは自動運転システム全体の重要な要素です。認識タスクの主な目的は、自動運転車が道路を走行する車両、路側の歩行者、運転中に遭遇する障害物、道路上の交通標識などの周囲の環境要素を理解して認識できるようにすることで、それによって下流のシステムを支援できるようにすることです。モジュール 正しく合理的な決定と行動を行います。自動運転機能を備えた車両には、通常、サラウンドビューカメラセンサー、ライダーセンサー、ミリ波レーダーセンサーなど、さまざまな種類の情報収集センサーが装備されており、自動運転車が正確に認識し、認識できるようにします。周囲の環境要素を理解することで、自動運転車が自動運転中に正しい判断を下せるようになります。
現在、純粋な画像ベースの視覚認識方法は、LIDAR ベースの認識アルゴリズムよりもハードウェア コストと展開コストが低いため、産業界および学界から広く注目されています。 BEV シーンで 3D オブジェクト認識タスクとセマンティック セグメンテーション タスクを実現するために、多くの優れた視覚認識アルゴリズムが登場しました。既存の 3D ターゲット認識アルゴリズムは検出パフォーマンスにおいて大幅な進歩を遂げていますが、実際のアプリケーションではまだいくつかの問題が徐々に明らかになってきています。
- オリジナルの 3D ターゲット認識アルゴリズムは十分なパフォーマンスを発揮できません。データセットに存在するテール問題、および現実世界に存在するが現在のトレーニング データセットではラベル付けされていない可能性のあるオブジェクト (道路上の大きな石、横転した車両など)
- オリジナル 一部の 3D ターゲット認識アルゴリズムは、通常、大まかな 3D 立体境界ボックスを直接出力するため、任意の形状のターゲット オブジェクトを正確に記述することができず、オブジェクトの形状や幾何学的構造の表現が十分に細密ではありません。この出力結果ボックスは、接続されたバスや長いフックを備えた建設車両など、ほとんどのオブジェクト シーンを満たすことができますが、現在の 3D 認識アルゴリズムでは正確かつ明確な説明を提供できません
前述の関連問題に基づく上記では、グリッド占有ネットワーク (Occupancy Network) センシング アルゴリズムが提案されました。基本的に、占有ネットワーク認識アルゴリズムは、3D 空間シーンに基づくセマンティック セグメンテーション タスクです。純粋な視覚に基づく占有ネットワーク知覚アルゴリズムは、現在の 3D 空間を 3D ボクセル グリッドに分割し、収集された周囲の画像を自動運転車に搭載された周囲のカメラ センサーを介してネットワーク モデルに送信し、アルゴリズム モデルの処理と予測を行った後、出力します。現在の空間内の各 3D ボクセル グリッドの占有ステータスと、考えられるターゲットの意味論的なカテゴリを分析することで、現在の 3D 空間シーンの包括的な認識を実現します。
近年、占有ネットワークに基づく知覚アルゴリズムは、その優れた知覚利点により研究者の間で広く注目されており、現在、このタイプのアルゴリズムの検出パフォーマンスを向上させるための優れた研究が数多く登場しています。これらの論文の主な内容は、より堅牢な特徴抽出方法、2D 特徴から 3D 特徴への座標変換方法、より複雑なネットワーク構造設計、モデル学習を支援する占有グラウンド トゥルース アノテーションをより正確に生成する方法などの提案です。しかし、既存の占有ネットワーク認識手法の多くは、モデルの予測と推論のプロセスに重大な計算オーバーヘッドを伴うため、これらのアルゴリズムが自動運転のリアルタイム認識の要件を満たすことが困難であり、車両への導入が困難になっています。
私たちは革新的な占有ネットワーク予測手法を提案しており、現在の主要な知覚アルゴリズムと比較して、FastOcc アルゴリズムはリアルタイムの推論速度と優れた検出パフォーマンスを備えています。次の図は、私たちが提案するアルゴリズムと他のアルゴリズムのパフォーマンスと推論速度の違いを視覚的に比較できます。
 FastOcc アルゴリズムと他の SOTA アルゴリズムの精度と推論速度の比較
FastOcc アルゴリズムと他の SOTA アルゴリズムの精度と推論速度の比較
論文リンク: https://arxiv.org/pdf/2403.02710.pdf
全体的なアーキテクチャとネットワーク モデルの詳細
占有ネットワーク認識アルゴリズムの推論速度を向上させるために、入力画像の解像度からバックボーン ネットワークを抽出し、特徴抽出を行いました。予測ヘッド構造の4つの部分について実験を行った結果、グリッド予測ヘッドにおける3次元コンボリューションまたはデコンボリューションには大きな時間空間があることが判明しました。 -消費型の最適化。これに基づいて、以下の図に示すように、FastOcc アルゴリズムのネットワーク構造を設計しました。
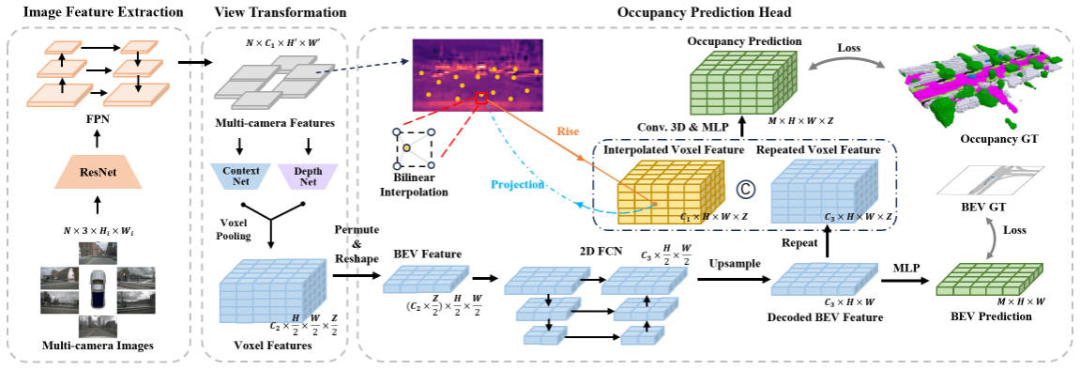 FastOcc アルゴリズムのネットワーク構造図
FastOcc アルゴリズムのネットワーク構造図
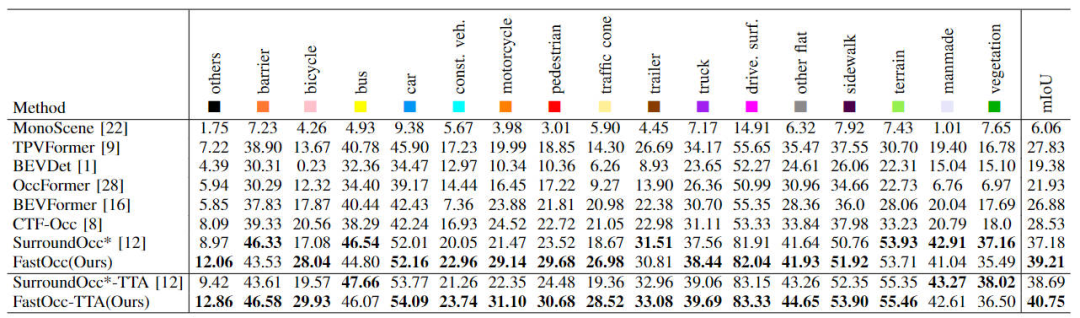
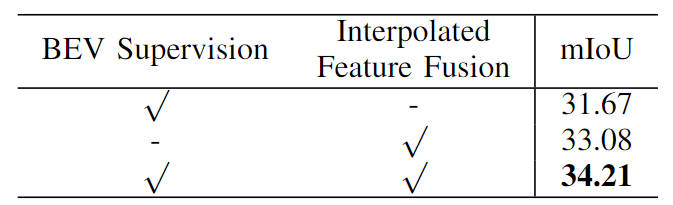
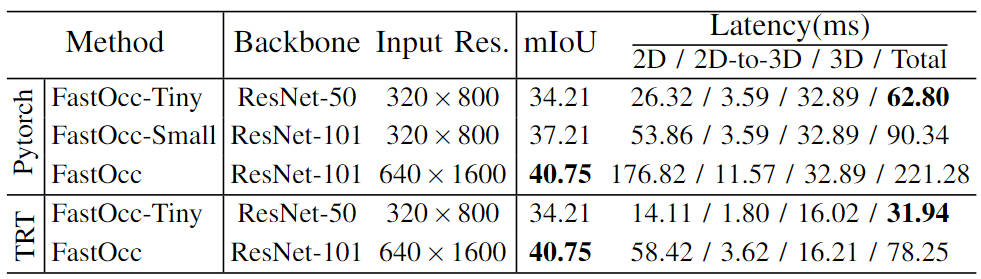
全体として、提案された FastOcc アルゴリズムには 3 つのサブモジュールが含まれています。 View Transformation は視点変換に使用され、Occupancy Prediction Head は知覚出力を実現するために使用されます。次に、これら 3 つの部分の詳細をそれぞれ紹介します。 提案された FastOcc アルゴリズムでは、ネットワーク入力は依然として収集されたサラウンド画像です。ここでは、ResNet ネットワーク構造を使用して、サラウンド画像の特徴抽出プロセスを完了します。同時に、FPN 特徴ピラミッド構造を使用して、バックボーン ネットワークによって出力されるマルチスケール画像特徴を集約します。以降の表現の便宜上、ここでは入力画像を 、特徴抽出後の特徴を と表すことにします。 ビュー変換モジュールの主な機能は、2D 画像特徴から 3D 空間特徴への変換プロセスを完了することです。アルゴリズム モデルのオーバーヘッドを減らすために、通常、3D 空間に変換された特徴は大まかに表現されますが、ここでは表現の便宜上、3D 空間に変換された特徴を としてマークします。これは、埋め込まれた特徴ベクトルの次元を表し、知覚空間の長さ、幅、高さ。現在の知覚アルゴリズムのうち、主流の透視変換処理には次の 2 つのカテゴリがあります。 LSS アルゴリズムの方が推論の速度と効率が優れていることを考慮して、この記事では視点変換モジュールとして LSS アルゴリズムを採用します。同時に、各ピクセル位置の離散的な深度が推定されることを考慮すると、その不確実性により、モデルの最終的な知覚パフォーマンスがある程度制限されます。したがって、私たちの具体的な実装では、より良い知覚結果を達成するために、深さ方向の監視に点群情報を利用します。 上に示したネットワーク構造図では、グリッド予測ヘッドには 3 つのサブパートも含まれています。特徴抽出、画像特徴補間サンプリング、特徴統合。次に、3部構成の方法の詳細を1つずつ紹介していきます。 取得された平面 BEV 特徴を内挿サンプリングによって取得された 3D ボクセル特徴と統合するために、最初にアップサンプリング操作を使用して BEV の空間次元を結合します。ボクセル特徴の空間的寸法を揃えて、Z 軸方向に沿って繰り返し操作を実行し、操作後に得られた特徴を として記録します。次に、画像特徴の内挿サンプリングによって得られた特徴を連結し、畳み込み層を通じて統合して、最終的なボクセル特徴を取得します。 上記の画像特徴補間サンプリングと特徴統合プロセスは、次の図で表すことができます。 画像特徴補間サンプリングと特徴統合プロセス さらに、BEV 特徴抽出モジュールによって出力される BEV 特徴に、後続の認識プロセスを完了するのに十分な特徴情報が含まれていることをさらに保証するために、追加の監視方法、つまりセマンティック セグメンテーションを使用する方法を採用しました。最初にセマンティック セグメンテーション タスクから開始し、占有率の真の値を使用してセマンティック セグメンテーションの真の値ラベルを構築し、監視プロセス全体を完了します。 まずはOcc3D-nuScenesで提案したFastOccアルゴリズムを示します。データセットと他の SOTA アルゴリズムの比較。各アルゴリズムの特定の指標は以下の表に示されています。 Occ3D-nuScenes データセットの各アルゴリズム指標の比較 表の結果から、私たちが提案した FastOcc アルゴリズムは、ほとんどのカテゴリで他のアルゴリズムよりも優れた利点を持っていることがわかり、同時に全体の mIoU インデックスも SOTA 効果を達成しています。 さらに、さまざまな透視変換方法とラスター予測ヘッドで使用されるデコード機能モジュールが知覚パフォーマンスと推論時間に及ぼす影響も比較しました (実験データはすべて入力画像に基づいています。解像度は640×1600、バックボーン ネットワークは ResNet-101 ネットワークを使用) 関連する実験結果は、以下の表に示すように比較されます。 さまざまなパースペクティブ変換とラスター予測ヘッド精度と推論時間消費量の比較 SurroundOcc アルゴリズムは、マルチスケール クロスビュー アテンション パースペクティブ変換方法と 3D 畳み込みを使用して 3D ボクセル特徴を抽出し、推論時間消費量が最も高くなります。オリジナルのクロスビューアテンションの視点変換方式を LSS 変換方式に置き換えた後、mIoU の精度が向上し、消費時間が短縮されました。これに基づいて、元の 3D 畳み込みを 3D FCN 構造に置き換えることにより、精度はさらに向上しますが、推論時間も大幅に増加します。最後に、検出パフォーマンスと推論時間消費の間のバランスを達成するために、サンプリング LSS と 2D FCN 構造の座標変換方法を選択しました。 さらに、BEV 特徴と画像特徴補間サンプリングに基づいて提案したセマンティック セグメンテーション監視タスクの有効性も検証しました。具体的なアブレーション実験結果を次の表に示します。 ##さまざまなモジュールのアブレーション実験の比較 さまざまなバックボーンでのモデル機能ネットワークと解像度の構成の比較 定性分析パート FastOcc アルゴリズムと SurroundOcc アルゴリズムの可視化結果の比較 この記事では、既存の占有ネットワーク アルゴリズム モデルの検出に時間がかかり、ネットワークへの展開が難しいという問題を解決するために、FastOcc アルゴリズム モデルを提案しました。車両。 3D ボクセルを処理するオリジナルの 3D 畳み込みモジュールを 2D 畳み込みで置き換えることにより、推論時間が大幅に短縮され、他のアルゴリズムと比較して SOTA 認識結果が得られます。 画像特徴抽出
ビュー変換
ラスター予測ヘッド (占有予測ヘッド)
BEV 特徴抽出
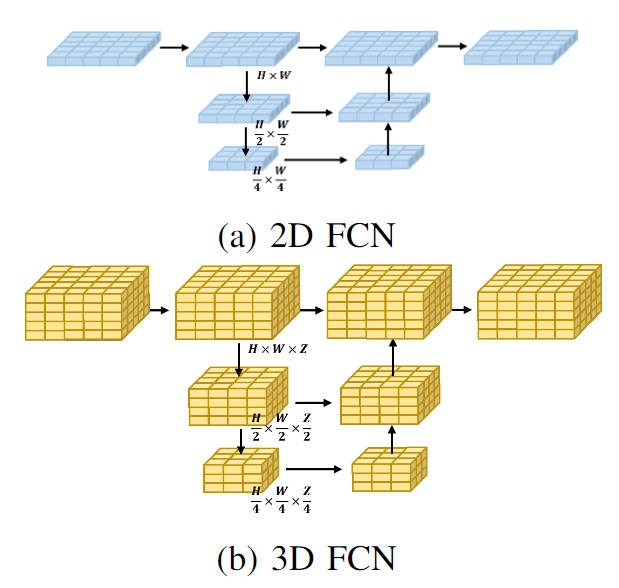
現在、ほとんどの占有ネットワーク アルゴリズムは、透視変換モジュールによって取得された 3D ボクセル特徴を処理します。処理形式は一般に 3 次元の完全畳み込みネットワークです。具体的には、3 次元完全畳み込みネットワークの任意の層について、入力 3 次元ボクセル フィーチャを畳み込むために必要な計算量は次のとおりです。 ここで、 および はそれぞれ入力フィーチャと出力フィーチャを表します。チャネルの数は、特徴マップ空間のサイズを表します。ボクセル特徴を 3D 空間で直接処理するのと比較して、軽量の 2D BEV 特徴畳み込みモジュールを使用します。具体的には、遠近変換モジュールの出力ボクセル特徴については、まず高さ情報と意味特徴を融合して2D BEV特徴を取得し、次に2D完全畳み込みネットワークを使用して特徴抽出を実行してBEV特徴を取得します。処理の計算量は次の形で表すことができます。3D 処理と 2D 処理の計算量を比較すると、元の 3D ボクセル特徴量が軽量 2D を使用することで置き換えられていることがわかります。 BEV 特徴畳み込みモジュール抽出により、モデルの計算量を大幅に削減できます。同時に、2 種類の処理プロセスの視覚的なフローチャートを以下に示します。
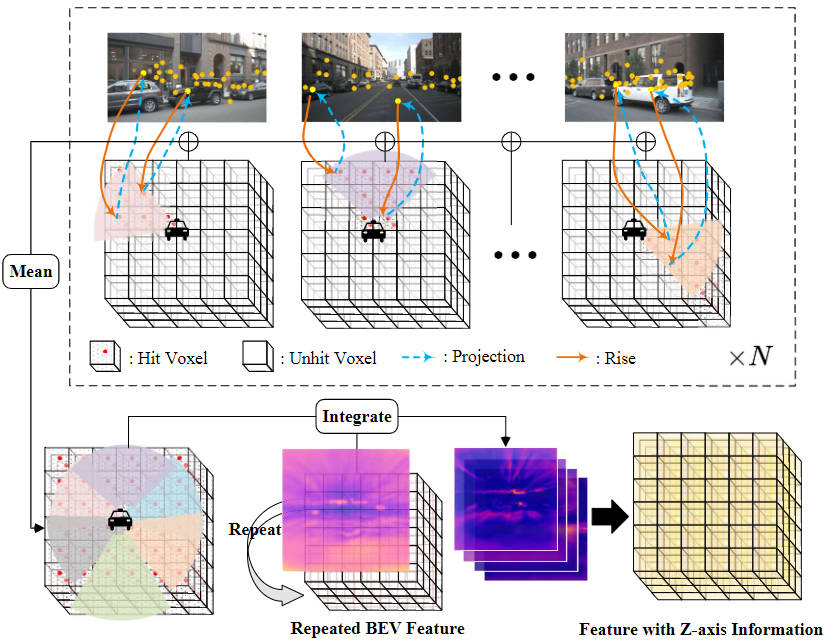
画像特徴補間サンプリング
ラスター予測ヘッドモジュールの計算量を削減するために、透視変換モジュールが出力する3Dボクセル特徴の高さを圧縮し、2D特徴抽出用のBEV畳み込みモジュール。しかし、欠落している Z 軸高さ特徴情報を増やし、モデル計算量を削減するという考えを堅持するために、画像特徴補間サンプリング方法を提案しました。 具体的には、まずセンシングしたい範囲に応じて対応する3次元ボクセル空間を設定し、 で表される自我座標系に割り当てます。次に、カメラの外部および内部座標変換行列を使用して、自我座標系の座標点を画像座標系に投影し、対応する位置で画像特徴を抽出するために使用されます。 それらのうち、 と はそれぞれカメラの固有座標変換行列と外部座標変換行列を表し、画像座標系に投影された自我座標系の空間点の位置を表します。対応する画像座標を取得した後、画像範囲を超える座標点や負の深度を持つ座標点を除外します。次に、双一次補間演算を使用して、投影された座標位置に従って対応する画像意味特徴を取得し、すべてのカメラ画像から収集された特徴を平均して、最終的な補間サンプリング結果を取得します。
特徴統合
実験結果と評価指標
定量分析パート

次の図は、提案した FastOcc アルゴリズム モデルと SurroundOcc アルゴリズム モデルの視覚的な結果の比較を示しています。提案された FastOcc アルゴリズム モデルが、より合理的な方法で周囲の環境要素を埋め、走行車両や樹木のより正確な認識を実現していることが明確にわかります。

結論
以上がSOTA をリアルタイムで追加すると、大幅に増加します。 FastOcc: より高速な推論と展開に適した Occ アルゴリズムが登場しました。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。