

 テクノロジー周辺機器AIヤン・シュイチェン/チェン・ミンミンの新作! Sora のコアコンポーネントである DiT トレーニングは 10 倍高速化され、Masked Diffusion Transformer V2 はオープンソースです
テクノロジー周辺機器AIヤン・シュイチェン/チェン・ミンミンの新作! Sora のコアコンポーネントである DiT トレーニングは 10 倍高速化され、Masked Diffusion Transformer V2 はオープンソースですヤン・シュイチェン/チェン・ミンミンの新作! Sora のコアコンポーネントである DiT トレーニングは 10 倍高速化され、Masked Diffusion Transformer V2 はオープンソースです

Sora の魅力的なコア テクノロジーの 1 つとして、DiT は拡散トランスフォーマーを利用して生成モデルを大規模に拡張し、優れた画像生成効果を実現します。
ただし、モデルのサイズが大きくなると、トレーニングのコストが急増します。
南開大学Sea AI LabのYan Shuicheng氏とCheng Mingming氏の研究チーム、およびKunlun Wanwei 2050 Research Instituteは、ICCV 2023カンファレンスでマスク拡散トランスと呼ばれる新しいモデルを提案しました。このモデルは、マスク モデリング技術を使用して、意味表現情報を学習することで拡散トランスフォーマーのトレーニングを高速化し、画像生成分野で SoTA 効果を実現します。このイノベーションは、画像生成モデルの開発に新たなブレークスルーをもたらし、研究者により効率的なトレーニング方法を提供します。研究チームは、さまざまな分野の専門知識とテクノロジーを組み合わせることで、トレーニング速度を向上させ、生成結果を向上させるソリューションを提案することに成功しました。彼らの研究は、人工知能分野の発展に重要な革新的なアイデアに貢献し、将来の研究と実践に有益なインスピレーションを提供しました
 写真
写真
論文アドレス: https://arxiv.org/abs/2303.14389
GitHub アドレス: https://github.com/sail-sg/MDT
##最近、Masked Diffusion Transformer V2 が再び SoTA を更新し、DiT と比較してトレーニング速度が 10 倍以上向上し、ImageNet ベンチマークで 1.58 の FID スコアを達成しました。 論文とコードの最新バージョンはオープンソースです。 背景 DiT に代表される拡散モデルは画像生成の分野で大きな成功を収めてきましたが、研究者らは、拡散モデルは多くの場合、画像内のオブジェクトの部分間の意味的関係を効率的に学習することは困難であり、この制限がトレーニング プロセスの収束効率の低下につながります。 図
図
 写真
写真
推論プロセス中、MDT は標準の拡散生成プロセスを維持します。 MDT の設計により、Difffusion Transformer は、マスク モデリング表現の学習によってもたらされる意味情報表現能力と、画像の詳細を生成する拡散モデルの能力の両方を得ることができます。
具体的には、MDT は VAE エンコーダーを通じて画像を潜在空間にマッピングし、それらを潜在空間で処理してコンピューティング コストを節約します。
トレーニング プロセス中、MDT はまずノイズが追加された画像トークンの一部をマスクし、残りのトークンを非対称拡散変換器に送信して、ノイズ除去後のすべての画像トークンを予測します。
#非対称拡散トランス アーキテクチャ##写真
として上の図に示されているように、非対称拡散トランスのアーキテクチャには、エンコーダ、サイド補間器 (補助補間器)、およびデコーダが含まれています。
図
トレーニング プロセス中、Encoder はマスクされていないトークンのみを処理します。推論では、マスク ステップがないため、すべてのトークンが処理されます。
したがって、デコーダーがトレーニングまたは推論フェーズ中に常にすべてのトークンを処理できるようにするために、研究者らは解決策を提案しました。トレーニング プロセス中に、以下で構成される DiT ブロックを使用するというものです。補助補間器 (上の図に示す) は、エンコーダーの出力からマスクされたトークンを補間および予測し、推論のオーバーヘッドを追加することなく推論段階でそれを削除します。
MDT のエンコーダとデコーダは、グローバルおよびローカル位置エンコード情報を標準 DiT ブロックに挿入して、マスク部分のトークンの予測を支援します。
#非対称拡散トランス V2##写真
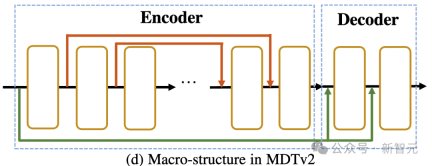 として上の図に示すように、MDTv2 は、マスク拡散プロセス用に設計されたより効率的なマクロ ネットワーク構造を導入することにより、拡散とマスク モデリングの学習プロセスをさらに最適化します。
として上の図に示すように、MDTv2 は、マスク拡散プロセス用に設計されたより効率的なマクロ ネットワーク構造を導入することにより、拡散とマスク モデリングの学習プロセスをさらに最適化します。
これには、エンコーダでの U-Net スタイルのロング ショートカットとデコーダでの高密度入力ショートカットの統合が含まれます。
このうち、dense input-shortcut は、マスクされたトークンにノイズを追加してデコーダーに送信し、マスクされたトークンに対応するノイズ情報を保持するため、拡散のトレーニングが容易になります。プロセス。 。
さらに、MDT は、より高速な Adan オプティマイザー、タイムステップ関連の損失重み、拡散モデルのマスクされたトレーニング プロセスをさらに加速する拡張マスク比など、より優れたトレーニング戦略も導入しました。 。
#実験結果ImageNet 256 ベンチマーク生成の品質比較 Image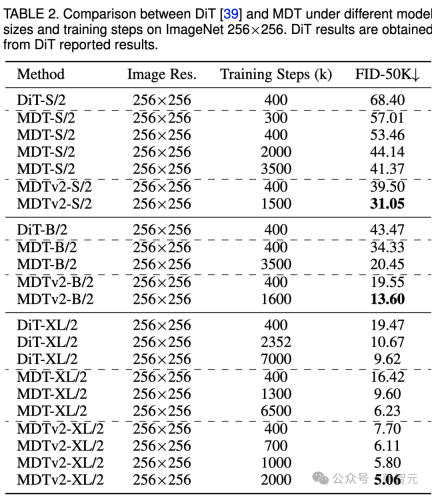 #上の表は、ImageNet 256 ベンチマークにおけるさまざまなモデル サイズでの MDT と DiT のパフォーマンスを比較しています。
#上の表は、ImageNet 256 ベンチマークにおけるさまざまなモデル サイズでの MDT と DiT のパフォーマンスを比較しています。
小規模モデルの場合、MDTv2-S/2 は、大幅に少ないトレーニング ステップで、DiT-S/2 よりも大幅に優れたパフォーマンスを実現します。たとえば、400k ステップの同じトレーニングでは、MDTv2 の FID インデックスは 39.50 で、これは DiT の FID インデックス 68.40 を大幅に上回っています。
さらに重要なのは、この結果は、400k トレーニング ステップでのより大きなモデル DiT-B/2 のパフォーマンスも上回っていることです (39.50 対 43.47)。
ImageNet 256 ベンチマーク CFG 生成の品質比較
 Image
Image
我々はまだ上の表は、分類子を使用しないガイダンスの下で、MDT と既存の方法の画像生成パフォーマンスを比較しています。
MDT は、FID スコア 1.79 で、以前の SOTA DiT や他の手法を上回ります。 MDTv2 はパフォーマンスをさらに向上させ、少ないトレーニング ステップで画像生成の SOTA FID スコアを新たな最低値の 1.58 に押し上げます。
DiT と同様に、トレーニングを継続しても、トレーニング中にモデルの FID スコアの飽和は観察されませんでした。
 #MDT が PaperWithCode のリーダーボードで SoTA を更新
#MDT が PaperWithCode のリーダーボードで SoTA を更新
 図
図
以上がヤン・シュイチェン/チェン・ミンミンの新作! Sora のコアコンポーネントである DiT トレーニングは 10 倍高速化され、Masked Diffusion Transformer V2 はオープンソースですの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 踊りましょう:私たちの人間のニューラルネットを微調整するための構造化された動きApr 27, 2025 am 11:09 AM
踊りましょう:私たちの人間のニューラルネットを微調整するための構造化された動きApr 27, 2025 am 11:09 AM科学者は、彼らの機能を理解するために、人間とより単純なニューラルネットワーク(C. elegansのものと同様)を広く研究してきました。 ただし、重要な疑問が生じます。新しいAIと一緒に効果的に作業するために独自のニューラルネットワークをどのように適応させるのか
 新しいGoogleリークは、Gemini AIのサブスクリプションの変更を明らかにしますApr 27, 2025 am 11:08 AM
新しいGoogleリークは、Gemini AIのサブスクリプションの変更を明らかにしますApr 27, 2025 am 11:08 AMGoogleのGemini Advanced:Horizonの新しいサブスクリプションティア 現在、Gemini Advancedにアクセスするには、1か月あたり19.99ドルのGoogle One AIプレミアムプランが必要です。 ただし、Android Authorityのレポートは、今後の変更を示唆しています。 最新のGoogle p
 データ分析の加速がAIの隠されたボトルネックをどのように解決しているかApr 27, 2025 am 11:07 AM
データ分析の加速がAIの隠されたボトルネックをどのように解決しているかApr 27, 2025 am 11:07 AM高度なAI機能を取り巻く誇大宣伝にもかかわらず、エンタープライズAIの展開内に大きな課題が潜んでいます:データ処理ボトルネック。 CEOがAIの進歩を祝う間、エンジニアはクエリの遅い時間、過負荷のパイプライン、
 MarkitDown MCPは、任意のドキュメントをマークダウンに変換できます!Apr 27, 2025 am 09:47 AM
MarkitDown MCPは、任意のドキュメントをマークダウンに変換できます!Apr 27, 2025 am 09:47 AMドキュメントの取り扱いは、AIプロジェクトでファイルを開くだけでなく、カオスを明確に変えることです。 PDF、PowerPoint、Wordなどのドキュメントは、あらゆる形状とサイズでワークフローをフラッシュします。構造化された取得
 建物のエージェントにGoogle ADKを使用する方法は? - 分析VidhyaApr 27, 2025 am 09:42 AM
建物のエージェントにGoogle ADKを使用する方法は? - 分析VidhyaApr 27, 2025 am 09:42 AMGoogleのエージェント開発キット(ADK)のパワーを活用して、実際の機能を備えたインテリジェントエージェントを作成します。このチュートリアルは、ADKを使用して会話エージェントを構築し、GeminiやGPTなどのさまざまな言語モデルをサポートすることをガイドします。 w
 効果的な問題解決のためにLLMを介したSLMの使用 - 分析VidhyaApr 27, 2025 am 09:27 AM
効果的な問題解決のためにLLMを介したSLMの使用 - 分析VidhyaApr 27, 2025 am 09:27 AMまとめ: Small Language Model(SLM)は、効率のために設計されています。それらは、リソース不足、リアルタイム、プライバシーに敏感な環境の大手言語モデル(LLM)よりも優れています。 特にドメインの特異性、制御可能性、解釈可能性が一般的な知識や創造性よりも重要である場合、フォーカスベースのタスクに最適です。 SLMはLLMSの代替品ではありませんが、精度、速度、費用対効果が重要な場合に理想的です。 テクノロジーは、より少ないリソースでより多くを達成するのに役立ちます。それは常にドライバーではなく、プロモーターでした。蒸気エンジンの時代からインターネットバブル時代まで、テクノロジーの力は、問題の解決に役立つ範囲にあります。人工知能(AI)および最近では生成AIも例外ではありません
 コンピュータービジョンタスクにGoogle Geminiモデルを使用する方法は? - 分析VidhyaApr 27, 2025 am 09:26 AM
コンピュータービジョンタスクにGoogle Geminiモデルを使用する方法は? - 分析VidhyaApr 27, 2025 am 09:26 AMコンピュータービジョンのためのGoogleGeminiの力を活用:包括的なガイド 大手AIチャットボットであるGoogle Geminiは、その機能を会話を超えて拡張して、強力なコンピュータービジョン機能を網羅しています。 このガイドの利用方法については、
 Gemini 2.0 Flash vs O4-Mini:GoogleはOpenaiよりもうまくやることができますか?Apr 27, 2025 am 09:20 AM
Gemini 2.0 Flash vs O4-Mini:GoogleはOpenaiよりもうまくやることができますか?Apr 27, 2025 am 09:20 AM2025年のAIランドスケープは、GoogleのGemini 2.0 FlashとOpenaiのO4-Miniの到着とともに感動的です。 数週間離れたこれらの最先端のモデルは、同等の高度な機能と印象的なベンチマークスコアを誇っています。この詳細な比較


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 中国語版
中国語版、とても使いやすい

メモ帳++7.3.1
使いやすく無料のコードエディター

MinGW - Minimalist GNU for Windows
このプロジェクトは osdn.net/projects/mingw に移行中です。引き続きそこでフォローしていただけます。 MinGW: GNU Compiler Collection (GCC) のネイティブ Windows ポートであり、ネイティブ Windows アプリケーションを構築するための自由に配布可能なインポート ライブラリとヘッダー ファイルであり、C99 機能をサポートする MSVC ランタイムの拡張機能が含まれています。すべての MinGW ソフトウェアは 64 ビット Windows プラットフォームで実行できます。

SAP NetWeaver Server Adapter for Eclipse
Eclipse を SAP NetWeaver アプリケーション サーバーと統合します。
ホットトピック
 7757
7757 15164414139952129325123429
15164414139952129325123429