このモデルは Sora と同様に DiT フレームワークを使用します。
誰もが知っているように、トップレベルの T2I モデルの開発には多くのリソースが必要となるため、個人の研究者がこれを行うことは基本的に不可能です。リソースが限られているため、手頃な価格であることも AIGC (人工知能コンテンツ生成) コミュニティのイノベーションにとって大きな障害となっています。同時に、時間が経つにつれて、AIGC コミュニティは継続的に更新される高品質のデータセットとより高度なアルゴリズムを取得できるようになります。 したがって、重要な質問は、これらの新しい要素を既存のモデルに効率的に統合し、限られたリソースでモデルをより強力にするにはどうすればよいかということです。 この問題を調査するために、ファーウェイのノアの方舟研究所などの研究機関の研究チームは、新しいトレーニング方法を提案しました。それは、弱から強へのトレーニング(弱から強へのトレーニング)です。 -強力なトレーニング)。 
論文タイトル: PixArt-Σ: 4K テキストから画像への生成のための拡散トランスフォーマーの弱から強へのトレーニング論文アドレス: https: //arxiv.org/pdf/2403.04692.pdfプロジェクト ページ: https://pixart-alpha.github.io/PixArt-sigma-project/ チームは、PixArt-α の事前トレーニングされた基本モデルを使用し、高度な要素を統合して継続的な改善を促進し、最終的にはより強力なモデル PixArt-Σ が完成しました。図 1 は、生成された結果の例をいくつか示しています。
# 具体的には、弱から強へのトレーニングを実現し、PixArt-Σを作成するために、チームは次のような改善策を採用しました。
#高品質のトレーニング データ
チームは高品質のデータセットを収集しました内部-Σ は、主に次の 2 つの側面に焦点を当てています:
#(1) 高品質画像: このデータセットには、インターネットからの 3,300 万枚の高解像度画像が含まれており、すべて 1K 以上です。約 4K 解像度の 230 万枚の画像を含む。これらのイメージの主な特徴は、その高い美的センスと幅広い芸術的スタイルをカバーしていることです。
(2) 緻密で正確な説明: 上の画像をより正確かつ詳細に説明するために、チームは PixArt-α で使用されていた LLaVA をより強力な画像記述子 Share-Captioner。
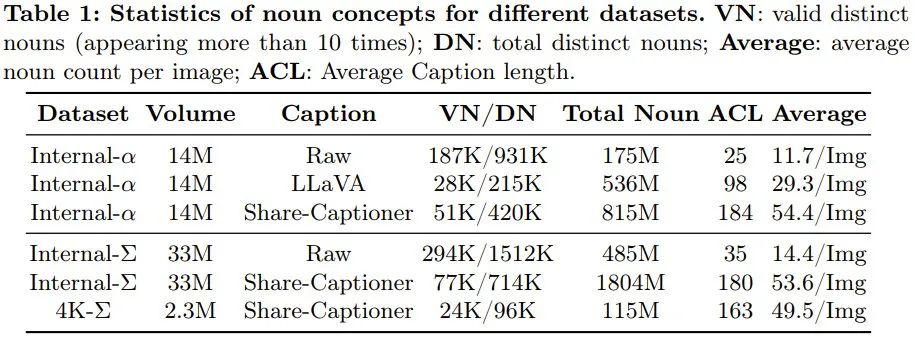
それだけでなく、テキストの概念と視覚的な概念を調整するモデルの機能を向上させるために、チームはテキスト エンコーダー (つまり Flan-T5) のトークン長を拡張しました。約300ワードまで。彼らは、これらの改善によりモデルの幻覚傾向が効果的に排除され、より高品質のテキストと画像の位置合わせが可能になることが観察されました。 #以下の表 1 は、さまざまなデータセットの統計を示しています。
#効率的なトークン圧縮
PixArt-α を強化するために、チームは世代解像度を向上させます。 1Kから4Kに増えました。超高解像度 (2K/4K など) の画像を生成するには、トークンの数が大幅に増加し、コンピューティング要件の大幅な増加につながります。
この問題を解決するために、キーと値のトークン圧縮を使用する、DiT フレームワーク用に特別に調整されたセルフアテンション モジュールを導入しました。具体的には、以下の図 7 に示すように、ストライド 2 のグループ化された畳み込みを使用して、キーと値のローカル集約を実行しました。
さらに、チームは、KV (キー値) 圧縮を使用せずに、事前トレーニングされたモデルからのスムーズな適応を実現するために、特別に設計された重み初期化スキームを採用しました。この設計により、高解像度画像生成のためのトレーニングと推論の時間が約 34% 効果的に短縮されます。 #弱いトレーニング戦略から強いトレーニング戦略までチームはさまざまな微調整を提案しました弱いモデルを強力なモデルに迅速かつ効率的に調整できるテクノロジー。 (1) 置換では、より強力な変分オートエンコーダ (VAE) が使用されます。PixArt-α の VAE は SDXL の VAE に置き換えられます。 (2) 低解像度から高解像度への拡張では、性能劣化の問題に対処するために、Position Embedding (PE) 補間方式を採用しています。 (3) KV 圧縮を使用しないモデルから KV 圧縮を使用するモデルに進化します。 #実験結果により、弱から強へのトレーニング方法の実現可能性と有効性が検証されました。 上記の改善により、PixArt-Σ は可能な限り低いトレーニング コストと可能な限り少ないモデル パラメーターで高品質の 4K 解像度の画像を生成できます。 具体的には、すでに事前トレーニングされたモデルから微調整を開始することで、チームは PixArt-α に必要な GPU 時間をさらに 9% しか使用しませんでした。 1Kの高解像度画像を生成できるモデル。新しいトレーニング データとより強力な VAE も使用しているため、このパフォーマンスは注目に値します。 また、PixArt-Σのパラメータ量はわずか0.6Bであるのに対し、SDXLとSD Cascadeのパラメータ量はそれぞれ2.6Bと5.1Bです。 PixArt-Σで生成される画像の美しさは、DALL・E 3やMJV6などの現在の一流PixArt製品に匹敵します。さらに、PixArt-Σ は、テキスト プロンプトとのきめ細かな位置合わせのための優れた機能も示します。 図 2 は、PixArt-Σ が 4K 高解像度画像を生成した結果を示しており、生成された結果は、複雑で情報量の多いテキスト命令によく従っていることがわかります。
#実験#トレーニングの詳細: 条件付き特徴抽出を実行するテキスト エンコーダーについては、チームは Imagen と PixArt-α の実践に従って T5 エンコーダー (つまり、Flan-T5-XXL) を使用しました。基本的な普及モデルはPixArt-αです。ほとんどの研究で固定の 77 個のテキスト トークンを抽出する方法とは異なり、Internal-Σ で編成された記述情報はより高密度であり、非常にきめの細かい詳細を提供できるため、テキスト トークンの長さは PixArt-α の 120 から 300 に増加します。 . .さらに、VAE は、SDXL の VAE の事前トレーニングされた凍結バージョンを使用します。その他の実装内容はPixArt-αと同様です。 モデルは、PixArt-α の 256 ピクセルの事前トレーニング チェックポイントに基づいて微調整されており、位置埋め込み補間テクノロジを使用しています。 最終モデル (解像度 1K を含む) は 32 個の V100 GPU でトレーニングされました。また、追加の 16 個の A100 GPU を使用して、2K および 4K 画像生成モデルをトレーニングしました。 評価指標: 美観と意味論的機能をより適切に実証するために、チームは 30,000 個の高品質のテキストと画像のペアを収集し、最も強力なテキストと画像のペア モデルを比較しました。ベンチマークされています。 FID メトリクスが生成品質を適切に反映していない可能性があるため、ここでは PixArt-Σ は主に人間と AI の好みによって評価されます。 画質評価: チームは、PixArt- Σ と PixArt- Σ を定性的に比較しました。クローズドソースの T2I 製品とオープンソースのモデル生成の品質。図 3 に示すように、オープンソース モデル SDXL やチームの以前の PixArt-α と比較して、PixArt-Σ によって生成されたポートレートはより現実的であり、より優れた意味分析機能を備えています。 PixArt-Σ は SDXL よりもユーザーの指示に従います。 #PixArt-Σ は、図 4 に示すように、オープン ソース モデルを上回るパフォーマンスを発揮するだけでなく、現在のクローズド ソース製品との競争力もあります。
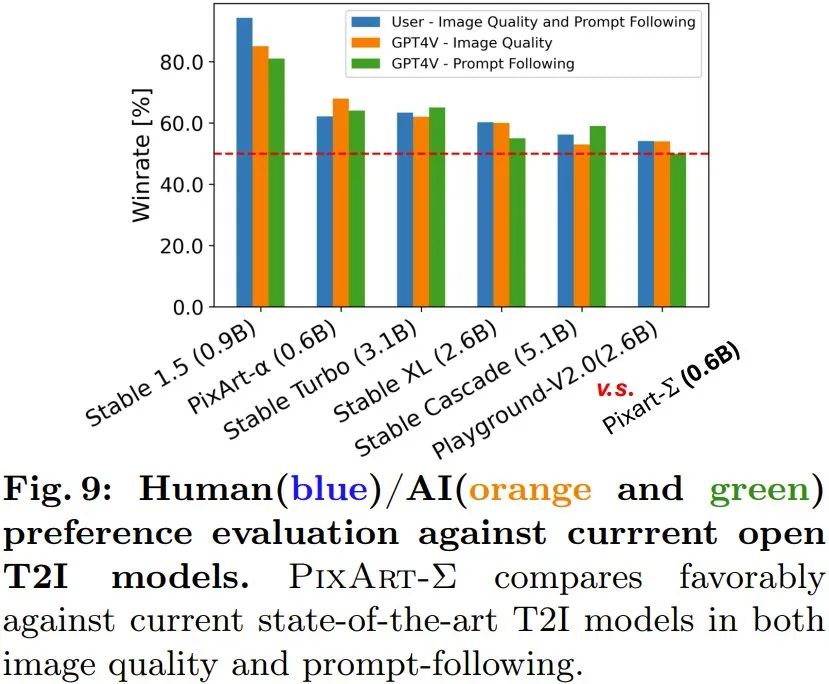
高解像度画像の生成: 新しい方法では、後処理なしで 4K 解像度の画像を直接生成できます。また、PixArt-Σは、ユーザーから提供される複雑で詳細な長文テキストにも正確に対応します。したがって、ユーザーは満足のいく結果を得るためにわざわざプロンプトを設計する必要はありません。 人間/AI (GPT-4V) の好みの調査: チームは、生成された結果に対する人間と AI の好みも調査しました。彼らは、PixArt-α、PixArt-Σ、SD1.5、Stable Turbo、Stable XL、Stable Cascade、Playground-V2.0 を含む 6 つのオープンソース モデルの生成結果を収集しました。彼らは、プロンプトと対応する画像を表示することで人間の好みのフィードバックを収集する Web サイトを開発しました。 #人間の評価者は、生成品質とプロンプトとの一致度に基づいて画像をランク付けできます。結果は図 9 の青い棒グラフに示されています。 人間の評価者は、他の 6 つのジェネレーターよりも PixArt-Σ を好むことがわかります。 SDXL (2.6B パラメーター) や SD Cascade (5.1B パラメーター) などの以前の Vincentian グラフ拡散モデルと比較して、PixArt-Σ は、はるかに少ないパラメーター (0.6B) で高品質でユーザー プロンプトとより一貫性のある画像を生成できます。
さらに、チームは高度なマルチモーダル モデルである GPT-4 Vision を使用して、AI の好みの調査を実行しました。彼らが行うことは、GPT-4 Vision に 2 つの画像を供給し、画像の品質と画像とテキストの配置に基づいて投票させることです。結果は図 9 のオレンジ色と緑色のバーに示されており、状況は人間の評価と基本的に一致していることがわかります。 チームは、さまざまな改善策の有効性を検証するためにアブレーション研究も実施しました。詳細については、原著論文をご覧ください。 # 参考記事:1. https://www.shoufachen.com/Awesome-Diffusion-Transformers/以上がDiTベースで4K画像生成をサポートするHuawei Noah 0.6B VincentグラフモデルPixArt-Σが登場の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。