
ホームページ >テクノロジー周辺機器 >AI >ViT、美団、浙江大学などを総合的に上回る視覚タスク向けの統一アーキテクチャ「VisionLLAMA」を提案
ViT、美団、浙江大学などを総合的に上回る視覚タスク向けの統一アーキテクチャ「VisionLLAMA」を提案

- PHPz転載
- 2024-03-07 15:37:02938ブラウズ
半年以上にわたって、Meta のオープンソース LLaMA アーキテクチャは LLM でテストされ、大きな成功を収めてきました (安定したトレーニングと容易なスケーリング)。
ViT の研究アイデアに従って、革新的な LLaMA アーキテクチャの助けを借りて、言語と画像のアーキテクチャ上の統合を本当に達成できるでしょうか?
この命題に関して、最近の研究 VisionLLaMA は進歩を遂げました。 VisionLLaMA は、画像生成 (Sora が依存する基礎となる DIT を含む) や理解 (分類、セグメンテーション、検出、自己監視) などの多くの主流タスクにおいて、元の ViT クラス メソッドと比較して大幅に改善されました。

- 論文タイトル: VisionLLaMA: ビジョン タスクのための統合 LLaMA インターフェイス
- ##ペーパーアドレス: https://arxiv.org/abs/2403.00522 #コード アドレス: https://github .com /Meituan-AutoML/VisionLLaMA
- この研究では、画像と言語のアーキテクチャを統合することを試みており、LLaMA 結果に関する LLM コミュニティのトレーニングを活用できます。安定した効率的なスケーリングと展開が含まれます。
研究の背景
大規模言語モデルは、現在の学術研究においてホットなテーマであり、その中でLLaMAは最も影響力があり代表的な研究です。最新の研究作業の多くはこのアーキテクチャに基づいて実行されており、さまざまなアプリケーションのソリューションのほとんどは、この一連のオープン ソース モデルに基づいて構築されています。マルチモーダル モデルの進歩において、これらのメソッドの多くは、テキスト処理には LLaMA に依存し、視覚には CLIP などのビジュアル トランスフォーマーに依存します。同時に、LLaMA の推論速度を高速化し、LLaMA のストレージ コストを削減するために多くの努力が払われています。全体として、LLaMA は現在、事実上最も多用途で重要な大規模言語モデル アーキテクチャです。

#テキスト シーケンスとビジュアル タスクのデータ処理方法には大きな違いがあります。一方で、テキスト シーケンスは 1 次元データですが、ビジョン タスクではより複雑な 2 次元または多次元データを処理する必要があります。一方、視覚的なタスクの場合、通常、パフォーマンスを向上させるためにピラミッド構造のバックボーン ネットワークを使用する必要がありますが、LLaMA エンコーダは比較的単純な構造を持っています。さらに、異なる解像度の画像およびビデオ入力を効率的に処理することも課題です。より効果的な解決策を見つけるには、テキスト領域とビジュアル領域間の横断研究でこれらの違いを十分に考慮する必要があります。
このペーパーの目的は、これらの課題に対処し、さまざまなモダリティ間のアーキテクチャ上のギャップを埋め、視覚タスクに適応した LLaMA アーキテクチャを提案することです。このアーキテクチャにより、モーダルの違いに関連する問題が解決され、視覚データと言語データを均一に処理できるため、より良い結果が得られます。
この記事の主な貢献は次のとおりです:
1. この記事では、LLaMA に似たビジュアル トランスフォーマー アーキテクチャである VisionLLaMA を提案して、言語と視覚的なアーキテクチャの違い。
2. この論文では、画像の理解と作成を含む一般的な視覚タスクに VisionLLaMA を適応させる方法を検討します (図 1)。この論文では、2 つのよく知られたビジョン アーキテクチャ スキーム (規則構造とピラミッド構造) を調査し、教師あり学習シナリオと自己教師あり学習シナリオでのパフォーマンスを評価します。さらに、この論文では、回転位置エンコーディングを 1D から 2D に拡張し、補間スケーリングを利用して任意の解像度に対応する AS2DRoPE (つまり、オートスケーリング 2D RoPE) を提案します。
3. 正確な評価の下では、VisionLLaMA は、画像生成、分類、セマンティック セグメンテーション、オブジェクト検出などの多くの代表的なタスクにおいて、現在の主流で正確に微調整されたビジョンを大幅に上回っています。広範な実験により、VisionLLaMA は既存のビジョン トランスフォーマーよりも収束速度が速く、パフォーマンスが優れていることが示されています。
VisionLLaMA 全体的なアーキテクチャ設計
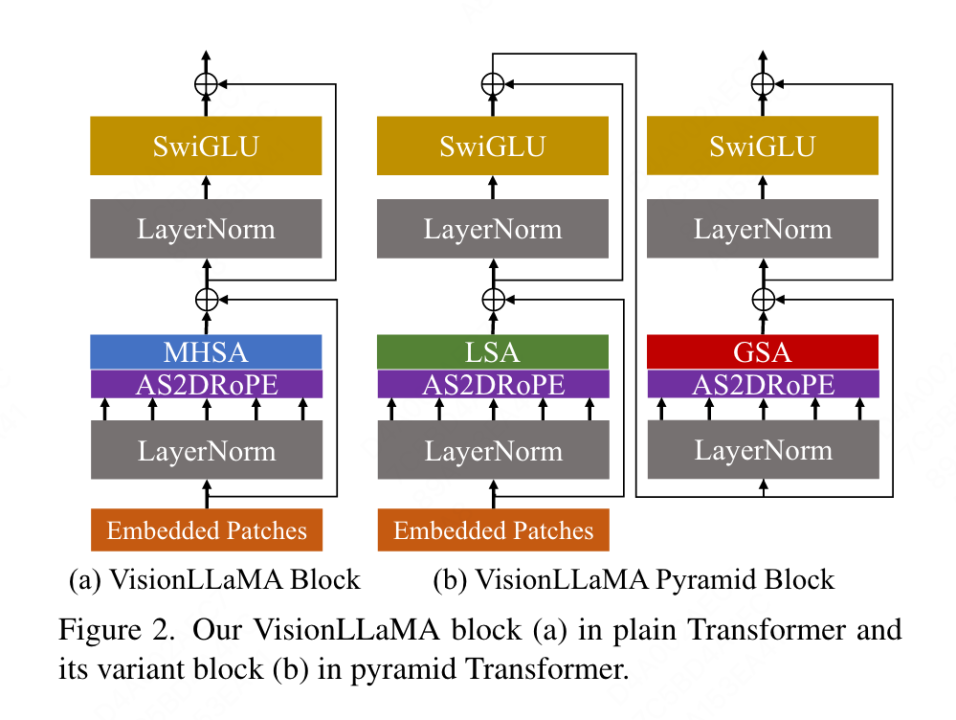
##汎用トランス
#この記事で提案する従来の VisionLLaMA は、ViT プロセスに従い、LLaMA のアーキテクチャ設計を可能な限り保持しています。画像の場合、まずシーケンスに変換および平坦化され、次にシーケンスの先頭にカテゴリ トークンが追加され、シーケンス全体が L VisionLLaMA ブロックを通じて処理されます。 ViT とは異なり、VisionLLaMA のブロックには位置エンコーディングが含まれているため、VisionLLaMA は入力シーケンスに位置エンコーディングを追加しません。具体的には、このブロックは、位置エンコーディングによるセルフアテンション (RoPE) と SwiGLU アクティベーションという 2 つの点で標準の ViT ブロックとは異なります。この記事では、RMSNorm の代わりに LayerNorm を引き続き使用します。これは、前者のパフォーマンスが優れていることが実験的に判明したためです (表 11g を参照)。ブロックの構造を図2(a)に示します。この論文では、ビジョン タスクに 1D RoPE を直接適用すると、さまざまな解像度にうまく一般化できないことが判明したため、次の 2 次元形式に拡張されています。

ピラミッド構造トランスフォーマー
VisionLLaMA を Swin のようなウィンドウベースのトランスフォーマーに適用するのは非常に簡単なので、この記事ではより強力なトランスフォーマーを使用することにします。 Baseline Twins で強力なピラミッド構造のトランスを構築する方法を探ってください。 Twins のオリジナルのアーキテクチャは、条件付き位置コーディング、ローカルとグローバルのアテンションの形でインターリーブされたローカルとグローバルの情報交換を活用しています。これらのコンポーネントは変圧器間で共通であるため、VisionLLaMA をさまざまな変圧器のバリエーションに適用することは難しくありません。この記事の目的は、ピラミッド構造を持つ新しいビジュアル トランスフォーマーを発明することではなく、既存の設計に基づいて VisionLLaMA の基本設計を調整する方法です。アーキテクチャとハイパーパラメータ 最小限の変更の原則。 ViT の命名方法に従って、2 つの連続するブロックは次のように記述できます。

シーケンス長の制限を超えたトレーニングまたは推論
1 次元 RoPE を 2 次元に拡張: 異なる入力解像度の処理はビジョンにおける共通の要件ですタスク。畳み込みニューラル ネットワークは、スライディング ウィンドウ メカニズムを使用して可変長を処理します。対照的に、ほとんどのビジュアル トランスフォーマーは、ローカル ウィンドウ操作または補間を適用します。たとえば、DeiT は、異なる解像度でトレーニングされた場合にバイキュービック補間を使用し、CPVT は畳み込みベースの位置エンコーディングを使用します。この論文では 1D RoPE のパフォーマンスを評価し、解像度 224×224 で最も高い精度を示すことがわかりましたが、解像度が 448×448 に増加すると、精度は急激に低下し、0 に達することさえあります。したがって、この論文では 1 次元 RoPE を 2 次元に拡張します。マルチヘッドセルフアテンションメカニズムの場合、2D RoPE は異なるヘッド間で共有されます。
位置補間は 2D RoPE の一般化を促進します: 補間を使用して LLaMA のコンテキスト ウィンドウを拡張するいくつかの作業に触発され、高解像度の参加により、VisionLLaMA は同様の方法で 2D コンテキスト ウィンドウを拡張します。やり方。拡大された固定コンテキスト長を使用する言語タスクとは異なり、オブジェクト検出などの視覚タスクは、多くの場合、異なる反復で異なるサンプリング解像度を処理します。この記事では、224×224 の入力解像度を使用して小さなモデルをトレーニングし、再トレーニングせずに大きな解像度のパフォーマンスを評価して、この記事が補間またはヘテロダイン戦略をより適切に適用できるようにガイドします。実験の結果、この記事では「アンカー解像度」に基づいて自動スケーリング補間 (AS2DRoPE) を適用することにしました。 H×Hの正方形画像とB×Bのアンカーポイント解像度を処理するための計算方法は次のとおりです。
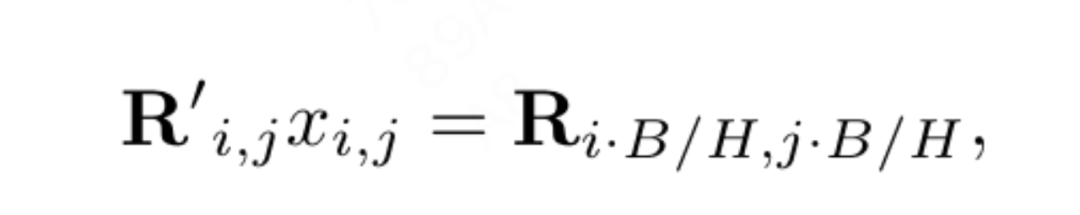
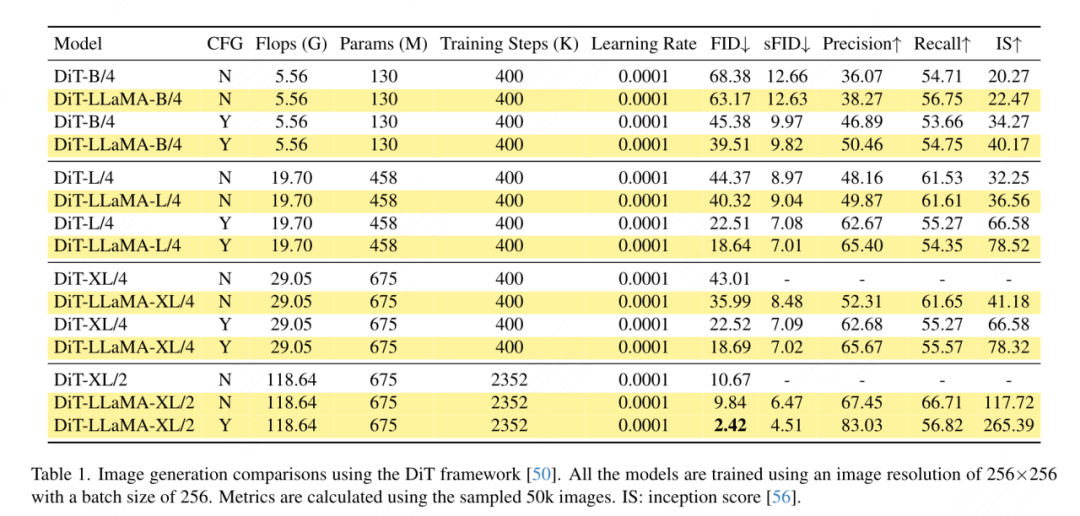
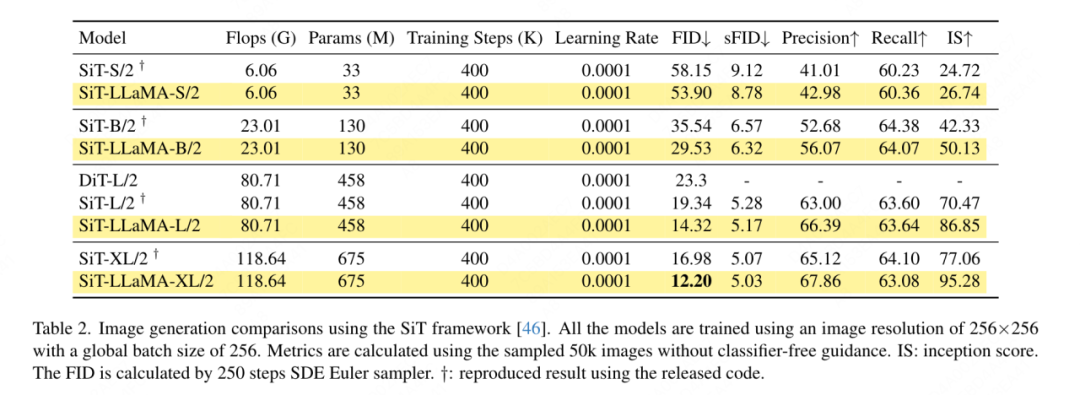
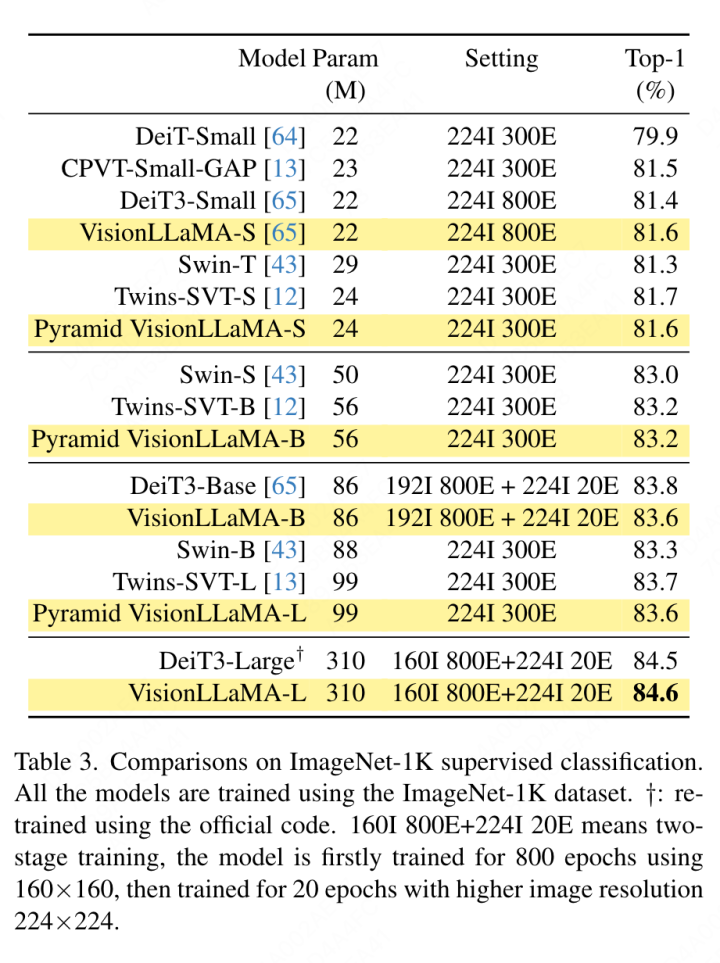
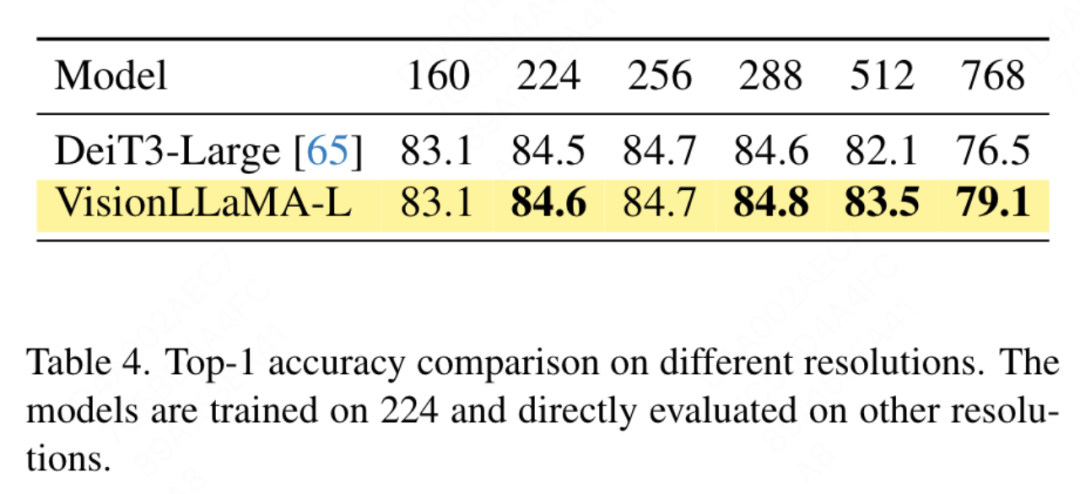
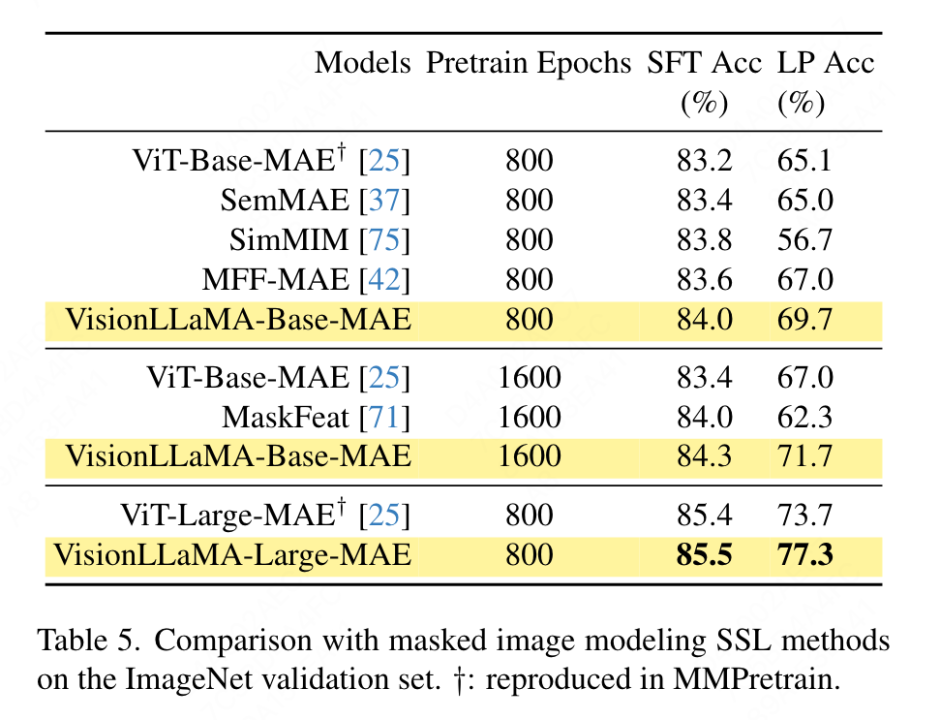
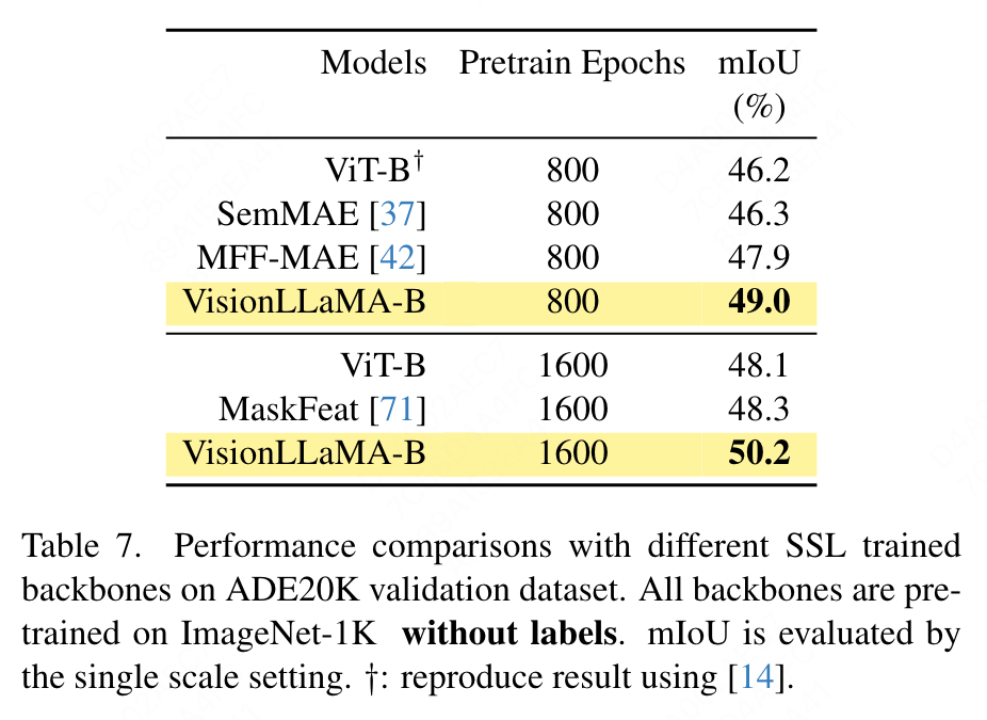
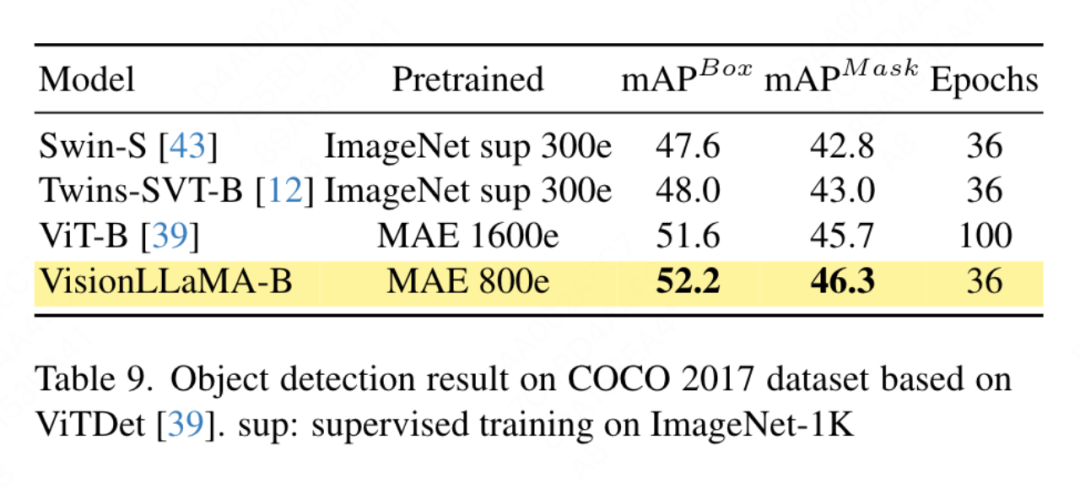
要約されたキー値に位置情報を追加する必要があるため、この記事では、ピラミッド構造設定の下で GSA を特別に扱います。これらのサブサンプリングされたキーは、機能マップの抽象化を通じて生成されます。この論文では、カーネル サイズ k×k およびストライド k の畳み込みを使用します。図 3 に示すように、生成されたキー値の座標は、サンプリングされた特徴の平均として表すことができます。 この論文では、画像生成、分類、セグメンテーション、検出などのタスクに対する VisionLLaMA の有効性を包括的に評価します。デフォルトでは、この記事のすべてのモデルは 8 つの NVIDIA Tesla A100 GPU でトレーニングされます。 画像生成 DiT フレームワークに基づく画像生成: この記事では DiT を選択します。 DiTは画像生成にVision TransformerとDDPMを使用した代表的な作品であるため、VisionLLaMAというフレームワークが適用されています。この記事では、他のコンポーネントとハイパーパラメータを変更せずに、DiT のオリジナルのビジョン トランスフォーマーを VisionLLaMA に置き換えます。この実験は、画像生成タスクにおける VisionLLaMA の多用途性を実証します。 DiT と同様に、この記事では DDPM のサンプル ステップを 250 に設定し、実験結果を表 1 に示します。ほとんどの方法論に従って、FID は主要な指標とみなされ、sFID、精度/再現率、インセプション スコアなどの他の二次的な指標に基づいて評価されます。結果は、VisionLLaMA がさまざまなモデル サイズにわたって DiT よりも大幅に優れていることを示しています。この記事では、XL モデルのトレーニング ステップ数を 2352k まで拡張して、モデルに収束が速いという利点があるか、またはトレーニング期間を長く設定してもパフォーマンスが向上するかを評価します。 DiT-LLaMA-XL/2 の FID は DiT-XL/2 よりも 0.83 低く、VisionLLaMA が DiT よりも計算効率が優れているだけでなく、パフォーマンスも高いことを示しています。 XL モデルを使用して生成されたいくつかの例を図 1 に示します。 SiT フレームワークに基づく画像生成: SiT フレームワークは、ビジュアル トランスフォーマーを使用した画像生成のパフォーマンスを大幅に向上させます。この記事では、SiT のビジョン トランスフォーマーを VisionLLaMA に置き換えて、より優れたモデル アーキテクチャ (この記事では SiT-LLaMA と呼ぶ) の利点を評価します。実験では、SiT の残りのすべての設定とハイパーパラメーターが保持され、すべてのモデルが同じステップ数を使用してトレーニングされ、線形補間と速度モデルがすべての実験で使用されました。公平な比較のために、公開されたコードを再実行し、250 ステップの SDE サンプラー (オイラー) を使用して 50k の 256×256 画像をサンプリングしました。結果を表 2 に示します。 SiT-LLaMA は、さまざまな容量レベルのモデルで SiT を上回ります。 SiT-L/2 と比較して、SiT-LLaMA-L/2 は 5.0 FID 減少します。これは、新しいフレームワークによってもたらされる改善 (4.0 FID) よりも大きくなります。この論文では、表 13 に、より効率的な ODE サンプラー (dopri5) も示していますが、私たちの方法とのパフォーマンスのギャップは依然として存在します。 SiT の論文と同様の結論が導き出されます。SDE は対応する ODE よりも優れたパフォーマンスを持っています。 #ImageNet での画像分類 このセクションでは、他のデータセットや蒸留手法の影響を排除した、ImageNet-1K データセットでのモデルの完全教師ありトレーニングに焦点を当てます。すべてのモデルはすべて ImageNet-1K トレーニング セットを使用してトレーニングされ、検証セットの精度結果を表 3 に示します。 従来のビジョン トランスフォーマーの比較: DeiT3 は、現在の最先端の従来のビジョン トランスフォーマーであり、特別なデータ拡張を提案し、パフォーマンスを向上させるために広範なハイパーパラメーター検索を実行します。 DeiT3 はハイパーパラメータに敏感で、過学習が起こりやすいため、カテゴリ トークンを GAP (グローバル平均プーリング) に置き換えると、800 エポックのトレーニング後に DeiT3-Large モデルの精度が 0.7% 低下します。したがって、この記事では、通常のトランスフォーマーの GAP の代わりにカテゴリー トークンを使用します。結果を表 3 に示します。VisionLLaMA は DeiT3 に匹敵するトップ 1 の精度を達成しています。単一解像度での精度は包括的な比較を提供しません。このホワイト ペーパーでは、さまざまな画像解像度でのパフォーマンスも評価しており、その結果を表 4 に示します。 DeiT3 では、学習可能な位置エンコーディングにバイキュービック補間を使用します。 2 つのモデルは 224×224 の解像度では同等のパフォーマンスを持っていますが、解像度が高くなるとその差は広がります。これは、私たちの方法がさまざまな解像度でより優れた汎化能力を備えていることを意味しており、ターゲットの検出や他の多くの下流タスクに適しています。 # ピラミッド構造のビジュアル トランスフォーマーの比較: この記事では Twins-SVT と同じアーキテクチャを使用しており、詳細な構成を表 17 に示します。 VisionLLaMA には回転位置エンコーディングがすでに含まれているため、この記事では条件付き位置エンコーディングを削除します。したがって、VisionLLaMA は畳み込みのないアーキテクチャです。この記事では、Twins-SVT と一貫性のある Twins-SVT のハイパーパラメータを含むすべての設定に従います。この記事ではカテゴリ トークンを使用せず、GAP を適用します。結果を表 3 に示します。私たちの方法は、すべてのモデル レベルで Twins と同等のパフォーマンスを達成し、常に Swin よりも優れています。 この記事では、ImageNet データセットを使用して、自己教師ありビジュアルの 2 つの一般的な方法を評価します。トレーニング データは ImageNet-1K に限定されており、CLIP、DALLE、または蒸留を使用してパフォーマンスを向上できるコンポーネントは削除されています。この記事の実装は MMPretrain フレームワークに基づいており、MAE フレームワークを利用し、代わりに VisionLLaMA を使用しています。他のコンポーネントは変更せずに、エンコーダーを変更します。この対照実験により、この方法の有効性を評価できます。さらに、比較した方法と同じハイパーパラメータ設定を使用していますが、その設定でも強力なベースラインと比較して大幅なパフォーマンスの向上を達成しています。 完全な微調整セットアップ: 現在のセットアップでは、モデルは最初に事前トレーニングされた重みで初期化され、次に完全にトレーニング可能なパラメーターで追加トレーニングされます。 VisionLLaMA-Base は ImageNet 上で 800 エポックにわたってトレーニングされ、84.0% というトップ 1 の精度を達成しました。これは ViT-Base より 0.8% 高いです。この記事の方法は、SimMIM よりも約 3 倍高速にトレーニングします。また、この論文では、VisionLLaMA が十分なトレーニング リソースで優位性を維持できるかどうかを検証するために、トレーニング期間を 1600 に延長しました。 VisionLLaMA-Base は、MAE バリアントの中で新しい SOTA 結果を達成し、トップ 1 の精度 84.3% を達成しました。これは、ViT-Base よりも 0.9% 向上しました。完全な微調整にはパフォーマンスが飽和するリスクがあることを考慮すると、この方法の改善は非常に重要です。 線形プローブ: 最近の研究では、線形プローブ指標が表現学習のより信頼性の高い評価であることが示唆されています。現在のセットアップでは、モデルは SSL ステージからの事前トレーニングされた重みによって初期化されます。その後、トレーニング中に、分類器ヘッドを除いてバックボーン ネットワーク全体がフリーズされます。結果を表 5 に示します。800 エポックのトレーニング コストで、VisionLLaMA-Base は ViTBase-MAE を 4.6% 上回りました。また、1600 エポックでトレーニングされた ViT-Base-MAE よりも優れたパフォーマンスを発揮します。 VisionLLaMA が 1600 エポックでトレーニングされた場合、VisionLLaMA-Base は 71.7% というトップ 1 の精度を達成します。この方法は VisionLLaMA-Large にも拡張されており、ViT-Large と比較して 3.6% 改善されています。 #ADE20K データセットのセマンティック セグメンテーション この記事では、 ADE20K データセットのセマンティック セグメンテーションでは、他のコンポーネントとハイパーパラメータを変更せずに、ViT バックボーンを置き換えるために VisionLLaMA が使用されます。この記事の実装は MMS セグメンテーションに基づいており、結果を表 7 に示します。 800 エポックの事前トレーニング セットでは、VisionLLaMA-B は ViT-Base を 2.8% mIoU 大幅に改善しました。また、私たちの方法は、トレーニング プロセスに追加のオーバーヘッドをもたらし、トレーニング速度を低下させる追加のトレーニング目標や機能の導入など、他のいくつかの改善点よりも大幅に優れています。対照的に、VisionLLaMA はベース モデルの置き換えのみを必要とし、学習速度が速いです。この論文ではさらに、1600 の長い事前トレーニング エポックのパフォーマンスを評価しており、VisionLLaMA-B は ADE20K 検証セットで 50.2% mIoU を達成しており、これにより ViT-B のパフォーマンスが 2.1% mIoU 向上しています。 #COCO データセットでのオブジェクト検出
#アブレーション実験とディスカッション この記事では、複数の実行でこのモデルによって生成される分散が小さいことが観察されているため、デフォルトで ViT-Large モデルでアブレーション実験を行うことを選択します。
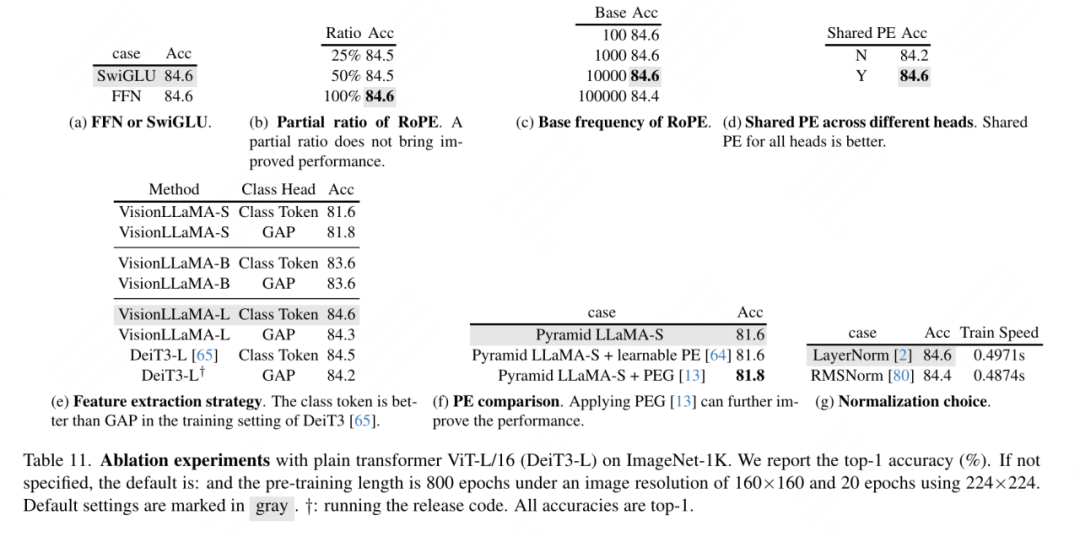
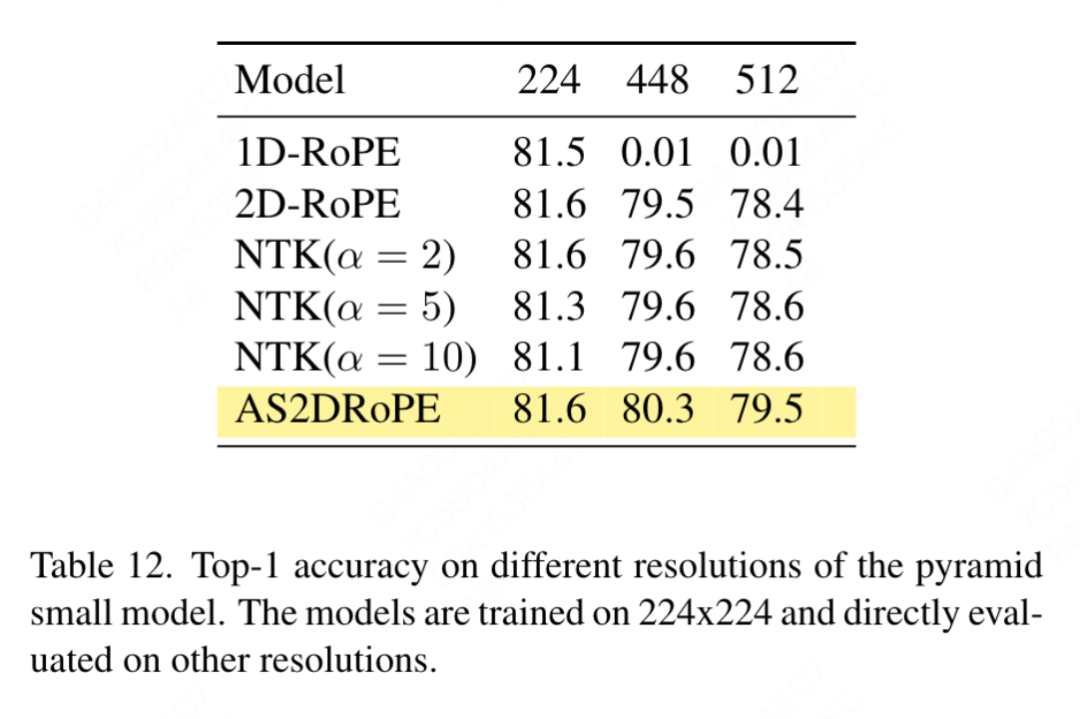
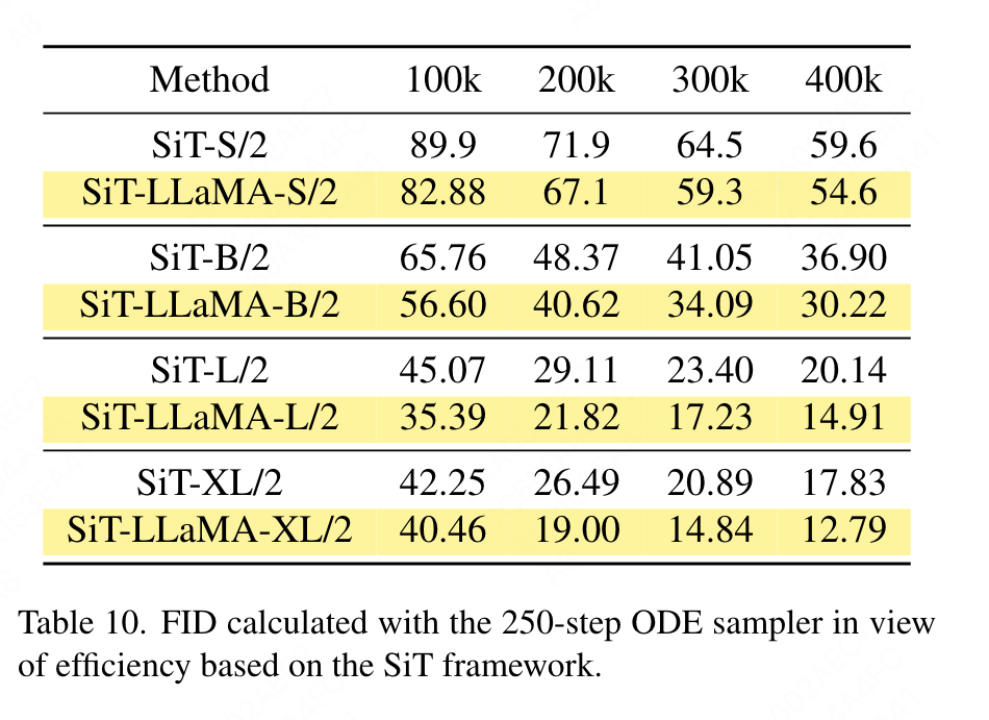
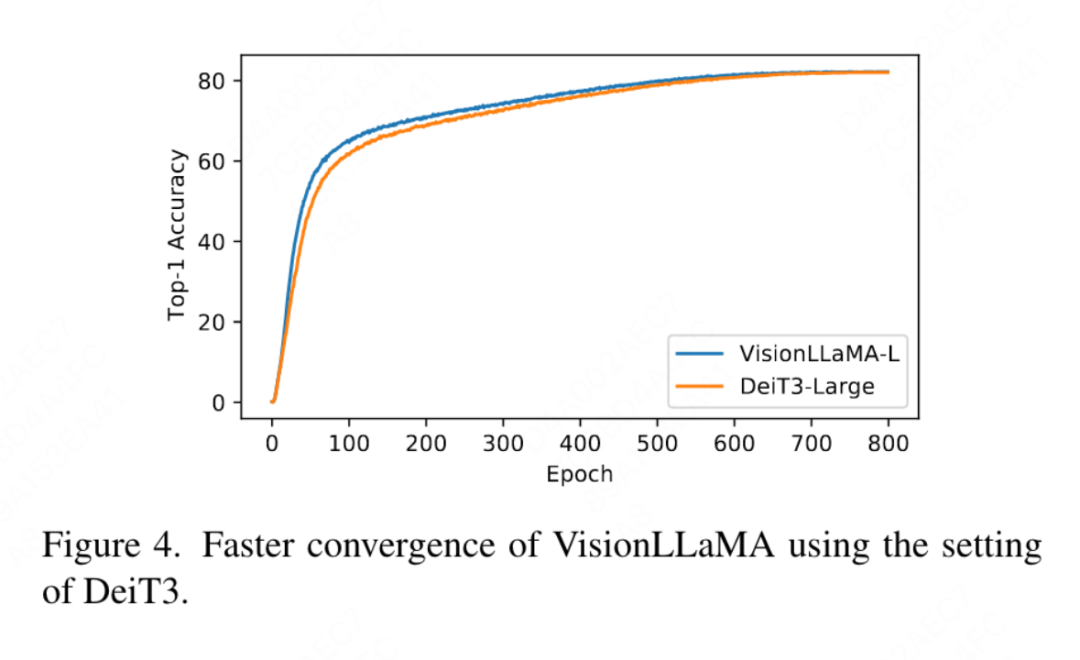
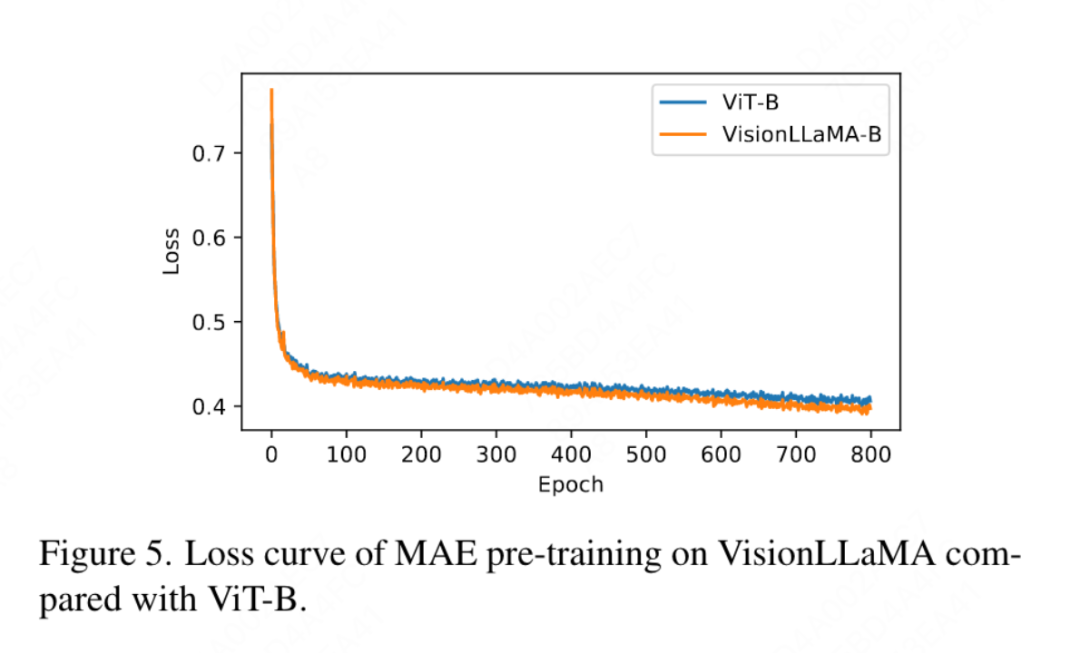
FFN と SwiGLU の廃止: この論文では、FFN を SwiGLU に置き換えます。結果を表 11a に示します。明らかなパフォーマンスのギャップがあるため、この文書では、LLaMA アーキテクチャに追加の変更を導入することを避けるために SwiGLU を使用することを選択しました。 正規化戦略の廃止: この論文では、トランスフォーマで広く使用されている 2 つの正規化方法、RMSNorm と LayerNorm を比較します。結果を表 11g に示します。後者の方が最終的なパフォーマンスが優れており、再センタリングの不変性も視覚タスクでは重要であることが示唆されています。この記事では、トレーニング速度を測定するために反復ごとに費やされる平均時間も計算します。LayerNorm は RMSNorm よりわずか 2% 遅いだけです。したがって、この記事では、よりバランスのとれたパフォーマンスを実現するために、RMSNorm ではなく LayerNorm を選択します。 部分位置エンコーディング: この論文では、RoPE を使用してすべてのチャネルの比率を調整します。結果は表 11b に示されています。結果は、比率を小さなしきい値に設定すると良好なパフォーマンスが得られることを示しています。異なる設定間で観察すると、パフォーマンスに大きな違いがあります。したがって、この記事では LLaMA のデフォルト設定をそのまま使用します。 基本周波数: この論文では、基本周波数を変更して比較し、その結果を表 11c に示します。結果は、パフォーマンスが広範囲の周波数に対して堅牢であることを示しています。したがって、この記事では、デプロイメント時の追加の特別な処理を避けるために、LLaMA のデフォルト値を保持します。 各注目ヘッド間での位置エンコーディングの共有: この論文では、異なるヘッド間で同じ PE を共有する (各ヘッドの周波数は 1 から 10000 まで変化します) 方が、独立した PE (周波数が異なる) よりも優れていることがわかりました。すべてのチャネルで 1 から 10000 まで変化する) の方が優れており、その結果を表 11d に示します。 特徴抽象化戦略: このペーパーでは、大パラメーター スケール モデル (-L) での 2 つの一般的な特徴抽出戦略、カテゴリ トークンと GAP を比較します。結果は、カテゴリを使用して表 11e に示されています。トークンは GAP よりも優れていますが、これは PEG [13] で得られた結論とは異なります。ただし、2 つの方法のトレーニング設定はまったく異なります。この論文では、DeiT3-L を使用した追加の実験も実施し、同様の結論に達しました。この記事では、「小型」 (-S) モデルと「基本」 (-B) モデルのパフォーマンスをさらに評価します。興味深いことに、小規模モデルでは逆の結論が観察されており、DeiT3 で使用されるドロップパス レートが高いため、GAP などのパラメーターを使用しない抽象化手法で望ましい効果を達成することが困難になっているのではないかと疑う理由があります。 位置符号化戦略: この論文では、学習可能な位置符号化や PEG など、ピラミッド構造 VisionLLaMA-S 上の他の絶対位置符号化戦略も評価します。強力なベースラインが存在するため、この論文では「小さい」モデルを使用します。結果を表 11f に示します。学習可能な PE はパフォーマンスを改善しませんが、PEG はベースラインを 81.6% から 81.8% にわずかに改善します。この記事では、3 つの理由から PEG を必須コンポーネントとして取り上げていません。まず、この文書では LLaMA に最小限の変更を加えることを試みます。第二に、この論文の目的は、ViT などのさまざまなタスクに対する一般的なアプローチを提案することです。 MAE のようなマスクされたイメージ フレームワークの場合、PEG によりトレーニング コストが増加し、ダウンストリーム タスクのパフォーマンスが低下する可能性があります。原則として、MAE フレームワークではスパース PEG を適用できますが、展開に不向きな演算子が導入されます。疎な畳み込みが密な畳み込みと同じくらい多くの位置情報を含むかどうかは未解決の問題のままです。第三に、モダリティフリーのデザインにより、テキストやビジュアルを超えた他のモダリティをカバーするさらなる研究への道が開かれます。 入力サイズに対する感度: トレーニングを行わずに、この記事ではさらに、増加した解像度と一般的な解像度のパフォーマンスを比較します。結果を表 12 に示します。ここではピラミッド構造トランスフォーマーが使用されています。これは、対応する非階層バージョンよりも下流タスクでよく使用されるためです。 1D-RoPE のパフォーマンスが解像度の変更によって重大な影響を受けることは驚くべきことではありません。 α = 2 の NTK-Aware 補間は、実際には NTKAware (α = 1) である 2D-RoPE と同様のパフォーマンスを実現します。 AS2DRoPE は、より大きな解像度で最高のパフォーマンスを発揮します。 収束速度: 画像生成について、この論文では、重みを保存してパフォーマンスを研究します。それぞれ 100k、200k、300k、400k の反復で忠実度メトリクスを計算します。 SDE は ODE よりも大幅に遅いため、この記事では ODE サンプラーを使用することにしました。表 10 の結果は、すべてのモデルで VisionLLaMA が ViT よりもはるかに高速に収束することを示しています。 300,000 回のトレーニング反復を行う SiT-LLaMA は、400,000 回のトレーニング反復を行うベースライン モデルよりも優れたパフォーマンスを示します。 この記事では、図 4 の ImageNet で DeiT3-Large を使用した完全教師ありトレーニングの 800 エポックのトップ 1 の精度も比較しています。これは、VisionLLaMA がDeiT3-L よりも早く収束します。この論文では、MAE フレームワークの下での ViT-Base モデルの 800 エポックのトレーニング損失をさらに比較しています。これを図 5 に示します。 VisionLLaMA では、最初のトレーニング損失が低く、この傾向が最後まで維持されます。 
実験結果
完全監視トレーニング
Swin の設定に従って、この記事では ADE20K データセットでセマンティック セグメンテーションを使用して、この方法の有効性を評価します。公平な比較を行うために、このペーパーではベースライン モデルを事前トレーニングに ImageNet-1K のみを使用するように制限しています。この記事では、UpperNet フレームワークを使用し、バックボーン ネットワークをピラミッド構造の VisionLLaMA に置き換えます。この記事の実装は、MMSegmentation フレームワークに基づいています。モデルのトレーニング ステップ数は 160k に設定され、グローバル バッチ サイズは 16 です。結果を表 6 に示します。同様の FLOP で、私たちの方法は Swin および Twins よりも 1.2% mIoU 以上優れています。 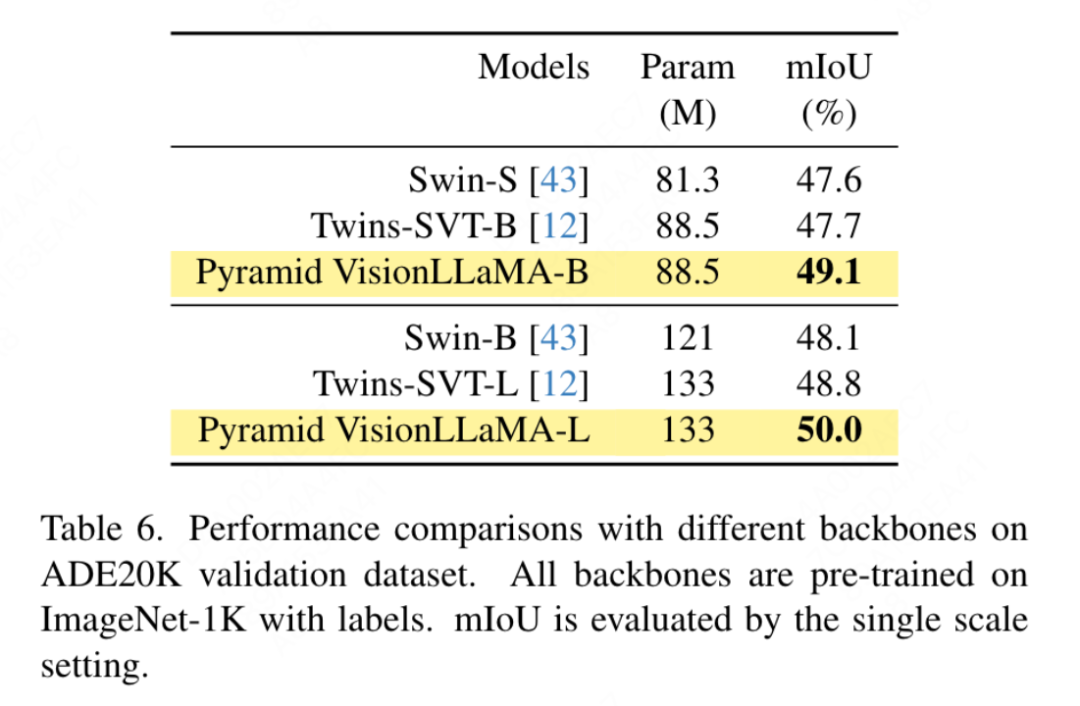
完全教師ありトレーニング
この論文では、COCO データセット上のターゲット検出タスクにおけるピラミッド構造 VisionLLaMA のパフォーマンスを評価します。この論文では、Mask RCNN フレームワークを使用し、バックボーン ネットワークを、Swin のセットアップと同様に、ImageNet-1K データセットで 300 エポックにわたって事前トレーニングされたピラミッド構造の VisionLLaMA に置き換えます。したがって、モデルには Twins と同じ数のパラメータと FLOP があります。この実験は、ターゲット検出タスクにおけるこの方法の有効性を検証するために使用できます。この記事の実装は、MMDetection フレームワークに基づいています。表 8 は、標準的な 36 エポック トレーニング サイクル (3 倍) の結果を示しています。この記事のモデルは、Swin および Twins よりも優れています。具体的には、VisionLLaMA-B は Swin-S よりもボックス mAP が 1.5%、マスク mAP が 1.0% 優れています。より強力なベースライン Twins-B と比較して、私たちの方法には、ボックス mAP が 1.1% 高く、マスク mAP が 0.8% 高いという利点があります。 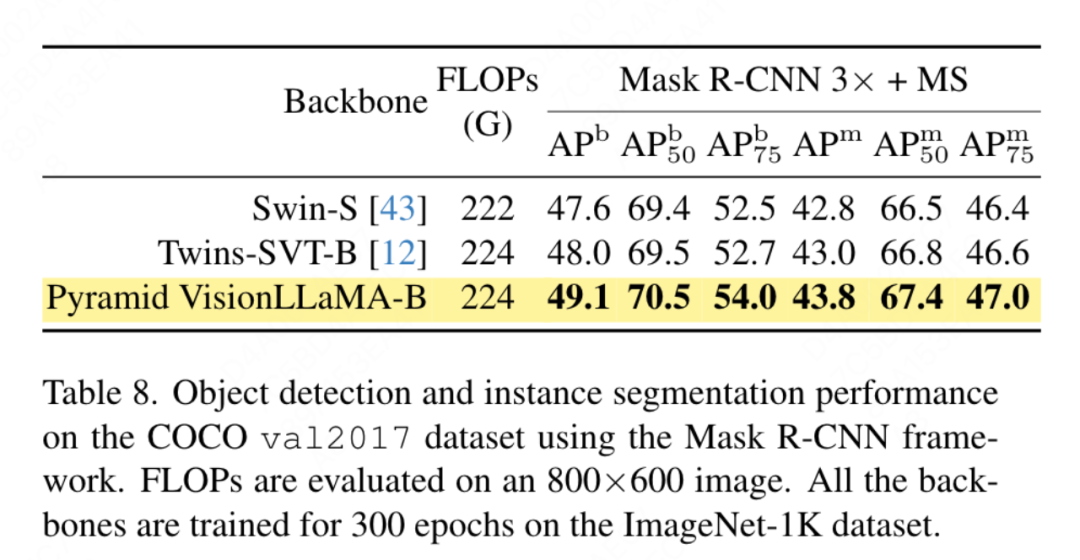
アブレーション実験
ディスカッション
以上がViT、美団、浙江大学などを総合的に上回る視覚タスク向けの統一アーキテクチャ「VisionLLAMA」を提案の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。