
ホームページ >テクノロジー周辺機器 >AI >ICLR 2024 口頭: 長いビデオでのノイズ相関学習、シングルカードのトレーニングにかかる時間はわずか 1 日
ICLR 2024 口頭: 長いビデオでのノイズ相関学習、シングルカードのトレーニングにかかる時間はわずか 1 日

- 王林転載
- 2024-03-05 22:58:13962ブラウズ

論文タイトル: 長期間のノイズの多いビデオからの多粒度通信学習 論文アドレス: https://openreview.net/pdf?id=9Cu8MRmhq2 プロジェクトアドレス: https://lin-yijie.github.io/projects/Norton コード アドレス: https://github.com/XLearning-SCU/2024-ICLR-Norton

長いビデオは通常、自動言語認識 (ASR) を使用して対応するテキスト字幕を取得するため、ビデオ全体に対応するテキスト段落 (Paragraph) は、 ASR テキスト タイムスタンプは複数の短いテキスト タイトル (Caption) に分割され、長いビデオ (Video) はそれに応じて複数のビデオ クリップ (Clip) に分割できます。ビデオ クリップとタイトルの後期段階での融合または位置合わせの戦略は、ビデオ全体を直接エンコードするより効率的であり、長期的な時間的関連学習に最適なソリューションです。
ただし、
-
粗粒度 NC (クリップとキャプションの間)。粗粒度 NC には、非同期 (Asynchronous) と無関係 (Irrelevant) の 2 つのカテゴリがあり、その違いは、ビデオ クリップまたはタイトルが既存のタイトルまたはビデオ クリップに対応できるかどうかにあります。 「非同期」とは、図 2 の t1 など、ビデオ クリップとタイトルの間のタイミングのずれを指します。これにより、アクションが実際に実行される前後でナレーターが説明するため、一連のステートメントとアクションの間に不一致が生じます。 「無関係」とは、ビデオクリップと一致しない意味のないタイトル(t2 や t6 など)、または無関係なビデオクリップを指します。 Oxford Visual Geometry Group [5] による関連調査によると、HowTo100M データセット内のビデオ クリップとタイトルの約 30% のみが視覚的に位置合わせされており、15% のみが元々位置合わせされています。 ##ファイングレイン NC (フレームワード) 。ビデオ クリップの場合、テキスト説明の一部のみがそれに関連する場合があります。図 2 では、タイトル t5「砂糖をふりかける」はビジュアル コンテンツ v5 と強く関連していますが、アクション「釉薬の剥がれを観察する」はビジュアル コンテンツと関連していません。無関係な単語やビデオ フレームは重要な情報の抽出を妨げ、セグメントとタイトル間の位置合わせに影響を与える可能性があります。
# 図 3 ビデオ - 段落比較アルゴリズムの図。 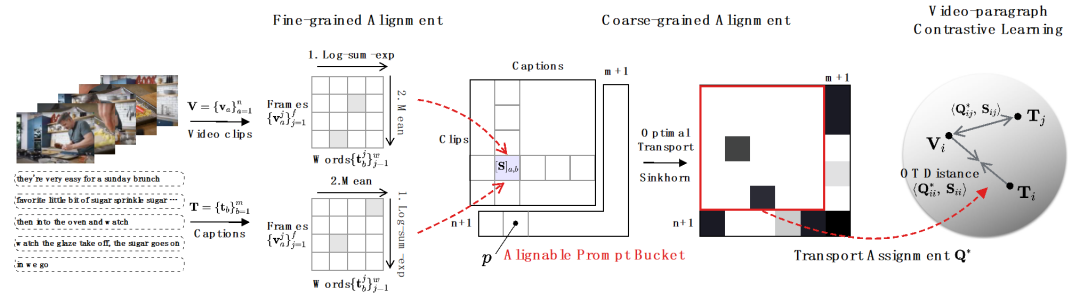
粒度の細かい NC
-
粗粒度の非同期 NC の場合。研究者らは、ビデオクリップとタイトル間の距離の指標として最適な伝送距離を使用しました。ビデオ クリップとテキストのタイトルの類似性行列 ( - はクリップとタイトルの数を表します) が与えられた場合、最適な送信目標は、全体的な配置の類似性を最大化することです。これにより、タイミングを非同期または 1 対多で自然に処理できます ( t3 など、v4、v5) の複雑なアライメント状況に対応します。

ここで、 は各セグメントとタイトルに等しい重みを与える一様分布であり、 は送信割り当てまたは再調整の瞬間であり、Sinkhorn アルゴリズムによって解決できます。 粗粒度で無関係な NC を対象としています。特徴マッチングにおける SuperGlue [6] からインスピレーションを得て、無関係なセグメントやタイトルをフィルタリングするために、適応性のある位置合わせ可能なヒント バケットを設計しました。プロンプトバケットは、類似度行列 上で結合された 1 行 1 列の同じ値のベクトルであり、その値は位置合わせできるかどうかの類似度のしきい値を表します。チップ バケットは、Optimal Transport Sinkhorn ソルバーにシームレスに統合されます。
長いビデオを直接モデリングするのではなく、最適な伝送を通じてシーケンス距離を測定すると、計算量を大幅に削減できます。最終的なビデオ段落の損失関数は次のとおりです。ここで、 は、 番目の長いビデオと 番目のテキスト段落の間の類似性行列を表します。 #2) スニペット - タイトルと 。この損失により、ビデオ段落の比較におけるセグメントとタイトルの位置合わせの精度が保証されます。自己教師あり対比学習では、意味的に類似したサンプルが誤って陰性サンプルとして最適化されるため、最適転送を使用して、潜在的な偽陰性サンプルを特定して修正します。 は、トレーニング バッチ内のすべてのビデオ クリップとタイトルの数、単位行列 は対比学習クロスエントロピー損失における標準的なアライメント ターゲットを表し、 は最適な送信補正ターゲット を組み込んだ後の再アライメント ターゲットを表します。 は重み係数です。 実験 この記事は、ノイズ相関を克服してモデルの精度を向上させることを目的としています。長いビデオの理解。ビデオ検索、質疑応答、アクション分割などの具体的なタスクを通じて検証したところ、以下のような実験結果が得られました。 1) 長いビデオの取得 このタスクの目標は、指定されたテキストです。段落、対応する長いビデオを取得します。研究者らは、YouCookII データセットで、テキストに依存しないビデオ クリップを保持するかどうかに応じて、背景保持と背景削除の 2 つのシナリオをテストしました。彼らは、Caption Average、DTW、OTAM という 3 つの類似性測定基準を使用します。 Caption Average は、テキスト段落内のタイトルごとに最適なビデオ クリップを照合し、最後に一致数が最も多い長いビデオを呼び出します。 DTW と OTAM は、ビデオとテキストの段落間の距離を時系列に累積します。結果を以下の表1および表2に示す。 表1、2 YouCookIIデータセットで見られる長時間ビデオ検索パフォーマンスの比較 # #2) ノイズ相関ロバストネス分析 ## 9 9 ノイズ関連性の HTM-Align データセット分析に関する表 9 概要と展望 参考文献: 1. このサイト「Yann LeCun :生成モデルはビデオの処理には適していません。AI は抽象空間で予測を行う必要があります。」、2024-01-23. 2.Sun, Y., Xue , H.、Song, R.、Liu, B.、Yang, H.、& Fu, J. (2022). マルチモーダル時間対比学習による長編ビデオ言語の事前トレーニング. 神経情報処理システムの進歩、35、38032-38045。 3.Huang、Z.、Niu、G.、Liu、X.、Ding、W.、Xiao、X . , Wu, H., & Peng, X. (2021). クロスモーダル マッチングのためのノイズを含む対応による学習. Advances in Neural Information Processing Systems, 34, 29406-29419. ##4.Lin, Y., Yang, M., Yu, J., Hu, P., Zhang, C., & Peng, X. (2023). バイレベルノイズ対応によるグラフマッチング. コンピュータ ビジョンに関する IEEE/CVF 国際会議議事録. ##5. Han, T.、Xie, W.、Zisserman, A. ( 2022 ). 長期ビデオ用の時間的アラインメント ネットワーク. コンピューター ビジョンとパターン認識に関する IEEE/CVF 会議議事録 (pp. 2906-2916).6.Sarlin, P. E.、DeTone, D.、Malisiewicz, T.、& Rabinovich, A. (2020). スーパーグルー: グラフ ニューラル ネットワークによる学習特徴マッチング. コンピューター ビジョンとパターン認識に関する IEEE/CVF 会議の議事録(pp. 4938-4947).
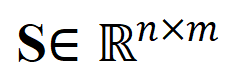
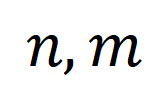
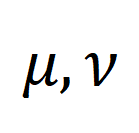 は各セグメントとタイトルに等しい重みを与える一様分布であり、
は各セグメントとタイトルに等しい重みを与える一様分布であり、 は送信割り当てまたは再調整の瞬間であり、Sinkhorn アルゴリズムによって解決できます。
は送信割り当てまたは再調整の瞬間であり、Sinkhorn アルゴリズムによって解決できます。  上で結合された 1 行 1 列の同じ値のベクトルであり、その値は位置合わせできるかどうかの類似度のしきい値を表します。チップ バケットは、Optimal Transport Sinkhorn ソルバーにシームレスに統合されます。
上で結合された 1 行 1 列の同じ値のベクトルであり、その値は位置合わせできるかどうかの類似度のしきい値を表します。チップ バケットは、Optimal Transport Sinkhorn ソルバーにシームレスに統合されます。 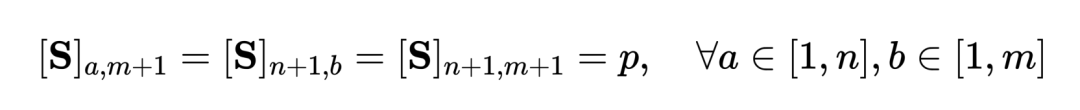
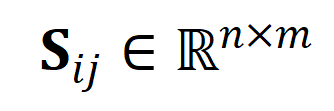 は、
は、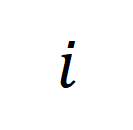 番目の長いビデオと
番目の長いビデオと 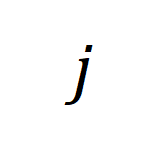 番目のテキスト段落の間の類似性行列を表します。
番目のテキスト段落の間の類似性行列を表します。 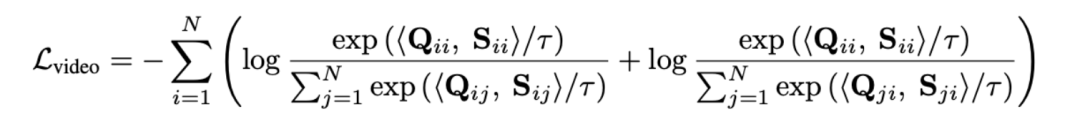
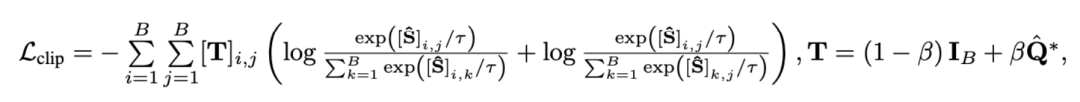
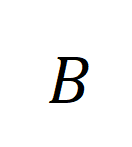 は、トレーニング バッチ内のすべてのビデオ クリップとタイトルの数、単位行列
は、トレーニング バッチ内のすべてのビデオ クリップとタイトルの数、単位行列 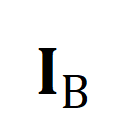 は対比学習クロスエントロピー損失における標準的なアライメント ターゲットを表し、
は対比学習クロスエントロピー損失における標準的なアライメント ターゲットを表し、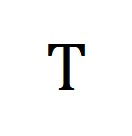 は最適な送信補正ターゲット
は最適な送信補正ターゲット 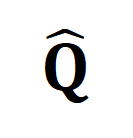 を組み込んだ後の再アライメント ターゲットを表します。
を組み込んだ後の再アライメント ターゲットを表します。 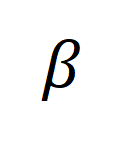 は重み係数です。
は重み係数です。 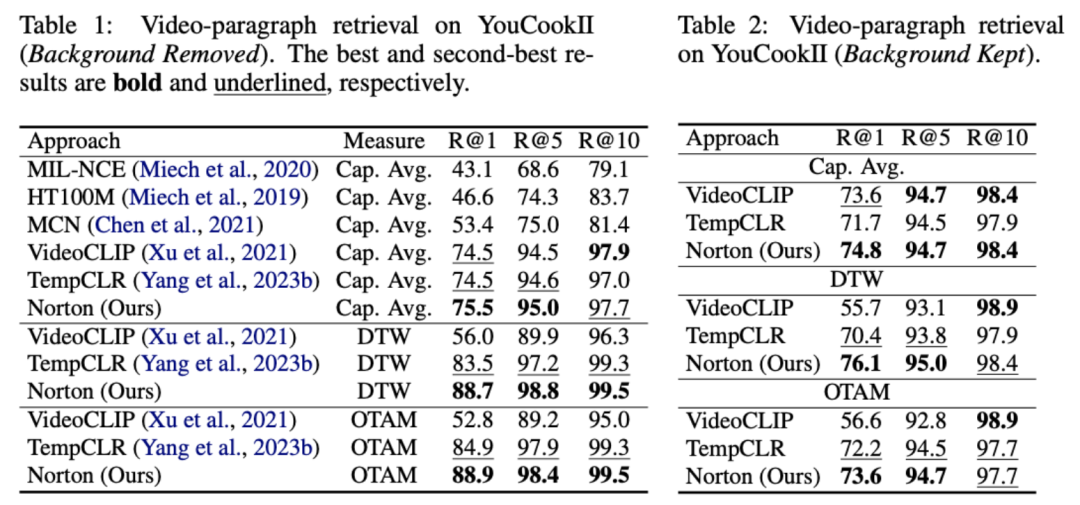

以上がICLR 2024 口頭: 長いビデオでのノイズ相関学習、シングルカードのトレーニングにかかる時間はわずか 1 日の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
声明:
この記事はjiqizhixin.comで複製されています。侵害がある場合は、admin@php.cn までご連絡ください。