
ホームページ >テクノロジー周辺機器 >AI >DeepMind CEO: LLM+tree 検索は AGI テクノロジーラインです。AI 研究はエンジニアリング能力に依存しています。クローズドソース モデルはオープンソース モデルより安全です。
DeepMind CEO: LLM+tree 検索は AGI テクノロジーラインです。AI 研究はエンジニアリング能力に依存しています。クローズドソース モデルはオープンソース モデルより安全です。

- PHPz転載
- 2024-03-05 12:04:18463ブラウズ
Google は 2 月以降、突然 996 モードに切り替え、1 か月足らずで 5 つのモデルを発表しました。
そして、DeepMind CEO の Hassabis 氏自身も、あらゆる場所で自社製品を宣伝し、開発舞台裏の多くのインサイダー情報を公開しています。
彼の見解では、技術的な進歩は依然として必要ですが、人類にとって AGI への道はすでに開かれています。
DeepMind と Google Brain の合併は、AI テクノロジーの開発が新しい時代に入ったことを示しています。
Q: DeepMind は常にテクノロジーの最前線に立っています。たとえば、AlphaZero のようなシステムでは、内部の知的エージェントは一連の思考を通じて最終目標を達成できます。これは、大規模言語モデル (LLM) もこの種の研究の仲間入りをする可能性があることを意味するのでしょうか?
Hassabis は、大規模モデルには大きな可能性があり、予測精度を向上させるためにさらに最適化する必要があり、それによってより信頼性の高い世界モデルを構築する必要があると考えています。このステップは重要ですが、完全な汎用人工知能 (AGI) システムを構築するには十分ではない可能性があります。
これに基づいて、私たちは、世界モデルを通じて特定の世界目標を達成するための計画を策定する、AlphaZero と同様の計画メカニズムを開発しています。
これには、さまざまな思考や推論のチェーンをつなぎ合わせたり、ツリー検索を使用して広大な可能性の空間を探索したりすることが含まれます。
これらは、現在の大規模モデルに欠けているリンクです。
Q: 純粋な強化学習 (RL) 手法から始めて、AGI に直接移行することは可能ですか?
#大規模な言語モデルが事前知識の基礎を形成し、これに基づいてさらなる研究を実行できるようです。
理論的には、AlphaZero の開発方法を完全に採用することが可能です。
DeepMind と RL コミュニティの一部の人々はこの方向に取り組んでおり、新しい知識システムを完全に構築するために事前の知識やデータに頼らず、ゼロからスタートします。
私は、Web 上の情報やすでに収集しているデータなど、世界の既存の知識を活用することが、AGI を達成する最も早い方法であると信じています。
この情報を吸収できるスケーラブルなアルゴリズム、トランスフォーマーを使用できるようになり、これらの既存のモデルを予測と学習のための事前知識として完全に使用できます。
したがって、最終的な AGI システムには、ソリューションの一部として今日の大規模モデルが確実に含まれると私は信じています。
しかし、大規模なモデルだけでは不十分です。さらに計画機能や検索機能を追加する必要もあります。
Q: これらの方法で必要となる膨大なコンピューティング リソースに直面して、どうすれば突破できるでしょうか?
AlphaGo のようなシステムでも、デシジョン ツリーの各ノードで計算を実行する必要があるため、非常に高価です。
私たちは、より効率的な方法の探索だけでなく、エクスペリエンスのリプレイなど、既存のデータを再利用するためのサンプル効率の高い方法と戦略の開発にも取り組んでいます。
実際、世界モデルが十分に優れていれば、検索はより効率的になる可能性があります。
Alpha Zero を例に挙げると、囲碁やチェスなどのゲームでのパフォーマンスは世界選手権レベルを超えていますが、検索範囲は従来の総当たり検索方法よりもはるかに狭いです。
これは、モデルを改善すると検索がより効率的になり、より多くのターゲットに到達できることを示しています。
しかし、報酬関数と目標を定義するときに、システムが正しい方向に発展することを保証する方法は、私たちが直面する課題の 1 つになります。
なぜ Google は半月で 5 つのモデルを作成できるのでしょうか?
Q: Google と DeepMind が同時にこれほど多くの異なるモデルに取り組んでいる理由について話してもらえますか?
当社は基礎研究を行ってきたため、さまざまな革新や方向性をカバーする基礎研究の仕事を大量に抱えています。
これは、私たちがメイン モデル トラック、つまりコアとなる Gemini モデルを構築している一方で、さらに多くの探索的なプロジェクトも進行中であることを意味します。
これらの探査プロジェクトが何らかの結果を達成したら、それらを Gemini の次のバージョンのメイン ブランチにマージします。これが、1.0 の直後に 1.5 がリリースされる理由です。すでに次のバージョンに取り組んでいます。複数のチームが異なるタイムスケールで作業し、相互に循環しているため、そうやって進歩を続けることができます。
安全なモデルをリリースすることが私たちの最優先事項であることを念頭に置き、これほどのスピードで製品をリリースすることが、もちろんですが非常に責任を持ってリリースされることが、私たちの新たな常態になることを願っています。
Q: 最近の大きなリリースである Gemini 1.5 Pro についてお聞きしたいのですが、新しい Gemini Pro 1.5 モデルは最大 100 万個のトークンを処理できます。これが何を意味するのか、そしてなぜコンテキストウィンドウが重要なテクニカル指標であるのか説明していただけますか?
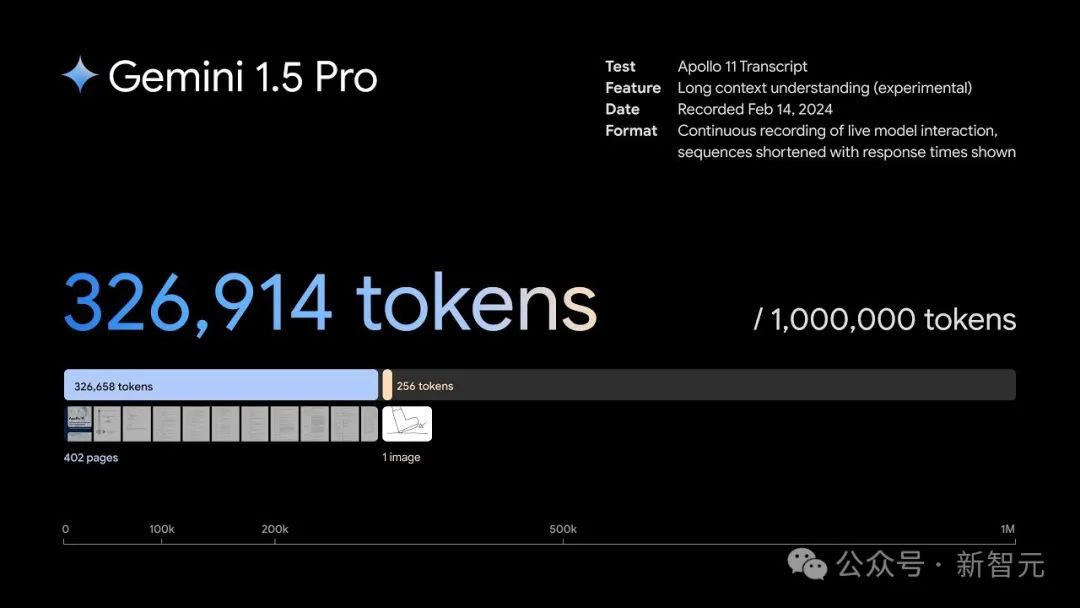
#はい、これは非常に重要です。長いコンテキストは、モデルの作業メモリ、つまりモデルが一度にどれだけのデータを記憶して処理できるか、と考えることができます。
保有するコンテキストが長くなるほど、その正確性も重要になります。長いコンテキストから物事を思い出す正確さも同様に重要であり、より多くのデータとコンテキストを考慮できるようになります。 。
つまり、100 万ということは、完全なコード ベースなど、膨大な書籍、完全な映画、膨大な量のオーディオ コンテンツを処理できることを意味します。
コンテキスト ウィンドウが短い場合 (レベルが 10 万レベルのみなど)、処理できるのはその断片のみであり、モデルは関心のあるコーパス全体について推論することができません。または検索してください。
つまり、これにより、小さなコンテキストでは実行できない、あらゆる種類の新しいユースケースの可能性が実際に開かれます。
Q: AI 研究者から、これらの大きなコンテキスト ウィンドウの問題は、計算量が非常に多いことだと聞きました。たとえば、映画や生物学の教科書全体をアップロードして、それについて質問した場合、そのすべてを処理して応答するには、より多くの処理能力が必要になります。多くの人がこれを行うと、コストがすぐに膨れ上がる可能性があります。 Google DeepMind は、これらの巨大なコンテキスト ウィンドウをより効率的にするための賢いイノベーションを思いついたのでしょうか、それとも、Google がこの余分な計算コストをすべて負担しただけなのでしょうか?
はい、これはまったく新しいイノベーションです。イノベーションがなければ、これほど長いコンテキストを維持することはできないからです。
しかし、これには依然として高い計算コストが必要なので、最適化に向けて懸命に取り組んでいます。
コンテキスト ウィンドウ全体を埋める場合。アップロードされたデータの初期処理には数分かかる場合があります。
しかし、それは、1 ~ 2 分で映画を 1 本丸ごと見るか、「戦争と平和」を丸ごと読むのと同じで、それに関する質問に答えることができると考えるのであれば、それほど悪くはありません。
次に、確認したいのは、ドキュメント、ビデオ、またはオーディオをアップロードして処理すると、その後の質問と回答がより速く行われるはずであるということです。
これが私たちが現在取り組んでいることであり、ほんの数秒で完了できると非常に自信を持っています。
Q: 最大 1,000 万のトークンを使用してシステムをテストしたとのことですが、その効果はどのようなものですか?
テストでは非常にうまく機能しました。コンピューティングコストがまだ比較的高いため、このサービスは現在利用できません。
しかし、精度と再現率の点では、非常に優れたパフォーマンスを発揮します。
Q: Gemini についてお聞きしたいのですが、以前の Google 言語モデルや他のモデルではできなかった、Gemini でできる特別なことは何ですか?
そうですね、Gemini、特にバージョン 1.5 の興味深い点は、本質的にマルチモーダルであり、あらゆる種類の入力を処理できるようにゼロから構築したことだと思います。 : テキスト、画像、コード、ビデオ。
これを長いコンテキストと組み合わせると、その可能性がわかります。たとえば、講義全体を聞いている場合、または理解したい重要な概念があるので、そこまで早送りしたい場合を想像できます。
つまり、コード ベース全体をコンテキスト ウィンドウに配置できるようになりました。これは、初心者プログラマーにとって非常に便利です。あなたが月曜日から仕事を始める新人エンジニアだとしましょう。通常、何十万行ものコードを確認する必要があります。関数にはどうやってアクセスしますか?
コードベースについては専門家に尋ねる必要があります。しかし今では、この楽しい方法で、実際に Gemini をコーディング アシスタントとして使用できるようになりました。コードの重要な部分がどこにあるかを示す概要が返されるので、作業を開始できます。
この機能があると非常に便利で、日々のワークフローがより効率的になると思います。
Slack のようなものや一般的なワークフローに統合されたときに Gemini がどのように動作するかを見るのがとても楽しみです。将来のワークフローはどのようになるのでしょうか?私たちはまだ変化を感じ始めているところだと思います。
Google のオープンソースに対する最優先事項はセキュリティです
Q: 次に、Gemma について話したいと思います。Gemma は、先ほど作成した一連の軽量オープン ソース モデルです。解放されました。現在、基盤となるモデルをオープンソースを通じてリリースするか、非公開のままにするかは、最も物議を醸すトピックの 1 つであるようです。これまでGoogleは、基礎となるモデルをクローズドソースとしてきた。なぜ今オープンソースを選択するのでしょうか?基礎となるモデルをオープンソースを通じて利用できるようにすると、悪意のある攻撃者によって使用されるリスクと可能性が高まるという批判についてはどう思いますか?
はい、私は実際にこの問題について何度も公の場で議論しました。
主な懸念の 1 つは、オープンソースとオープンリサーチ一般が明らかに有益であるということです。しかし、ここには特有の問題があり、それは AGI および AI テクノロジーに関連しています。なぜなら、それらは普遍的なものであるからです。
これらを公開すると、悪意のある攻撃者がそれらを有害な目的に使用する可能性があります。
もちろん、一度何かをオープンソースにしてしまうと、それを元に戻す実際の方法はありません。API アクセスなどとは異なり、これまで誰も有害とは考えなかったものをダウンストリームで見つけた場合、ユースケースでは、単にアクセスを遮断することができます。
これは、セキュリティ、堅牢性、説明責任のハードルがさらに高いことを意味すると思います。 AGI に近づくにつれて、AGI の機能はより強力になるため、悪意のある攻撃者によって AGI が何に使用されるかについて、より注意する必要があります。
オープンソース過激派など、オープンソースを支持する人たちから良い議論をまだ聞いたことがありません。その多くは私が尊敬する学界の同僚です。この質問にあなたはどう答えますか? 、より多くの悪意のある攻撃者がモデルにアクセスできるようにするオープン ソース モデルに対する保護と一致していますか?
これらのシステムがより強力になるにつれて、これらの問題についてさらに考える必要があります。
Q: それで、ジェマはなぜこの問題について心配しなかったのですか?

#はい、もちろん、お気づきのとおり、Gemma はライトウェイトのみを提供しています。バージョンが異なるため、比較的小さいです。
実際には、開発者にとっては小さいサイズの方が便利です。通常、個人の開発者、学者、小規模チームはラップトップで素早く作業したいため、その最適化向けに作られているからです。
これらは最先端のモデルではなく小型モデルであるため、これらのモデルの機能は厳密にテストされており、これらのモデルがどのような用途に使用できるかをよく知っているため、安心できます。このサイズのモデルでは大きなリスクはありません。
DeepMind が Google Brain と合併した理由
Q: 昨年、Google Brain と DeepMind が合併したとき、AI 業界の私の知人の何人かはこう感じました。心配。彼らは、Googleが歴史的にDeepMindに、重要と思われるさまざまな研究プロジェクトに取り組むかなりの自由を与えてきたことを懸念している。
合併により、DeepMind は、より大きな事業ではなく、短期的に Google にとって有益となる事業にリダイレクトされる必要があるかもしれません。長期にわたる基礎研究プロジェクト。合併から 1 年が経過しましたが、Google に対する短期的な関心と、長期的な AI の進歩の可能性との間の緊張によって、取り組める内容は変わりましたか?
はい、あなたがおっしゃったように、この最初の年はすべてが非常に順調でした。その理由の一つは、今が適切な時期であると考えているからであり、研究者の観点から見ても、今が適切な時期であると考えています。
おそらく 5 ~ 6 年前に戻りましょう。私たちが AI の分野で AlphaGo のようなことをしていたとき、私たちはどうすれば AGI に達するか、どのようなブレークスルーが必要か、何に賭けるべきかについて探索的な研究をしていました。 , その場合、幅広いことをやりたいので、非常に模索的な段階だと思います。
ここ 2 ~ 3 年で、前に述べたように、AGI の主なコンポーネントが何になるかが明らかになってきたと思いますが、まだ新しいイノベーションが必要です。

Gemini1.5 の長い文脈を見てきたと思いますが、そのような新しいイノベーションがたくさんあると思います。したがって、基礎研究はこれまでと同様に重要です。
しかし今、私たちはエンジニアリングの方向にも取り組む必要があり、それは既知のテクノロジーを拡張して利用し、その限界に挑戦することです。プロトタイプから製品に至るまで、大規模な非常に創造的なエンジニアリングが必要です。データセンターの規模に対するハードウェアのレベル、および関連する効率の問題。
もう 1 つの理由は、5 ~ 6 年前に AI 主導の製品を製造していた場合、AGI 研究トラックとはまったく異なる AI を構築する必要があったということです。
特定の製品の特別なシナリオでのみタスクを実行できる、カスタマイズされたAIの一種「手作りAI」です。
しかし、今日では状況が異なり、製品に AI を導入するには、複雑さと機能が十分なレベルに達しているため、一般的な AI テクノロジとシステムを使用するのが最善の方法です。
つまり、これは実際には収束点であり、研究トラックと製品トラックが統合されたことがわかります。
たとえば、これから作るのはAI音声アシスタントですが、その逆は言語を真に理解するチャットボットです。それらは統合されているので、その二項対立を考える必要はありませんまたは、緊張した関係を調整します。
2 番目の理由は、研究と実際の応用の間に緊密なフィードバック ループがあることが、実際に研究にとって非常に有益であるということです。
製品を使用するとモデルのパフォーマンスを実際に理解できるため、学術的な指標を得ることができますが、実際のテストは何百万人ものユーザーが製品を使用するときに行われます。それは役に立ちますか、役立つと思いますか、世界にとって有益だと思いますか。
明らかに多くのフィードバックが得られ、それが基礎となるモデルの非常に迅速な改善につながるため、私たちは非常にエキサイティングな状況にいると思います。今のステージ。
以上がDeepMind CEO: LLM+tree 検索は AGI テクノロジーラインです。AI 研究はエンジニアリング能力に依存しています。クローズドソース モデルはオープンソース モデルより安全です。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。