
ホームページ >テクノロジー周辺機器 >AI >大規模モデルの数学を補足するには、95 億トークンを含むオープンソースの MathPile コーパスを提出してください。これは商業的にも使用できます。
大規模モデルの数学を補足するには、95 億トークンを含むオープンソースの MathPile コーパスを提出してください。これは商業的にも使用できます。

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2024-03-01 22:31:20953ブラウズ
論文アドレス: https://huggingface.co/papers/2312.17120
プロジェクト アドレス: https://gair-nlp.github.io/MathPile/ コードアドレス: https://github.com/GAIR-NLP/MathPile
研究用途: https://huggingface.co/datasets / GAIR/MathPile 商用バージョン: https://huggingface.co/datasets/GAIR/MathPile_Commercial
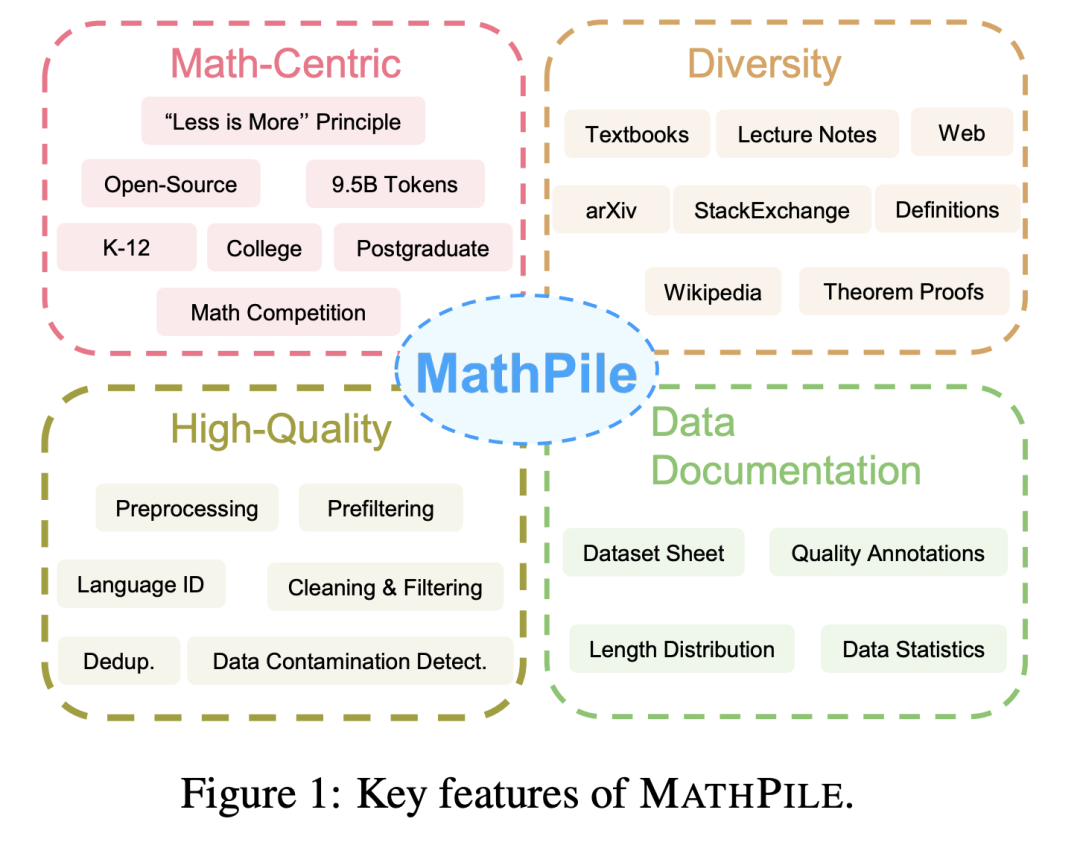
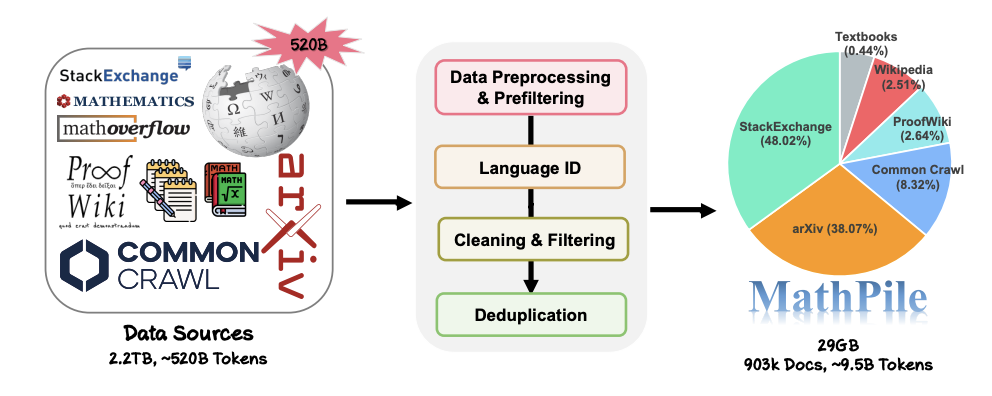
MathPile のデータ収集と処理プロセス。
- ##「lorem ipsum」を含む行を検出します。「lorem ipsum」が行内の 5 文字未満に置き換えられている場合は、その行を削除します。
- 「javascript」を含む行を検出します。 ” に「有効」、「無効」、または「ブラウザ」を含む行が含まれており、その行の文字数が 200 文字未満である場合は、その行をフィルタリングします;
- 200 文字未満をフィルタリングします。「ログイン」、「サインイン」、「続きを読む...」、または「カート内の商品」を含む 10 個の単語と行;
- フィルタ大文字の単語の割合を除外する ドキュメントの 40% 以上;
- 省略記号で終わる行がドキュメント全体の 30% 以上を占めるドキュメントをフィルタリングします;
- 文字単語の割合が 80% を超える非ドキュメントをフィルタリングします;
- 英単語の平均文字長が範囲外であるドキュメントをフィルタリングしますof (3, 10);
- 少なくとも 2 つのストップワード (the、be、to、of、that、have など) を含まないドキュメントをフィルタリングして除外します。 );
- 省略記号と単語の割合が 50% を超えるドキュメントをフィルタリングします;
- 行頭文字が黒丸であるドキュメントをフィルタリングします90% 以上を占める;
- 箇条書きで始まる行を含むドキュメントをフィルタリングする スペースと句読点を除いた 200 文字未満のドキュメント;
- ...

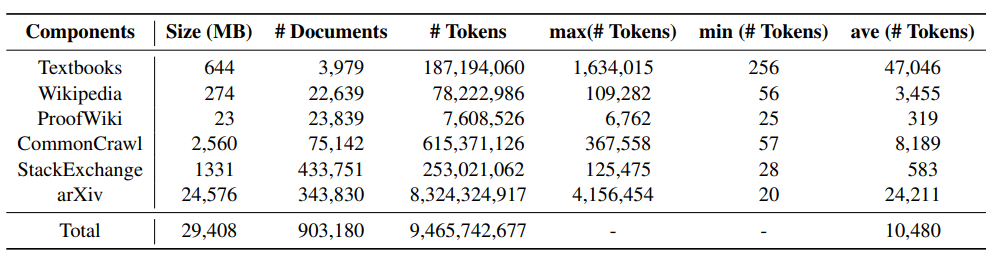
次の表は、MathPile のさまざまなコンポーネントを示しています。統計情報によると、arXiv の論文が見つかります。通常、教科書の文書の長さは長くなりますが、Wiki の文書は比較的短いです。

研究チームは、いくつかの予備的な実験結果も公開しました。彼らは、現在人気のある Mistral-7B モデルに基づいて、さらなる事前トレーニングを実行しました。次に、いくつかの一般的な数学的推論ベンチマーク データ セットに基づいて、少数ショット プロンプト手法によって評価されました。これまでに得られた予備的な実験データは次のとおりです。
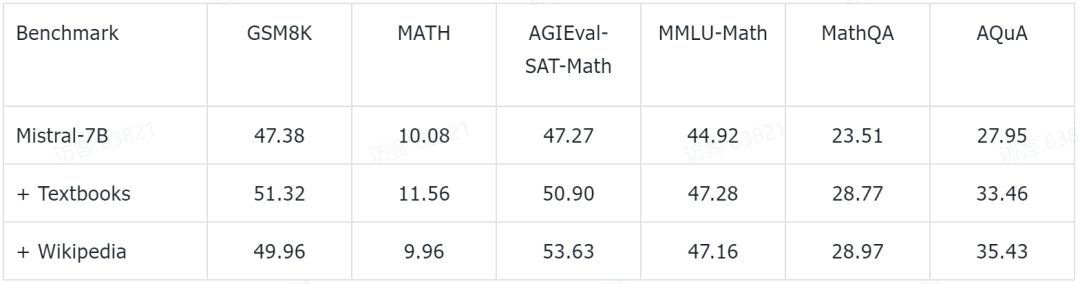 これらのテスト ベンチマークは、小学校の数学 (GSM8K、TAL など) を含む、あらゆるレベルの数学的知識をカバーします。 SCQ5K-EN および MMLU-Math)、高校数学 (MATH、SAT-Math、MMLU-Math、AQuA、MathQA など)、および大学数学 (MMLU-Math など)。研究チームが発表した予備実験結果によると、MathPileの教科書とWikipediaのサブセットで事前トレーニングを続けることで、言語モデルがさまざまな難易度で数学的推論能力の大幅な向上を達成したことが示されている。
これらのテスト ベンチマークは、小学校の数学 (GSM8K、TAL など) を含む、あらゆるレベルの数学的知識をカバーします。 SCQ5K-EN および MMLU-Math)、高校数学 (MATH、SAT-Math、MMLU-Math、AQuA、MathQA など)、および大学数学 (MMLU-Math など)。研究チームが発表した予備実験結果によると、MathPileの教科書とWikipediaのサブセットで事前トレーニングを続けることで、言語モデルがさまざまな難易度で数学的推論能力の大幅な向上を達成したことが示されている。
研究チームは、関連する実験が現在も進行中であることも強調した。 #########結論###### 

現在、MathPile はオープンソース コミュニティの研究開発に貢献することを目的として、第 2 バージョンに更新されています。同時に、商用版のデータセットも公開されました。
以上が大規模モデルの数学を補足するには、95 億トークンを含むオープンソースの MathPile コーパスを提出してください。これは商業的にも使用できます。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。