
ホームページ >テクノロジー周辺機器 >AI >大規模なマルチビュー ガウス モデル LGM: 5 秒で高品質の 3D オブジェクトを生成し、試用可能
大規模なマルチビュー ガウス モデル LGM: 5 秒で高品質の 3D オブジェクトを生成し、試用可能

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2024-02-20 15:10:19801ブラウズ
メタバースにおける 3D クリエイティブ ツールの需要の高まりに応えて、最近では 3D コンテンツ生成 (3D AIGC) に大きな関心が集まっています。同時に、3D コンテンツの作成も品質とスピードにおいて大幅な進歩を遂げました。
現在のフィードフォワード生成モデルは 3D オブジェクトを数秒で生成できますが、トレーニング中に必要な集中的な計算によって解像度が制限され、生成されるコンテンツの品質が低くなります。そこで、高解像度、高品質の 3D オブジェクトをわずか 5 秒で生成できるのかという疑問が生じます。

この記事では、北京大学、南洋理工大学 S-Lab、上海人工知能研究所の研究者が、 新しいフレームワーク LGM を提案しました。 Large Gaussian Model を使用すると、単一視点の画像やテキスト入力から、わずか 5 秒で高解像度かつ高品質の 3 次元オブジェクトを生成できます。
現在、コードとモデルの重みはオープンソースです。研究者らは、誰もが試せるオンライン デモも提供しています。

- #論文タイトル: LGM: 高解像度 3D コンテンツ作成のための大規模マルチビュー ガウス モデル
- プロジェクトのホームページ: https://me.kiui.moe/lgm/
- コード: https://github.com/3DTopia/LGM
- 論文: https://arxiv.org/abs/2402.05054
- オンライン デモ: https://huggingface.co/spaces/ashawkey/LGM
このような目標を達成するために、研究者は次の 2 つの課題に直面しています。
- 限られた計算量での効率的な 3D 表現: 既存の 3D 生成作業では、3D 表現およびレンダリング パイプラインとして 3 プレーン ベースの NeRF が使用されており、シーンの高密度モデリングとレイ トレーシング ボリューム レンダリング テクノロジが大幅に制限されています。そのトレーニング解像度 ( 128×128) を使用すると、最終的に生成されるコンテンツのテクスチャがぼやけ、品質が低下します。
- 高解像度の 3D バックボーン生成ネットワーク: 既存の 3D 生成作業では、十分な密度を確保するためにバックボーン ネットワークとして高密度トランスを使用しています。パラメータは普遍的なオブジェクトをモデル化するために使用されますが、これによりトレーニングの解像度がある程度犠牲になり、最終的な 3 次元オブジェクトの品質が低下します。
この目的のために、この論文では、4 視点画像から高解像度の 3 次元表現を合成する新しい方法を提案します。高品質の Text-to-3D および Image-to-3D タスクをサポートするための画像からマルチパースペクティブ画像モデルへの変換。
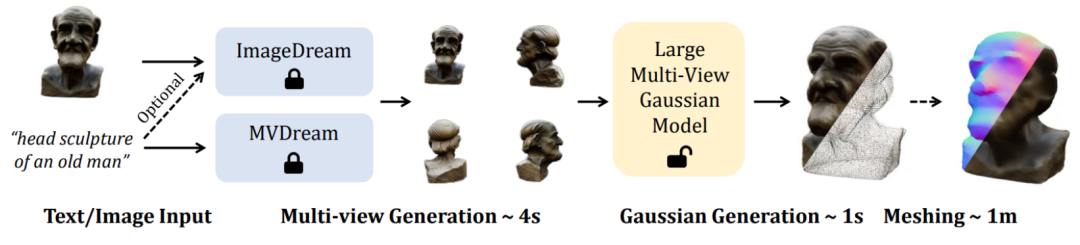
LGM コア モジュールは大規模マルチビュー ガウス モデル です。ガウス スパッタリングからインスピレーションを得たこの方法では、バックボーン ネットワークとして効率的で軽量な非対称 U-Net を使用して、4 視点画像から高解像度のガウス プリミティブを直接予測し、最終的に任意の視野角からの画像をレンダリングします。
具体的には、バックボーン ネットワーク U-Net は 4 つの視点からの画像と対応するプラッカー座標を受け取り、複数の視点から固定数のガウス特徴を出力します。このガウス特徴のセットは最終的なガウス要素に直接融合され、微分可能なレンダリングを通じてさまざまな視野角からの画像が取得されます。このプロセスでは、クロスビュー セルフ アテンション メカニズムを使用して、計算オーバーヘッドを低く抑えながら、低解像度フィーチャ マップ上の異なるビュー間の相関モデリングを実現します。
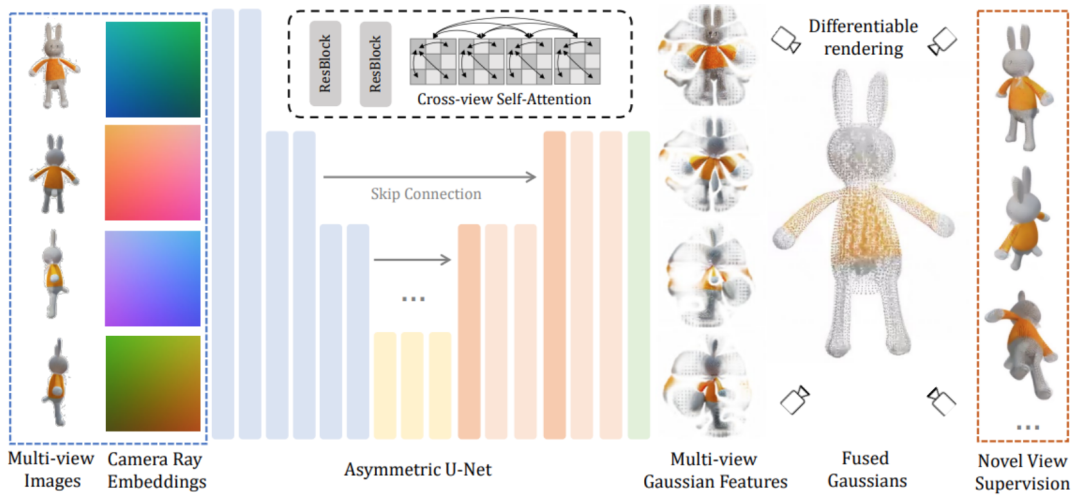
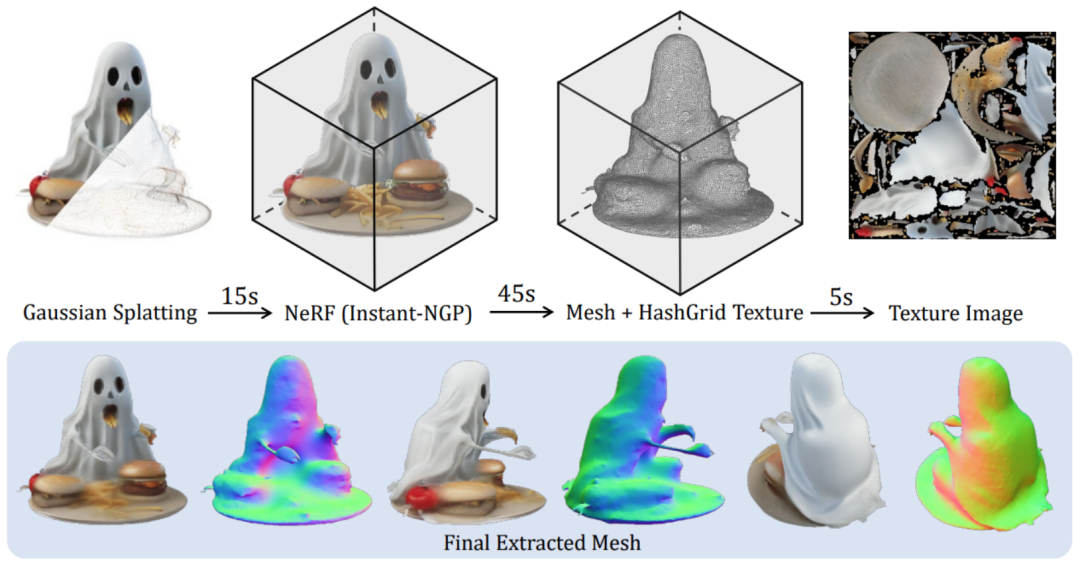
まず、オブジャバース データセットでレンダリングされた 3 次元の一貫したマルチビュー画像がトレーニング フェーズで使用されます。一方、推論フェーズでは、既存のモデルを直接使用してテキストやテキストからマルチパースペクティブ画像を合成します。画像。モデルに基づいて合成された多視点画像には常に多視点の不一致の問題があるため、この領域のギャップを埋めるために、 この記事では、グリッドの歪みに基づいたデータ拡張戦略を提案します。 3 つの視点からの画像は、マルチビューの不一致をシミュレートするためにランダムな歪みを適用します。 2 番目の理由は、推論段階で生成された多視点画像は、カメラ視点の 3 次元ジオメトリの一貫性を厳密に保証していないため、 この記事また、3 つの視点からカメラのポーズをランダムに摂動させます。この現象をシミュレートするには、推論段階でモデルをより堅牢にします。 最後に、生成されたガウス プリミティブは微分可能レンダリングを通じて対応する画像にレンダリングされ、教師あり学習を通じて 2 次元画像上でエンドツーエンドで直接学習されます。 トレーニングが完了すると、LGM は既存の image-to-multiview または text-to-multi を通じて、高品質の Text-to-3D および Image-to-3D を実現できます。 -拡散モデルを表示するタスク。 同じ入力テキストまたは画像を指定すると、この方法ではさまざまな高品質の 3D モデルを生成できます。 下流のグラフィックス タスクをさらにサポートするために、研究者らは、生成されたガウス表現を滑らかで縞模様の表現に変換する効率的な方法も提案しました。テクスチャ メッシュ: 詳細については、元の論文を参照してください。 

以上が大規模なマルチビュー ガウス モデル LGM: 5 秒で高品質の 3D オブジェクトを生成し、試用可能の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。