
ホームページ >テクノロジー周辺機器 >AI >自然言語生成タスクと Pytorch コード実装における 5 つのサンプリング方法の紹介
自然言語生成タスクと Pytorch コード実装における 5 つのサンプリング方法の紹介

- WBOY転載
- 2024-02-20 08:50:031091ブラウズ
自然言語生成タスクにおいて、サンプリング法は生成モデルからテキスト出力を取得する手法です。この記事では、5 つの一般的なメソッドについて説明し、PyTorch を使用してそれらを実装します。
1. 貪欲デコード
貪欲デコードでは、生成モデルは入力シーケンスに基づいて出力シーケンスの単語を時間ごとに予測します。各タイム ステップで、モデルは各単語の条件付き確率分布を計算し、最も高い条件付き確率を持つ単語を現在のタイム ステップの出力として選択します。このワードは次のタイム ステップへの入力となり、指定された長さのシーケンスや特別な終了マーカーなど、何らかの終了条件が満たされるまで生成プロセスが続行されます。 Greedy Decoding の特徴は、大域的な最適解を考慮せずに、現在の条件付き確率が最も高い単語が毎回出力として選択されることです。この方法はシンプルで効率的ですが、生成されるシーケンスの精度や多様性が低くなる可能性があります。 Greedy Decoding は一部の単純なシーケンス生成タスクには適していますが、複雑なタスクの場合は、生成の品質を向上させるためにより複雑なデコード戦略が必要になる場合があります。
この方法は計算が高速ですが、貪欲なデコードは局所的な最適解のみに焦点を当てるため、生成されるテキストが多様性に欠けたり、不正確になったりして、大域的な最適解が得られない可能性があります。
貪欲なデコードには制限がありますが、特に高速な実行が必要な場合やタスクが比較的単純な場合には、多くのシーケンス生成タスクで広く使用されています。
def greedy_decoding(input_ids, max_tokens=300): with torch.inference_mode(): for _ in range(max_tokens): outputs = model(input_ids) next_token_logits = outputs.logits[:, -1, :] next_token = torch.argmax(next_token_logits, dim=-1) if next_token == tokenizer.eos_token_id: break input_ids = torch.cat([input_ids, rearrange(next_token, 'c -> 1 c')], dim=-1) generated_text = tokenizer.decode(input_ids[0]) return generated_text
2. ビーム サーチ
ビーム サーチは貪欲デコードの拡張であり、各タイム ステップで複数の候補シーケンスを保持することで克服されます。デコード中。
ビーム検索は、各タイム ステップで最も高い確率で候補単語を保持し、次のタイム ステップでこれらの候補単語に基づいて生成が終了するまで拡張し続けるテキストを生成する方法です。この方法では、複数の単語パス候補を考慮することで、生成されるテキストの多様性を向上させることができます。
ビーム探索では、モデルは 1 つの最良のシーケンスを選択するのではなく、複数の候補シーケンスを同時に生成します。現在生成されている部分シーケンスと隠れ状態に基づいて、次のタイム ステップで考えられる単語を予測し、各単語の条件付き確率分布を計算します。複数の候補シーケンスを並行して生成するこの方法は、検索効率の向上に役立ち、モデルが全体の確率が最も高いシーケンスをより迅速に見つけることができます。
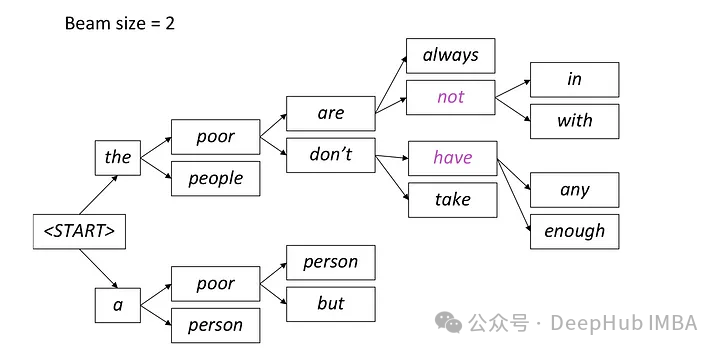
各ステップでは、最も可能性の高い 2 つのパスのみが保持され、残りのパスはビーム = 2 の設定に従って破棄されます。このプロセスは、シーケンス終了トークンを生成するか、モデルによって設定された最大シーケンス長に達することによって、停止条件が満たされるまで継続します。最終出力は、パスの最後のセットの中で全体の確率が最も高いシーケンスになります。
from einops import rearrange import torch.nn.functional as F def beam_search(input_ids, max_tokens=100, beam_size=2): beam_scores = torch.zeros(beam_size).to(device) beam_sequences = input_ids.clone() active_beams = torch.ones(beam_size, dtype=torch.bool) for step in range(max_tokens): outputs = model(beam_sequences) logits = outputs.logits[:, -1, :] probs = F.softmax(logits, dim=-1) top_scores, top_indices = torch.topk(probs.flatten(), k=beam_size, sorted=False) beam_indices = top_indices // probs.shape[-1] token_indices = top_indices % probs.shape[-1] beam_sequences = torch.cat([ beam_sequences[beam_indices], token_indices.unsqueeze(-1)], dim=-1) beam_scores = top_scores active_beams = ~(token_indices == tokenizer.eos_token_id) if not active_beams.any(): print("no active beams") break best_beam = beam_scores.argmax() best_sequence = beam_sequences[best_beam] generated_text = tokenizer.decode(best_sequence) return generated_text3. 温度サンプリング
温度パラメーター サンプリング (温度サンプリング) は、言語モデルなどの確率ベースの生成モデルでよく使用されます。 「温度」と呼ばれるパラメータを導入してモデル出力の確率分布を調整することで、生成されるテキストの多様性を制御します。
温度パラメーター サンプリングでは、モデルが各タイム ステップで単語を生成するときに、単語の条件付き確率分布が計算されます。次にモデルは、この条件付き確率分布内の各単語の確率値を温度パラメーターで除算し、結果を正規化し、新しい正規化された確率分布を取得します。温度の値が高いほど確率分布が滑らかになり、生成されるテキストの多様性が高まります。確率の低い単語も選択される確率が高くなりますが、温度値が低いほど確率分布がより集中し、確率の高い単語が選択される可能性が高くなるため、生成されるテキストはより決定的になります。最後に、モデルはこの新しい正規化された確率分布に従ってランダムにサンプリングし、生成された単語を選択します。
import torch import torch.nn.functional as F def temperature_sampling(logits, temperature=1.0): logits = logits / temperature probabilities = F.softmax(logits, dim=-1) sampled_token = torch.multinomial(probabilities, 1) return sampled_token.item()
4. 上位 K サンプリング
上位 K サンプリング (各タイム ステップで条件付き確率ランキングを使用して上位 K 語を選択し、次に上位 K 語を選択します)この K 語の中の単語をランダムにサンプリングすることで、一定の生成品質を維持できるだけでなく、テキストの多様性を高めることができ、候補単語数を制限することで生成されるテキストの多様性を制御することができます。
このプロセスにより生成が行われます 一定の生成品質を維持しながら、候補単語間である程度の競合が存在するため、テキストにはある程度の多様性が生まれます。 ##パラメータ K は、各タイム ステップで保持する候補単語の数を制御します。K 値が小さいほど、ランダム サンプリングに参加する単語が少ないため、より貪欲な動作につながります。一方、K 値が大きいほど、多様性が増加します。生成されたテキストの量が減りますが、計算オーバーヘッドも増加します。def top_k_sampling(input_ids, max_tokens=100, top_k=50, temperature=1.0):for _ in range(max_tokens): with torch.inference_mode(): outputs = model(input_ids) next_token_logits = outputs.logits[:, -1, :] top_k_logits, top_k_indices = torch.topk(next_token_logits, top_k) top_k_probs = F.softmax(top_k_logits / temperature, dim=-1) next_token_index = torch.multinomial(top_k_probs, num_samples=1) next_token = top_k_indices.gather(-1, next_token_index) input_ids = torch.cat([input_ids, next_token], dim=-1) generated_text = tokenizer.decode(input_ids[0]) return generated_text
5、Top-P (Nucleus) Sampling:
Nucleus Sampling(核采样),也被称为Top-p Sampling旨在在保持生成文本质量的同时增加多样性。这种方法可以视作是Top-K Sampling的一种变体,它在每个时间步根据模型输出的概率分布选择概率累积超过给定阈值p的词语集合,然后在这个词语集合中进行随机采样。这种方法会动态调整候选词语的数量,以保持一定的文本多样性。

在Nucleus Sampling中,模型在每个时间步生成词语时,首先按照概率从高到低对词汇表中的所有词语进行排序,然后模型计算累积概率,并找到累积概率超过给定阈值p的最小词语子集,这个子集就是所谓的“核”(nucleus)。模型在这个核中进行随机采样,根据词语的概率分布来选择最终输出的词语。这样做可以保证所选词语的总概率超过了阈值p,同时也保持了一定的多样性。
参数p是Nucleus Sampling中的重要参数,它决定了所选词语的概率总和。p的值会被设置在(0,1]之间,表示词语总概率的一个下界。
Nucleus Sampling 能够保持一定的生成质量,因为它在一定程度上考虑了概率分布。通过选择概率总和超过给定阈值p的词语子集进行随机采样,Nucleus Sampling 能够增加生成文本的多样性。
def top_p_sampling(input_ids, max_tokens=100, top_p=0.95): with torch.inference_mode(): for _ in range(max_tokens): outputs = model(input_ids) next_token_logits = outputs.logits[:, -1, :] sorted_logits, sorted_indices = torch.sort(next_token_logits, descending=True) sorted_probabilities = F.softmax(sorted_logits, dim=-1) cumulative_probs = torch.cumsum(sorted_probabilities, dim=-1) sorted_indices_to_remove = cumulative_probs > top_p sorted_indices_to_remove[..., 0] = False indices_to_remove = sorted_indices[sorted_indices_to_remove] next_token_logits.scatter_(-1, indices_to_remove[None, :], float('-inf')) probs = F.softmax(next_token_logits, dim=-1) next_token = torch.multinomial(probs, num_samples=1) input_ids = torch.cat([input_ids, next_token], dim=-1) generated_text = tokenizer.decode(input_ids[0]) return generated_text总结
自然语言生成任务中,采样方法是非常重要的。选择合适的采样方法可以在一定程度上影响生成文本的质量、多样性和效率。上面介绍的几种采样方法各有特点,适用于不同的应用场景和需求。
贪婪解码是一种简单直接的方法,适用于速度要求较高的情况,但可能导致生成文本缺乏多样性。束搜索通过保留多个候选序列来克服贪婪解码的局部最优问题,生成的文本质量更高,但计算开销较大。Top-K 采样和核采样可以控制生成文本的多样性,适用于需要平衡质量和多样性的场景。温度参数采样则可以根据温度参数灵活调节生成文本的多样性,适用于需要平衡多样性和质量的任务。
以上が自然言語生成タスクと Pytorch コード実装における 5 つのサンプリング方法の紹介の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。