
ホームページ >テクノロジー周辺機器 >AI >RNNモデルがトランスフォーマーの覇権に挑戦! Mistral-7B と同等の 1% のコストとパフォーマンス、世界最多の 100 以上の言語をサポート
RNNモデルがトランスフォーマーの覇権に挑戦! Mistral-7B と同等の 1% のコストとパフォーマンス、世界最多の 100 以上の言語をサポート

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2024-02-19 21:30:39967ブラウズ
大型モデルが投入される一方で、トランスフォーマーの地位も次々と挑戦されています。
最近、RWKV は、最新の RWKV-v5 アーキテクチャに基づいた Eagle 7B モデルをリリースしました。
Eagle 7B は多言語ベンチマークで優れており、英語テストではトップ モデルと同等の成績を収めています。
同時に、Eagle 7B は RNN アーキテクチャを使用しており、同じサイズの Transformer モデルと比較して、推論コストが 10 ~ 100 倍以上削減されます。世界で最も環境に優しい7Bと言われるモデル。
RWKV-v5 の論文は来月までリリースされない可能性があるため、最初に RWKV の論文を提供します。これは、パラメータを数百億まで拡張する初の非 Transformer アーキテクチャです。
 写真
写真
論文アドレス: https://arxiv.org/pdf/2305.13048.pdf
この作品は EMNLP 2023 に採択されました。著者は世界中の一流の大学、研究機関、テクノロジー企業の出身です。
以下はイーグル 7B の公式写真で、イーグルがトランスフォーマーの上を飛んでいる様子を示しています。
 写真
写真
Eagle 7B
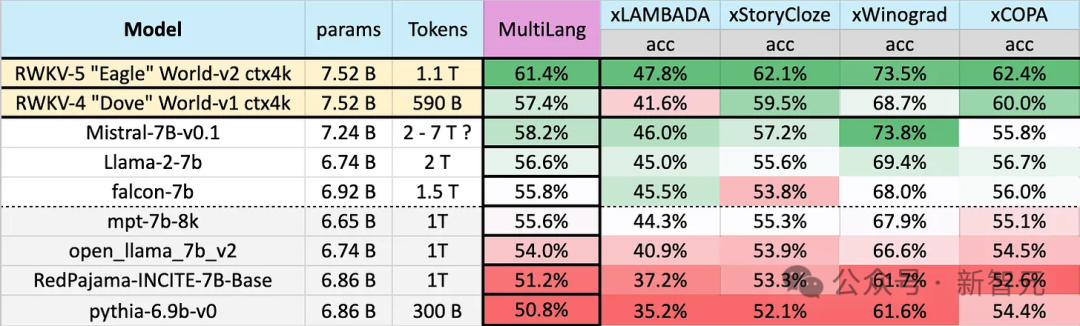
Eagle 7B は 100 以上の言語で利用可能ですEagle 7B は、1.1T (兆) の Token トレーニング データにより、以下の多言語ベンチマーク テストの平均スコアで 1 位にランクされています。
ベンチマークには、xLAMBDA、xStoryCloze、xWinograd、xCopa が含まれており、23 の言語と、それぞれの言語での常識的な推論をカバーしています。
Eagle 7B は 3 試合で 1 位を獲得し、そのうち 1 試合は Mistral-7B に勝てず 2 位でしたが、相手が使用した学習データは Eagle をはるかに上回っていました。
 写真
写真
下の写真の英語テストには、12 の個別のベンチマーク、常識的推論、および世界の知識が含まれています。
英語のパフォーマンステストでは、Eagle 7B のレベルは Falcon (1.5T)、LLaMA2 (2T)、Mistral (>2T) に近く、同様に約 1T のトレーニングを使用します。 MPT-7B と同等のデータです。
 写真
写真
両方のテストにおいて、新しい v5 アーキテクチャは、以前の v4 の全体的な進歩と比較して大幅に改善されています。
Eagle 7B は現在、Linux Foundation によってホストされており、Apache 2.0 ライセンスに基づいて無制限の個人使用または商用使用が許可されています。
多言語サポート
前述したように、Eagle 7B のトレーニング データは 100 以上の言語から提供されており、4 つの多言語サポートは上記で使用されている言語 ベンチマークには 23 言語のみが含まれていました。
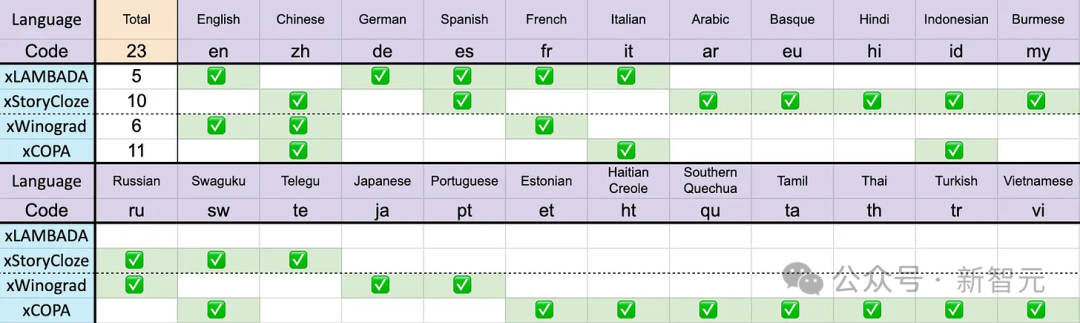 写真
写真
1位を獲得したものの、総合的にはイーグル7Bが負けを喫し、結局ベンチマークを直接行うことはできません他の 70 以上の言語でモデルのパフォーマンスを評価します。
追加のトレーニング費用はランキングの向上に役立ちません。英語に集中すれば、今よりも良い結果が得られるかもしれません。
——それでは、なぜ RWKV はこのようなことを行ったのでしょうか?関係者は次のように述べました:
#英語だけでなく、この世界のすべての人のための包括的な AI を構築
##RWKV に関する多数のフィードバックに応えてモデルの中で最も一般的なものは次のとおりです:
多言語アプローチはモデルの英語評価スコアに悪影響を及ぼし、線形 Transformer の開発を遅らせます。
# # 多言語モデルの多言語パフォーマンスを英語のみのモデルと比較するのは不公平です
当局者は「ほとんどの場合、私たちはこれらの意見に同意します」と述べました。 #
「しかし、それを変える計画はありません。なぜなら、私たちは世界のために人工知能を構築しているからです。そして、それは英語圏だけの世界ではありません。」
 Picture
Picture
2023 年には、世界人口の 17% (約 13 億人) だけが英語を話すことになりますが、世界の上位 25 言語をサポートすることで、このモデルは、世界の総人口の 50% に相当する約 400 億人をカバーできます。
チームは、より多くの言語をサポートするなど、モデルを低価格でローエンドのハードウェアで実行できるようにするなど、将来の人工知能がすべての人を助けることができるようになることを望んでいます。
チームは、より広範囲の言語をサポートするために多言語データ セットを徐々に拡張し、対象言語を世界の 100% の地域に徐々に拡大します。取り残された。
#データ セットのスケーラブルなアーキテクチャ
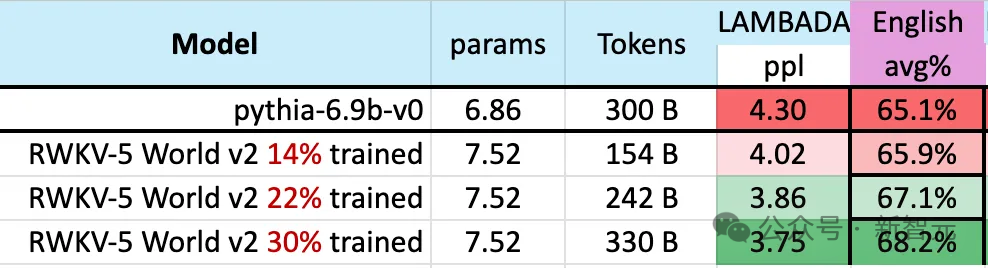
モデルのトレーニング プロセス中に、注目に値する現象があります:
トレーニング データのサイズが増加し続けると、モデルのパフォーマンスは徐々に向上します。トレーニング データが約 300B に達すると、モデルは pythia-6.9b のトレーニング データ量が 300B であるのに対し、同等のパフォーマンスを示します。 。
 写真
写真
この現象は、RWKV-v4 アーキテクチャで行われた以前の実験と同じです。トレーニング データのサイズが同じ場合、RWKV のような線形 Transformer のパフォーマンスは Transformer のパフォーマンスと同様になります。
それでは、これが本当に当てはまるのであれば、モデルのパフォーマンス向上にとって正確なアーキテクチャよりもデータの方が重要なのではないかと問わずにはいられません。
 図
図
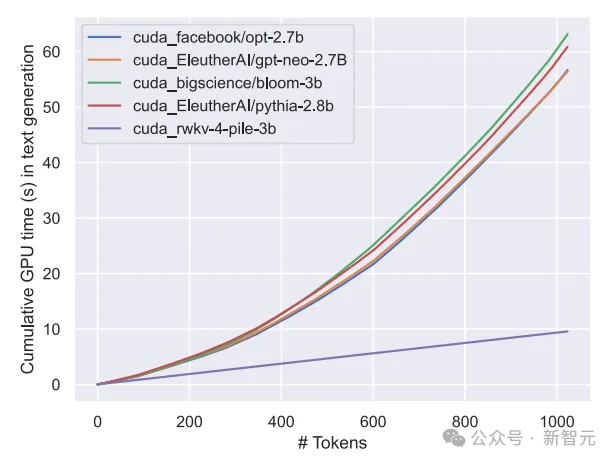
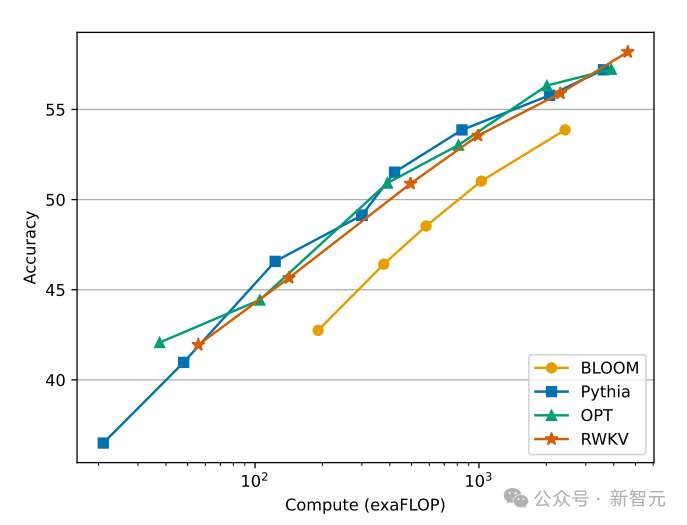
Transformer クラス モデルの計算とストレージのコストは平方であることがわかっており、上の図ではRWKV アーキテクチャの計算コストは、トークンの数に応じて直線的に増加するだけです。
おそらく、私たちはアクセシビリティを高め、すべての人にとって AI のコストを下げ、環境への影響を軽減する、より効率的でスケーラブルなアーキテクチャを追求する必要があるでしょう。
RWKV
RWKV アーキテクチャは、GPT レベルの LLM パフォーマンスを備えた RNN であり、同時に Transformer のように並列トレーニングできます。 。
RWKV は、RNN と Transformer の利点 (優れたパフォーマンス、高速推論、高速トレーニング、VRAM 節約、「無制限」のコンテキスト長、自由な文の埋め込み) を組み合わせています。RWKV はアテンション メカニズムを使用しません。
次の図は、RWKV モデルと Transformer モデルの計算コストの比較を示しています:
 図
図
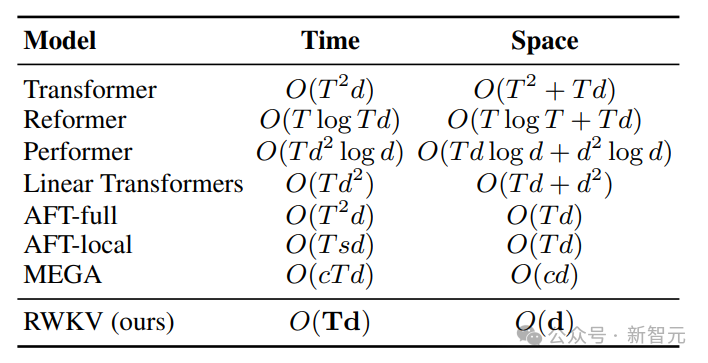
#Transformer の時間と空間の複雑さの問題を解決するために、研究者はさまざまなアーキテクチャを提案しました。 #RWKV アーキテクチャは、スタックされた一連の残差ブロックで構成され、各残差ブロックはループ構造を備えた時間ミキシングとチャネル ミキシング サブブロックで構成されます
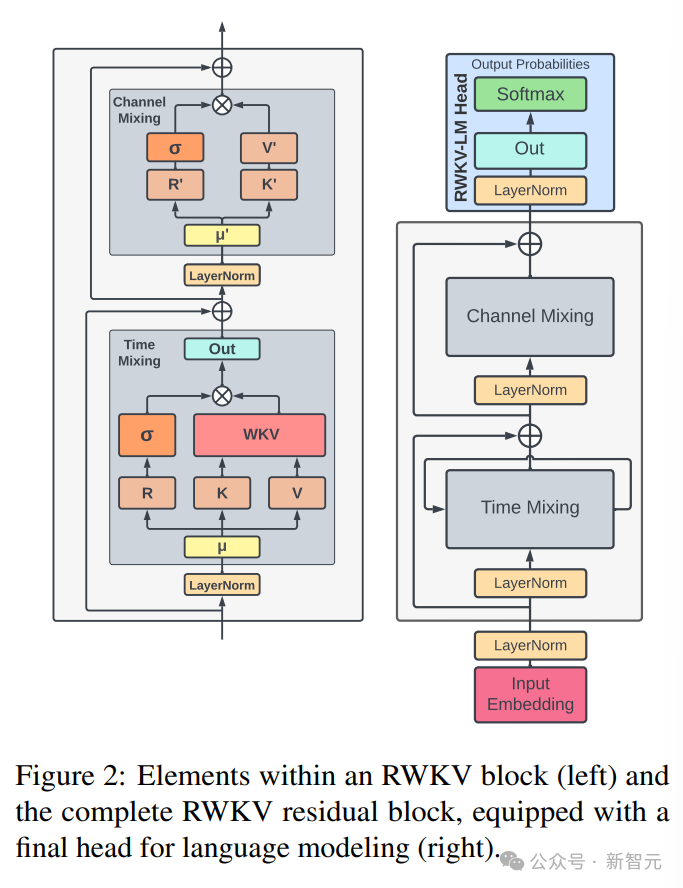
 図では左側に RWKV ブロック要素、右側に RWKV 残差ブロック、そして言語モデリングの最終ヘッダーの下にあります。
図では左側に RWKV ブロック要素、右側に RWKV 残差ブロック、そして言語モデリングの最終ヘッダーの下にあります。
図
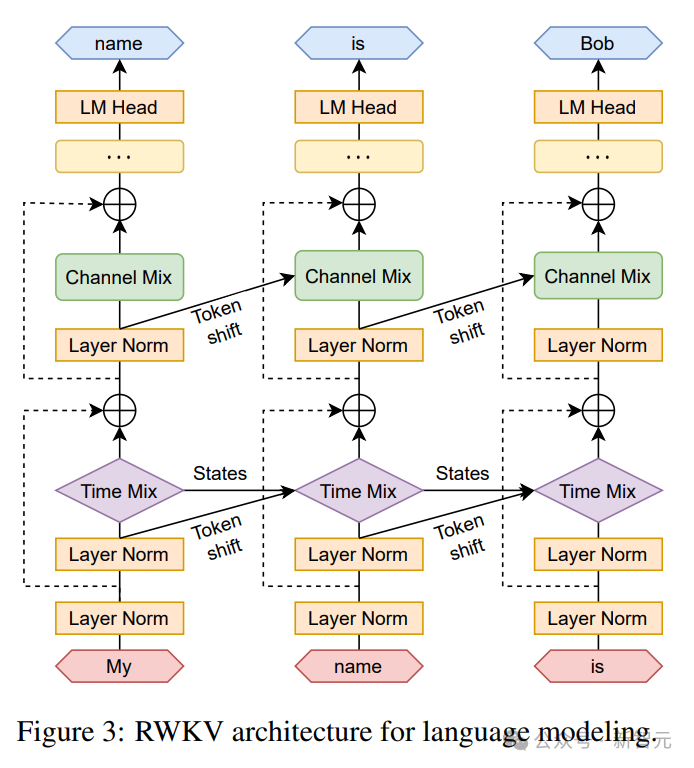
再帰は、現在の入力と前のタイム ステップの入力の間の線形補間として表現できます (図を参照)下の図の ) は、入力エンベディングの線形投影ごとに個別に調整できます。
 現在のトークンを個別に処理するベクトルも、潜在的な劣化を補うためにここで導入されています。
現在のトークンを個別に処理するベクトルも、潜在的な劣化を補うためにここで導入されています。
 図
図
RWKV は、いわゆる時間並列モードで効率的に並列化 (行列乗算) できます。
リカレント ネットワークでは、通常、前の瞬間の出力が現在の瞬間の入力として使用されます。これは、言語モデルの自己回帰復号推論で特に顕著であり、次のステップを入力する前に各トークンを計算する必要があるため、RWKV は時間モードと呼ばれる RNN のような構造を利用できます。
この場合、RWKV は推論中のデコード用に再帰的に定式化することができ、最新の状態のみに依存する各出力トークンを利用します。状態のサイズはシーケンスに関係なく一定です。長さ。
その後、RNN デコーダとして機能し、シーケンスの長さに応じて一定の速度とメモリ フットプリントを実現し、より長いシーケンスをより効率的に処理できるようにします。
対照的に、self-attention の KV キャッシュはシーケンスの長さに比べて継続的に増加するため、シーケンスが長くなるにつれて効率が低下し、メモリ使用量と時間が増加します。
#参考:
#以上がRNNモデルがトランスフォーマーの覇権に挑戦! Mistral-7B と同等の 1% のコストとパフォーマンス、世界最多の 100 以上の言語をサポートの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。