
ホームページ >テクノロジー周辺機器 >AI >Google が新しい RLHF 手法を提案: 報酬モデルを排除し、敵対的トレーニングの必要性を排除
Google が新しい RLHF 手法を提案: 報酬モデルを排除し、敵対的トレーニングの必要性を排除

- PHPz転載
- 2024-02-15 19:00:191444ブラウズ
効果はより安定しており、実装はより簡単です。




この研究では、現実的な選好関数を使用して一連の連続制御タスクを実行しました。上記により、SPO は報酬モデルに基づく方法よりも優れたパフォーマンスを発揮することが証明されています。 SPO は、以下の図 2 に示すように、さまざまな設定で報酬モデルベースの方法よりも効率的にサンプルを学習できます。
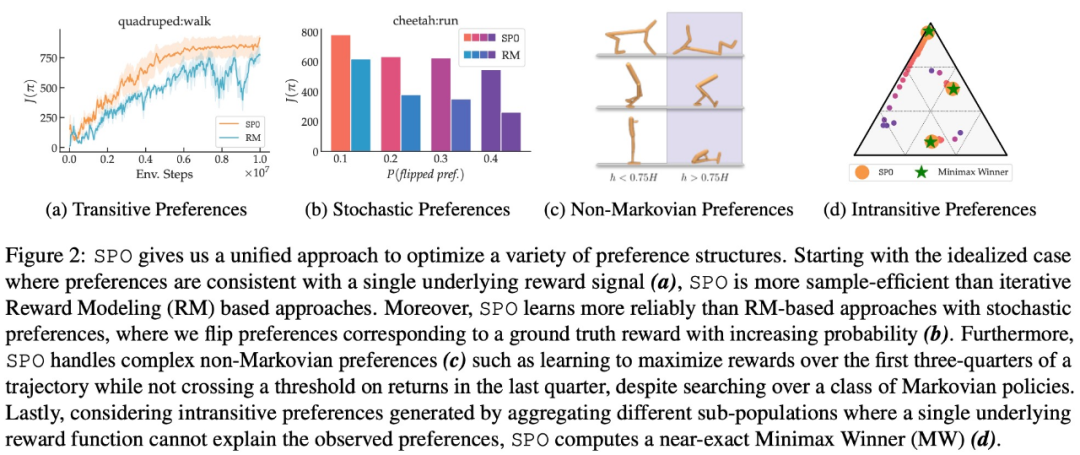
 この研究では、SPO と複数のディメンション A からの反復報酬モデリング (RM) 手法を組み合わせています。比較は 4 つの質問に答えるために行われます:
この研究では、SPO と複数のディメンション A からの反復報酬モデリング (RM) 手法を組み合わせています。比較は 4 つの質問に答えるために行われます:
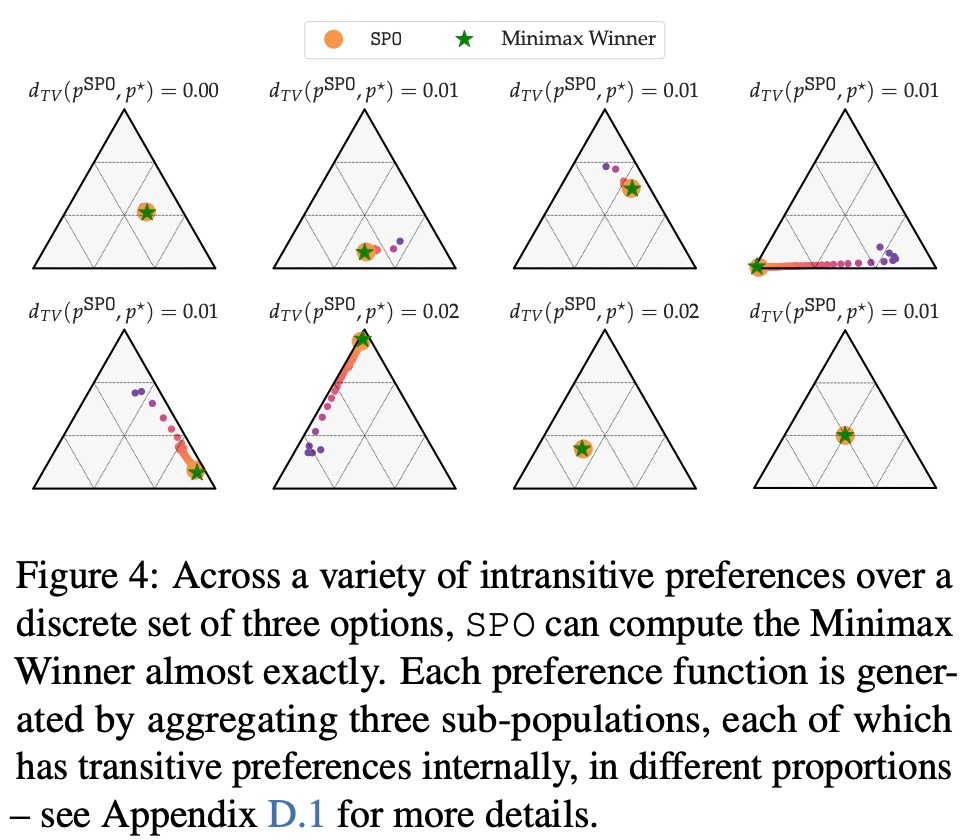
- 自動詞の好みに直面した場合、SPO は MW を計算できますか?
- SPO は、独自の Copeland Winners/最適戦略の問題で RM サンプル効率と同等またはそれを超えることができますか?
- SPO はランダムな設定に対してどの程度堅牢ですか?
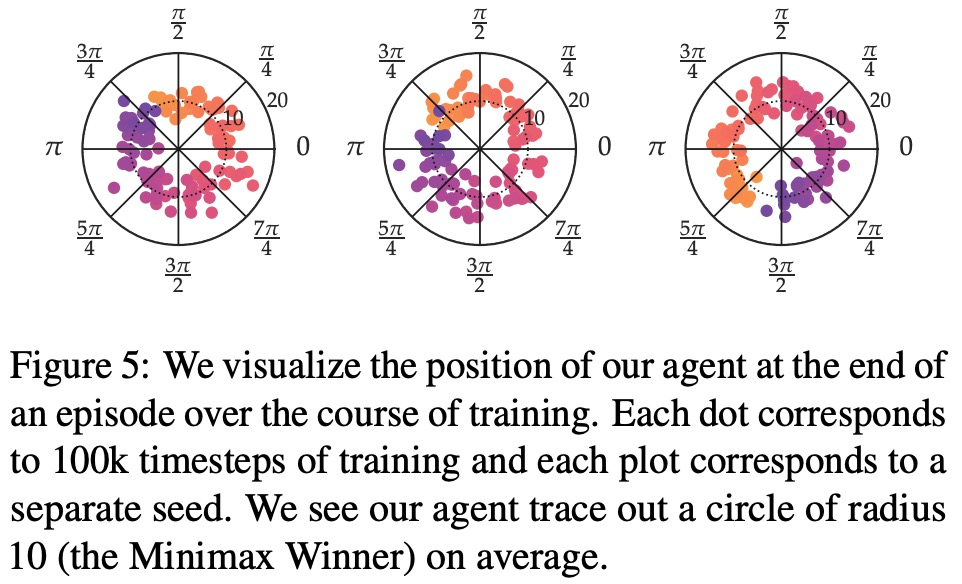
- SPO は非マルコフ選好を処理できますか?
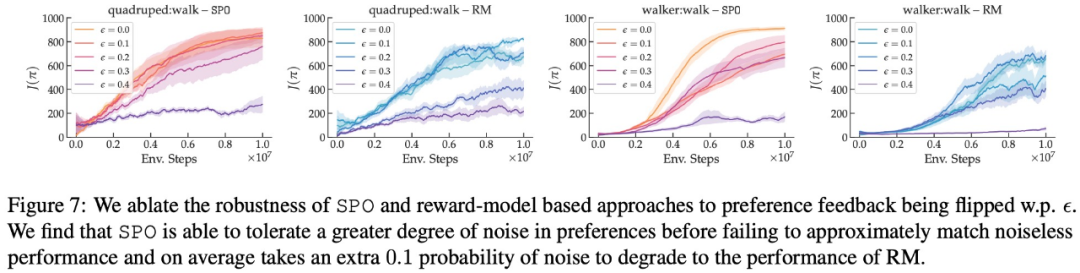
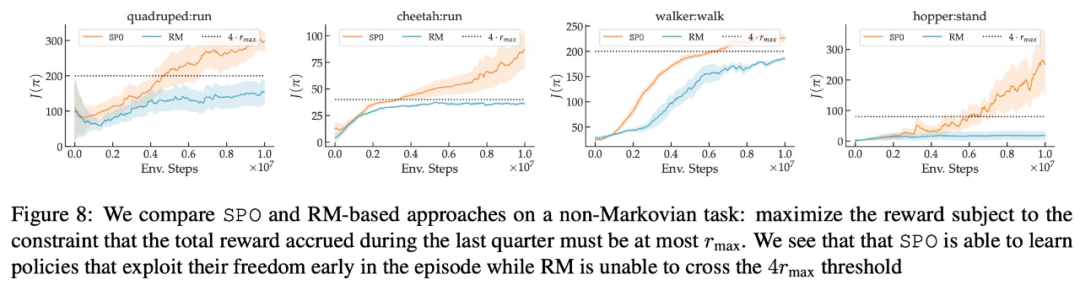
 最大報酬選好、ノイズ選好、および非マルコフ選好に関して、この研究の実験結果を図 6、7 に示します。 、および 8 はそれぞれ以下に表示されます。
最大報酬選好、ノイズ選好、および非マルコフ選好に関して、この研究の実験結果を図 6、7 に示します。 、および 8 はそれぞれ以下に表示されます。
以上がGoogle が新しい RLHF 手法を提案: 報酬モデルを排除し、敵対的トレーニングの必要性を排除の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
声明:
この記事はjiqizhixin.comで複製されています。侵害がある場合は、admin@php.cn までご連絡ください。