
ホームページ >システムチュートリアル >Linux >Linux システムの CPU は 100% 使用されています。
Linux システムの CPU は 100% 使用されています。

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2024-02-13 23:27:121314ブラウズ
昨日の午後、運用保守部門から突然、データプラットフォームサーバーのCPU使用率が98.94%にも達しているというアラートメールが届きました。最近ではこの稼働率が70%を超える状態が続いています。一見すると、ハードウェア リソースがボトルネックに達しており、拡張する必要があるように見えます。しかし、よく考えてみると、私たちのビジネス システムは同時実行性や CPU 負荷が高いアプリケーションではないことがわかりました。この使用率は誇張されすぎており、ハードウェアのボトルネックにそれほど早く到達することはできません。ビジネスコードのロジックのどこかに問題があるはずです。
2. トラブルシューティングのアイデア
2.1 高負荷プロセスの pid を特定する
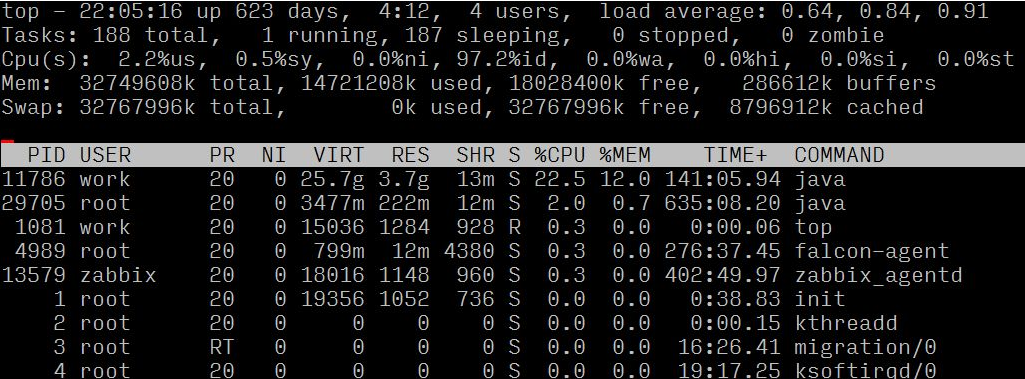
まずサーバーにログインし、topコマンドでサーバーの具体的な状況を確認し、具体的な状況に基づいて分析・判断してください。

負荷平均と負荷評価基準 (8 コア) を観察することで、サーバーが高負荷であることを確認できます;
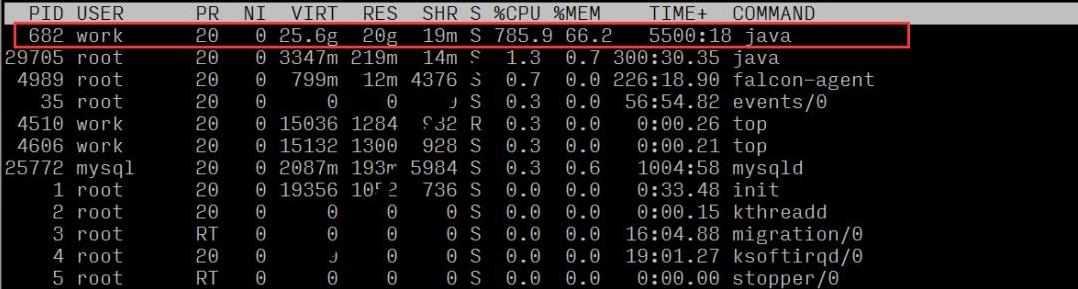
各プロセスのリソース使用量を観察すると、プロセス ID 682 のプロセスの CPU 比率が高いことがわかります。
2.2 特定の異常なビジネスを特定する
ここでは、pwdx コマンドを使用して、pid に基づいてビジネス プロセス パスを検索し、担当者とプロジェクトを特定できます。

このプロセスはデータ プラットフォームの Web サービスに相当すると結論付けることができます。
2.3 異常なスレッドと特定のコード行を特定する
従来のソリューションは通常 4 つのステップです:
1. top oder by with P:1040 //まずプロセス負荷でソートし、maxLoad(pid)を見つけます
2. top -Hp process PID: 1073 // 関連するロード スレッド PID を検索します。
3. printf "0x%x" Thread PID: 0x431 // 後で jstack ログを検索できるように準備するために、スレッド PID を 16 進数に変換します。 4. jstack プロセス PID | vim /hex スレッド PID – // 例: jstack 1040|vim /0x431 –
しかし、オンラインで問題を特定するには、一秒一秒が重要であり、上記の 4 つの手順は依然として面倒で時間がかかります。以前に淘宝網を紹介した Oldratlee は、上記のプロセスを show-busy-java-threads というツールにカプセル化しました。ああ、この種の問題はオンラインで簡単に見つけることができます:
システム内のタイム ツール メソッドの実行 CPU が比較的高いと結論付けることができます。特定のメソッドを特定した後、コード ロジックにパフォーマンスの問題があるかどうかを確認してください。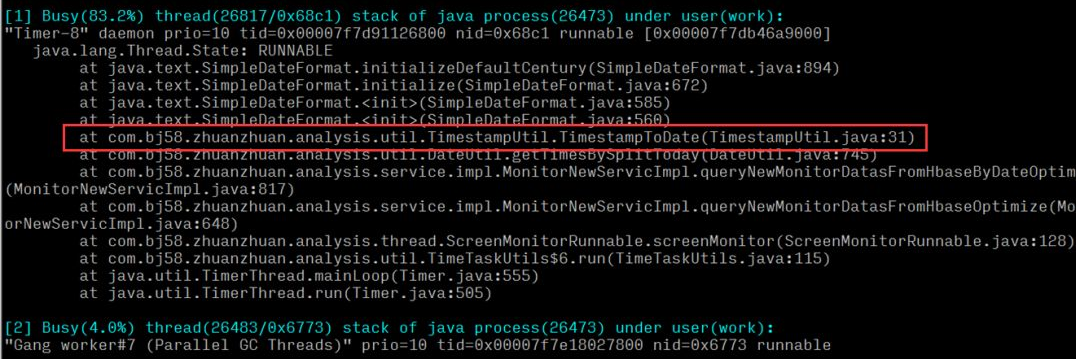
# オンラインの問題がより緊急である場合は、2.1 と 2.2 を省略して 2.3 を直接実行できます。ここでの分析は、完全な分析アイデアを提供するために複数の角度から行われています。
3. 根本原因の分析 前回の分析とトラブルシューティングの後、最終的に、過度のサーバー負荷と CPU 使用率を引き起こす時間ツールの問題を特定しました。
- 例外メソッドのロジック: は、タイムスタンプを対応する特定の日付と時刻の形式に変換することです。
- 上位層の呼び出し: 早朝から現在時刻までのすべての秒を計算し、対応する形式に変換してセットに入れて結果を返します;
- ロジック層: データ プラットフォームのリアルタイム レポートのクエリ ロジックに対応します。リアルタイム レポートは一定の時間間隔で送信され、1 回のメソッドで複数 (n) のメソッド呼び出しが行われます。クエリ。
現在時刻がその日の午前 10 時である場合、クエリの計算回数は 106060n 回 = 36,000n であると結論付けることができます。時間の経過とともに、午前 0 時に近づくにつれて単一クエリの数が直線的に増加します。リアルタイム クエリやリアルタイム アラームなどのモジュールからの大量のクエリ要求では、このメソッドを複数回呼び出す必要があるため、大量の CPU リソースが占有され、無駄になります。
4. 解決策
問題を特定した後、最初に考慮するのは、計算の数を減らし、例外メソッドを最適化することです。調査の結果、ロジック層で使用する場合、このメソッドによって返されるセット コレクションの内容は使用されず、セットのサイズ値が単に使用されることが判明しました。ロジックを確認した後、新しいメソッド (現在の秒 - その日の早朝の秒) によって計算を簡略化し、呼び出されたメソッドを置き換えて、過剰な計算の問題を解決します。オンライン化後、サーバー負荷とCPU使用率を観察したところ、異常時と比べてサーバー負荷とCPU使用率が30分の1に低下し、正常な状態に戻り、現時点では問題は解決しました。

負荷平均と負荷評価基準 (8 コア) を観察することで、サーバーが高負荷であることを確認できます;
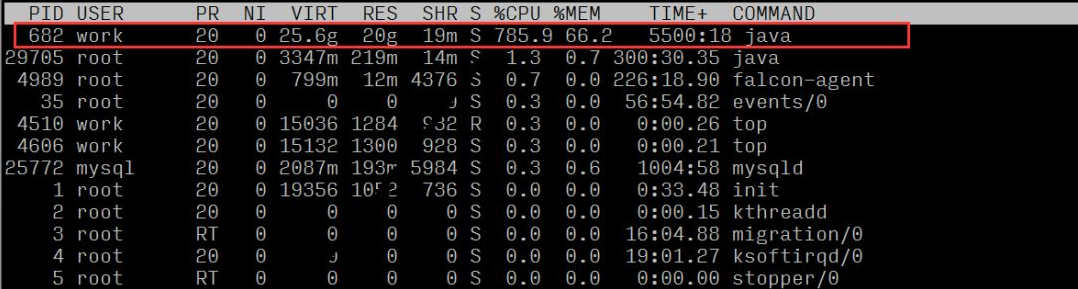
各プロセスのリソース使用量を観察すると、プロセス ID 682 のプロセスの CPU 比率が高いことがわかります。
2.2 特定の異常なビジネスを特定する
ここでは、pwdx コマンドを使用して、pid に基づいてビジネス プロセス パスを検索し、担当者とプロジェクトを特定できます。

このプロセスはデータ プラットフォームの Web サービスに相当すると結論付けることができます。
2.3 異常なスレッドと特定のコード行を特定する
従来のソリューションは通常 4 つのステップです:
1. top oder by with P:1040 //まずプロセス負荷でソートし、maxLoad(pid)を見つけます
2. top -Hp process PID: 1073 // 関連するロード スレッド PID を検索します。
3. printf "0x%x" Thread PID: 0x431 // 後で jstack ログを検索できるように準備するために、スレッド PID を 16 進数に変換します。 4. jstack プロセス PID | vim /hex スレッド PID – // 例: jstack 1040|vim /0x431 – しかし、オンラインで問題を特定するには、一秒一秒が重要であり、上記の 4 つの手順は依然として面倒で時間がかかります。以前に淘宝網を紹介した Oldratlee は、上記のプロセスを show-busy-java-threads というツールにカプセル化しました。ああ、この種の問題はオンラインで簡単に見つけることができます: システム内のタイム ツール メソッドの実行 CPU が比較的高いと結論付けることができます。特定のメソッドを特定した後、コード ロジックにパフォーマンスの問題があるかどうかを確認してください。 # オンラインの問題がより緊急である場合は、2.1 と 2.2 を省略して 2.3 を直接実行できます。ここでの分析は、完全な分析アイデアを提供するために複数の角度から行われています。 前回の分析とトラブルシューティングの後、最終的に、過度のサーバー負荷と CPU 使用率を引き起こす時間ツールの問題を特定しました。 現在時刻がその日の午前 10 時である場合、クエリの計算回数は 106060n 回 = 36,000n であると結論付けることができます。時間の経過とともに、午前 0 時に近づくにつれて単一クエリの数が直線的に増加します。リアルタイム クエリやリアルタイム アラームなどのモジュールからの大量のクエリ要求では、このメソッドを複数回呼び出す必要があるため、大量の CPU リソースが占有され、無駄になります。 問題を特定した後、最初に考慮するのは、計算の数を減らし、例外メソッドを最適化することです。調査の結果、ロジック層で使用する場合、このメソッドによって返されるセット コレクションの内容は使用されず、セットのサイズ値が単に使用されることが判明しました。ロジックを確認した後、新しいメソッド (現在の秒 - その日の早朝の秒) によって計算を簡略化し、呼び出されたメソッドを置き換えて、過剰な計算の問題を解決します。オンライン化後、サーバー負荷とCPU使用率を観察したところ、異常時と比べてサーバー負荷とCPU使用率が30分の1に低下し、正常な状態に戻り、現時点では問題は解決しました。 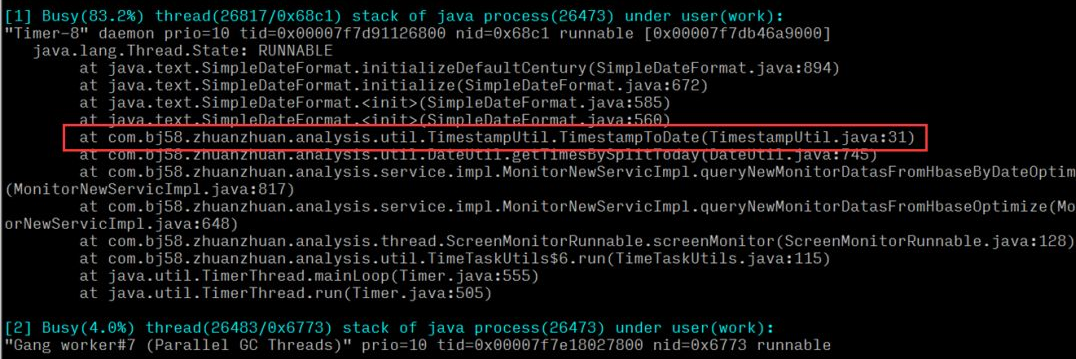
3. 根本原因の分析
4. 解決策
#5. 概要
コーディング プロセスでは、ビジネス ロジックの実装に加えて、コードのパフォーマンスの最適化にも重点を置く必要があります。ビジネス要件を実現する能力と、それをより効率的かつエレガントに達成する能力は、実はエンジニアの能力と領域の全く異なる発現であり、後者はエンジニアの核となる競争力でもあります。
以上がLinux システムの CPU は 100% 使用されています。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。