
ホームページ >システムチュートリアル >Linux >Linux メモリ管理: 仮想メモリと物理メモリを変換して割り当てる方法
Linux メモリ管理: 仮想メモリと物理メモリを変換して割り当てる方法

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2024-02-10 17:24:261395ブラウズ
Linux システムでは、メモリ管理はオペレーティング システムの最も重要な部分の 1 つです。これは、限られた物理メモリを複数のプロセスに割り当て、仮想メモリの抽象化を提供して、各プロセスが独自のアドレス空間を持ち、メモリを保護および共有できるようにする役割を果たします。この記事では、仮想メモリ、物理メモリ、論理メモリ、リニアメモリなどの概念、Linuxメモリ管理の基本モデル、システムコール、実装方法など、Linuxメモリ管理の原理と手法を紹介します。
この記事は 32 ビット マシンに基づいており、メモリ管理の知識ポイントについて説明しています。
\1. 仮想アドレス、物理アドレス、論理アドレス、リニア アドレス
仮想アドレスはリニアアドレスとも呼ばれます。 Linux はセグメンテーション メカニズムを使用しないため、論理アドレスと仮想アドレス (リニア アドレス) (ユーザー モードでは、カーネル モードの論理アドレスは、具体的には後述のリニア オフセット前のアドレスを指します) は同じ概念です。物理アドレスを言及する必要はありません。カーネルの仮想アドレスと物理アドレスのほとんどは、線形オフセットだけ異なります。ユーザー空間の仮想アドレスと物理アドレスは、マルチレベルのページ テーブルを使用してマッピングされますが、依然としてリニア アドレスと呼ばれます。
\2. DMA/HIGH_MEM/NROMAL パーティション
x86 構造では、Linux カーネル仮想アドレス空間はユーザー空間として 0 ~ 3G、カーネル空間として 3 ~ 4G に分割されます (カーネルが使用できるリニア アドレスは 1G のみであることに注意してください) )。カーネル仮想空間 (3G ~ 4G) は、次の 3 種類の領域に分かれています。
ZONE_DMA 3G
の後に始まる 16MB
ZONE_NORMAL 16MB~896MB
ZONE_HIGHMEM 896MB ~1G
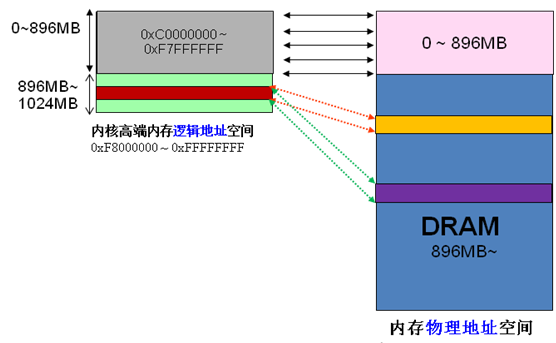 ハイエンド メモリの分割は次のとおりです。
ハイエンド メモリの分割は次のとおりです。
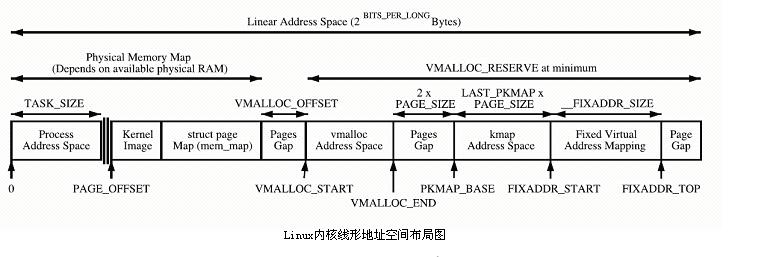 カーネルはスペース PAGE_OFFSET~VMALLOC_START を直接マップし、kmalloc と __get_free_page() がここにページを割り当てます。どちらもスラブ アロケータを使用して物理ページを直接割り当て、論理アドレスに変換します (物理アドレスは連続しています)。メモリの小さなセグメントを割り当てるのに適しています。この領域には、カーネル イメージや物理ページ フレーム テーブル mem_map などのリソースが含まれます。
カーネルはスペース PAGE_OFFSET~VMALLOC_START を直接マップし、kmalloc と __get_free_page() がここにページを割り当てます。どちらもスラブ アロケータを使用して物理ページを直接割り当て、論理アドレスに変換します (物理アドレスは連続しています)。メモリの小さなセグメントを割り当てるのに適しています。この領域には、カーネル イメージや物理ページ フレーム テーブル mem_map などのリソースが含まれます。 カーネル動的マッピング空間 VMALLOC_START~VMALLOC_END は vmalloc によって使用され、大きな表現可能な空間を持っています。
カーネル永続マッピング空間 PKMAP_BASE ~ FIXADDR_START、kmap
カーネル一時マッピング空間 FIXADDR_START~FIXADDR_TOP、kmap_atomic
3. パートナー アルゴリズムとスラブ アロケーター
Buddy アルゴリズムは、外部断片化の問題を解決します。カーネルは、各ゾーンで使用可能なページを管理し、2 のべき乗 (順序) サイズに従ってリンク リスト キューに配置し、free_area 配列に格納します。
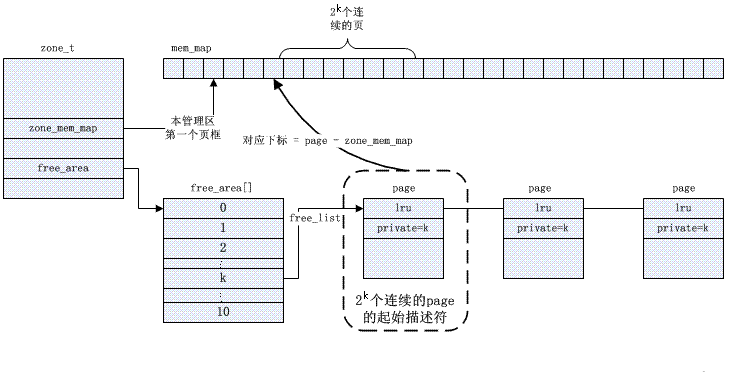 特定のバディ管理はビットマップに基づいており、ページの割り当てとリサイクルのアルゴリズムは次のように説明されます。
特定のバディ管理はビットマップに基づいており、ページの割り当てとリサイクルのアルゴリズムは次のように説明されます。
バディアルゴリズムの例の説明:
システム メモリには ***16****** ページ****
RAM*しかないとします。 RAM には 16 ページしかないため、バディ ビットマップの 4 レベル (次数) を使用するだけで済みます (理由は、最大連続メモリ サイズが ******16****** ページであるためです* * *)、以下に示すとおり。
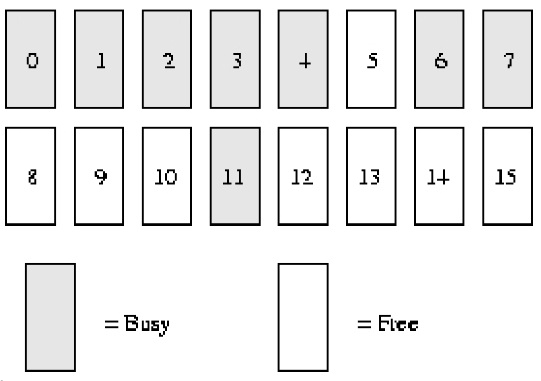 order(0) bimap は 8 ビットです (*** ページには最大 ******16****** ページを含めることができるため、******16/ 2***)
order(0) bimap は 8 ビットです (*** ページには最大 ******16****** ページを含めることができるため、******16/ 2***)
order(1) bimap は 4 ビット (***order******(******0******)******bimap**** ** ******8****** ******bit****** bit*** があるため、8/2);
つまり、順序 (1) の最初のブロックは *** 2 つのページ フレーム ****page1* *** と ******page2***** で構成されます。 *order (1) で構成 ブロック 2 は、 2 つのページ フレーム ****page3* *** と ******page4* で構成されます* ****、これら 2 つのブロックの間に ******bit**** bit*
がありますorder(2) bimap には 2 ビットがあります (***order******(******1******)******bimap**** ** ******4************ビット******桁***があるため、4/2)
order(3) bimap は 1 ビット (***order******(******2******)******bimap**** ** ******4****** ******bit****** bit*** あるため、2/2)
order(0) では、最初のビットは最初の ****2****** ページ*** を表し、2 番目のビットは次の 2 ページを表します。ページ 4 は割り当てられており、ページ 5 は空いているため、3 番目のビットは 1 です。
また、order(1) で、ビット 3 が 1 である理由は、1 つのパートナー (ページ 8 および 9) が完全にアイドル状態であるが、その対応するパートナー (ページ 10 および 11) は完全にアイドル状態ではないためです。そのため、ページがリサイクルされると、将来的には、合併することができます。
割り当てプロセス
*********order****** (******1******) の空きページ ブロックが必要な場合、*** 次の手順を実行します。 :
1.最初の無料リンク リストは次のとおりです:
注文(0): 5、10
注文(1): 8 [8,9]
注文(2): 12 [12,13,14,15]
注文(3):
2. 上記のフリーリンクリストから、注文(1)のリンクリストに*フリーページブロックがあることが分かりますので、これをユーザーに割り当て、リンクリストから削除します。 *
3. 別の order(1) ブロックが必要な場合は、order(1) の空きリストからもスキャンを開始します。
4. ***order****** (******1******) に空きページ ブロック *** がない場合は、より高いレベルに進みます。 ( 注文)、注文(2)。
5. 現時点では (***オーダー****** (******1*****)* には空きページ ブロックがありません)空きページ ブロック、ブロックは 12 ページから始まります。ページ ブロックは、2 つのわずかに小さい順序 (1) ページ ブロック [12, 13] と [14, 15] に分割されます。 [14, 15] ページ ブロックが order****** (******1*****) 自由リンク リスト * に追加されます。と ## を同時に #[12******,******13]****ページ ブロックがユーザーに返されます。 *
6. 最終的な無料リンク リストは次のとおりです:
注文(0): 5、10
注文(1): 14 [14,15]
注文(2):
注文(3):
リサイクルプロセス
***ページ ******11****** (******注文 0****) をリサイクルする場合、次の手順が実行されます: *
***1******、****** が ******order****** (******0******) で見つかりましたパートナー ビットマップ内のページ ******11****** を表すビット ****は、次の公開表記法を使用して計算されます: *
#index =* *page_idx >> (順序 1)*
#= 11 >> (0 1)*
#= 5*
2. 上記の手順を確認して、ビットマップ内の対応するビットの値を計算します。ビット値が 1 の場合、近くにアイドル状態のパートナーが存在します。パートナー ページ 10 が空いているため、ビット 5 の値は 1 です (ビット 0 から始まり、ビット 5 が 6 番目のビットであることに注意してください)。3. 現時点では 2 つのパートナー (ページ 10 とページ 11) が完全にアイドル状態であるため、このビットの値を 0 にリセットします。
4. order(0) の空きリストからページ 10 を削除します。
5. この時点で、2 つの空きページ (10 ページと 11 ページ、順序 (1)) に対してさらに操作を実行します。
6. 新しい空きページは 10 ページから始まるため、order(1) のパートナー ビットマップでそのインデックスを見つけて、さらにマージ操作を行うためのアイドル パートナーがあるかどうかを確認します。ステップ 1 で計算された会社を使用すると、ビット 2 (数字 3) が得られます。
7. パートナー ページ ブロック (ページ 8 と 9) が空いているため、ビット 2 (order(1) ビットマップ) も 1 です。
8. bit2 (order(1) ビットマップ) の値をリセットし、order(1) リンク リスト内の空きページ ブロックを削除します。
9. 次に、4 ページ サイズの空きブロック (ページ 8 から開始) にマージし、別のレベルに入ります。順序 (2) でパートナー ビットマップに対応するビット値を見つけます。これは bit1 で、その値は 1 です。さらにマージする必要があります (理由は上記と同じです)。
10. oder(2) リンク リストから空きページ ブロック (12 ページ目から) を削除し、そのページ ブロックを前回のマージで得られたページ ブロックとさらにマージします。これで、8 ページから始まり、サイズが 8 ページの空きページのブロックが得られます。
11. 別のレベル、順序 (3) に入ります。そのビット インデックスは 0 であり、その値も 0 です。これは、対応するパートナーがすべて無料ではないことを意味し、さらなる合併の可能性はありません。このビットを 1 に設定するだけで、マージされたフリー ページ ブロックを order(3) フリー リンク リストに追加します。
12. 最後に、8 ページの無料ブロックを取得します。

内部の断片化を回避するための友人の取り組み
物理メモリの断片化は、常に Linux オペレーティング システムの弱点の 1 つです。多くの解決策が提案されていますが、完全に解決できる方法はありません。メモリ バディの割り当ては解決策の 1 つです。ディスク ファイルにも断片化の問題があることはわかっていますが、ディスク ファイルの断片化はシステムの読み取りおよび書き込み速度が低下するだけで、機能エラーは発生しません。さらに、ディスクの機能に影響を与えずにディスクを断片化することもできます。きちんとした。物理メモリの断片化はまったく異なります。物理メモリとオペレーティング システムは非常に密接に統合されているため、実行時に物理メモリを移動するのは困難です (この時点では、ディスクの断片化ははるかに簡単です。実際、mel gorman はメモリ圧縮パッチを持っています)は送信されましたが、メインライン カーネルによってまだ受信されていません)。したがって、解決策の方向性は主にデブリの防止に焦点を当てています。 2.6.24 カーネルの開発中に、断片化を防ぐカーネル機能がメインライン カーネルに追加されました。断片化防止の基本原理を理解する前に、まずメモリ ページを分類します。
\1. 移動不可能なページ: メモリ内の位置は固定されている必要があり、他の場所に移動することはできません。コア カーネルによって割り当てられるほとんどのページは、このカテゴリに分類されます。\2. 再利用可能なページ reclaimable: 直接移動することはできませんが、いくつかのソースからページを再構築することもできるため、リサイクルすることはできます。たとえば、マッピング ファイルのデータはこのカテゴリに属し、kswapd は特定のルールに従って定期的にリサイクルするこのタイプのページ。
\3. 可動ページ移動可能: 自由に移動できます。ユーザー空間アプリケーションに属するページは、このタイプのページに属します。ページ テーブルを介してマップされるため、必要なのはページ テーブル エントリを更新し、データを新しい場所にコピーすることだけです。複数のページ テーブル エントリに対応するプロセス共有によって使用される可能性があります。
断片化を防ぐ方法は、これら 3 種類のページを異なるリンク リストに配置して、異なる種類のページが相互に干渉しないようにすることです。移動できないページが移動可能なページの真ん中にある状況を考えてみましょう。これらのページを移動またはリサイクルした後、この移動できないページによって、より大きな連続した物理空き領域を確保できなくなります。
さらに、各ゾーンには、非アクティブ化されたダーティ ページ キューとアクティブ キューという 2 つのクロスゾーン グローバル キューに対応する独自の非アクティブ化されたネット ページ キューがあります。これらのキューは、ページ構造の lru ポインタを介してリンクされます。 考察: 非アクティブ化キューの意味は何ですか (
を参照)?カーネルは多くの場合、システムのライフサイクル中に数え切れないほど割り当てられる小さなオブジェクトの割り当てに依存します。スラブ キャッシュ アロケータは、同様のサイズ (1 ページよりもはるかに小さい) のオブジェクトをキャッシュすることによってこの機能を提供し、一般的な内部断片化の問題を回避します。一応絵はこちらでございますが、その原理につきましては共通参考資料3をごらんください。明らかに、スラブ メカニズムはバディ アルゴリズムに基づいており、前者は後者を改良したものです。
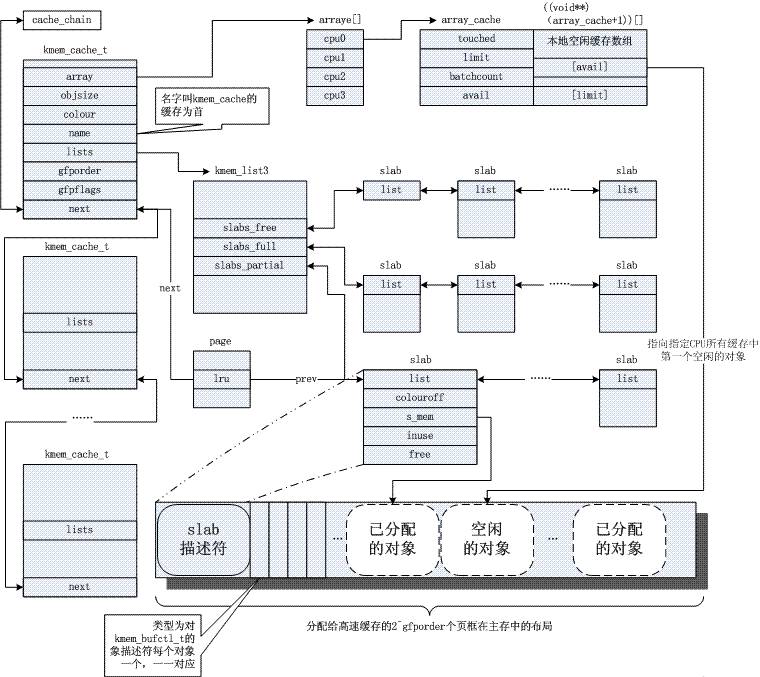 4. ページのリサイクル/フォーカスのメカニズム
4. ページのリサイクル/フォーカスのメカニズムページのご利用について
ページ割り当てがある場合、ページのリサイクルが行われます。ページのリサイクル方法は、一般に次の 2 つのタイプに分類できます。
1 つはアクティブリリースです。ユーザープログラムが malloc 関数で割り当てたメモリを free 関数で解放するのと同じように、ページのユーザーはそのページがいつ使用され、いつ不要になるかを明確に知っています。
上記の最初の 2 つの割り当て方法は、通常、カーネル プログラムによって積極的に解放されます。パートナー システムから直接割り当てられたページの場合、free_pages などの関数を使用してユーザーによってアクティブに解放されます。ページが解放された後、パートナー システムに直接解放されます。(kmem_cache_alloc 関数を使用して) スラブから割り当てられたオブジェクトも解放されます。ユーザーによって解放されました。積極的に解放されます (kmem_cache_free 関数を使用)。
上記の最初の 2 つのページ割り当て方法 (直接ページ割り当てとスラブを介したオブジェクト割り当て) では、PFRA を介したリサイクルも必要になる場合があります。
このページのユーザーは、コールバック関数を PFRA に登録できます (register_shrink 関数を使用)。これらのコールバック関数は、適切なタイミングで PFRA によって呼び出され、対応するページまたはオブジェクトのリサイクルがトリガーされます。
最も典型的なものの 1 つは、dentry のリサイクルです。 Dentry は、スラブによって割り当てられ、仮想ファイル システムのディレクトリ構造を表すために使用されるオブジェクトです。 dentry の参照カウントが 0 に減少すると、dentry は直接解放されず、後で使用するために LRU リンク リストにキャッシュされます。 (「Linux カーネル仮想ファイル システムの簡単な分析」を参照してください。) さらに、システムの実行中、スラブ内に多くのアイドル状態のオブジェクトが存在する可能性があります (たとえば、特定のオブジェクトの使用量のピークが過ぎた後など)。 PFRA の cache_reap 関数は、これらの冗長なアイドル オブジェクトをリサイクルするために使用されます。一部のアイドル オブジェクトをページに復元できる場合は、このページをパートナー システムに解放できます。 メモリマッピングについて メモリ マッピングは、ファイル マッピングと匿名マッピングに分かれています。 ファイル マッピングは、共有マッピングとプライベート マッピングに分かれています。プライベート マッピング中に、プロセスがマップされたアドレス空間に書き込む場合、マッピングに対応するディスク キャッシュには直接書き込まれません。代わりに、元のコンテンツをコピーしてからそのコピーを書き込むと、現在のプロセスの対応するページ マッピングがこのコピーに切り替わります (コピーオンライト)。つまり、書き込み操作は自分だけが見ることができます。共有マッピングの場合、書き込み操作はディスク キャッシュに影響し、すべてのユーザーに表示されます。 どのページ **** をリサイクルする必要がありますか? したがって、ページが予約またはロックされていない限り (ページ フラグ PG_reserved/PG_locked が設定されています。場合によっては、カーネルはリサイクルを避けるためにページを一時的に予約する必要があります)、すべてのディスク キャッシュ ページはリサイクル可能で、すべて匿名にすることができます。マップされたページは交換可能です。 リサイクルできるページはたくさんありますが、PFRA がリサイクル/スワップをできる限り少なくする必要があるのは明らかです (これらのページはディスクから復元する必要があり、多大なコストがかかるため)。したがって、PFRA は必要に応じて、めったに使用されないページの一部のみを再利用/交換し、毎回再利用されるページ数は経験値である 32 です。 したがって、これらすべてのディスク キャッシュ ページと匿名マッピング ページは、一連の LRU に配置されます。 (実際には、各ゾーンにはそのような LRU のセットがあり、ページは対応するゾーンの LRU に配置されます。)
LRU のグループは、ディスク キャッシュ ページ (ファイル マッピング ページを含む) のリンク リスト、匿名マッピング ページのリンク リストなどを含む、リンク リストのいくつかのペアで構成されます。リンク リストのペアは、実際にはアクティブと非アクティブの 2 つのリンク リストであり、前者は最近使用されたページ、後者は最近使用されていないページです。 最近使用されていないものを特定する
ここで問題は、アクティブ/非アクティブ リスト内のどのページが最も最近使用されていないかをどのように判断するかということです。
メモリマップされたページの場合、ユーザー プロセスは (カーネルを経由せずに) 直接アクセスできるため、この場合のアクセス フラグはカーネルではなく mmu によって設定されます。仮想アドレスを物理アドレスにマッピングした後、mmu は対応するページ テーブル エントリにアクセス済みフラグを設定して、ページがアクセスされたことを示します。 (同様に、mmu は、書き込まれているページに対応するページ テーブル エントリにダーティ フラグを設定し、そのページがダーティ ページであることを示します。)
LRU のグループが複数あるため (システム内に複数のゾーンがあり、各ゾーンに複数の LRU グループがある)、PFRA がリサイクルのたびにすべての LRU をスキャンして、リサイクルに最も価値のあるページを見つけると、リサイクルの効率が低下します。アルゴリズムは明らかですが、理想的とは言えません。 アクセスフラグが設定されているかどうかに基づいて、スキャンされたページが決定されます。では、このアクセスタグはどのように設定されるのでしょうか?ユーザーが読み取り/書き込みなどのシステムコールでファイルにアクセスすると、カーネルがディスクキャッシュ内のページを操作し、そのページのアクセスフラグを設定する(ページ構造に設定する)方法の2つがあります。プロセスがファイルに直接アクセスすることです。ページがマップされると、mmu は対応するページ テーブル エントリにアクセス タグ (ページ テーブルの pte に設定) を自動的に追加します。アクセスタグの判断は、この2つの情報に基づいて行われます。 (あるページに対して、複数の PTE が参照している可能性があります。これらの PTE にアクセス タグが設定されているかどうかを確認するにはどうすればよいですか? 次に、逆マッピングを通じてこれらの PTE を見つける必要があります。これについては以下で説明します。) 逆マッピング ページに対応するページ構造で、page->mapping の最下位ビットが設定されている場合、それは匿名マッピング ページであり、page->mapping は anon_vma 構造体を指します。それ以外の場合、それはファイル マッピング ページです。 、および page->mapping は、file. 構造に対応する address_space です。 (当然のことながら、anon_vma 構造体と address_space 構造体が割り当てられるときは、アドレスが整列している必要があり、少なくとも最下位ビットは 0 でなければなりません。) 上記の 2 つの手順では、魔法の page->index は、ページの仮想アドレスの取得と、ファイル ディスク キャッシュ内のページの場所の取得という 2 つのことを実行します。 ページの入出力切り替え 匿名でマップされたページをスワップ ファイルにスワップするプロセス (スワップアウト プロセス) は、ディスク キャッシュ内のダーティ ページをファイルに書き戻すプロセスと非常によく似ています。 同様に、匿名でマップされたページをスワップ ファイルから読み取るプロセス (スワップイン プロセス) も、ファイル データを読み取るプロセスと非常によく似ています。 最後の殺害 5. メモリ管理アーキテクチャ 上の写真について一言 アドレス マッピング 仮想アドレス管理 物理メモリ管理 [アドレスマッピングを確立する]
カーネルが物理メモリを必要とする場合、多くの場合、ページ全体が割り当てられます。これを行うには、上記の mem_map からページを選択するだけです。たとえば、前述のカーネルはページ フォールト例外をキャプチャし、マッピングを確立するためにページを割り当てる必要があります。 カーネルスペース管理 ページの入出力切り替え(写真: 右上) [ユーザー空間のメモリ管理]
Malloc は libc のライブラリ関数であり、ユーザー プログラムは一般にこれ (または同様の関数) を使用してメモリ領域を割り当てます。 ユーザーのスタック]
ヒープと同様に、スタックも vma です (写真: 中段左) この vma は、一端が固定され、もう一端が拡張可能です (縮小できないことに注意してください)。この vma は特別です。この vma を拡張するための brk のようなシステム コールはありません。自動的に拡張されます。
ユーザーがアクセスする仮想アドレスがこの vma を超えると、カーネルはページ フォールト例外を処理するときに自動的に vma を増やします。カーネルは現在のスタック レジスタ (ESP など) をチェックし、アクセスされる仮想アドレスは ESP に n を加えた値を超えることはできません (n は、CPU プッシュ命令が一度にスタックにプッシュできる最大バイト数です)。つまり、カーネルは ESP をベンチマークとして使用して、アクセスが範囲外かどうかをチェックします。
以前の記事では、Linux カーネルが多くの状況でページを割り当てることを学びました。
1. カーネル コードは、alloc_pages などの関数を呼び出して、物理ページ (管理ゾーンの free_area フリー リスト) を管理するパートナー システムからページを直接割り当てることがあります (「Linux カーネル メモリ管理の簡単な分析」を参照)。たとえば、ドライバーはこの方法でキャッシュを割り当てることができ、プロセスの作成時に、カーネルもこの方法で 2 つの連続するページをスレッド情報構造体およびプロセスのカーネル スタックとして割り当てます。パートナー システムからのページの割り当ては、最も基本的なページ割り当て方法であり、他のメモリ割り当てはこの方法に基づいています。
2. カーネル内の多くのオブジェクトは、スラブ メカニズムを使用して管理されます (「Linux スラブ アロケータの簡単な分析」を参照)。スラブはオブジェクト プールに相当し、ページを「オブジェクト」に「フォーマット」し、人間が使用できるようにプールに保存します。スラブ内に不十分なオブジェクトがある場合、スラブ メカニズムはパートナー システムからページを自動的に割り当て、それらを新しいオブジェクトに「フォーマット」します。
3. ディスク キャッシュ (「Linux カーネル ファイルの読み取りと書き込みの簡単な分析」を参照)。ファイルの読み取りおよび書き込み時には、パートナー システムからページが割り当てられてディスク キャッシュに使用され、ディスク上のファイル データが対応するディスク キャッシュ ページにロードされます。
4. メモリマッピング。ここでのいわゆるメモリ マッピングとは、実際には、ユーザー プロセスが使用するためにメモリ ページをユーザー空間にマッピングすることを指します。プロセスの task_struct->mm 構造内の各 vma はマッピングを表し、マッピングの実際の実装では、ユーザー プログラムが対応するメモリ アドレスにアクセスした後、ページ フォールト例外によって発生したページが割り当てられ、ページ テーブルが更新されました (「Linux カーネルのメモリ管理の簡単な分析」を参照);
ページをリサイクルするもう 1 つの方法は、Linux カーネルによって提供されるページ フレーム リサイクル アルゴリズム (PFRA) を通じてページをリサイクルすることです。ページのユーザーは通常、システムの動作効率を向上させるためにページをある種のキャッシュとして扱います。キャッシュが常に存在するのは良いことですが、キャッシュがなくなってもエラーは発生せず、影響を受けるのは効率だけです。ページのユーザーは、これらのキャッシュされたページをいつ保持するのが最適で、いつリサイクルするのが最適であるかを明確に知りません。その処理は PFRA に任されています。
簡単に言えば、PFRA が行うべきことは、リサイクル可能なページをリサイクルすることです。システムがページ不足に陥るのを防ぐために、PFRA はカーネル スレッドで定期的に呼び出されます。または、システムがすでにページ不足になっているため、ページを割り当てようとしているカーネル実行プロセスが必要なページを取得できず、PFRA を同期的に呼び出します。
PFRAリサイクル総合ページ
この LRU リンク リスト内の dentry は最終的にリサイクルする必要があるため、仮想ファイル システムが初期化されるときに register_shrinker が呼び出され、リサイクル関数 shrin_dcache_memory が登録されます。
システム内のすべてのファイル システムのスーパーブロック オブジェクトは、リンク リストに格納されます。shrink_dcache_memory 関数は、このリンク リストをスキャンし、各スーパーブロックの未使用の dentry の LRU を取得し、そこから最も古い dentry の一部を回収します。 dentry が解放されると、対応する i ノードが参照解除され、これにより i ノードが解放される可能性もあります。
i ノードが解放されると、その i ノードも未使用のリンク リストに配置されます。初期化中に、仮想ファイル システムは register_shrinker を呼び出して、これらの未使用の i ノードをリサイクルするコールバック関数 shrin_icache_memory を登録します。これにより、その i ノードに関連付けられたディスク キャッシュも削除されます。解放されました。
cache_reap 関数が行うことは簡単に言うと簡単です。システム内のオブジェクト プールを格納する kmem_cache 構造はすべてリンク リストに接続されており、cache_reap 関数は各オブジェクト プールをスキャンし、リサイクル可能なページを探してリサイクルします。 (もちろん、実際のプロセスはもう少し複雑です。)
前述したように、ディスク キャッシュとメモリ マッピングは通常、PFRA によってリサイクルされます。 PFRA による 2 つのリサイクルは非常に似ており、実際、ディスク キャッシュはユーザー領域にマッピングされる可能性があります。以下はメモリ マッピングについて簡単に説明したものです:
ファイル マッピングとは、このマッピングを表す vma がファイル内の特定の領域に対応することを意味します。このマッピング方法がユーザー モード プログラムで明示的に使用されることは比較的まれですが、ユーザー モード プログラムは通常、ファイルを開いてからファイルの読み取り/書き込みを行うことに慣れています。
実際、ユーザー プログラムは mmap システム コールを使用して、ファイルの特定の部分をメモリ (vma に対応) にマップし、メモリにアクセスしてファイルの読み取りと書き込みを行うこともできます。ユーザー プログラムがこの方法を使用することはほとんどありませんが、ユーザー プロセスはこのようなマッピングでいっぱいです。プロセスによって実行される実行可能コード (実行可能ファイルおよび lib ライブラリ ファイルを含む) はこの方法でマッピングされます。
「Linux カーネル ファイルの読み取りと書き込みの簡単な分析」の記事では、ファイル マッピングの実装については説明しませんでした。実際、ファイル マッピングはファイルのディスク キャッシュ内のページをユーザー空間に直接マッピングします (ファイルによってマッピングされたページはディスク キャッシュ ページのサブセットであることがわかります)。ユーザーはそれらのページを 0 で読み書きできます。コピー。読み取り/書き込みを使用すると、ユーザー空間メモリとディスク キャッシュの間でコピーが発生します。
匿名マッピングはファイル マッピングに相対的です。つまり、このマッピングの vma はファイルに対応しません。ユーザー空間 (ヒープ空間、スタック空間) での通常のメモリ割り当ての場合、それらはすべて匿名マッピングに属します。
明らかに、複数のプロセスが独自のファイル マッピングを通じて同じファイルにマッピングする可能性があります (たとえば、ほとんどのプロセスは libc ライブラリの so ファイルをマッピングします)。匿名マッピングはどうなるのでしょうか?実際、複数のプロセスが独自の匿名マッピングを通じて同じ物理メモリにマップされる場合がありますが、この状況は、親子プロセスがフォーク後に元の物理メモリを共有する (コピーオンライト) ことによって引き起こされます。
リサイクルに関しては、ディスク キャッシュ ページ (ファイル マップされたページを含む) を破棄してリサイクルできます。ただし、ページがダーティな場合は、破棄する前にディスクに書き戻す必要があります。
匿名でマップされたページは、ユーザー プログラムによって使用されているデータが含まれており、破棄後にデータを復元できないため、破棄できません。対照的に、ディスク キャッシュ ページのデータ自体はディスク上に保存され、再生できます。
したがって、匿名でマップされたページをリサイクルしたい場合は、最初にページのデータをディスクにダンプする必要があります (これがページ スワップ (スワップ) です)。明らかに、ページ スワップのコストは比較的高くなります。
匿名でマップされたページは、ディスク上のスワップ ファイルまたはスワップ パーティションにスワップできます (パーティションはデバイスであり、デバイスもファイルです。そのため、以下ではまとめてスワップ ファイルと呼びます)。
ページをリサイクルするとき、PFRA は 2 つのことを行う必要があります。1 つは、アクティブなリンク リスト内の最も最近使用されていないページを非アクティブなリンク リストに移動することです。もう 1 つは、非アクティブなリンク リスト内の最も最近使用されていないページをリサイクルしようとすることです。
1 つのアプローチは、ソートし、ページにアクセスしたときに、そのページをリンク リストの末尾に移動することです (リサイクルが先頭から始まると仮定して)。ただし、これは、リンク リスト内のページの位置が頻繁に移動される可能性があり、移動前にページをロックする必要があることを意味し (複数の CPU が同時にアクセスする可能性がある)、効率に大きな影響を与えます。
Linux カーネルは、マーク付けと順序付けの方法を使用します。ページがアクティブなリンク リストと非アクティブなリンク リストの間を移動する場合、そのページは常にリンク リストの最後に配置されます (リサイクルが先頭から開始すると仮定した場合、上記と同じです)。
リンクされたリスト間でページが移動されない場合、その順序は調整されません。代わりに、アクセス タグは、ページがアクセスされたばかりかどうかを示すために使用されます。非アクティブなリンク リストにアクセス タグが設定されているページに再度アクセスすると、アクティブなリンク リストに移動され、アクセス タグがクリアされます。 (実際には、アクセスの競合を避けるために、ページは非アクティブなリンク リストからアクティブなリンク リストに直接移動しませんが、リンク リストのロックを避けるためのバッファとして使用される pagevec 中間構造があります。)
ページのアクセス タグ (上記の 2 つのタグを含む) は、PFRA によるページのリサイクルのプロセス中にクリアされます。これは、アクセス タグには明らかに有効期間が必要であり、PFRA の実行サイクルがこの有効期間を表すためです。 page->flags の PG_referenced マークは直接クリアできますが、ページ テーブル エントリのアクセスされたビットは、ページを通じて対応するページ テーブル エントリを見つけた後にのみクリアできます (下記の「逆マッピング」を参照)。
Linux カーネル PFRA で使用されるスキャン方法では、スキャンの優先順位を定義し、この優先順位を使用して各 LRU でスキャンする必要があるページ数を計算します。リサイクル アルゴリズム全体は、最も低い優先順位から開始され、各 LRU 内の最も最近使用されていないページをスキャンして、それらの再利用を試みます。 1 回のスキャン後に十分な数のページがリサイクルされると、リサイクル プロセスは終了します。それ以外の場合は、優先順位を上げ、十分な数のページが再利用されるまで再スキャンします。また、十分な数のページをリサイクルできない場合は、優先度が最大に引き上げられ、すべてのページがスキャンされます。このとき、リサイクルページ数がまだ足りない場合でも、リサイクル処理は終了します。
PFRA は、アクティブなリンク リストから匿名でマップされたページをリサイクルする傾向がありません。これは、ユーザー プロセスによって使用されるメモリが一般に比較的小さく、リサイクルにはスワップが必要であり、コストがかかるためです。したがって、メモリが大量に残っており、匿名マッピングの割合が少ない場合、匿名マッピングに対応するアクティブなリンク リスト内のページはリサイクルされません。 (ページが非アクティブ リストに追加されている場合は、もう心配する必要はありません。)
このように、PFRA によって処理されるページのリサイクルのプロセス中に、LRU の非アクティブ リスト内の一部のページがリサイクルされようとしている可能性があります。
ページがマップされていない場合は、パートナー システムに直接リサイクルできます (ダーティ ページの場合は、最初に書き戻してからリサイクルします)。そうでなければ、対処しなければならない厄介なことがまだ1つあります。ユーザープロセスの特定のページテーブルエントリがこのページを参照しているため、ページが再利用される前に、それを参照しているページテーブルエントリに説明を与える必要があります。
そこで、カーネルはどのページ テーブル エントリがこのページによって参照されているかをどのようにして知るのでしょうか?という疑問が生じます。これを行うために、カーネルは、ページからページ テーブル エントリへの逆マッピングを確立します。
マッピングされたページに対応する vma は逆マッピングを通じて見つけることができ、対応するページ テーブルは vma->vm_mm->pgd を通じて見つけることができます。次に、page->index を通じてページの仮想アドレスを取得します。次に、仮想アドレスを通じてページ テーブルから対応するページ テーブル エントリを見つけます。 (前述のページ テーブル エントリ内のアクセスされたタグは、逆マッピングによって実現されます。)
匿名でマップされたページの場合、anon_vma 構造はリンク リスト ヘッダーとして機能し、このページをマッピングするすべての vmas を vma->anon_vma_node リンク リスト ポインターを介して接続します。ページがユーザー空間に (匿名で) マップされるたびに、対応する vma がこのリンク リストに追加されます。
ファイル マップされたページの場合、address_space 構造はディスク キャッシュ ページを格納するための基数ツリーを維持するだけでなく、ファイルにマップされたすべての vmas の優先検索ツリーも維持します。ファイルによってマップされるこれらの VMA は、必ずしもファイル全体をマップするとは限らないため、ファイルの一部のみがマップされる可能性があります。したがって、この優先検索ツリーは、マップされたすべての vmas のインデックス付けに加えて、ファイルのどの領域がどの vmas にマップされているかを認識する必要もあります。ページ (ファイル) がユーザー空間にマップされるたびに、対応する vma がこの優先検索ツリーに追加されます。したがって、ディスク キャッシュ上にページがあるとすると、ファイル内のページの位置は、page->index を通じて取得でき、このページにマッピングされているすべての vmas は優先検索ツリーを通じて見つけることができます。
vma->vm_start は vma の最初の仮想アドレスを記録し、vma->vm_pgoff は対応するマッピング ファイル (または共有メモリ) 内の vma のオフセットを記録し、page->index はファイル (または共有メモリ) 内のページを記録します。オフセットで。
vma 内のページのオフセットは vma->vm_pgoff および page->index を通じて取得でき、ページの仮想アドレスは vma->vm_start を追加することで取得でき、ファイル ディスク キャッシュ内のページは次のように取得できます。ページ -> インデックスの位置。
リサイクルするページを参照するページ テーブル エントリを見つけた後、ファイル マッピングのために、そのページを参照するページ テーブル エントリを直接クリアできます。ユーザーがこのアドレスに再度アクセスすると、ページ フォールト例外がトリガーされます。例外処理コードはページを再割り当てし、対応するデータをディスクから読み取ります (おそらく、ページはすでに対応するディスク キャッシュにあります。他のプロセスがアクセスしているため)初め)。これは、マッピング後に初めてページにアクセスしたときと同じです;
匿名マッピングの場合、最初にページがスワップ ファイルに書き戻され、次にスワップ ファイル内のページのインデックスがページ テーブル エントリに記録される必要があります。
ページ テーブル エントリには存在ビットがあり、このビットがクリアされると、mmu はページ テーブル エントリが無効であると見なします。ページ テーブル エントリが無効な場合、他のビットは mmu によって処理されず、他の情報を格納するために使用できます。ここでは、スワップ ファイル内のページのインデックス (実際にはスワップ ファイル番号、スワップ ファイル内のインデックス番号) を格納するために使用されます。
スワップ ファイルには、対応するアドレス空間構造もあり、スワップアウトする場合、匿名でマップされたページは、まずこのアドレス空間に対応するディスク キャッシュに配置され、ダーティ ページが書き戻されるのと同じように、スワップ ファイルに書き戻されます。ライトバックが完了すると、ページは解放されます (ページを解放することが目的であることを思い出してください)。
では、なぜディスク キャッシュを経由せずにページをスワップ ファイルに書き戻さないのでしょうか?このページは複数回マップされている可能性があるため、すべてのユーザー プロセスのページ テーブル内の対応するページ テーブル エントリを一度に変更する (スワップ ファイル内のページのインデックスに変更する) ことは不可能です。ページが解放されると、ページは一時的にディスク キャッシュに配置されます。
ページ テーブル エントリへのすべての変更が成功するわけではありません (たとえば、変更前にページが再度アクセスされているため、今ページをリサイクルする必要はありません)。そのため、ページがディスク キャッシュに配置されるまでにかかる時間が長くなる可能性があります。また、非常に長くなります。
まず、対応するディスク キャッシュにアクセスしてページが存在するかどうかを確認し、存在しない場合はスワップ ファイルからそのページを読み取ります。ファイル内のデータもディスク キャッシュに読み取られ、ユーザー プロセスのページ テーブル内の対応するページ テーブル エントリがこのページを直接指すように書き換えられます。
このページはディスク キャッシュからすぐにフェッチされない場合があります。これは、このページにマップされている他のユーザー プロセスがある場合 (対応するページ テーブル エントリがスワップ ファイルにインデックスを付けるように変更されている場合)、ここで参照することもできるためです。 。他のページ テーブル エントリがスワップ ファイル インデックスを参照しなくなるまで、ページをディスク キャッシュからフェッチすることはできません。
前述したように、PFRA はすべての LRU をスキャンしても、必要なページをまだ回収できない可能性があります。同様に、ページはスラブ、dentry キャッシュ、inode キャッシュなどでリサイクルされない場合があります。
このとき、カーネル コードの特定の部分がページを取得する必要がある場合はどうなるでしょうか (ページがないとシステムがクラッシュする可能性があります)。 PFRA は最後の手段である OOM (メモリ不足) に頼るしかありませんでした。いわゆる OOM は、最も重要度の低いプロセスを見つけてそれを強制終了することです。このプロセスによって占有されているメモリ ページを解放することで、システムの負荷を軽減します。 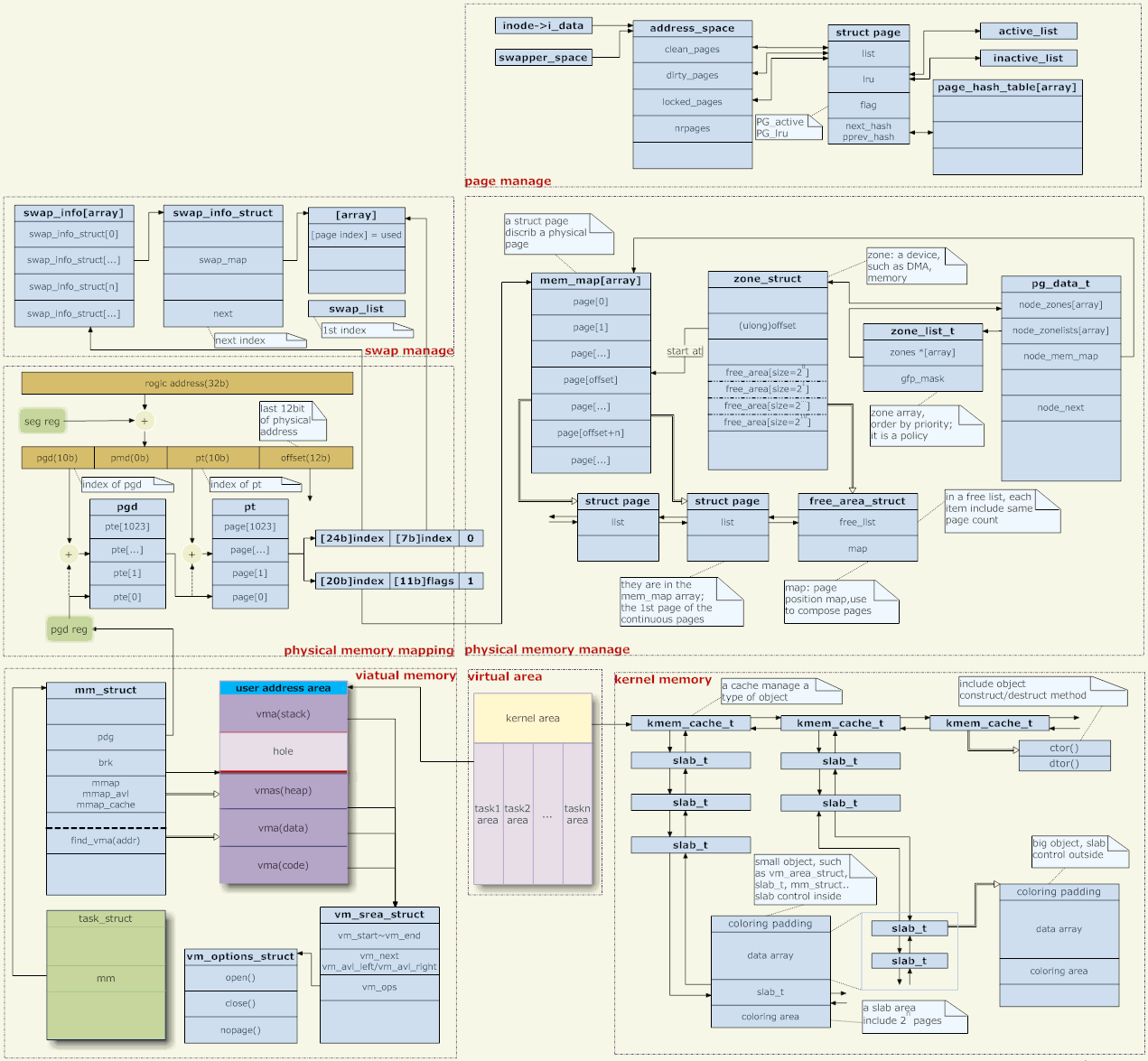
Linux カーネルはページ メモリ管理を使用します。アプリケーションによって与えられるメモリ アドレスは仮想アドレスです。複数のレベルのページ テーブルのレベルごとの変換を行う必要があります。実際の物理アドレスになる前に。
考えてみてください、アドレスマッピングは依然として恐ろしいものです。仮想アドレスで表されるメモリ空間にアクセスする場合、マッピングが完了する前に、ページ テーブルの各レベル (ページ テーブルはメモリに格納されます) で変換に使用されるページ テーブル エントリを取得するために、複数のメモリ アクセスが必要です。つまり、メモリ アクセスを実現するには、実際にはメモリに N 1 回アクセスし (N = ページ テーブル レベル)、N 回の加算演算を実行する必要があります。
したがって、アドレス マッピングはハードウェアでサポートされている必要があり、mmu (メモリ管理ユニット) がこのハードウェアです。また、ページテーブルを保存するにはキャッシュが必要ですが、このキャッシュがTLB(Translation Lookaside Buffer)です。
それにもかかわらず、アドレス マッピングには依然としてかなりのオーバーヘッドが存在します。キャッシュのアクセス速度がメモリの 10 倍、ヒット率が 40%、ページ テーブルが 3 レベルであると仮定すると、平均して 1 回の仮想アドレス アクセスで物理メモリのアクセス時間が約 2 回かかります。
そのため、一部の組み込みハードウェアは mmu の使用を放棄する場合があり、そのようなハードウェアでは VxWorks (非常に効率的な組み込みリアルタイム オペレーティング システム)、Linux (Linux には mmu を無効にするコンパイル オプションもあります)、およびその他のシステムを実行できます。
しかし、mmu を使用する利点も大きく、最も重要なのはセキュリティの考慮事項です。各プロセスは独立した仮想アドレス空間を持ち、相互に干渉しません。アドレス マッピングを放棄した後は、すべてのプログラムが同じアドレス空間で実行されます。したがって、mmu のないマシンでは、プロセスの境界外メモリ アクセスにより、他のプロセスで不可解なエラーが発生したり、カーネルがクラッシュしたりする可能性があります。
アドレス マッピングの問題に関しては、カーネルはページ テーブルのみを提供し、実際の変換はハードウェアによって完了します。では、カーネルはどのようにしてこれらのページテーブルを生成するのでしょうか?これには、仮想アドレス空間の管理と物理メモリの管理という 2 つの側面があります。 (実際には、管理する必要があるのはユーザー モードのアドレス マッピングのみであり、カーネル モードのアドレス マッピングはハードコーディングされています。)
各プロセスは、プロセスのメモリ マネージャーである mm 構造体を指すタスク構造体に対応します。 (スレッドの場合、各スレッドにもタスク構造がありますが、それらはすべて同じ mm を指すため、アドレス空間は共有されます。)
mm->pgd はページ テーブルを含むメモリを指します。各プロセスには独自の mm があり、各 mm には独自のページ テーブルがあります。したがって、処理がスケジュールされると、ページ テーブルが切り替えられます (一般的に、X86 では CR3 など、ページ テーブルのアドレスを保存する CPU レジスタがあり、ページ テーブルの切り替えとはレジスタの値を変更することです)。したがって、各プロセスのアドレス空間は互いに影響しません(ページテーブルが異なるため、当然他人のアドレス空間にアクセスすることはできません。共有メモリを除いて、これは意図的に異なるページテーブルが同じ物理アドレスにアクセスできるようにするためです) .)。
ユーザー プログラムのメモリ上の操作 (割り当て、リサイクル、マッピングなど) はすべて mm 上の操作であり、具体的には mm 上の vma (仮想メモリ空間) 上の操作です。これらの vma は、ヒープ、スタック、コード領域、データ領域、さまざまなマッピング領域など、プロセス空間のさまざまな領域を表します。
ユーザー プログラムのメモリ操作は、物理メモリの割り当てはもちろん、ページ テーブルにも直接影響しません。たとえば、malloc が成功すると、特定の vma が変更されるだけで、ページ テーブルや物理メモリの割り当ては変更されません。
ユーザーがメモリを割り当てて、このメモリにアクセスするとします。該当するマッピングがページテーブルに記録されていないため、CPU はページフォールト例外を生成します。カーネルは例外をキャッチし、例外が発生したアドレスが正当な vma に存在するかどうかを確認します。そうでない場合は、プロセスに「セグメンテーション違反」を与えてクラッシュさせます。そうである場合は、物理ページを割り当て、そのマッピングを確立します。
では、物理メモリはどのように割り当てられるのでしょうか?
まず、Linux は NUMA (非同種ストレージ アーキテクチャ) をサポートしており、物理メモリ管理の最初のレベルはメディア管理です。 pg_data_t 構造体はメディアを記述します。一般的に言えば、メモリ管理媒体はメモリのみであり、均一であるため、単純にシステム内に pg_data_t オブジェクトが 1 つだけ存在すると考えることができます。
各メディアの下にいくつかのゾーンがあります。一般的には、DMA、NORMAL、HIGH の 3 つがあります。
DMA: 一部のハードウェア システムの DMA バスはシステム バスより狭いため、アドレス空間の一部しか DMA に使用できず、この部分のアドレスは DMA 領域で管理されます (ハイエンド製品です)。 ;
HIGH: ハイエンドのメモリ。 32ビットシステムではアドレス空間は4Gで、3~4Gがカーネル空間、0~3Gがユーザー空間(各ユーザープロセスはこのような大きな仮想空間を持つ)とカーネルで規定されています(図:中下)。前述したように、カーネルのアドレス マッピングはハードコーディングされており、3 ~ 4G の対応するページ テーブルがハードコーディングされており、物理アドレス 0 ~ 1G にマッピングされます。 (実際には、1G はマッピングされず、896M のみがマッピングされます。残りのスペースは 1G より大きい物理アドレスをマッピングするために残されており、この部分は明らかにハードコーディングされていません)。したがって、896M を超える物理アドレスには、それらに対応するハードコーディングされたページ テーブルがなく、カーネルはそれらに直接アクセスできません (マッピングを確立する必要があります)。これらはハイエンド メモリと呼ばれます (もちろん、マシンのメモリが896M 未満の場合、ハイエンド メモリはありません。64 ビット マシンの場合、アドレス空間が非常に大きく、カーネルに属する空間が 1G を超えるため、ハイエンド メモリはありません) ;
NORMAL: DMA または HIGH に属さないメモリを NORMAL と呼びます。
ゾーンの上にあるzone_listは、割り当て戦略、つまりメモリを割り当てるときのゾーンの優先順位を表します。ある種のメモリ割り当ては、1 つのゾーンにだけ割り当てられるわけではないことがよくあります。たとえば、カーネルが使用するページを割り当てる場合、NORMAL から割り当てるのが最優先です。それがうまくいかない場合は、DMA (HIGH) から割り当てます。まだ割り当てられていないため機能しません)。マッピングを確立します)、これは割り当て戦略です。
各メモリ媒体は mem_map を維持し、物理メモリを管理するために媒体内の物理ページごとに対応するページ構造が確立されます。
各ゾーンは mem_map 上の開始位置を記録します。そして、このゾーン内の空きページはfree_areaを介して接続されています。物理メモリの割り当てはここから行われ、free_area からページを削除すると、物理メモリが割り当てられます。 (カーネルのメモリ割り当ては、ユーザー プロセスのメモリ割り当てとは異なります。ユーザーによるメモリの使用はカーネルによって監視され、不適切な使用は「セグメンテーション違反」を引き起こします。一方、カーネルは監視されず、意識にのみ依存することができます) .free_area から選択していないページは使用しないでください。)
そういえば、カーネルがページを割り当ててアドレスマッピングを確立するときに、カーネルは仮想アドレスを使用しますか、それとも物理アドレスを使用しますか?まず第一に、CPU 命令は仮想アドレスを受け取るため、カーネル コードによってアクセスされるアドレスは仮想アドレスです (アドレス マッピングは CPU 命令に対して透過的です)。ただし、アドレス マッピングの目的は物理アドレスを取得することであるため、アドレス マッピングを確立するときにカーネルによってページ テーブルに埋められる内容は物理アドレスになります。
では、カーネルはどのようにしてこの物理アドレスを取得するのでしょうか?実際、上で述べたように、mem_map 内のページは物理メモリに基づいて確立され、各ページは物理ページに対応します。
したがって、仮想アドレスのマッピングはここのページ構造によって完了し、最終的な物理アドレスが与えられると言えます。ただし、ページ構造は明らかに仮想アドレスを通じて管理されます (前述したように、CPU 命令は仮想アドレスを受け取ります)。したがって、ページ構造は他の人の仮想アドレス マッピングを実装しますが、ページ構造自体の仮想アドレス マッピングは誰が実装するのでしょうか?誰もそれを達成することはできません。
これにより、カーネル空間内のページ テーブル エントリがハードコーディングされるという、前述した問題が発生します。カーネルが初期化されると、アドレス マッピングがカーネルのアドレス空間にハードコーディングされます。ページ構造は明らかにカーネル空間に存在するため、そのアドレス マッピングの問題は「ハードコーディング」によって解決されています。
カーネル空間のページ テーブル エントリはハードコーディングされているため、NORMAL (または DMA) 領域のメモリがカーネル空間とユーザー空間の両方にマッピングされる可能性があるという別の問題が発生します。このマッピングはハードコーディングされているため、カーネル空間にマッピングされることは明らかです。これらのページはユーザー空間にマップされることもあります。これは、前述のページ欠落例外シナリオで発生する可能性があります。ユーザー空間にマッピングされたページは、最初に HIGH 領域から取得する必要があります。これらのメモリはカーネルがアクセスするには不便なので、ユーザー空間に割り当てるのが最善です。ただし、HIGH 領域が枯渇したり、デバイスの物理メモリ不足によりシステム内に HIGH 領域が存在しない可能性があるため、NORMAL 領域をユーザー空間にマッピングすることは避けられません。
ただし、NORMAL 領域のメモリがカーネル空間とユーザー空間の両方にマッピングされていても問題はありません。ページがカーネルによって使用されている場合、対応するページは free_area から削除されているはずなので、ページ フォールト例外が発生します。このページはユーザー空間にマップされています。逆も同様で、ユーザー空間にマップされたページは当然 free_area から削除され、カーネルはこのページを使用しなくなります。
メモリのページ全体を使用することに加えて、ユーザー プログラムが malloc を使用するのと同じように、カーネルは任意のサイズのスペースを割り当てる必要がある場合もあります。この機能はスラブシステムによって実現されます。
スラブは、タスク構造に対応するプール、mm 構造に対応するプールなど、カーネルで一般的に使用されるいくつかの構造オブジェクトのオブジェクト プールを確立することに相当します。
スラブは、「32 バイト サイズ」のオブジェクト プール、「64 バイト サイズ」のオブジェクト プールなどの一般的なオブジェクト プールも維持します。カーネルで一般的に使用される kmalloc 関数 (ユーザーモードの malloc と同様) は、これらの汎用オブジェクト プールに割り当てられます。
オブジェクトによって実際に使用されるメモリ空間に加えて、スラブには対応する制御構造もあります。オブジェクトを編成するには 2 つの方法があります。オブジェクトが大きい場合、コントロール構造は特別なページを使用してオブジェクトを保存します。オブジェクトが小さい場合、コントロール構造はオブジェクト スペースと同じページを使用します。
Linux 2.6 では、スラブに加えて、mempool (メモリ プール) も導入されました。その目的は、メモリ不足により特定のオブジェクトの割り当てが失敗することを望まないため、事前にいくつかのオブジェクトを割り当てて mempool に保存することです。通常の状況では、オブジェクトを割り当てるときに mempool 内のリソースには触れず、通常どおりスラブを通じて割り当てられます。システム メモリが不足し、スラブを介してメモリを割り当てることができなくなると、メモリプールの内容が使用されます。
ページのスワップインとスワップアウトも、非常に複雑なシステムです。メモリ ページをディスクにスワップアウトすることと、ディスク ファイルをメモリにマッピングすることは、2 つの非常によく似たプロセスです (メモリ ページをディスクにスワップアウトする動機は、将来的にページをディスクからメモリにロードし直すことです)。したがって、スワップはファイル サブシステムのいくつかのメカニズムを再利用します。
ページのインとスワップアウトは CPU と IO を非常に集中的に使用する問題ですが、メモリが高価であるという歴史的な理由により、メモリを拡張するにはディスクを使用する必要があります。しかし、メモリが安くなった今では、数ギガバイトのメモリを簡単に取り付けて、スワップ システムをシャットダウンすることができます。したがって、スワップの実装は検討するのが非常に難しいため、ここでは詳しく説明しません。 (参照:「Linux カーネル ページのリサイクルの簡単な分析」)
libc がメモリを割り当てる方法は 2 つあり、1 つはヒープのサイズを調整する方法、もう 1 つは新しい仮想メモリ領域を mmap する方法です (ヒープは vma でもあります)。
カーネルでは、ヒープは固定端と格納可能な端を備えた vma です (写真: 中央左)。スケーラブルエンドは brk システムコールを通じて調整されます。 Libc はヒープ領域を管理し、ユーザーがメモリを割り当てるために malloc を呼び出すと、libc は既存のヒープからメモリを割り当てようとします。ヒープ領域が足りない場合は、brk を使用してヒープ領域を増やしてください。
ユーザーが割り当てられた領域を解放すると、libc は brk を通じてヒープ領域を削減する可能性があります。ただし、ヒープ領域を増やすのは簡単ですが、減らすのは困難です。ユーザー領域が継続的に 10 ブロックのメモリを割り当て、最初の 9 ブロックが解放された状況を考えてみましょう。このとき、空きのない 10 番目のブロックのサイズが 1 バイトしかない場合でも、libc はヒープ サイズを削減できません。伸縮できるのはパイルの片方の端だけで、真ん中をくりぬくことはできないからです。メモリの 10 番目のブロックはヒープのスケーラブルな端を占有します。ヒープのサイズを減らすことはできず、関連リソースをカーネルに返すこともできません。
ユーザーが大きなメモリを割り当てた場合、libc は mmap システム コールを通じて新しい vma をマップします。ヒープサイズの調整や領域管理はやはり面倒なので、vmaを再構築した方が便利です(前述の空きの問題も理由の一つです)。
それでは、malloc 中に常に新しい vma を mmap しないのはなぜでしょうか?まず、小さなスペースの割り当てとリサイクルについては、libc によって管理されるヒープ スペースですでにニーズを満たすことができ、毎回システム コールを行う必要がありません。また、vma はページに基づいており、少なくとも 1 ページを割り当てる必要があります。次に、vma が多すぎるとシステムのパフォーマンスが低下します。ページフォールト例外、vma の作成と破棄、ヒープ領域のサイズ変更などはすべて vma での操作が必要です。現在のプロセス内のすべての vma の中から操作する必要がある vma (複数可) を見つける必要があります。 vmas が多すぎると、必然的にパフォーマンスの低下につながります。 (プロセスの VMA が少ない場合、カーネルはリンク リストを使用して VMA を管理します。VMA が多い場合は、代わりに赤黒ツリーが使用されます。)
しかし、ESP の値はユーザーモードのプログラムで自由に読み書きできるため、ユーザープログラムが ESP を調整してスタックを非常に大きくした場合はどうなるでしょうか。カーネルにはスタックサイズの設定を含むプロセス制限に関する一連の設定があり、スタックは大きくすることができ、それを超えるとエラーが発生します。
プロセスの場合、スタックは通常、比較的大きく拡張される可能性があります (例: 8MB)。しかし、スレッドについてはどうでしょうか?
まず、スレッドスタックで何が起こっているのでしょうか?前述したように、スレッドの mm は親プロセスを共有します。スタックは mm 単位の vma ですが、スレッドはこの vma を親プロセスと共有できません (実行中の 2 つのエンティティがスタックを共有する必要がないことは明らかです)。したがって、スレッドが作成されると、スレッド ライブラリは mmap を介してスレッドのスタック (通常は 2M より大きい) として新しい vma を作成します。
スレッドのスタックは、ある意味では実際のスタックではなく、固定領域であり、容量が非常に限られていることがわかります。
以上がLinux メモリ管理: 仮想メモリと物理メモリを変換して割り当てる方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。