
ホームページ >システムチュートリアル >Linux >Linux カーネルの CPU 負荷分散メカニズム: 原理、プロセス、最適化
Linux カーネルの CPU 負荷分散メカニズム: 原理、プロセス、最適化

- 王林転載
- 2024-02-09 13:50:111368ブラウズ
CPU 負荷分散とは、各 CPU の負荷が可能な限り分散されるように、実行中のプロセスまたはタスクをマルチコアまたはマルチプロセッサ システムの異なる CPU に割り当て、それによってシステムのパフォーマンスと効率を向上させることを指します。 CPU 負荷分散は Linux カーネルの重要な機能であり、これにより Linux システムがマルチコアまたはマルチプロセッサを最大限に活用して、さまざまなアプリケーション シナリオやニーズに適応できるようになります。しかし、Linux カーネルの CPU 負荷分散メカニズムを本当に理解していますか?その動作原理、プロセス、最適化方法をご存知ですか?この記事では、Linux カーネルの CPU 負荷分散メカニズムに関する関連知識を詳しく紹介し、Linux でこの強力なカーネル機能をよりよく使用し、理解できるようにします。
これは依然として、魔法のプロセス スケジューリングの問題が原因です。Linux プロセス グループ スケジューリング メカニズムの分析を参照してください。グループ スケジューリング メカニズムがはっきりとわかります。再起動プロセス中に、多くのカーネル コール スタックがブロックされていることがわかります。 double_rq_lock 関数上で、double_rq_lock がload_balance. それがトリガーされました. その際、コア間のスケジューリングに問題があるのではないかと疑われ、ある責任のあるシナリオでマルチコア連動が発生しました. 後でコードを見てみたCPU負荷分散のもとで実装し、まとめを書きました。
カーネル コード バージョン: kernel-3.0.13-0.27。
カーネル コード関数は、load_balance 関数から始まります。load_balance 関数から、それを参照する関数を見ると、スケジュール関数がここに見つかります。ここから、下に見てください。__schedule に次の文があります。
リーリー上記のことから、カーネルがいつ CPU 負荷分散を実行しようとするかがわかります。つまり、現在の CPU 実行キューが NULL の場合です。
CPU ロード バランシングには、プルとプッシュの 2 つの方法があります。つまり、アイドル状態の CPU が他のビジー CPU キューから現在の CPU キューにプロセスをプルするか、ビジー CPU キューがプロセスをアイドル状態の CPU キューにプッシュします。 idle_balance が行うのはプルですが、具体的なプッシュについては後述します。
idle_balance には、現在の CPU がプルであるかどうかを制御する proc バルブがあります:
sysctl_sched_migration_cost に対応する proc 制御ファイルは /proc/sys/kernel/sched_migration_cost です。このスイッチは、CPU キューが 500us (sysctl_sched_migration_cost のデフォルト値) を超えてアイドル状態である場合はプルが実行され、そうでない場合はプルが返されることを意味します。 。
for_each_domain(this_cpu, sd) は、現在の CPU が配置されているスケジューリング ドメインを横断します。task_group と同様に、CPU グループとして直感的に理解できます。コア間バランスとは、グループ内のバランスを指します。ロード バランシングには矛盾があります。ロード バランシングの頻度と CPU キャッシュのヒット率は矛盾しています。CPU スケジューリング ドメインは、各 CPU を異なるレベルのグループに分割します。低レベルで達成されたバランスは、決してレベルにアップグレードされません。処理レベルが高く、キャッシュ ヒット率への影響を回避します。
イラストは次のとおりです;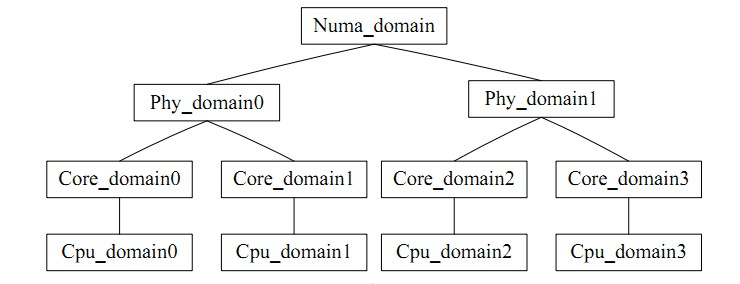
いよいよload_balanceを通して本題に入ります。
まず、find_busiest_group を使用して現在のスケジューリング ドメインで最もビジーなスケジューリング グループを取得します。まず、update_sd_lb_stats が sd のステータスを更新します。つまり、対応する sd を走査し、次のように sds 内の構造データを埋めます。 リーリー リーリー
スケジューリング ドメインで最もビジーなグループを選択するための参照基準は、グループ内のすべての CPU の負荷の合計です。グループ内でビジーな実行キューを見つけるための参照基準は、CPU 実行キューの長さです。 、つまり負荷であり、負荷の値が大きいほどビジーであることを示します。バランシング プロセス中に、現在のキューの負荷ステータスを以前に記録された最もビジーな状態と比較することにより、これらの変数がタイムリーに更新され、最もビジーなグループが常にドメイン内で最もビジーなグループを指すようになり、検索が容易になります。
スケジューリングドメインの平均負荷計算
リーリー
次に、find_busiest_queue で最もビジーなスケジューリング キューを見つけ、グループ内のすべての CPU キューを走査し、各キューの負荷を順番に比較して最もビジーなキューを見つけます。
リーリー
Busiest->nr_running の値が 1 より大きい場合、プル操作が実行されますが、プルの前に move_tasks は double_rq_lock によってロックされます。
リーリー
以下は、選択したプロセスが移行可能かどうかを確認する can_merge_task 関数です。移行が失敗する理由は 3 つあります。1. 移行されたプロセスは実行中です。2. プロセスはコア バインドされており、ターゲット CPU に移行できません。3.プロセス キャッシュはまだホットです。これはキャッシュ ヒット率を確保するためでもあります。
リーリー
に対応するプロセス制御スイッチ sysctl_sched_migration_cost を超えています。
static int
task_hot(struct task_struct *p, u64 now, struct sched_domain *sd)
{
s64 delta;
delta = now - p->se.exec_start;
return delta
在load_balance中,move_tasks返回失败也就是ld_moved==0,其中sd->nr_balance_failed++对应can_migrate_task中的”too many balance attempts have failed”,然后busiest->active_balance = 1设置,active_balance = 1。
if (active_balance) //如果pull失败了,开始触发push操作 stop_one_cpu_nowait(cpu_of(busiest), active_load_balance_cpu_stop, busiest, &busiest->active_balance_work);
push整个触发操作代码机制比较绕,stop_one_cpu_nowait把active_load_balance_cpu_stop添加到cpu_stopper每CPU变量的任务队列里面,如下:
void stop_one_cpu_nowait(unsigned int cpu, cpu_stop_fn_t fn, void *arg,
struct cpu_stop_work *work_buf)
{
*work_buf = (struct cpu_stop_work){ .fn = fn, .arg = arg, };
cpu_stop_queue_work(&per_cpu(cpu_stopper, cpu), work_buf);
}
而cpu_stopper则是cpu_stop_init函数通过cpu_stop_cpu_callback创建的migration内核线程,触发任务队列调度。因为migration内核线程是绑定每个核心上的,进程迁移失败的1和3问题就可以通过push解决。active_load_balance_cpu_stop则调用move_one_task函数迁移指定的进程。
上面描述的则是整个pull和push的过程,需要补充的pull触发除了schedule后触发,还有scheduler_tick通过触发中断,调用run_rebalance_domains再调用rebalance_domains触发,不再细数。
void __init sched_init(void)
{
open_softirq(SCHED_SOFTIRQ, run_rebalance_domains);
}
通过本文,你应该对 Linux 内核的 CPU 负载均衡机制有了一个深入的了解,知道了它的定义、原理、流程和优化方法。你也应该明白了 CPU 负载均衡机制的作用和影响,以及如何在 Linux 下正确地使用和配置它。我们建议你在使用多核或多处理器的 Linux 系统时,使用 CPU 负载均衡机制来提高系统的性能和效率。同时,我们也提醒你在使用 CPU 负载均衡机制时要注意一些潜在的问题和挑战,如负载均衡策略、能耗、调度延迟等。希望本文能够帮助你更好地使用 Linux 系统,让你在 Linux 下享受 CPU 负载均衡机制的优势和便利。
以上がLinux カーネルの CPU 負荷分散メカニズム: 原理、プロセス、最適化の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。