
ホームページ >テクノロジー周辺機器 >AI >レア! Apple のオープンソース画像編集ツール MGIE は iPhone で利用できるようになりますか?
レア! Apple のオープンソース画像編集ツール MGIE は iPhone で利用できるようになりますか?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2024-02-05 15:33:291311ブラウズ
写真を撮ってテキスト コマンドを入力すると、携帯電話が自動的に写真のレタッチを開始しますか?
この魔法の機能は、Apple が新たにオープンソース化した画像編集ツール「MGIE」から提供されます。

背景の人物を削除
ピザを追加テーブルへ
近年、画像編集においてはAIの進歩が著しい。一方で、AI はマルチモーダル ラージ モデル (MLLM) を通じて画像を入力として受け取り、視覚的な認識応答を提供することで、より自然な画像編集を実現できます。一方、指示ベース編集技術では、詳細な説明や領域マスクに頼らず、ユーザーが直接指示を出して編集方法や目的を表現できるようになります。この方法は人間の直感的な方法により近いため、非常に実用的です。これらの革新的なテクノロジーを通じて、AI は画像編集の分野で徐々に人々の右腕アシスタントになりつつあります。
Apple は、上記のテクノロジーからインスピレーションを得て、MLLM を使用して不十分な指示ガイダンスの問題を解決する MGIE (MLLM ガイド付き画像編集) を提案しました。

- #論文タイトル: マルチモーダル大規模言語モデルによる命令ベースの画像編集のガイド
- 論文リンク: https://openreview.net/pdf?id=S1RKWSyZ2Y
- プロジェクトのホームページ: https://mllm-ie.github.io/
MGIE (Mind-Guided Image Editing) は、図 2 に示すように、MLLM (Mind-Language Linking Model) と拡散モデルで構成されます。 MLLM は、簡潔な表現指示を習得することを学習し、明確で視覚的に適切なガイダンスを提供します。拡散モデルは、意図したターゲットの潜在的な想像力を使用して画像編集を実行し、エンドツーエンドのトレーニングを通じて同期的に更新されます。このように、MGIE は固有の視覚的導出の恩恵を受け、人間による曖昧な指示を解決して賢明な編集を実現できます。
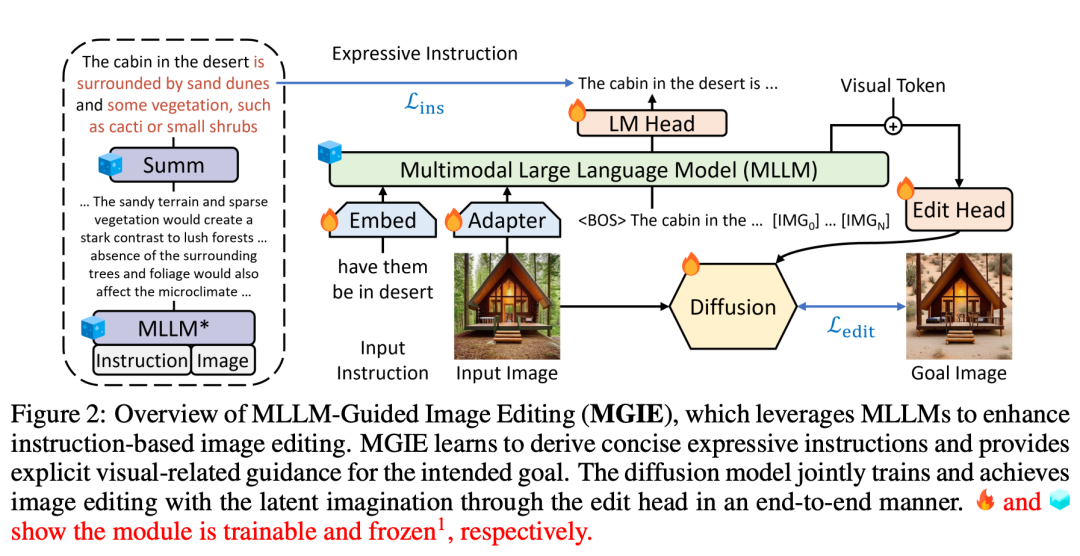
人間のコマンドに従って、MGIE は Photoshop スタイルの変更、グローバルな写真の最適化、およびローカル オブジェクトの変更を実行できます。例として下の写真を見てみましょう。追加のコンテキストがなければ「健康的」の意味を理解することは困難ですが、MGIE は「野菜のトッピング」をピザと正確に関連付け、人間の期待に応じて編集できます。

最近 Apple が発表した一連の生成 AI 理論研究結果と組み合わせると、Apple が次にリリースする新しい AI 機能が楽しみになりそうです。
本研究で提案するMGIE手法は、与えられた命令Xにより入力画像Vを目的画像に編集することができます。 命令の簡潔な表現 機能の調整と命令の調整を通じて、MLLM はクロスモーダルな認識とビジョンを提供できます。関連する回答。画像編集の場合、この研究では、画像の言語入力として「[命令] だとこの画像はどうなるでしょうか」というプロンプトを使用し、編集コマンドの詳細な説明を導き出します。ただし、これらの説明は長すぎることが多く、ユーザーの意図を誤解させることもあります。より簡潔な説明を得るために、この研究では事前トレーニング済みサマライザーを適用して、MLLM に要約出力の生成方法を学習させます。このプロセスは次のように要約できます: # 潜在的な想像力による画像編集 を使用して [IMG] を実際の視覚的なガイダンスに変換します。ここで、 , このモデルは、変分オートエンコーダー (VAE) を含みながら、潜在空間でのノイズ除去拡散問題も解決できます。 の根底にある想像力を活用することで、そのモダリティを変換し、結果として得られる画像の #実験評価
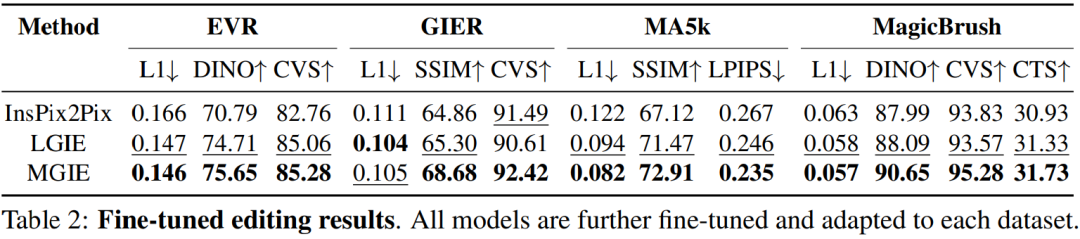
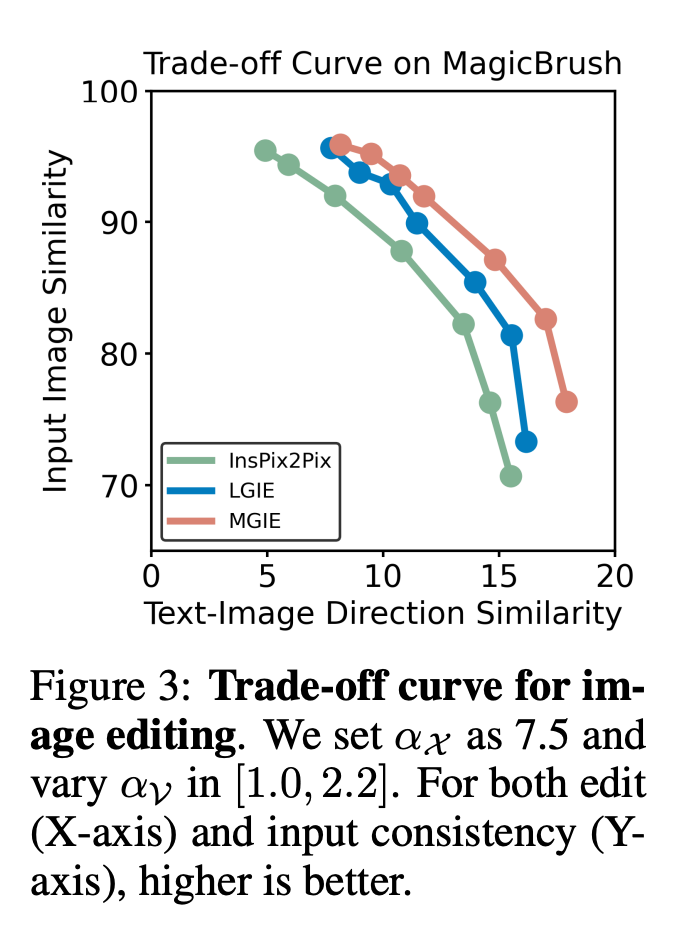
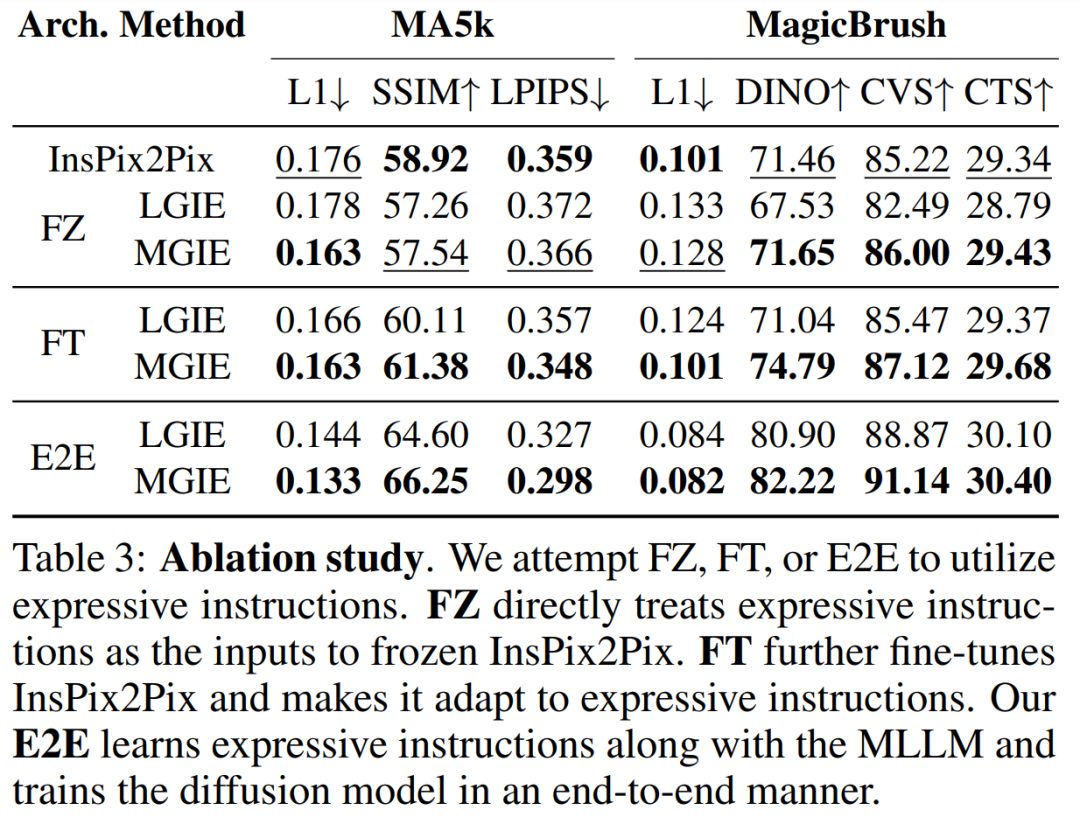
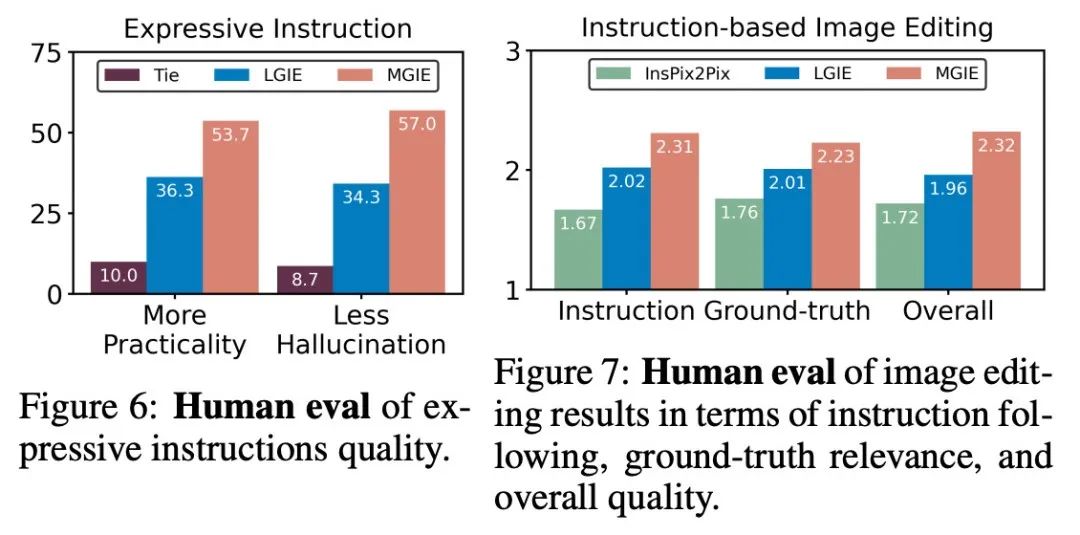
表 1 は、データセット IPr2Pr のみでトレーニングされたモデルのゼロショット編集結果を示しています。 Photoshop スタイルの変更を伴う EVR および GIER の場合、編集結果はブートストラップの意図に近づきました (たとえば、LGIE は EVR で 82.0 という高い CVS を達成しました)。 MA5k でのグローバル画像最適化の場合、関連するトレーニング トリプルが不足しているため、InsPix2Pix は扱いにくいです。 LGIE と MGIE は LLM の学習を通じて詳細な説明を提供できますが、LGIE はまだ単一のモダリティに限定されています。画像にアクセスすることで、MGIE はどの領域を明るくするか、どのオブジェクトをより鮮明にするかなどの明示的な指示を導き出すことができ、その結果、パフォーマンスが大幅に向上します (例: 66.3 SSIM が高く、写真距離が 0.3 低くなります)。同様の結果が MagicBrush でも見つかりました。 MGIE はまた、正確な視覚画像と、ターゲットとして指定されたターゲットの変更 (たとえば、82.2 DINO の高い視覚的類似性と 30.4 CTS の高いグローバル サブタイトル アラインメント) から最高のパフォーマンスを獲得します。 #特定の目的のための命令ベースの画像編集を研究するために、表 2 は各データセットのモデルを微調整します。 EVR と GIER では、すべてのモデルが Photoshop スタイルの編集タスクに適応すると改善されました。 MGIE は、編集のあらゆる面で一貫して LGIE を上回ります。これは、表現力豊かな指示を使用した学習が画像編集を効果的に強化できること、および最大限の強化のための明示的なガイダンスを得るには視覚認識が重要な役割を果たすことも示しています。 α_X と α_V の間のトレードオフ。画像編集には 2 つの目的があります。1 つは命令としてターゲットを操作すること、もう 1 つは入力画像の残りの部分を保持することです。図 3 は、命令 (α_X) と入力一貫性 (α_V) の間のトレードオフ曲線を示しています。この研究では、α_X を 7.5 に固定し、α_V を [1.0, 2.2] の範囲で変化させました。 α_V が大きいほど、編集結果は入力に似ていますが、命令との一貫性は低くなります。 X 軸は CLIP の方向の類似性、つまり編集結果が指示とどの程度一致しているかを計算し、Y 軸は CLIP ビジュアル エンコーダと入力画像の間の特徴の類似性を表します。特定の表現命令を使用すると、実験はすべての設定で InsPix2Pix を上回ります。さらに、MGIE は明示的な視覚的なガイダンスを通じて学習できるため、全体的な改善が可能になります。これにより、より多くの入力が必要な場合でも、関連性の編集が必要な場合でも、堅牢な改善がサポートされます。 アブレーション研究 さらに、研究者らはまた、命令を表現する際のさまざまなアーキテクチャ FZ、FT、および E2E のパフォーマンスを考慮したアブレーション実験も実施しました。結果は、MGIE が FZ、FT、および E2E で一貫して LGIE を上回っていることを示しています。これは、重要な視覚認識を備えた表現力豊かな指示が、すべてのアブレーション設定にわたって一貫した利点があることを示唆しています。 #MLLM ブートストラップが役立つのはなぜですか?図 5 は、入力またはグラウンドトゥルース ターゲット画像と表現命令の間の CLIP-Score 値を示しています。入力画像の CLIP-S スコアが高いほど、その指示が編集ソースに関連していることを示し、ターゲット画像との位置合わせが良好であれば、明確で関連性のある編集ガイダンスが提供されます。示されているように、MGIE は入力/目標との一貫性が高く、その表現力豊かな指示が役立つ理由が説明されています。 MGIE は、期待される結果を明確に説明することで、画像編集を最大限に改善することができます。
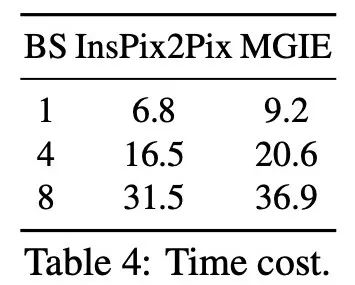
推論の効率。 MGIE は画像編集の推進に MLLM に依存していますが、簡潔な表現命令 (32 トークン未満) のみが導入されているため、効率は InsPix2Pix に匹敵します。表 4 に、NVIDIA A100 GPU での推論時間のコストを示します。単一入力の場合、MGIE は 10 秒で編集タスクを完了できます。データの並列処理を増やすと、必要な時間は同様になります (バッチ サイズ 8 で 37 秒)。プロセス全体は 1 つの GPU (40GB) だけで完了できます。 #定性的な比較。図 8 は、使用されたすべてのデータセットの視覚的な比較を示し、図 9 はさらに、LGIE または MGIE の表現命令を比較します。 論文詳細
 。これらの不正確な命令については、MGIE の MLLM が学習導出を実行して、簡潔な表現命令 ε を取得します。言語と視覚のモダリティの間に橋渡しをするために、研究者らはεの後に特別なトークン [IMG] を追加し、編集ヘッド
。これらの不正確な命令については、MGIE の MLLM が学習導出を実行して、簡潔な表現命令 ε を取得します。言語と視覚のモダリティの間に橋渡しをするために、研究者らはεの後に特別なトークン [IMG] を追加し、編集ヘッド 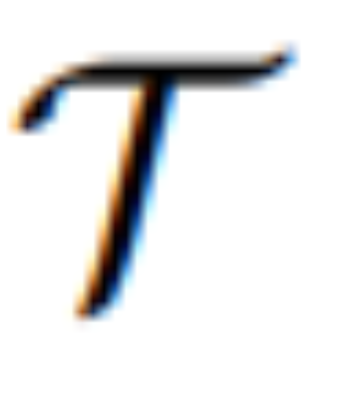 を使用してそれらを変換しました。変換された情報は、MLLM の基礎となる視覚的想像力として機能し、望ましい編集目標を達成するために拡散モデル
を使用してそれらを変換しました。変換された情報は、MLLM の基礎となる視覚的想像力として機能し、望ましい編集目標を達成するために拡散モデル 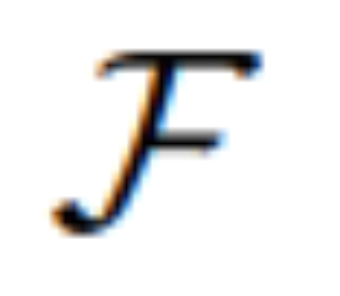 # を導きます。 MGIE は、視覚的に認識されたファジー コマンドを理解して、合理的な画像編集を実行できるようになります (アーキテクチャ図は上の図 2 に示されています)。
# を導きます。 MGIE は、視覚的に認識されたファジー コマンドを理解して、合理的な画像編集を実行できるようになります (アーキテクチャ図は上の図 2 に示されています)。 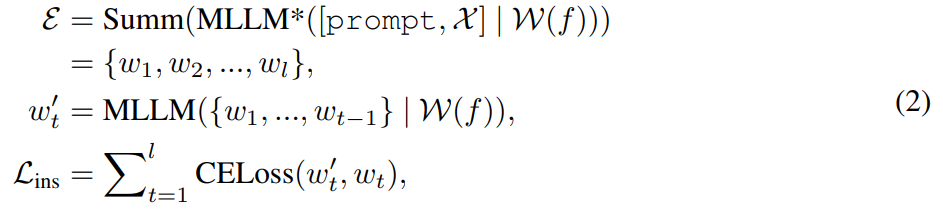
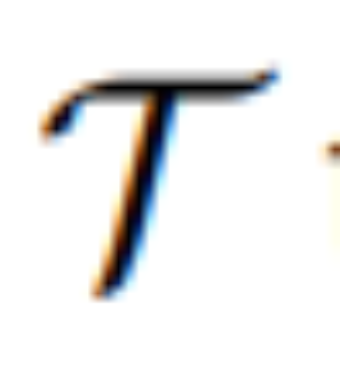 は、MLLM からの連続視覚トークンを意味的に意味のある潜在 U = {u_1, u_2, ..., u_L} にマッピングするシーケンスツーシーケンス モデルであり、編集ガイドとして機能します。 :
は、MLLM からの連続視覚トークンを意味的に意味のある潜在 U = {u_1, u_2, ..., u_L} にマッピングするシーケンスツーシーケンス モデルであり、編集ガイドとして機能します。 :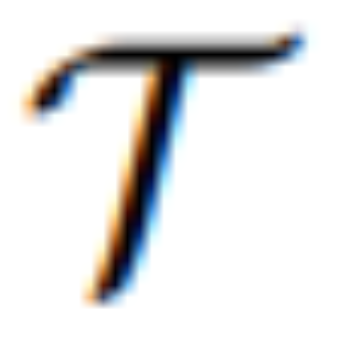
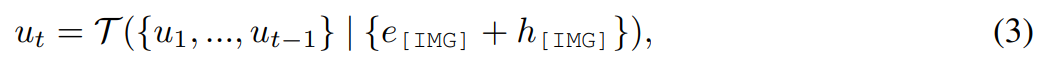
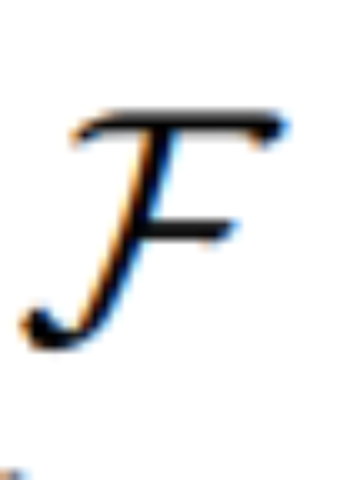
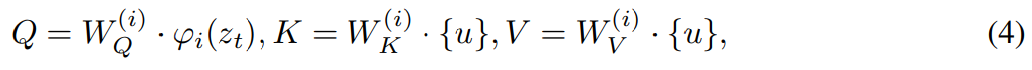 #アルゴリズム 1 は、MGIE の学習プロセスを示しています。 MLLM は、命令損失 L_ins を介してコンパクトな命令 ε を導出します。 [IMG]
#アルゴリズム 1 は、MGIE の学習プロセスを示しています。 MLLM は、命令損失 L_ins を介してコンパクトな命令 ε を導出します。 [IMG] 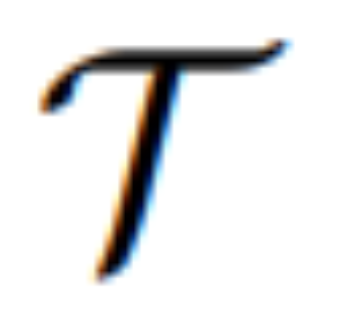 合成を導きます。編集損失 L_edit は拡散トレーニングに使用されます。ほとんどの重みを凍結できるため (MLLM 内のセルフ アテンション ブロック)、パラメータ効率の高いエンドツーエンドのトレーニングが実現します。
合成を導きます。編集損失 L_edit は拡散トレーニングに使用されます。ほとんどの重みを凍結できるため (MLLM 内のセルフ アテンション ブロック)、パラメータ効率の高いエンドツーエンドのトレーニングが実現します。 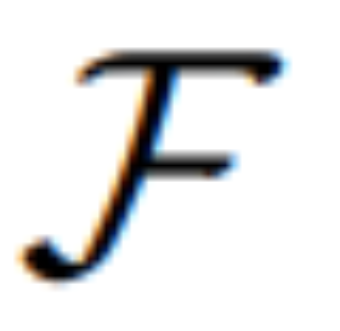

入力画像について、同じ命令の下で、異なる方法の違いを比較たとえば、指示の最初の行は「昼を夜に変える」です:



以上がレア! Apple のオープンソース画像編集ツール MGIE は iPhone で利用できるようになりますか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。