
ホームページ >テクノロジー周辺機器 >AI >OpenAIを打破し、重みもデータもコードもすべてオープンソースで、完璧に再現できる埋め込みモデルNomic Embedが登場しました。
OpenAIを打破し、重みもデータもコードもすべてオープンソースで、完璧に再現できる埋め込みモデルNomic Embedが登場しました。

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2024-02-04 09:54:151189ブラウズ
1 週間前、OpenAI はユーザーに特典を提供しました。彼らは GPT-4 が遅延するという問題を解決し、より小型で効率的な text-embedding-3-small 埋め込みモデルを含む 5 つの新しいモデルを導入しました。
エンベディングは、自然言語やコードなどで概念を表すために使用される一連の数値です。これらは、機械学習モデルやその他のアルゴリズムがコンテンツがどのように関連しているかをよりよく理解し、クラスタリングや検索などのタスクを実行しやすくするのに役立ちます。 NLP の分野では、埋め込みは非常に重要な役割を果たします。
ただし、OpenAI の埋め込みモデルは誰でも無料で使用できるわけではなく、たとえば、text-embedding-3-small では 1,000 トークンあたり $0.00002 の料金がかかります。
text-embedding-3-small よりも優れた埋め込みモデルが無料で登場しました。
AI スタートアップ企業である Nomic AI は、最近、オープンソース、オープンデータ、オープンウェイト、オープントレーニングコードである初の埋め込みモデル Nomic Embed をリリースしました。モデルは完全に再現可能で監査可能で、コンテキスト長は 8192 です。 Nomic Embed は、ショート コンテキストとロング コンテキストのベンチマークの両方で OpenAI の text-embeding-3-small モデルと text-embedding-ada-002 モデルを上回りました。この成果は、組み込みモデルの分野における Nomic AI の重要な進歩を示しています。

テキスト埋め込みは、検索拡張生成 (RAG) 機能を提供する最新の NLP アプリケーションの重要なコンポーネントです。 、LLM とセマンティック検索のサポートを提供します。この技術は、文や文書の意味情報を低次元ベクトルにエンコードし、データの視覚化、分類、情報検索のためのクラスタリングなどの下流アプリケーションに適用することで、より効率的な処理を可能にします。 現在、OpenAI の text-embedding-ada-002 は、最も人気のあるロングコンテキストのテキスト埋め込みモデルの 1 つであり、最大 8192 のコンテキスト長をサポートしています。ただし、残念なことに、Ada はクローズド ソースであり、そのトレーニング データは監査できないため、その信頼性が制限されています。それにもかかわらず、このモデルは依然として広く使用されており、多くの NLP タスクで良好なパフォーマンスを発揮します。 将来的には、信頼性と信頼性を向上させるために、より透明性が高く監査可能なテキスト埋め込みモデルを開発したいと考えています。これは、NLP 分野の発展を促進し、さまざまなアプリケーションにより効率的かつ正確なテキスト処理機能を提供するのに役立ちます。
E5-Mistral や jina-embeddings-v2-base-en など、最もパフォーマンスの高いオープンソースの長いコンテキスト テキスト埋め込みモデルには、いくつかの制限がある場合があります。一方で、モデルのサイズが大きいため、一般的な使用には適さない可能性があります。一方で、これらのモデルは、対応する OpenAI のパフォーマンス レベルを超えることができない可能性があります。したがって、特定のタスクに適したモデルを選択するときは、これらの要素を考慮する必要があります。
Nomic-embed のリリースにより、この状況が変わります。モデルには 1 億 3,700 万個のパラメーターしかなく、導入が非常に簡単で、5 日間でトレーニングできます。

論文アドレス: https://static.nomic.ai/reports/2024_Nomic_Embed_Text_Technical_Report.pdf
論文のタイトル: Nomic Embed: 再現可能な長いコンテキスト テキスト エンベッダーのトレーニング
プロジェクト アドレス: https://github.com/nomic-ai/contrastors
nomic-embed の構築方法
既存のテキスト エンコーダーの主な欠点の 1 つは、制限があることです。シーケンスの長さによって、512 トークンに制限されます。より長いシーケンスに対してモデルをトレーニングするには、最初に行うことは、長いシーケンス長に対応できるように BERT を調整することです。この研究のターゲット シーケンス長は 8192 でした。
コンテキスト長 2048 での BERT のトレーニング
この研究では、多段階の対照学習パイプラインに従ってトレーニングを行います。 nomic-embed 。まず、研究では BERT の初期化を実行しましたが、bert-base は最大 512 トークンのコンテキスト長しか処理できないため、研究ではコンテキスト長 2048 トークン (nomic-bert-2048) で独自の BERT をトレーニングすることにしました。
MosaicBERT に触発されて、研究チームは BERT のトレーニング プロセスに次のような変更を加えました。
- 回転位置埋め込みを使用してコンテキスト長の外挿を可能にします;
- モデルのパフォーマンスを向上させることが示されているため、SwiGLU アクティベーションを使用します;
- ドロップアウトを 0 に設定します。
#そして、次のトレーニングの最適化が実行されました:
- #トレーニングには Deepspeed と FlashAttend を使用します;
- BF16 の精度でトレーニングする;
- 語彙 (vocab) サイズを 64 の倍数に増やす;
- トレーニングバッチ サイズは 4096 です。
- #マスクされた言語モデリング プロセスでは、マスク率は 15% ではなく 30% になります。
- しないでください。次の文を使用してターゲットを予測します。
- トレーニング中に、研究では最大シーケンス長 2048 ですべてのステージをトレーニングし、推論中に動的 NTK 補間を使用してシーケンス長 8192 まで拡張しました。
実験
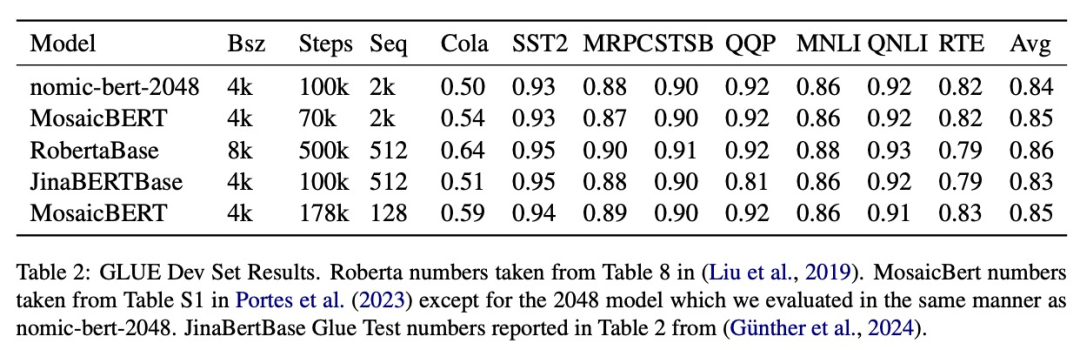
研究では、標準の GLUE ベンチマークで nomic-bert-2048 の品質を評価し、そのパフォーマンスが他のベンチマークと同等であることがわかりました。 BERT モデル 同等ですが、コンテキストの長さが大幅に長いという利点があります。
この研究では nomic-embed を使用します。 bert-2048 は nomic-embed トレーニングを初期化します。比較データセットは約 2 億 3,500 万のテキスト ペアで構成されており、その品質は収集中に Nomic Atlas を使用して広範囲に検証されました。
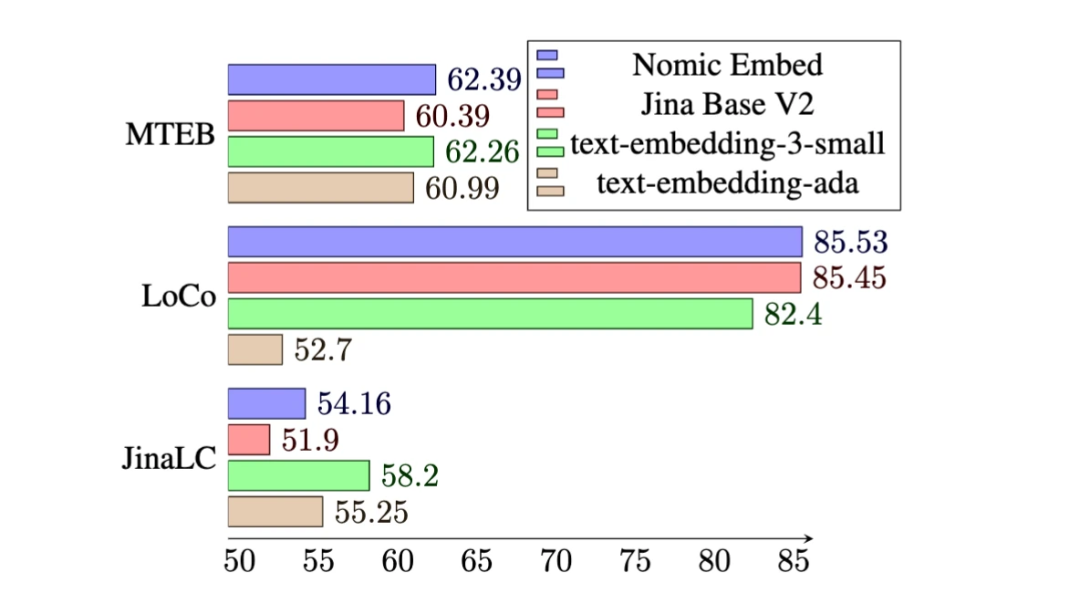
MTEB ベンチマークでは、nomic-embed は text-embedding-ada-002 および jina-embeddings-v2-base-en よりも優れたパフォーマンスを示します。
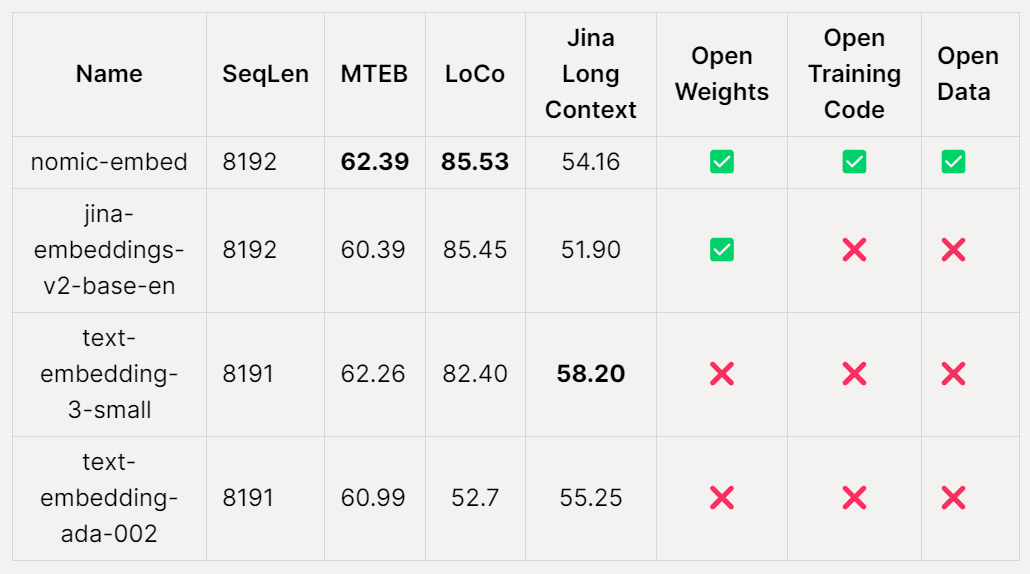 # ただし、MTEB は長いコンテキストのタスクを評価できません。したがって、この調査では、最近リリースされた LoCo ベンチマークと Jina Long Context ベンチマークで nomic-embed を評価します。
# ただし、MTEB は長いコンテキストのタスクを評価できません。したがって、この調査では、最近リリースされた LoCo ベンチマークと Jina Long Context ベンチマークで nomic-embed を評価します。
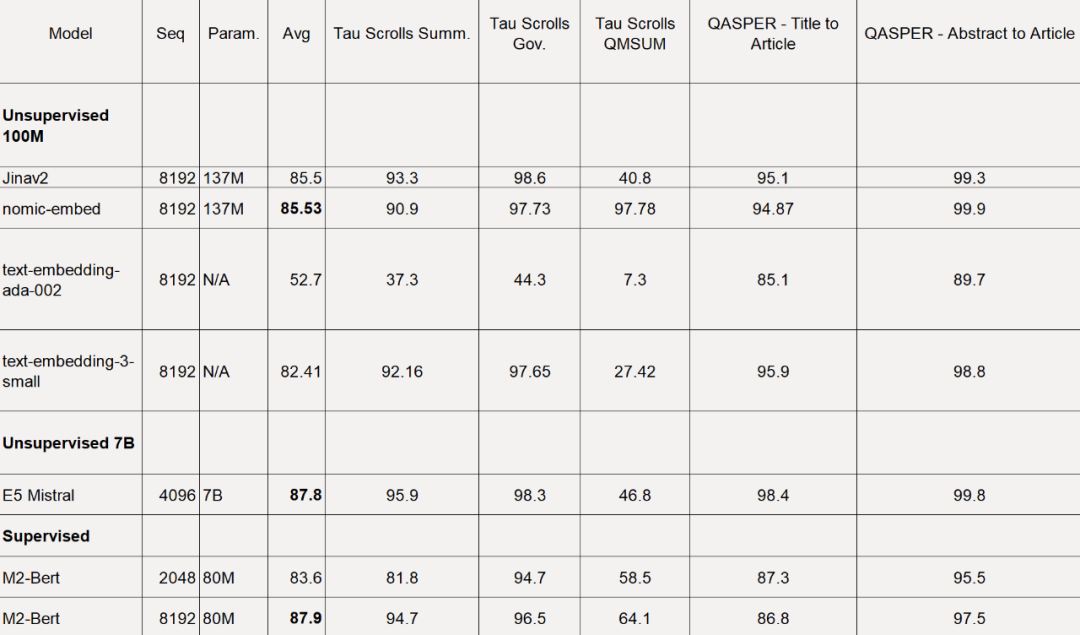
LoCo ベンチマークの場合、調査ではパラメータ カテゴリごとに、また評価が監視設定で実行されるか監視なし設定で実行されるかによって個別に評価されます。
以下の表に示すように、Nomic Embed は 100M パラメーターの教師なしモデルの中で最高のパフォーマンスを発揮します。特に、Nomic Embed は、7B パラメーター カテゴリの最高パフォーマンスのモデルや、監視された環境で LoCo ベンチマークで特別にトレーニングされたモデルと同等です。
 # Jina Long Context ベンチマークでも、Nomic Embed は jina-embeddings-v2-base-en よりも全体的に優れたパフォーマンスを示していますが、このベンチマークでは Nomic Embed は OpenAI ada-002 や text-embedding よりもパフォーマンスが優れていません。 :
# Jina Long Context ベンチマークでも、Nomic Embed は jina-embeddings-v2-base-en よりも全体的に優れたパフォーマンスを示していますが、このベンチマークでは Nomic Embed は OpenAI ada-002 や text-embedding よりもパフォーマンスが優れていません。 :
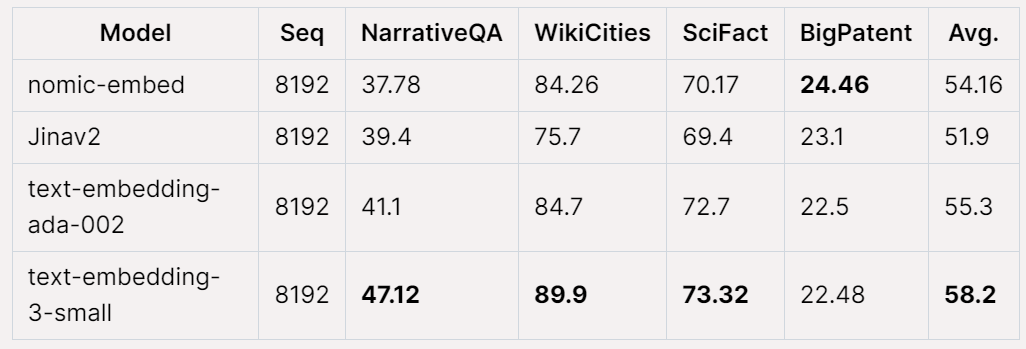 全体的に、Nomic Embed は OpenAI Ada-002 および text-embedding- 2/3 ベンチマーク 3-small を上回っています。
全体的に、Nomic Embed は OpenAI Ada-002 および text-embedding- 2/3 ベンチマーク 3-small を上回っています。
#調査結果では、Nomic Embed を使用するための最良のオプションは Nomic Embedding API であることが示されています。API を入手する方法は次のとおりです:
最後に、データ アクセス: 完全なデータにアクセスするために、この調査ではユーザーに Cloudflare R2 (AWS S3) を提供します。オブジェクトストレージサービスのような) アクセスキー。アクセスするには、ユーザーはまず Nomic Atlas アカウントを作成し、contrastors リポジトリの指示に従う必要があります。 
コントラストのアドレス: https://github.com/nomic-ai/contrastors?tab=readme-ov-file#data-access
以上がOpenAIを打破し、重みもデータもコードもすべてオープンソースで、完璧に再現できる埋め込みモデルNomic Embedが登場しました。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。