
ホームページ >テクノロジー周辺機器 >AI >人間と同じように批判から学び成長しましょう。1317 件のコメントで LLaMA2 の勝率は 30 倍になりました
人間と同じように批判から学び成長しましょう。1317 件のコメントで LLaMA2 の勝率は 30 倍になりました

- PHPz転載
- 2024-02-04 09:20:38744ブラウズ
既存の大規模モデル アライメント手法には、example ベースの教師あり微調整 (SFT) および スコア フィードバックベースの強化学習 (RLHF) が含まれます。ただし、スコアは現在の応答の品質を反映することしかできず、モデルの欠点を明確に示すことはできません。対照的に、私たち人間は通常、言葉によるフィードバックから行動パターンを学習し、調整します。レビューのコメントは単なるスコアではなく、承認または拒否の多くの理由も含まれています。
では、大規模な言語モデルも人間と同じように言語フィードバックを使用して自らを改善できるのでしょうか?
香港中文大学とテンセント AI ラボの研究者らは最近、対照的尤度学習 (CUT) と呼ばれる革新的な研究を提案しました。この研究では、言語フィードバックを使用して言語モデルを調整し、人間と同じようにさまざまな批判から学習して改善できるようにしています。この研究は、言語モデルの品質と精度を向上させ、人間の思考方法との一貫性を高めることを目的としています。研究者らは、非尤度トレーニングを比較することで、言語モデルが多様な言語使用状況をよりよく理解して適応できるようになり、それによって自然言語処理タスクのパフォーマンスが向上することを期待しています。この革新的な研究は、言語モデル
#CUT のためのシンプルで効果的な方法を提供すると期待されています。わずか 1317 個の言語フィードバック データを使用することで、CUT は AlpacaEval での LLaMA2-13b の勝率を 1.87% から 62.56% に大幅に向上させることができ、175B DaVinci003 を破ることに成功しました。興味深いのは、CUT が他の強化学習や強化学習強化フィードバック (RLHF) フレームワークと同様に、探索、批判、改善の反復サイクルを実行できることです。このプロセスでは、自動評価モデルによって批判段階が完了し、システム全体の自己評価と改善が達成されます。
著者は LLaMA2-chat-13b で 4 ラウンドの反復を実行し、AlpacaEval でのモデルのパフォーマンスを 81.09% から 91.36% まで徐々に改善しました。スコア フィードバック (DPO) に基づくアライメント テクノロジと比較して、CUT は同じデータ サイズの下でより優れたパフォーマンスを発揮します。この結果は、言語フィードバックがアライメントの分野で発展する大きな可能性を秘めていることを明らかにし、将来のアライメント研究に新たな可能性を切り開くものです。この発見は、アライメント技術の精度と効率の向上に重要な意味を持ち、より良い自然言語処理タスクを達成するための指針を提供します。

- 論文のタイトル: 拒否する理由? 言語モデルと判断の調整
- 紙のリンク: https://arxiv.org/abs/2312.14591
- Github リンク: https://github.com/wwxu21 /CUT
大きなモデルの位置合わせ
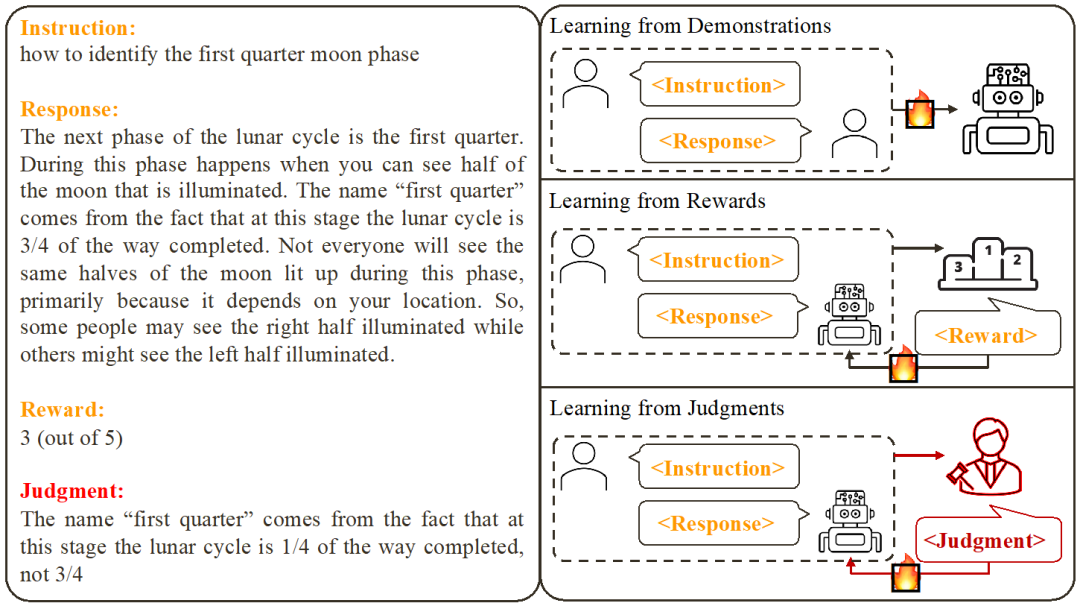
既存の作業に基づいて、研究者らは、2 つの一般的な大規模モデルの位置合わせ方法を要約しました:
1. デモンストレーションから学ぶ: 既製の指示に基づく - 「はい」と回答し、教師ありトレーニング方法を使用して大規模モデルを位置合わせします。
利点: 安定したトレーニング、簡単な実装。- 欠点: 高品質で多様なサンプル データを収集するコストは高くなります。エラー応答から学習することは不可能です。サンプル データは多くの場合、モデルとは無関係です。
- 2. 報酬からの学習: コマンドと応答のペアをスコアリングし、強化学習を使用して応答スコアを最大化するようにモデルをトレーニングします。
利点: 正しい応答とエラー応答を同時に使用できます。フィードバック信号はモデルに関連しています。
- 欠点: フィードバック信号がまばらであるため、トレーニング プロセスが複雑になることがよくあります。
- この研究は、言語フィードバック (判断からの学習) からの学習に焦点を当てています。言語フィードバックに基づいて、指示を与える - コメントの書き込みに返信するモデルの欠点を除去し、モデルの利点を維持することで、モデルのパフォーマンスが向上します。
言語フィードバックはスコア フィードバックの利点を継承していることがわかります。スコア フィードバックと比較して、口頭フィードバックはより有益です。口頭フィードバックは、モデルに何が正しくて何が間違っていたかを推測させる代わりに、詳細な欠陥や改善の方向性を直接指摘できます。しかし、残念なことに、研究者らは、現時点では口頭によるフィードバックを完全に活用する効果的な方法がないことを発見しました。この目的を達成するために、研究者たちは言語フィードバックを最大限に活用するように設計された革新的なフレームワーク CUT を提案しました。
対比非尤度トレーニング
CUT の中心的な考え方は、対比から学ぶことです。研究者は、さまざまな条件下で大規模モデルの応答を比較し、どの部分が満足していて維持する必要があり、どの部分に欠陥があり、修正が必要かを特定します。これに基づいて、研究者は最尤推定 (MLE) を使用して満足のいく部分をトレーニングし、尤度トレーニング (UT) を使用して応答の欠陥を修正します。
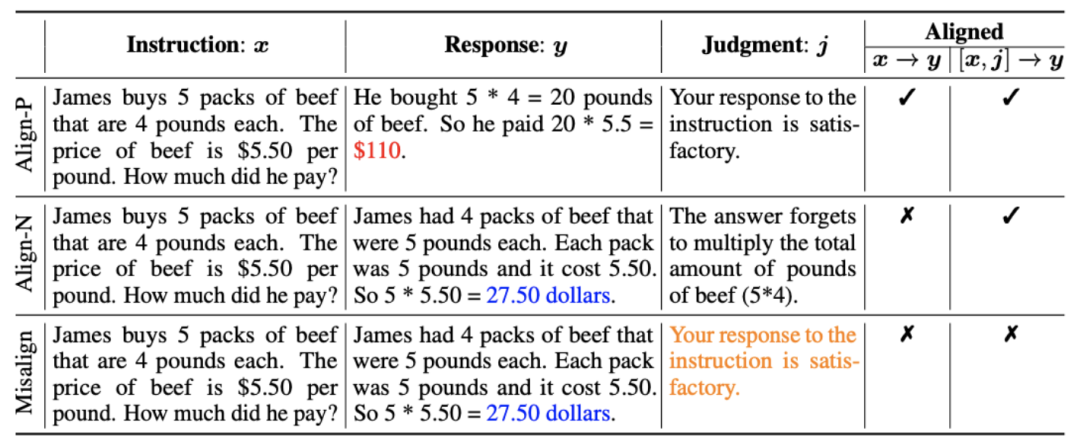
1. アライメント シナリオ : 上の図に示すように、研究者は 2 つのアライメント シナリオを検討しました。
a): これは一般的に理解されている調整シナリオであり、返信は指示に忠実に従い、人間の期待や価値観と一致する必要があります。 
: このシナリオでは、追加の条件として口頭によるフィードバックが導入されています。このシナリオでは、応答は指示と口頭フィードバックの両方を満たす必要があります。たとえば、否定的なフィードバックを受け取った場合、大規模モデルは、対応するフィードバックで言及されている問題に基づいて間違いを犯す必要があります。 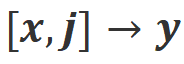
アライメント データ : 上の図に示すように、上記の 2 つのアライメント シナリオに基づいて、研究者は 3 種類のアライメント データを構築しました。 ##a) Align-P: 大規模モデルは 満足のいく
応答を生成し、肯定的なフィードバックを受け取りました。明らかに、Align-P は シナリオと シナリオの両方でアラインメントを満たします。 
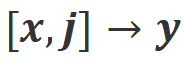 b) Align-N: 大規模モデルは欠陥のある (青の太字) 応答を生成したため、否定的なフィードバックを受けました。 Align-N の場合、
b) Align-N: 大規模モデルは欠陥のある (青の太字) 応答を生成したため、否定的なフィードバックを受けました。 Align-N の場合、
でアライメントが満たされていません。しかし、この否定的なフィードバックを考慮した後でも、Align-N は依然として シナリオに沿っています。 
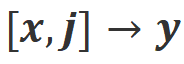 c) ミスアライン: Align-N の実際の負のフィードバックは、偽の正のフィードバックに置き換えられます。明らかに、Misalign は
c) ミスアライン: Align-N の実際の負のフィードバックは、偽の正のフィードバックに置き換えられます。明らかに、Misalign は
シナリオと シナリオの両方で位置合わせを満たしていません。 
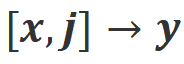 3. コントラストから学ぶ
3. コントラストから学ぶ
a) 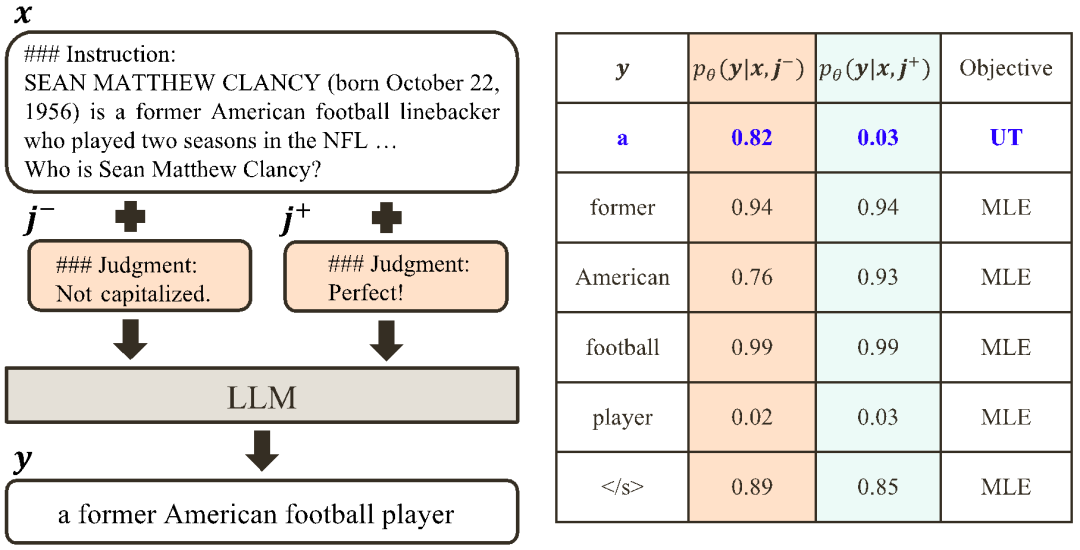 Align-N と Misalign
Align-N と Misalign
での位置合わせの程度です。大規模モデルの強力なコンテキスト内学習機能を考慮すると、Align-N から Misalign へのアライメント極性の反転は、通常、特定の単語、特に実際の負のフィードバックと密接に関連する単語の生成確率の大幅な変化を伴います。上の図に示すように、Align-N (左チャンネル) の条件下では、大きなモデルが「a」を生成する確率は、Misalign (右チャンネル) よりも大幅に高くなります。そして、確率が大きく変わる場所は、大きなモデルがミスをする場所です。 この比較から学ぶために、研究者たちはAlign-NデータとMisalignデータを同時に大規模モデルに入力し、2つの条件下での出力単語の生成確率を取得しました ここで は取引されるハイパーパラメータです。不適切な単語認識中に精度と再現率が低下します。
は応答単語の数です。 での位置合わせの程度にあります。 。基本的に、大規模モデルは、さまざまな極性の言語フィードバックを導入することによって、出力応答の品質を制御します。したがって、この 2 つの比較により、大規模なモデルが満足のいく応答と欠陥のある応答を区別できるようになります。具体的には、次の最尤推定 (MLE) 損失を介して、この一連の比較から学習します。 アライメントを満たしている場合は 1 を返し、そうでない場合は 0 を返すインジケータ関数です。 実験評価 順番Qian を救うために、研究者らはまず既存の言語フィードバック データを使用して大規模なモデルを調整しようとしました。この実験は、言語フィードバックを利用する CUT の能力を実証するために使用されました。
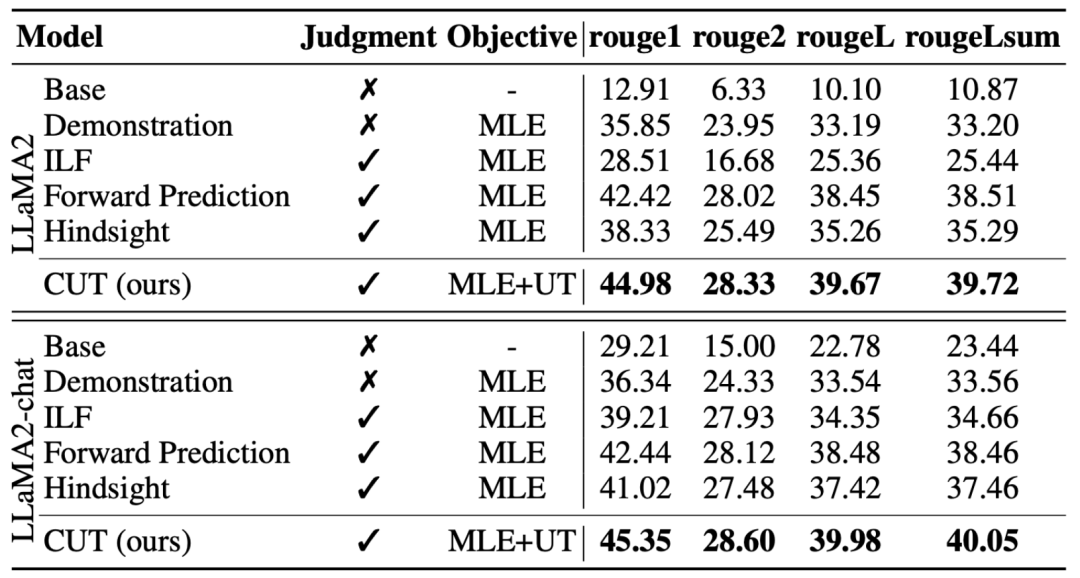
上の表に示すように、一般的なモデルのアライメントでは、研究者らは Shepherd が提供した 1317 個のアライメント データを使用して、コールド スタート (LLaMA2) 条件とホット スタート (LLaMA2-chat) 条件での CUT を既存の方法と比較しました。言語的なフィードバックから学習します。 LLaMA2 に基づくコールド スタート実験では、CUT は AlpacaEval テスト プラットフォーム上の既存のアライメント手法を大幅に上回り、言語フィードバックの利用における利点を十分に証明しました。さらに、CUT は基本モデルと比較して TruthfulQA においても大幅な改善を達成しました。これは、CUT が大規模モデルの幻覚問題を軽減する上で大きな可能性を持っていることを明らかにしています。 LLaMA2 チャットに基づくホット スタート シナリオでは、既存の方法では LLaMA2 チャットの改善が不十分であり、悪影響さえあります。ただし、CUT はこれに基づいて基本モデルのパフォーマンスをさらに向上させることができ、言語フィードバックの利用における CUT の大きな可能性が再度検証されます。 b) エキスパート モデル 研究者らは、特定のエキスパート タスク (要約テキスト) についてもテストしました。 CUTアライメント効果。上の表に示されているように、CUT は、エキスパート タスクに関する既存の調整方法と比較して大幅な改善も実現しています。 2. オンライン アライメント オフライン アライメントに関する研究により、CUT の強力なアライメント パフォーマンスが実証されました。現在、研究者は、より実用的なアプリケーションに近いオンライン調整シナリオをさらに研究しています。このシナリオでは、研究者はターゲットの大規模モデルの応答に言語フィードバックで繰り返し注釈を付け、ターゲット モデルに関連付けられた言語フィードバックに基づいてターゲット モデルをより正確に調整できるようにします。具体的なプロセスは次のとおりです。 3. AI コメントモデル
これは、AI コメント モデルを使用してターゲットの大規模モデルを調整する実現可能性を証明し、調整プロセス全体におけるコメント モデルの品質の重要性も強調しています。この一連の実験は、将来のアノテーションのコストを削減するための強力なサポートも提供します。 4. 言語フィードバックとスコア フィードバック 大規模なモデルの調整における言語フィードバックの大きな可能性を深く調査するために、研究者は言語フィードバックに基づく CUT とスコア フィードバック (DPO) に基づく方法を比較しました。公平な比較を保証するために、研究者らは実験サンプルとして同じ命令と応答のペアの 4,000 セットを選択し、CUT と DPO がそれぞれこれらのデータに対応するスコア フィードバックと言語フィードバックから学習できるようにしました。 上記の表に示すように、コールド スタート (LLaMA2) 実験では、CUT が DPO よりも大幅に優れたパフォーマンスを示しました。ホット スタート (LLaMA2 チャット) 実験では、CUT は ARC、HellaSwag、MMLU、TruthfulQA などのタスクで DPO と同等の結果を達成でき、AlpacaEval タスクでは DPO を大幅に上回っています。この実験により、大規模モデルのアライメント中の分数フィードバックと比較して、言語フィードバックの方が大きな可能性と利点があることが確認されました。 この研究では、研究者らは、大規模なモデルの調整における言語フィードバックの現状と革新性を体系的に調査しました。言語フィードバックに基づくアライメント フレームワーク CUT は、大規模モデル アライメントの分野における言語フィードバックの大きな可能性と利点を明らかにします。さらに、言語フィードバックの研究には、次のような新しい方向性と課題があります: #1. コメント モデルの品質#: 研究ではありますが、研究者らはレビュー モデルのトレーニングの実現可能性を実証することに成功しましたが、モデルの出力を観察すると、レビュー モデルが正確とは言えないレビューを提供することが多いことが依然としてわかりました。したがって、レビューモデルの品質を向上させることは、将来的に調整のための言語フィードバックを大規模に使用するために非常に重要です。 2. 新しい知識の導入: 言語フィードバックに、大規模なモデルが正確に認識できたとしても、大規模なモデルに欠けている知識が含まれる場合、エラー問題は特定されましたが、明確な修正の方向性はありませんでした。したがって、大型モデルに不足している知識を位置合わせしながら補うことは非常に重要です。 3. マルチモーダル調整: 言語モデルの成功により、言語などのマルチモーダル大規模モデルの研究が促進されました。 、スピーチ、画像とビデオの組み合わせ。これらのマルチモーダルなシナリオでは、言語フィードバックと対応するモダリティのフィードバックを研究することで、新しい定義と課題が生まれました。 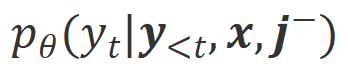 ## #そして#########。
## #そして#########。 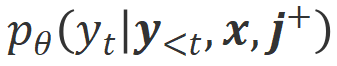 条件での生成確率が
条件での生成確率が 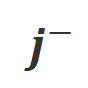 条件よりも大幅に高い単語は、不適切な単語としてマークされます。具体的には、研究者は次の基準を使用して不適切な単語の定義を定量化しました:
条件よりも大幅に高い単語は、不適切な単語としてマークされます。具体的には、研究者は次の基準を使用して不適切な単語の定義を定量化しました: 
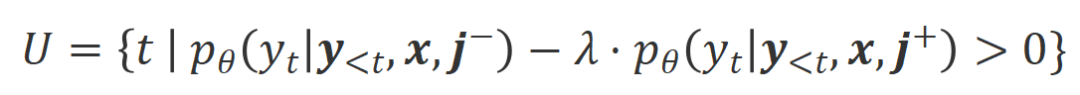
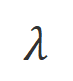 研究者らは、これらの特定された不適切な単語に対して尤度トレーニング (UT) を使用し、それによって大規模モデルがより満足のいく応答を探索するように強制しました。他の応答語については、研究者は依然として最尤推定 (MLE) を使用して最適化しています。
研究者らは、これらの特定された不適切な単語に対して尤度トレーニング (UT) を使用し、それによって大規模モデルがより満足のいく応答を探索するように強制しました。他の応答語については、研究者は依然として最尤推定 (MLE) を使用して最適化しています。 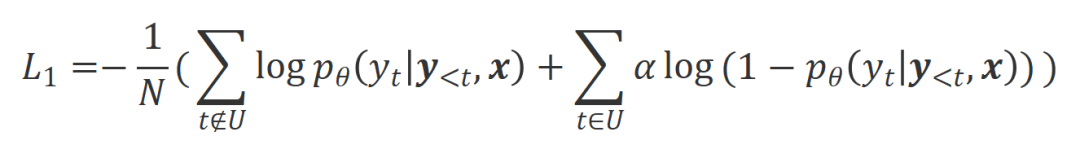 は、非尤度トレーニングの割合を制御するハイパーパラメータ。
は、非尤度トレーニングの割合を制御するハイパーパラメータ。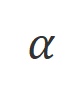 b)
b)  Align-P と Align-N: 2 つの違いは主に、
Align-P と Align-N: 2 つの違いは主に、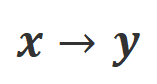 #where
#where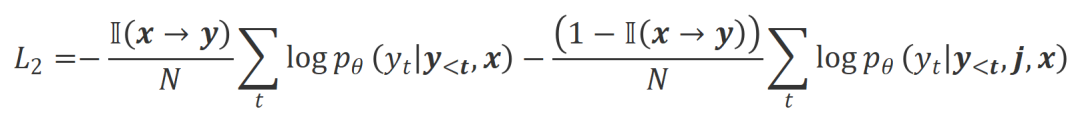 は、データが
は、データが 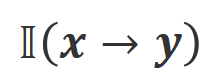 CUT の最終トレーニング目標は、上記の 2 つの比較セットを組み合わせたものです:
CUT の最終トレーニング目標は、上記の 2 つの比較セットを組み合わせたものです: 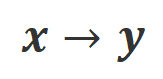 。
。 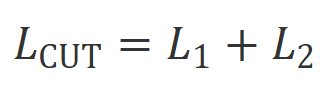
1. オフライン調整
 。
。 


#上図に示すように、4 ラウンドのオンライン アライメント反復の後、CUT は次のようになります。 4000 個のトレーニング データと 13B の小さなモデル サイズの条件下では、それでも 91.36 という素晴らしいスコアを達成できます。この成果は、CUT の優れたパフォーマンスと大きな可能性をさらに証明しています。 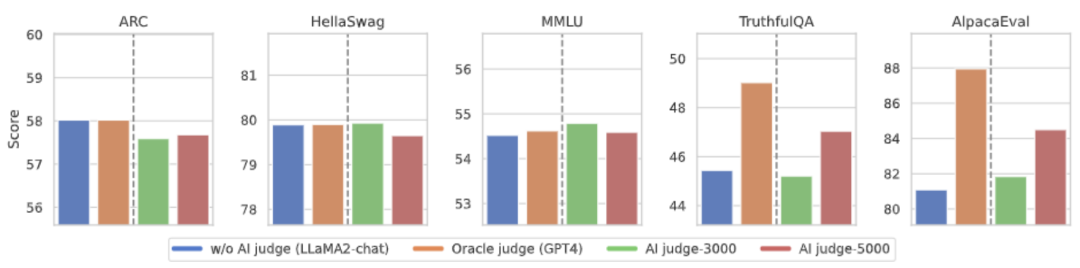 言語フィードバックを考慮したアノテーションコストを削減するために、研究者たちは、対象となる大規模モデルの言語フィードバックに自動的に注釈を付けるための判断モデルをトレーニングしようとしています。上図に示すように、研究者らは 5,000 個(AI Judge-5000)と 3,000 個(AI Judge-3000)の言語フィードバック データを使用して 2 つのレビュー モデルをトレーニングしました。どちらのレビューモデルも、対象となる大規模モデルの最適化、特にAI Judge-5000の効果において顕著な成果をあげています。
言語フィードバックを考慮したアノテーションコストを削減するために、研究者たちは、対象となる大規模モデルの言語フィードバックに自動的に注釈を付けるための判断モデルをトレーニングしようとしています。上図に示すように、研究者らは 5,000 個(AI Judge-5000)と 3,000 個(AI Judge-3000)の言語フィードバック データを使用して 2 つのレビュー モデルをトレーニングしました。どちらのレビューモデルも、対象となる大規模モデルの最適化、特にAI Judge-5000の効果において顕著な成果をあげています。 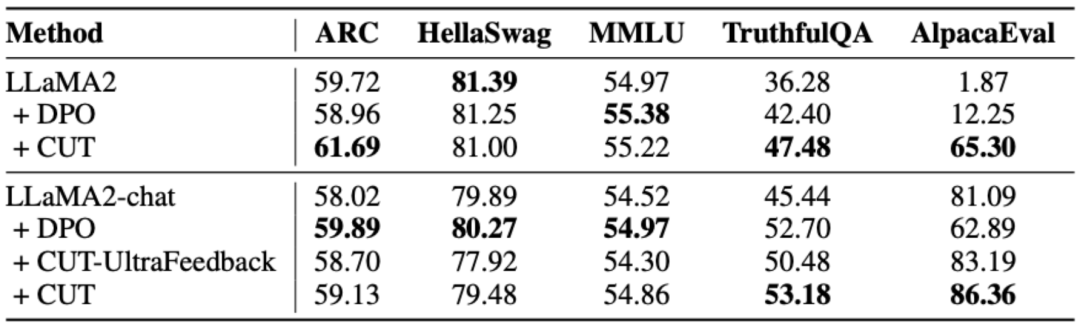
要約と課題
以上が人間と同じように批判から学び成長しましょう。1317 件のコメントで LLaMA2 の勝率は 30 倍になりましたの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。