



前に書いた&著者の個人的な理解
次世代の自動運転技術は、インテリジェントな認識、予測、計画と低レベルの間の特殊な統合と統合に依存すると予想されますコントロール、インタラクション。自動運転アルゴリズムの性能上限には常に大きなボトルネックが存在しており、ボトルネックを克服する鍵はデータ中心の自動運転技術にあるということで学者も産業界も一致しています。 AD シミュレーション、閉ループ モデル トレーニング、AD ビッグ データ エンジンは最近、貴重な経験を積みました。しかし、AD アルゴリズムの自己進化とより優れた AD ビッグデータの蓄積を実現するために、効率的なデータ中心の AD テクノロジーを構築する方法についての体系的な知識と深い理解が不足しています。この研究ギャップを埋めるために、ここでは、主にマイルストーン、主要な機能、データ収集設定などを含む自動運転データセットの包括的な分類に焦点を当てて、最新のデータ駆動型自動運転技術に細心の注意を払います。さらに、クローズドループフレームワークのプロセス、主要テクノロジー、実証研究を含む、業界最前線からの既存のベンチマーククローズドループ AD ビッグデータパイプラインの体系的なレビューを実施しました。最後に、自動運転のさらなる開発を促進するための学界と産業界の共同の取り組みを引き出すために、将来の開発の方向性、潜在的なアプリケーション、限界、懸念事項について議論します。
要約すると、主な貢献は次のとおりです:
- マイルストーン世代、モジュール式タスク、センサー スイート、主要機能によって分類された自動運転データセットの最初の包括的な分類法を導入しました ;
- 深層学習と生成人工知能モデルに基づいた、最先端の閉ループ データ駆動型自動運転パイプラインと関連する主要テクノロジーの体系的なレビュー。
- 閉ループ ビッグ データ ドライバーを提供します パイプライン が自動運転産業用アプリケーションでどのように機能するかについての実証的研究。
- では、現在の パイプライン とソリューションの長所と短所、およびデータの将来についての研究について説明します。自動運転中心の方向性。
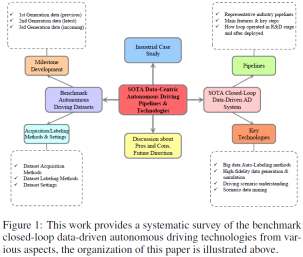
SOTA 自動運転データセット: 分類と開発
自動運転データセットの進化は、この分野の技術の進歩と開発を反映しています。成長する野心。 20 世紀末の先端研究所での初期の AVT 研究とカリフォルニア大学バークレー校の PATH プログラムは、基本的なセンサー データの基礎を築きましたが、当時の技術レベルによって制限されました。過去 20 年間、センサー技術、計算能力、洗練された機械学習アルゴリズムの進歩により、大きな進歩が見られました。 2014 年に自動車技術者協会 (SAE) は、体系的な 6 レベル (L0 ~ L5) の自動運転システムを一般に発表し、自動運転の研究開発の進展により広く認知されました。深層学習によって推進され、コンピューター ビジョン ベースの手法がインテリジェントな認識を支配してきました。深層強化学習とそのバリアントは、インテリジェントな計画と意思決定に重要な改善をもたらします。最近、大規模言語モデル (LLM) と視覚言語モデル (VLM) の強力なシーン理解、運転行動の推論と予測、インテリジェントな意思決定機能が実証され、将来の自動運転開発の新たな可能性が開かれています。
自動運転データ セットのマイルストーン開発
図 2 は、オープンソースの自動運転データ セットのマイルストーン開発を時系列で示しています。大きな進歩により、主流のデータセットは 3 世代に分類され、データセットの複雑さ、量、シーンの多様性、アノテーションの粒度が大幅に向上し、この分野が技術的成熟度の新たなフロンティアに押し上げられています。具体的には、横軸は開発タイムラインを表します。各行のヘッダーには、データセット名、センサー モダリティ、適切なタスク、データ収集場所、および関連する課題が含まれます。世代間でデータセットをさらに比較するために、異なる色の棒グラフを使用して、認識されたデータセットのサイズと予測/計画されたデータセットのサイズを視覚化します。 KITTI と Cityscapes が主導した 2012 年に始まった第 1 世代の初期段階では、知覚タスクに高解像度の画像が提供され、ビジョン アルゴリズムのベンチマーク進歩の基礎となりました。第 2 世代に進むと、NuScenes、Waymo、Argoverse 1 などのデータセットはマルチセンサー方式を導入し、車載カメラ、高精度地図 (HD マップ)、ライダー、レーダー、GPS、IMU、軌跡、およびデータからのデータを統合しました。これは、包括的な運転環境モデリングと意思決定プロセスにとって重要です。最近では、NuPlan、Argoverse 2、Lyft L5 が影響力の基準を大幅に引き上げ、前例のないデータ規模を実現し、最先端の研究に役立つエコシステムを育成しました。巨大なサイズとマルチモーダル センサーの統合を特徴とするこれらのデータセットは、認識、予測、計画タスクのためのアルゴリズムの開発において重要な役割を果たし、高度な End2End またはハイブリッド自動運転モデルへの道を切り開きました。 2024 年には、第 3 世代の自動運転データセットが登場します。 VLM、LLM、その他の第 3 世代の人工知能テクノロジーによってサポートされている第 3 世代のデータセットは、データのロングテール配信の問題、配信範囲外の検出、コーナーケース分析など。

データセットの取得、設定、および主要な機能
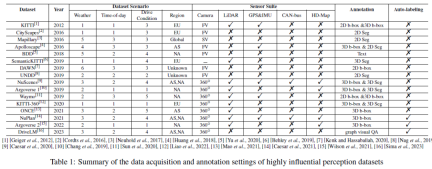
表 1 は、運転シナリオ、センサー スイート、注釈を含む、非常に影響力のある知覚データセットのデータ取得と注釈の設定をまとめたものです。データセット シナリオにおける天気/時間/運転条件カテゴリの合計数。天気には通常、晴れ/曇り/霧/雨/雪/その他 (極端な条件)、時間帯には通常、朝、午後、夜間が含まれます。運転条件は通常、市街路、幹線道路、脇道、田園地帯、高速道路、トンネル、駐車場などが含まれます。シナリオが多様であればあるほど、データセットはより強力になります。また、(アジア)、EU (ヨーロッパ)、NA (北アメリカ)、SA (南アメリカ)、AU (オーストラリア)、AF (アフリカ) として示される、データセットが収集された地域も報告します。 Mapillary は AS/EU/NA/SA/AF/AF を通じて収集され、DAWN は Google および Bing 画像検索エンジンから収集されることは注目に値します。センサー スイートについては、カメラ、LIDAR、GPS、IMU などを検討しました。表1中のFVはフロントビューカメラ、SVはストリートビューカメラの略称である。 360° パノラマ カメラのセットアップは通常、複数のフロント ビュー カメラ、レア ビュー カメラ、サイド ビュー カメラで構成されます。 AD テクノロジーの発展に伴い、データセットに含まれるセンサーの種類と数が増加し、データ パターンがますます多様化していることがわかります。データセットのアノテーションに関しては、初期のデータセットでは通常手動のアノテーション方法が使用されていましたが、最近の NuPlan、Argoverse 2、DriveLM では AD ビッグ データに自動アノテーション テクノロジが採用されています。私たちは、従来の手動アノテーションから自動アノテーションへの移行が、将来のデータ中心の自動運転の大きなトレンドになると考えています。
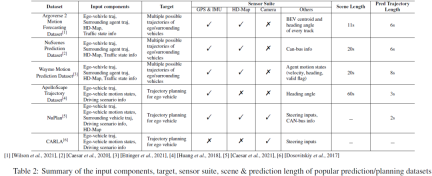
予測タスクと計画タスクについて、主流のデータセットの入出力コンポーネント、センサー スイート、シーン長、予測長を表 2 にまとめます。動きの予測/予測タスクの場合、入力コンポーネントには通常、自車両の履歴軌跡、周囲のエージェントの履歴軌跡、高精度地図、交通状況情報 (信号状況、道路 ID、一時停止標識など) が含まれます。 )。目標出力は、短期間における自車両および/または周囲の対象物の最も可能性の高いいくつかの軌道(上位 5 位または上位 10 位の軌道など)です。モーション予測タスクは通常、スライディング タイム ウィンドウ設定を採用して、シーン全体をいくつかの短い時間ウィンドウに分割します。たとえば、NuScenes は過去 2 秒間の GT データと高精度マップを使用して次の 6 秒の軌道を予測しますが、Argoverse 2 は過去の 5 秒間のグラウンド トゥルースと高精度マップを使用して次の 6 秒の軌道を予測します。秒。 NuPlan、CARLA、ApoloScape は、最も人気のある計画タスク データセットです。入力コンポーネントには、自車/周囲車両の履歴軌跡、自車の運動状態、および運転シーンの表現が含まれます。 NuPlan と ApoloScape は現実世界で取得されたものですが、CARLA はシミュレートされたデータセットです。 CARLA には、さまざまな町での模擬運転中に撮影された道路画像が含まれています。各道路画像はステアリング角度に関連付けられており、車両を適切に動かし続けるために必要な調整を表します。計画の予測の長さは、さまざまなアルゴリズムの要件に応じて変化する可能性があります。
クローズドループデータ駆動型自動運転システム
私たちは今、ソフトウェアによって定義された以前の自動運転の時代から移行しつつあります。とアルゴリズムが新たな時代へ インスピレーションを与えるビッグデータ駆動型とインテリジェントモデルの協調型自動運転時代。閉ループのデータ駆動型システムは、AD アルゴリズムのトレーニングと実際のアプリケーション/展開の間のギャップを埋めることを目的としています。人間の顧客の運転や路上テストから収集されたデータセットに基づいてモデルが受動的にトレーニングされる従来の開ループ アプローチとは異なり、閉ループ システムは実際の環境と動的に対話します。このアプローチは、分布の変動という課題に対処します。つまり、静的なデータセットから学習した動作が、現実世界の運転シナリオの動的な性質に変換されない可能性があります。クローズド ループ システムにより、AV はインタラクションから学習して新しい状況に適応し、アクションとフィードバックの反復サイクルを通じて改善することができます。
ただし、実際のデータ中心の閉ループ AD システムの構築は、いくつかの重要な問題があるため、依然として困難です。 最初の問題は、AD データ収集に関連しています。実際のデータ収集では、ほとんどのデータ サンプルは一般的な/通常の運転シナリオですが、カーブや異常な運転シナリオに関するデータを収集することはほとんど不可能です。第二に、AD データに対する正確かつ効率的な自動アノテーション方法を探索するには、さらなる努力が必要です。第三に、都市環境の特定のシーンにおける AD モデルのパフォーマンスが低いという問題を軽減するために、シーン データ マイニングとシーンの理解を重視する必要があります。
SOTA 閉ループ自動運転パイプライン
自動運転業界は、大量のデータの蓄積によってもたらされる課題に対処するために、統合ビッグデータ プラットフォームを積極的に構築しています。 ADデータ。データドリブンな自動運転時代の新たなインフラと呼ぶにふさわしいものです。一流の AD 企業/研究機関が開発したデータ駆動型の閉ループ システムを調査したところ、次のような共通点が見つかりました。
- これらのパイプラインは通常、(I) データ収集、(II) データ保存、(III) データ選択と前処理、(IV) データ注釈、(V) などのワークフロー サイクルに従います。 ) AD モデルのトレーニング、(VI) シミュレーション/テストの検証、および (VII) 現実世界の展開。
- システム内の閉ループの設計について、既存のソリューションでは、「データ閉ループ」と「モデル閉ループ」を個別に設定するか、「研究開発段階」という異なる段階でサイクルを設定するかを選択します。クローズド ループ」、「展開ステージ クローズド ループ」。
- さらに、業界は、現実世界の AD データセットの長期的な配布問題と、特殊なケースに対処する際の課題も強調しました。 Tesla と Nvidia はこの分野の業界の先駆者であり、彼らのデータ システム アーキテクチャはこの分野の発展に重要な参考資料を提供します。
NVIDIA MagLev AV プラットフォーム 図 3 (左)) は、プログラムとして「収集 → 選択 → ラベル付け → ドラゴンの訓練」を踏襲しており、SDC のアクティブ ラーニングを実現できる複製可能なワークフローであり、スマートループ内の注釈。 MagLev には主に 2 つの閉ループ パイプライン が含まれています。最初のサイクルは自動運転データを中心としており、データの取り込みとインテリジェントな選択から始まり、注釈と注釈、そしてモデルの検索とトレーニングを経ます。トレーニングされたモデルは評価、デバッグされ、最終的に現実世界に展開されます。 2 番目の閉ループは、データ センター バックボーンやハードウェア インフラストラクチャを含むプラットフォームのインフラストラクチャ サポート システムです。このループには、安全なデータ処理、スケーラブルな DNN とシステム KPI、追跡とデバッグ用のダッシュボードが含まれます。 AV 開発の全サイクルをサポートし、開発プロセス中の現実世界のデータとシミュレーション フィードバックの継続的な改善と統合を保証します。
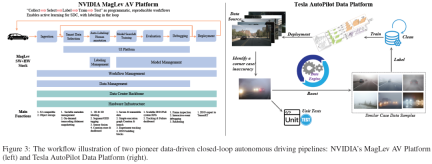
Tesla 自動運転データ プラットフォーム (図 3 (右)) は、もう 1 つの代表的な AD プラットフォームであり、ビッグ データ駆動型の閉ループ パイプライン# の使用に重点を置いています。 ## 自動運転モデルのパフォーマンスを大幅に向上させます。 パイプライン通常はテスラのフリート学習、イベントトリガーの車両側データ収集、およびシャドウ モードからのソース データ収集から開始します。収集されたデータは、データ プラットフォーム アルゴリズムまたは人間の専門家によって保存、管理、およびレビューされます。例外的なケース/不正確さが発見されるたびに、データ エンジンは既存のデータベースからその例外的なケース/不正確さに非常に類似したデータ サンプルを取得して照合します。同時に、シナリオを再現し、システムの応答を厳密にテストするための単体テストが開発されます。取得されたデータ サンプルは、自動注釈アルゴリズムまたは人間の専門家によって注釈が付けられます。その後、十分に注釈が付けられたデータが AD データベースにフィードバックされ、AD データベースが更新されて、AD センシング/予測/計画/制御モデル用の新しいバージョンのトレーニング データセットが生成されます。モデルのトレーニング、検証、シミュレーション、実世界でのテストの後、より高いパフォーマンスを備えた新しい AD モデルがリリースされ、展開されます。
Generative AI に基づく高忠実度の AD データ生成とシミュレーション
現実世界から収集された AD データ サンプルのほとんどは、一般的/通常の運転シナリオであり、その中にはデータベースにはすでに多数の同様のサンプルが存在します。ただし、実際の収集からある種の AD データ サンプルを収集するには、飛躍的に長時間運転する必要がありますが、これは産業用アプリケーションでは現実的ではありません。したがって、高忠実度の自動運転データ生成およびシミュレーション手法は、学術コミュニティから大きな注目を集めています。 CARLA は、ユーザーが指定したさまざまな設定で自動運転データを生成できる自動運転研究用のオープンソース シミュレーターです。 CARLA の強みは柔軟性にあり、ユーザーはさまざまな道路状況、交通シナリオ、気象ダイナミクスを作成できるため、包括的なモデルのトレーニングとテストが容易になります。ただし、シミュレータとしての主な欠点はドメイン ギャップです。 CARLA によって生成された AD データは、現実世界の物理的および視覚的効果を完全にシミュレートすることはできず、実際の運転環境の動的で複雑な特性も表現できません。最近、ワールド モデルは、より高度な固有の概念とより有望なパフォーマンスを備えた高忠実度の AD データ生成に使用されています。世界モデルは、認識する環境の内部表現を構築し、学習した表現を使用して環境内のデータやイベントをシミュレートする人工知能システムとして定義できます。一般世界モデルの目標は、成熟した人間が現実世界で遭遇するのと同じように、状況や相互作用を表現し、シミュレートすることです。自動運転の分野では、GAIA-1 と DriveDreamer は世界モデルに基づいたデータ生成の代表作です。 GAIA-1 は、生の画像/ビデオをテキストとアクション プロンプトとともに入力として取得することで、画像/ビデオから画像/ビデオの生成を実現する生成人工知能モデルです。 GAIA-1 の入力モダリティは、統一されたトークンのシーケンスにエンコードされます。これらの注釈は、後続の画像注釈を予測するために、ワールド モデル内の自己回帰変換器によって処理されます。次に、ビデオ デコーダは、これらの注釈を時間解像度が向上したコヒーレントなビデオ出力に再構築し、動的でコンテキストに富んだビジュアル コンテンツの生成を可能にします。 DriveDreamer は、そのアーキテクチャに拡散モデルを革新的に採用し、現実世界の運転環境の複雑さを捉えることに重点を置いています。その 2 段階のトレーニング パイプライン により、モデルは最初に構造化された交通制約を学習し、次に将来の状態を予測できるようになり、自動運転アプリケーションに合わせた強力な環境理解を確保します。
自動運転データセットの自動ラベル付け方法
成功と信頼性のためには、高品質のデータラベル付けが不可欠です。これまでのところ、データ アノテーション パイプライン は、従来の手動アノテーションから半自動アノテーション、最先端の全自動アノテーション手法まで 3 つのタイプに分類できます。図 4 に示すように、AD データ アノテーションは通常次のようにみなされます。タスク/モデルに特化してください。ワークフローは、アノテーション タスクの要件と元のデータセットを慎重に準備することから始まります。次に、人間の専門家、自動アノテーション アルゴリズム、または End2End の大規模モデルを使用して、初期のアノテーション結果を生成します。その後、アノテーションの品質は、事前定義された要件に基づいて人間の専門家または自動化された品質チェック アルゴリズムによってチェックされます。このラウンドの注釈結果が品質チェックに合格しなかった場合、それらは再び注釈サイクルに戻され、事前定義された要件を満たすまでこの注釈ジョブが繰り返されます。最後に、既製のラベル付き AD データセットを取得できます。

自動アノテーション方法は、閉ループ自動運転ビッグデータ プラットフォームの鍵であり、労働集約的な手動アノテーションを軽減し、閉ループの AD データの効率を向上させます。循環を促進し、関連コストを削減します。従来の自動ラベル付けタスクには、シーンの分類と理解が含まれます。最近では、BEV 手法の普及に伴い、AD データ アノテーションの業界標準も継続的に改善されており、自動アノテーション タスクはより複雑になっています。今日の産業の最先端のシナリオでは、3D 動的ターゲットの自動ラベル付けと 3D 静的シーンの自動ラベル付けが、一般的に使用される 2 つの高度な自動ラベル付けタスクです。
シーンの分類と理解は自動運転ビッグデータ プラットフォームの基礎であり、システムはビデオ フレームを走行場所 (道路、高速道路、都市高架、主要道路など) やシーンなどの事前定義されたシーンに分類します。天気(晴れの日、雨の日、雪の日、霧の日、雷雨の日など)。 CNN ベースの手法は、シーンの分類に一般的に使用されます。これには、事前トレーニングされた微調整された CNN モデル、マルチビューおよびマルチレイヤー CNN モデル、シーン表現を改善するためのさまざまな CNN ベースのモデルが含まれます。シーンの理解は単なる分類を超えています。これには、周囲の車両エージェント、歩行者、信号機など、シーン内の動的要素の解釈が含まれます。画像ベースのシーン理解に加えて、SemanticKITTI などの LIDAR ベースのデータ ソースも、提供されるきめ細かい幾何学的情報により広く採用されています。
3 次元の動的オブジェクトの自動アノテーションと 3 次元の静的シーンの自動アノテーションの出現は、広く採用されている純粋な電気自動車の認識技術の要件を満たすためです。 Waymo は、LIDAR 点群シーケンス データに基づく 3D 自動ラベル付けパイプラインを提案しました。これは、3D 検出器を使用してフレームごとにターゲットの位置を特定します。次に、フレーム全体で識別されたオブジェクトの境界ボックスが、マルチオブジェクト トラッカーを介してリンクされます。オブジェクトの軌跡データ (各フレームでの対応する点群 3D バウンディング ボックス) がオブジェクトごとに抽出され、分割統治アーキテクチャを使用してオブジェクト中心の自動ラベル付けが実行され、最終的に洗練された 3D バウンディング ボックスがラベルとして生成されます。 Uber が提案した Auto4D パイプライン は、AD 知覚マーカーを初めて時空間スケールで調査します。自動運転の分野では、空間スケールでの 3D ターゲット境界ボックス マーキングと、時間スケールでの 1D 対応するタイムスタンプ マーキングは、4D マーキングと呼ばれます。 Auto4D パイプライン は、連続 LIDAR 点群から開始して、オブジェクトの初期軌道を確立します。軌道は、ターゲット観測を使用してターゲット サイズをエンコードおよびデコードするターゲット サイズ ブランチによって洗練されます。同時に、モーション パス ブランチはパスの観測とモーションをエンコードし、パス デコーダが一定のターゲット サイズで軌道を調整できるようにします。
3D 静的シーンの自動ラベリングは、車線、道路境界線、横断歩道、信号機、および運転シーン内のその他の関連要素にラベルを付ける必要がある HDMap 生成と考えることができます。このトピックの下には、MVMap、NeMO などのビジョンベースの手法、VMA などの LIDAR ベースの手法、OccBEV、OccNet/ADPT、ALO などの事前トレーニング済み 3D シーン再構成手法など、いくつかの魅力的な研究成果があります。 VMA は、3D 静的シーンの自動ラベル付けのために最近提案された機能です。 VMA フレームワークは、クラウドソースのマルチトリップ集約 LIDAR 点群を利用して静的シーンを再構築し、処理用のユニットにセグメント化します。 MapTR ベースのユニット アノテーターは、クエリとデコードを通じて生の入力を特徴マップにエンコードし、意味的に型付けされた点シーケンスを生成します。 VMA の出力はベクトル化されたマップであり、閉ループ アノテーションと手動検証を通じて改良され、自動運転に満足のいく高精度マップが提供されます。
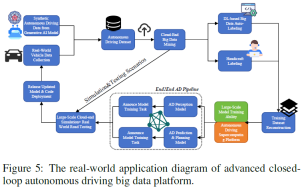
実証研究
この記事で言及されている高度な閉ループ AD データ プラットフォームをより詳しく説明するために、実証研究を提供します。全体のプロセス図を図 5 に示します。この場合、研究者の目標は、自動運転アルゴリズム開発と自動運転アルゴリズム開発の間のスムーズな移行を実現するために、生成 AI とさまざまな深層学習ベースのアルゴリズムに基づいた AD ビッグデータ閉ループ パイプライン を開発することです。フェーズと OTA アップグレード フェーズ (実際の展開後) により、データの閉ループが実現されます。具体的には、生成された人工知能モデルは、(1) エンジニアが提供するテキスト プロンプトに基づいて、特定のシナリオ向けの高忠実度の AD データを生成するために使用されます。 (2) AD ビッグデータの自動ラベル付けにより、グラウンド トゥルース ラベルを効果的に作成します。
図は 2 つの閉ループを示しています。より大きな段階の 1 つは自動運転アルゴリズムの開発フェーズであり、人工知能モデルと現実世界の運転から得られたデータ サンプルを生成するための合成自動運転データのデータ収集から始まります。これら 2 つのデータ ソースは自動運転データ セットに統合され、クラウドでマイニングされて貴重な洞察が得られます。その後、データセットは二重ラベル付けパスに入ります。深層学習に基づく自動ラベル付けまたは手動による手動ラベル付けにより、アノテーションの速度と精度が保証されます。次に、ラベル付けされたデータは、大容量自動運転スーパーコンピューティング プラットフォーム上でモデルをトレーニングするために使用されます。これらのモデルはシミュレーションと実際の道路でテストされ、その有効性が評価され、自動運転モデルのリリースとその後の展開につながります。小さい方は、実際の展開後の OTA アップグレード フェーズ用であり、AD アルゴリズムの不正確さ/コーナー ケースを収集するための大規模なクラウド シミュレーションと現実世界のテストが含まれます。特定された不正確さ/例外的なケースは、モデルのテストと更新の次の反復に通知するために使用されます。たとえば、トンネル運転シナリオでは AD アルゴリズムのパフォーマンスが低いことが判明したとします。識別されたトンネル運転曲線はすぐにリングに通知され、次の反復で更新されます。生成人工知能モデルは、トンネル運転シーンの関連説明をテキスト プロンプトとして使用して、大規模なトンネル運転データ サンプルを生成します。生成されたデータと生のデータセットは、シミュレーション、テスト、モデルの更新にフィードされます。これらのプロセスの反復的な性質は、モデルを最適化して困難な環境や新しいデータに適応し、自動運転機能の高い精度と信頼性を維持するために重要です。
第 3 世代以降の新しい自動運転データセットについて議論します。 LLM/VLM などの基本モデルは、言語理解やコンピュータ ビジョンにおいて成功を収めていますが、それらを自動運転に直接適用することは依然として困難です。これには 2 つの理由があります。1 つは、これらの LLM/VLM には、マルチソースの AD ビッグ データ (FOV 画像/ビデオ、LIDAR クラウド ポイント、高解像度マップ、 GPS/IMU データなど)は、日常生活で目にする画像を理解するのがさらに困難です。一方で、自動運転分野における既存データの規模や品質は他の分野(金融や医療など)に比べて及ばず、大容量のLLM/VLMの学習や最適化を支援することが困難です。自動運転用のビッグデータは、現在、規制、プライバシーへの懸念、コストのため、規模と品質が制限されています。私たちは、関係者全員の協力により、次世代の AD ビッグデータの規模と品質が大幅に向上すると信じています。
自動運転アルゴリズムのハードウェア サポート。現在のハードウェア プラットフォームは、特に GPU や TPU などの専用プロセッサの出現により大幅な進歩を遂げ、深層学習タスクに不可欠な大規模な並列コンピューティング能力を提供します。車載およびクラウド インフラストラクチャの高性能コンピューティング リソースは、車両センサーによって生成される大量のデータ ストリームをリアルタイムで処理するために不可欠です。これらの進歩にもかかわらず、自動運転アルゴリズムの複雑さの増大に対処する場合、スケーラビリティ、エネルギー効率、および処理速度には依然として限界があります。 VLM/LLM 誘導によるユーザーと車両のインタラクションは、非常に有望なアプリケーション ケースです。このアプリケーションに基づいて、ユーザー固有の行動ビッグデータを収集できます。ただし、VLM/LLM 車載デバイスには高水準のハードウェア コンピューティング リソースが必要であり、対話型アプリケーションの遅延は低いことが期待されます。したがって、将来的には軽量で大規模な自動運転モデルが登場するか、LLM/VLM の圧縮技術がさらに研究される可能性があります。
ユーザー行動データに基づいたパーソナライズされた自動運転の推奨事項。スマート カーは、単純な交通手段からスマート ターミナル シナリオにおける最新のアプリケーション拡張まで発展してきました。したがって、高度な自動運転機能を搭載した車両には、運転スタイルやルートの好みなどのドライバーの行動の好みを過去の運転データ記録から学習できることが期待されています。これにより、将来的にはスマートカーがユーザーのお気に入りの車両とより連携し、ドライバーの車両制御、運転決定、ルート計画を支援できるようになります。上記の概念をパーソナライズされた自動運転推奨アルゴリズムと呼びます。レコメンデーション システムは、電子商取引、オンライン ショッピング、食品配達、ソーシャル メディア、ライブ ストリーミング プラットフォームで広く使用されています。ただし、自動運転の分野では、パーソナライズされた推奨事項はまだ初期段階にあります。近い将来、より適切なデータシステムとデータ収集メカニズムが設計され、ユーザーの許可と関連規制の遵守のもとでユーザーの運転行動の好みに関するビッグデータが収集され、それによってユーザー向けにカスタマイズされた自動運転システムの推奨が実現されると私たちは考えています。 。
データセキュリティと信頼できる自動運転。大量の自動運転ビッグデータは、データセキュリティとユーザーのプライバシー保護に大きな課題をもたらしています。コネクテッド自動運転車 (CAV) や車両のインターネット (IoV) テクノロジーの発展に伴い、車両のコネクテッド化が進み、運転習慣から頻繁に使用するルートに至るまで詳細なユーザー データが収集されるため、個人情報の悪用の可能性についての懸念が生じています。収集されるデータの種類、保持ポリシー、サードパーティの共有に関する透明性の必要性を推奨します。 「追跡しない」要求の尊重や個人データを削除するオプションの提供など、ユーザーの同意と制御の重要性を強調しています。自動運転業界にとって、イノベーションを促進しながらこのデータを保護するには、これらのガイドラインを厳守し、ユーザーの信頼と進化するプライバシー法への準拠を確保する必要があります。
データのセキュリティとプライバシーに加えて、信頼できる自動運転をどのように実現するかという問題もあります。 AD テクノロジーの驚異的な発展により、インテリジェント アルゴリズムと生成人工知能モデル (LLM、VLM など) は、ますます複雑になる運転上の意思決定やタスクを実行する際に「駆動要素として機能」するようになります。この分野では、人間は自動運転モデルを信頼できるのか?という当然の疑問が生じます。私たちの見解では、信頼性の鍵は自動運転モデルの解釈可能性にあると考えています。ドライバーは、単に運転操作を実行するだけでなく、人間のドライバーに決定の理由を説明できる必要があります。 LLM/VLM は、高度な推論とリアルタイムでのわかりやすい説明を提供することで、信頼性の高い自動運転を強化することが期待されています。
結論
この調査は、ビッグ データ システム、データ マイニング、クローズド ループ テクノロジーなど、自動運転におけるデータ中心の進化に関する初めての体系的なレビューを提供します。この調査では、まずマイルストーン生成ごとにデータセットの分類を作成し、歴史的なタイムライン全体で AD データセットの開発をレビューし、データセットの取得、セットアップ、および主要な機能を紹介します。さらに、閉ループデータ駆動型自動運転システムについて、学術と産業の両方の観点から詳しく解説します。データ中心の閉ループ システムにおけるワークフローパイプライン、プロセス、および主要なテクノロジについて詳しく説明します。実証研究を通じて、アルゴリズム開発および OTA アップグレードにおけるデータ中心のクローズドループ AD プラットフォームの利用率と利点が実証されています。最後に、既存のデータ駆動型自動運転技術の長所と短所、および今後の研究の方向性について包括的に議論します。新しいデータ セット、ハードウェア サポート、パーソナライズされた AD の推奨事項、および第 3 世代以降の説明可能な自動運転に重点が置かれています。また、生成 AI モデルの信頼性、データのセキュリティ、自動運転の将来の開発についての懸念も表明しました。

元のリンク: https://mp.weixin.qq.com/s/YEjWSvKk6f-TDAR91Ow2rA
以上がデータは王様です!データを基に効率的な自動運転アルゴリズムを段階的に構築するにはどうすればよいでしょうか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 AIのスキルギャップは、サプライチェーンのダウンを遅くしていますApr 26, 2025 am 11:13 AM
AIのスキルギャップは、サプライチェーンのダウンを遅くしていますApr 26, 2025 am 11:13 AM「AI-Ready労働力」という用語は頻繁に使用されますが、サプライチェーン業界ではどういう意味ですか? サプライチェーン管理協会(ASCM)のCEOであるAbe Eshkenaziによると、批評家ができる専門家を意味します
 1つの会社がAIを永遠に変えるために静かに取り組んでいる方法Apr 26, 2025 am 11:12 AM
1つの会社がAIを永遠に変えるために静かに取り組んでいる方法Apr 26, 2025 am 11:12 AM分散型AI革命は静かに勢いを増しています。 今週の金曜日、テキサス州オースティンでは、ビテンサーのエンドゲームサミットは極めて重要な瞬間を示し、理論から実用的な応用に分散したAI(DEAI)を移行します。 派手なコマーシャルとは異なり
 Nvidiaは、AIエージェント開発を合理化するためにNEMOマイクロサービスをリリースしますApr 26, 2025 am 11:11 AM
Nvidiaは、AIエージェント開発を合理化するためにNEMOマイクロサービスをリリースしますApr 26, 2025 am 11:11 AMエンタープライズAIはデータ統合の課題に直面しています エンタープライズAIの適用は、ビジネスデータを継続的に学習することで正確性と実用性を維持できるシステムを構築する大きな課題に直面しています。 NEMOマイクロサービスは、NVIDIAが「データフライホイール」と呼んでいるものを作成することにより、この問題を解決し、AIシステムがエンタープライズ情報とユーザーインタラクションへの継続的な露出を通じて関連性を維持できるようにします。 この新しく発売されたツールキットには、5つの重要なマイクロサービスが含まれています。 NEMOカスタマイザーは、より高いトレーニングスループットを備えた大規模な言語モデルの微調整を処理します。 NEMO評価者は、カスタムベンチマークのAIモデルの簡素化された評価を提供します。 Nemo Guardrailsは、コンプライアンスと適切性を維持するためにセキュリティ管理を実装しています
 aiは芸術とデザインの未来のために新しい絵を描きますApr 26, 2025 am 11:10 AM
aiは芸術とデザインの未来のために新しい絵を描きますApr 26, 2025 am 11:10 AMAI:芸術とデザインの未来 人工知能(AI)は、前例のない方法で芸術とデザインの分野を変えており、その影響はもはやアマチュアに限定されませんが、より深く影響を与えています。 AIによって生成されたアートワークとデザインスキームは、広告、ソーシャルメディアの画像生成、Webデザインなど、多くのトランザクションデザインアクティビティで従来の素材画像とデザイナーに迅速に置き換えられています。 ただし、プロのアーティストやデザイナーもAIの実用的な価値を見つけています。 AIを補助ツールとして使用して、新しい美的可能性を探求し、さまざまなスタイルをブレンドし、新しい視覚効果を作成します。 AIは、アーティストやデザイナーが繰り返しタスクを自動化し、さまざまなデザイン要素を提案し、創造的な入力を提供するのを支援します。 AIはスタイル転送をサポートします。これは、画像のスタイルを適用することです
 エージェントAIとのズームがどのように革命を起こしているか:会議からマイルストーンまでApr 26, 2025 am 11:09 AM
エージェントAIとのズームがどのように革命を起こしているか:会議からマイルストーンまでApr 26, 2025 am 11:09 AM最初はビデオ会議プラットフォームで知られていたZoomは、エージェントAIの革新的な使用で職場革命をリードしています。 ZoomのCTOであるXD Huangとの最近の会話は、同社の野心的なビジョンを明らかにしました。 エージェントAIの定義 huang d
 大学に対する実存的な脅威Apr 26, 2025 am 11:08 AM
大学に対する実存的な脅威Apr 26, 2025 am 11:08 AMAIは教育に革命をもたらしますか? この質問は、教育者と利害関係者の間で深刻な反省を促しています。 AIの教育への統合は、機会と課題の両方をもたらします。 Tech Edvocate NotesのMatthew Lynch、Universitとして
 プロトタイプ:アメリカの科学者は海外の仕事を探していますApr 26, 2025 am 11:07 AM
プロトタイプ:アメリカの科学者は海外の仕事を探していますApr 26, 2025 am 11:07 AM米国における科学的研究と技術の開発は、おそらく予算削減のために課題に直面する可能性があります。 Natureによると、海外の雇用を申請するアメリカの科学者の数は、2024年の同じ期間と比較して、2025年1月から3月まで32%増加しました。以前の世論調査では、調査した研究者の75%がヨーロッパとカナダでの仕事の検索を検討していることが示されました。 NIHとNSFの助成金は過去数か月で終了し、NIHの新しい助成金は今年約23億ドル減少し、3分の1近く減少しました。リークされた予算の提案は、トランプ政権が科学機関の予算を急激に削減していることを検討しており、最大50%の削減の可能性があることを示しています。 基礎研究の分野での混乱は、米国の主要な利点の1つである海外の才能を引き付けることにも影響を与えています。 35
 オープンAIの最新のGPT 4.1ファミリ - 分析VidhyaApr 26, 2025 am 10:19 AM
オープンAIの最新のGPT 4.1ファミリ - 分析VidhyaApr 26, 2025 am 10:19 AMOpenaiは、強力なGPT-4.1シリーズを発表しました。実際のアプリケーション向けに設計された3つの高度な言語モデルのファミリー。 この大幅な飛躍は、より速い応答時間、理解の強化、およびTと比較した大幅に削減されたコストを提供します


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

VSCode Windows 64 ビットのダウンロード
Microsoft によって発売された無料で強力な IDE エディター

DVWA
Damn Vulnerable Web App (DVWA) は、非常に脆弱な PHP/MySQL Web アプリケーションです。その主な目的は、セキュリティ専門家が法的環境でスキルとツールをテストするのに役立ち、Web 開発者が Web アプリケーションを保護するプロセスをより深く理解できるようにし、教師/生徒が教室環境で Web アプリケーションを教え/学習できるようにすることです。安全。 DVWA の目標は、シンプルでわかりやすいインターフェイスを通じて、さまざまな難易度で最も一般的な Web 脆弱性のいくつかを実践することです。このソフトウェアは、

AtomエディタMac版ダウンロード
最も人気のあるオープンソースエディター

メモ帳++7.3.1
使いやすく無料のコードエディター

mPDF
mPDF は、UTF-8 でエンコードされた HTML から PDF ファイルを生成できる PHP ライブラリです。オリジナルの作者である Ian Back は、Web サイトから「オンザフライ」で PDF ファイルを出力し、さまざまな言語を処理するために mPDF を作成しました。 HTML2FPDF などのオリジナルのスクリプトよりも遅く、Unicode フォントを使用すると生成されるファイルが大きくなりますが、CSS スタイルなどをサポートし、多くの機能強化が施されています。 RTL (アラビア語とヘブライ語) や CJK (中国語、日本語、韓国語) を含むほぼすべての言語をサポートします。ネストされたブロックレベル要素 (P、DIV など) をサポートします。
ホットトピック
 7743
7743 15164314139752129125123429
15164314139752129125123429