


手動による注釈は必要ありません。 LLM はテキスト埋め込み学習をサポートします: 100 の言語を簡単にサポートし、数十万のダウンストリーム タスクに適応します

テキスト埋め込み (単語埋め込み) は、自然言語処理 (NLP) 分野の基本テクノロジーであり、テキストを意味空間にマッピングし、高密度ベクトル表現に変換できます。この手法は、情報検索 (IR)、質問応答、テキスト類似性計算、推奨システムなど、さまざまな NLP タスクで広く使用されています。テキストの埋め込みにより、テキストの意味と関係をより深く理解できるようになり、NLP タスクの効率が向上します。
情報検索 (IR) の分野では、通常、検索の最初の段階で類似性の計算にテキスト埋め込みが使用されます。これは、大規模なコーパス内の候補ドキュメントの少数のセットを呼び出して、詳細な計算を実行することによって機能します。埋め込みベースの検索も、検索拡張生成 (RAG) の重要なコンポーネントです。これにより、大規模言語モデル (LLM) がモデル パラメーターを変更せずに動的な外部知識にアクセスできるようになります。このようにして、IR システムはテキストの埋め込みと外部の知識をより適切に利用して、検索結果を向上させることができます。
word2vec や GloVe などの初期のテキスト埋め込み学習方法は広く使用されていますが、その静的な特性により、自然言語で豊富なコンテキスト情報を取得する能力は制限されています。しかし、事前トレーニング済み言語モデルの台頭により、Sentence-BERT や SimCSE などのいくつかの新しい手法は、テキストの埋め込みを学習するために BERT を微調整することにより、自然言語推論 (NLI) データセットで大きな進歩を達成しました。これらの方法は、BERT のコンテキスト認識機能を活用してテキストのセマンティクスとコンテキストをより深く理解し、それによってテキスト埋め込みの品質と表現力を向上させます。これらのメソッドは、事前トレーニングと微調整を組み合わせることにより、大規模なコーパスからより豊富な意味情報を学習し、自然言語処理を提供することができます
##テキストの埋め込みを改善するためパフォーマンスと堅牢性、E5 や BGE などの高度な手法では、多段階トレーニングが採用されています。これらはまず、数十億の弱く監視されたテキストのペアで事前トレーニングされ、次にいくつかの注釈付きデータセットで微調整されます。この戦略により、テキスト埋め込みのパフォーマンスを効果的に向上させることができます。
既存のマルチステージ手法にはまだ 2 つの欠陥があります:
1. 複雑なマルチステージ トレーニング パイプラインの構築には多大なエンジニアリングが必要です多数の相関ペアを管理する作業。
2. 微調整は手動で収集されたデータセットに依存しますが、多くの場合、タスクの多様性と言語範囲によって制限されます。
ほとんどのメソッドは BERT スタイルのエンコーダーを使用し、より優れた LLM および関連テクニックのトレーニングの進行状況を無視します。
マイクロソフトの研究チームは最近、以前の方法の欠点のいくつかを克服するための、シンプルで効率的なテキスト埋め込みトレーニング方法を提案しました。このアプローチでは、複雑なパイプライン設計や手動で構築したデータセットは必要ありませんが、LLM を利用して多様なテキスト データを合成します。このアプローチにより、トレーニング プロセス全体の所要ステップは 1,000 未満でありながら、約 100 の言語で数十万のテキスト埋め込みタスクに対して高品質のテキスト埋め込みを生成することができました。

具体的には、研究者らは 2 段階のプロンプト戦略を使用しました。最初に LLM に候補タスクのプールをブレインストーミングするよう促し、次に LLM にそのプールから特定のタスクのデータを生成するよう促しました。
さまざまなアプリケーション シナリオをカバーするために、研究者はタスクの種類ごとに複数のプロンプト テンプレートを設計し、さまざまなテンプレートによって生成されたデータを組み合わせて多様性を高めました。
実験結果は、「合成データのみ」を微調整すると、Mistral-7B が BEIR および MTEB ベンチマークで非常に競争力のあるパフォーマンスを達成することを証明しています。合成および Sota のパフォーマンスが達成できるのは、注釈付きデータは微調整されます。
大規模なモデルを使用してテキストの埋め込みを改善する
1. 合成データの生成最先端の技術を利用するGPT-4 言語モデル (LLM) などの大規模モデルは、データを合成することでますます注目を集めています。これにより、モデルのマルチタスクおよび複数言語機能の多様性が強化され、より堅牢なテキスト埋め込みをトレーニングできます。さまざまな下流タスク (セマンティック検索、テキスト類似性計算、クラスタリングなど) で使用でき、良好なパフォーマンスを発揮します。
多様な合成データを生成するために、研究者らは、最初に埋め込みタスクを分類し、次にタスクの種類ごとに異なるプロンプト テンプレートを使用する単純な分類法を提案しました。
#非対称タスク
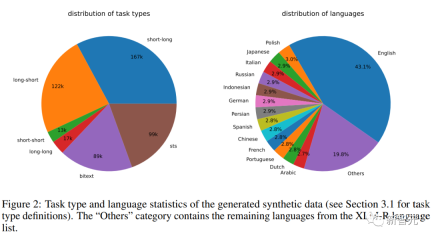
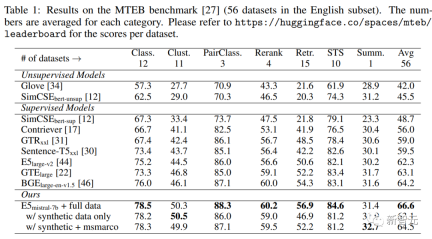
クエリとドキュメントが意味的に関連しているが、相互に言い換えていないタスクが含まれます。 研究者らは、クエリとドキュメントの長さに基づいて、非対称タスクをさらに 4 つのサブカテゴリに分割しました: 短長マッチング (短いクエリと長いドキュメント、商用検索の典型的なシナリオ)エンジン )、ロング-ショート マッチング、ショート-ショート マッチング、ロング-ロング マッチング。 研究者らは、サブカテゴリごとに、最初に LLM にタスク リストのブレインストーミングを促し、次にタスク定義の条件の具体例を生成する 2 段階のプロンプト テンプレートを設計しました。GPT より-4 の出力はほぼ一貫性があり、高品質です。 #研究者らは予備実験で、単一のプロンプトを使用してタスク定義とクエリ文書のペアを生成することも試みましたが、データの多様性はそれほど高くありませんでした。上記2ステップで良い方法です。 対称タスク には、主に、同様のセマンティクスを持つが表面形式が異なるクエリとドキュメントが含まれます。 この記事では、単言語セマンティック テキスト類似性 (STS) とバイテキスト検索という 2 つのアプリケーション シナリオを検討し、シナリオごとに 2 つの異なるプロンプト テンプレートを設計し、特定の目的に合わせてカスタマイズします。タスクの定義は比較的単純であるため、ブレインストーミングのステップは省略できます。 プロンプトワードの多様性をさらに高め、合成データの多様性を向上させるために、研究者らは各プロンプトボードにいくつかのプレースホルダーを追加し、実行時にそれらをランダムにサンプリングしました。たとえば、" {query_length}" は、セット「{5 ワード未満、5 ~ 10 ワード、少なくとも 10 ワード}」からのサンプリングを表します。 多言語データを生成するために、研究者は XLM-R の言語リストから「{言語}」の値をサンプリングし、高リソース言語、つまり、期待されたものを満たしていません JSON 形式を定義する生成されたデータは解析中に破棄され、重複したデータも文字列の正確な一致に基づいて削除されます。 関連するクエリとドキュメントのペアが与えられた場合、最初に元のクエリ q を使用して新しい命令 q_inst を生成します。 {task_diction}" は、タスクの 1 文の説明を埋め込むプレースホルダーです。 #生成された合成データの場合は、ブレインストーミング ステップの出力が使用されます。MS-MARCO などの他のデータセットの場合は、研究者が手動でタスク定義を作成しますファイル側のディレクティブ プレフィックスを変更せずに、それをデータセット内のすべてのクエリに適用します。 この方法では、ドキュメント インデックスを事前に構築し、クエリ側のみを変更することで実行するタスクをカスタマイズできます。 事前トレーニングされた LLM が与えられた場合、クエリとドキュメントの末尾に [EOS] トークンを追加し、最後の層の [EOS] ベクトルを取得してそれを LLM にフィードします。クエリとドキュメントの埋め込みを取得します。 次に、標準の InfoNCE 損失を使用して、バッチ内のネガとハード ネガの損失を計算します。 ここで、ℕ はすべての否定値のセットを表し、 研究者らは、Azure OpenAI サービスを使用して、150,000 の一意の命令を含む 500,000 のサンプルを生成しました。そのうち 25% は GPT-3.5-Turbo によって生成され、残りは GPT-4 によって生成され、合計で1億8000万トークン。 主要言語は英語で、合計 93 の言語をカバーしています。75 の低リソース言語については、言語ごとに平均約 1,000 のサンプルがあります。 研究者らは、データ品質の観点から、GPT-3.5-Turbo の出力の一部がプロンプト テンプレートに記載されているガイドラインに厳密に従っていないことを発見しました。 、全体的な品質は依然として許容可能でした。受け入れられ、予備実験では、このデータのサブセットを使用する利点も実証されました。 モデルの微調整と評価 研究者らは、上記の損失を利用して、事前トレーニングされたモデルを微調整しました。 1エポックはMistral-7B、RankLLaMAの育成方法に従い、ランク16でLoRAを使用。 GPU メモリ要件をさらに削減するために、勾配チェックポイント、混合精度トレーニング、DeepSpeed ZeRO-3 などのテクノロジーが使用されます。 トレーニング データに関しては、生成された合成データと 13 の公開データセットの両方が使用され、サンプリング後に約 180 万のサンプルが得られました。 以前の研究との公正な比較のために、研究者らは、唯一のアノテーション監視が MS-MARCO 章ランキング データセットである場合の結果と、MTEB ベンチマークの結果も報告しています。評価されました。 以下の表にあるように、記事で取得したモデル「E5mistral-7B フルデータ」が取得されました。 MTEB ベンチマーク テストでは、従来の最先端モデルよりも 2.4 ポイント高い、最高の平均スコアを達成しました。 「合成データのみあり」設定では、トレーニングに注釈付きデータは使用されませんが、パフォーマンスは依然として非常に競争力があります。 研究者らは、いくつかの市販のテキスト埋め込みモデルも比較しましたが、これらのモデルに関する透明性と文書化の欠如により、公正な比較ができませんでした。 しかし、BEIR ベンチマークでの検索パフォーマンスの比較結果から、トレーニング済みモデルが現在の商用モデルよりも大幅に優れていることがわかります。 多言語検索 多言語の検索を評価するには、研究者らは、人間が注釈を付けたクエリと 18 言語の関連性判断を含む MIRACL データセットの評価を実施しました。 結果は、このモデルが高リソース言語、特に英語で mE5-large を上回っていることを示していますが、低リソース言語ではモデルのパフォーマンスが mE5-large より優れています。 mE5-baseと比較すると、まだ理想的ではありません。 研究者らは、これはミストラル-7Bが主に英語のデータに基づいて事前トレーニングされており、予測多言語モデルがこのギャップを埋めるために使用できる方法であると考えています。 
2. トレーニング

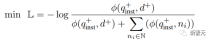
 はクエリとクエリの間の一致スコアを計算するために使用されます。ドキュメントでは、t は温度ハイパーパラメータであり、実験では 0.02 に固定されています
はクエリとクエリの間の一致スコアを計算するために使用されます。ドキュメントでは、t は温度ハイパーパラメータであり、実験では 0.02 に固定されています
合成データ統計
主な結果
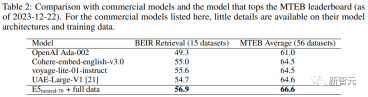
以上が手動による注釈は必要ありません。 LLM はテキスト埋め込み学習をサポートします: 100 の言語を簡単にサポートし、数十万のダウンストリーム タスクに適応しますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 AIのスキルギャップは、サプライチェーンのダウンを遅くしていますApr 26, 2025 am 11:13 AM
AIのスキルギャップは、サプライチェーンのダウンを遅くしていますApr 26, 2025 am 11:13 AM「AI-Ready労働力」という用語は頻繁に使用されますが、サプライチェーン業界ではどういう意味ですか? サプライチェーン管理協会(ASCM)のCEOであるAbe Eshkenaziによると、批評家ができる専門家を意味します
 1つの会社がAIを永遠に変えるために静かに取り組んでいる方法Apr 26, 2025 am 11:12 AM
1つの会社がAIを永遠に変えるために静かに取り組んでいる方法Apr 26, 2025 am 11:12 AM分散型AI革命は静かに勢いを増しています。 今週の金曜日、テキサス州オースティンでは、ビテンサーのエンドゲームサミットは極めて重要な瞬間を示し、理論から実用的な応用に分散したAI(DEAI)を移行します。 派手なコマーシャルとは異なり
 Nvidiaは、AIエージェント開発を合理化するためにNEMOマイクロサービスをリリースしますApr 26, 2025 am 11:11 AM
Nvidiaは、AIエージェント開発を合理化するためにNEMOマイクロサービスをリリースしますApr 26, 2025 am 11:11 AMエンタープライズAIはデータ統合の課題に直面しています エンタープライズAIの適用は、ビジネスデータを継続的に学習することで正確性と実用性を維持できるシステムを構築する大きな課題に直面しています。 NEMOマイクロサービスは、NVIDIAが「データフライホイール」と呼んでいるものを作成することにより、この問題を解決し、AIシステムがエンタープライズ情報とユーザーインタラクションへの継続的な露出を通じて関連性を維持できるようにします。 この新しく発売されたツールキットには、5つの重要なマイクロサービスが含まれています。 NEMOカスタマイザーは、より高いトレーニングスループットを備えた大規模な言語モデルの微調整を処理します。 NEMO評価者は、カスタムベンチマークのAIモデルの簡素化された評価を提供します。 Nemo Guardrailsは、コンプライアンスと適切性を維持するためにセキュリティ管理を実装しています
 aiは芸術とデザインの未来のために新しい絵を描きますApr 26, 2025 am 11:10 AM
aiは芸術とデザインの未来のために新しい絵を描きますApr 26, 2025 am 11:10 AMAI:芸術とデザインの未来 人工知能(AI)は、前例のない方法で芸術とデザインの分野を変えており、その影響はもはやアマチュアに限定されませんが、より深く影響を与えています。 AIによって生成されたアートワークとデザインスキームは、広告、ソーシャルメディアの画像生成、Webデザインなど、多くのトランザクションデザインアクティビティで従来の素材画像とデザイナーに迅速に置き換えられています。 ただし、プロのアーティストやデザイナーもAIの実用的な価値を見つけています。 AIを補助ツールとして使用して、新しい美的可能性を探求し、さまざまなスタイルをブレンドし、新しい視覚効果を作成します。 AIは、アーティストやデザイナーが繰り返しタスクを自動化し、さまざまなデザイン要素を提案し、創造的な入力を提供するのを支援します。 AIはスタイル転送をサポートします。これは、画像のスタイルを適用することです
 エージェントAIとのズームがどのように革命を起こしているか:会議からマイルストーンまでApr 26, 2025 am 11:09 AM
エージェントAIとのズームがどのように革命を起こしているか:会議からマイルストーンまでApr 26, 2025 am 11:09 AM最初はビデオ会議プラットフォームで知られていたZoomは、エージェントAIの革新的な使用で職場革命をリードしています。 ZoomのCTOであるXD Huangとの最近の会話は、同社の野心的なビジョンを明らかにしました。 エージェントAIの定義 huang d
 大学に対する実存的な脅威Apr 26, 2025 am 11:08 AM
大学に対する実存的な脅威Apr 26, 2025 am 11:08 AMAIは教育に革命をもたらしますか? この質問は、教育者と利害関係者の間で深刻な反省を促しています。 AIの教育への統合は、機会と課題の両方をもたらします。 Tech Edvocate NotesのMatthew Lynch、Universitとして
 プロトタイプ:アメリカの科学者は海外の仕事を探していますApr 26, 2025 am 11:07 AM
プロトタイプ:アメリカの科学者は海外の仕事を探していますApr 26, 2025 am 11:07 AM米国における科学的研究と技術の開発は、おそらく予算削減のために課題に直面する可能性があります。 Natureによると、海外の雇用を申請するアメリカの科学者の数は、2024年の同じ期間と比較して、2025年1月から3月まで32%増加しました。以前の世論調査では、調査した研究者の75%がヨーロッパとカナダでの仕事の検索を検討していることが示されました。 NIHとNSFの助成金は過去数か月で終了し、NIHの新しい助成金は今年約23億ドル減少し、3分の1近く減少しました。リークされた予算の提案は、トランプ政権が科学機関の予算を急激に削減していることを検討しており、最大50%の削減の可能性があることを示しています。 基礎研究の分野での混乱は、米国の主要な利点の1つである海外の才能を引き付けることにも影響を与えています。 35
 オープンAIの最新のGPT 4.1ファミリ - 分析VidhyaApr 26, 2025 am 10:19 AM
オープンAIの最新のGPT 4.1ファミリ - 分析VidhyaApr 26, 2025 am 10:19 AMOpenaiは、強力なGPT-4.1シリーズを発表しました。実際のアプリケーション向けに設計された3つの高度な言語モデルのファミリー。 この大幅な飛躍は、より速い応答時間、理解の強化、およびTと比較した大幅に削減されたコストを提供します


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

SublimeText3 Linux 新バージョン
SublimeText3 Linux 最新バージョン

SAP NetWeaver Server Adapter for Eclipse
Eclipse を SAP NetWeaver アプリケーション サーバーと統合します。

VSCode Windows 64 ビットのダウンロード
Microsoft によって発売された無料で強力な IDE エディター

ZendStudio 13.5.1 Mac
強力な PHP 統合開発環境

SublimeText3 中国語版
中国語版、とても使いやすい
ホットトピック
 7747
7747 15164314139752129125123429
15164314139752129125123429