
ホームページ >テクノロジー周辺機器 >AI >Kuaishou と Beida のマルチモーダル大型モデル: 画像は外国語で、DALLE-3 の画期的な進歩に匹敵します
Kuaishou と Beida のマルチモーダル大型モデル: 画像は外国語で、DALLE-3 の画期的な進歩に匹敵します

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2024-01-30 16:36:28866ブラウズ
ダイナミックなビジュアルワードセグメンテーションによるグラフィックとテキスト表現の統合、Kuaishou と北京大学は協力して、マルチモーダルな理解と生成タスクのリストをブラッシュアップするための基本モデル LaVIT を提案しました。
GPT、LLaMA などの現在の大規模言語モデルは、自然言語処理の分野で大幅な進歩を遂げており、複雑なテキスト コンテンツを理解して生成することができます。しかし、この強力な理解と生成能力をマルチモーダル データに移すことを検討したことがありますか?これにより、大量の画像やビデオを簡単に理解して、豊かなイラストのコンテンツを作成できるようになります。このビジョンを実現するために、Kuaishou と北京大学は最近協力して、LaVIT と呼ばれる新しいマルチモーダル大型モデルを開発しました。 LaVITはこのアイデアを徐々に実現しつつあり、今後の発展が期待されます。

論文のタイトル: 動的離散視覚トークン化を使用した LLM での統合言語視覚事前トレーニング
論文のアドレス: https://arxiv.org/abs/2309.04669
コードモデルアドレス: https://github.com/jy0205/LaVIT
#モデルの概要
LaVIT は、言語モデルに似た、視覚的なコンテンツを理解して生成できる、新しい一般的なマルチモーダル基本モデルです。 LaVIT のトレーニング パラダイムは、大規模な言語モデルの成功体験を活用し、自己回帰アプローチを使用して次の画像またはテキスト トークンを予測します。トレーニング後、LaVIT は、さらに微調整することなく、マルチモーダルな理解と生成タスクを実行できるマルチモーダル ユニバーサル インターフェイスとして機能します。たとえば、LaVIT には次の機能があります。
LaVIT は、テキスト プロンプトに基づいて、高品質、複数のアスペクト比、および審美性の高い画像を生成できる高度な画像生成モデルです。 LaVIT の画像生成機能は、Parti、SDXL、DALLE-3 などの最先端の画像生成モデルと比べても遜色ありません。高品質のテキストから画像への生成を効果的に実現し、より多くの選択肢と優れた視覚体験をユーザーに提供します。

マルチモーダルプロンプトに基づく画像生成: LaVIT では、画像とテキストが離散化されたトークンとして均一に表現されるため、複数のモダリティの組み合わせ (テキスト、画像テキストなど) を受け入れることができます。 、イメージ イメージ)はプロンプトとして機能し、微調整を行わずに対応するイメージを生成します。

画像コンテンツを理解して質問に答える: 入力画像が与えられると、LaVIT は画像コンテンツを読み取り、そのセマンティクスを理解できます。たとえば、モデルは入力画像にキャプションを提供し、対応する質問に答えることができます。

メソッドの概要
LaVIT のモデル構造を次の図に示します。その最適化プロセス全体には 2 つの段階が含まれます。
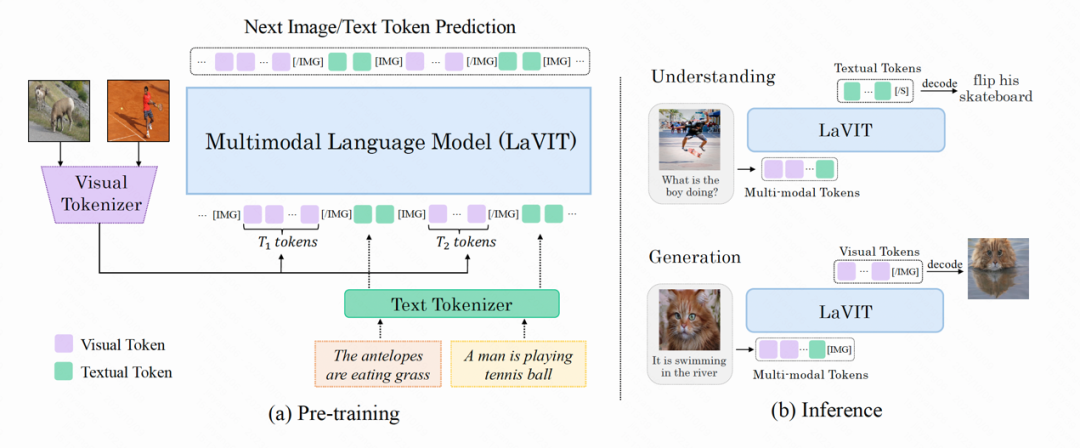
##図: LaVIT モデルの全体的なアーキテクチャ
フェーズ 1: 動的ビジュアルトークナイザー
自然言語のようなビジュアル コンテンツを理解して生成できるようにするために、LaVIT では、LLM が理解できるように、ビジュアル コンテンツ (連続信号) をテキストのようなトークン シーケンスに変換する、適切に設計されたビジュアル トークナイザーを導入しています。外国語も。著者は、統一されたビジョンと言語モデリングを実現するには、ビジュアル トークナイザー (Tokenizer) が次の 2 つの特性を持つ必要があると考えています。Discretization: ビジュアル トークンは、テキストのような離散化された形式で表現されます。これは、2 つのモダリティの統一された表現形式を使用しており、統一された自己回帰生成トレーニング フレームワークの下でマルチモーダル モデリングの最適化に同じ分類損失を使用する LaVIT に役立ちます。
Dynamicization: テキスト トークンとは異なり、画像パッチには重要な相互依存関係があるため、他の 1 つの画像パッチと区別することができます。別の方法は比較的簡単です。したがって、この依存性により、元の LLM の次のトークン予測の最適化目標の有効性が低下します。 LaVIT は、さまざまな画像の異なる意味の複雑さに基づいて動的な数のビジュアル トークンをエンコードするトークン マージを使用して、ビジュアル パッチ間の冗長性を減らすことを提案しています。このように、異なる複雑さの画像に対して、動的トークン エンコーディングを使用すると、事前トレーニングの効率がさらに向上し、冗長なトークン計算が回避されます。
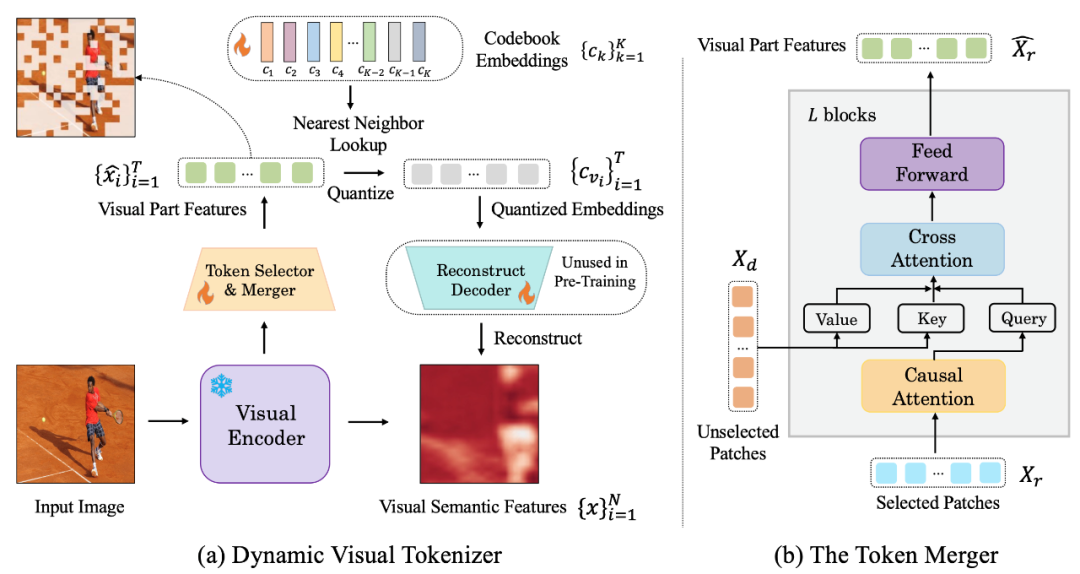
圖:(a) 動態視覺token 產生器(b) token 合併器
此動態視覺分詞器包括token 選擇器和token 合併器。如圖所示, token 選擇器用來選擇最具資訊的影像區塊,而 token 合併器則將那些 uninformative 的視覺區塊的資訊壓縮到保留下的 token 上,實現對冗餘 token 的 merging。整個動態視覺分詞器則透過最大限度地重構輸入影像的語意進行訓練。
Token 選擇器
Token 選擇器接收N 個影像區塊級的特徵作為輸入,其目標是評估每個影像區塊的重要性並選擇資訊量最高的區塊,以充分代表整個影像的語意。為實現這一目標,採用輕量級模組,由多個 MLP 層組成,用於預測分佈 π。透過從分佈 π 中取樣,產生一個二進位決策 mask,用於指示是否保留相應的影像區塊。
Token 合併器
Token 合併器根據產生的決策掩碼,將 N 個影像區塊劃分為保留 X_r 和捨棄 X_d 兩組。與直接丟棄 X_d 不同,token 合併器可以最大限度地保留輸入影像的詳細語意。 token 合併器由 L 個堆疊的區塊組成,每個區塊包括因果自註意力層、交叉注意力層和前饋層。在因果自註意力層中, X_r 中的每個 token 只關注其前面的 token,以確保與 LLM 中的文本 token 形式一致。與雙向自註意相比,這種策略表現更好。交叉注意力層將保留的 token X_r 作為 query,並根據它們在語義上的相似性合併 X_d 中的 token。
階段2: 統一的生成式預訓練
經過視覺分詞器處理後的視覺token 與文字token 相連接形成多模態序列作為訓練時的輸入。為了區分兩種模態,作者在圖像 token 序列的開頭和結尾插入了特殊 token :[IMG] 和 [/IMG],用於表示視覺內容的開始和結束。為了能夠產生文字和圖像,LaVIT 採用兩種圖文連接形式:[image, text] 和 [text; image]。
對於這些多模態輸入序列,LaVIT 採用統一的、自回歸方式來直接最大化每個多模態序列的似然性進行預訓練。這樣在表示空間和訓練方式上的完全統一,有助於 LLM 更好地學習多模態互動和對齊。在預訓練完成後,LaVIT 具有感知圖像的能力,可以像處理文字一樣理解和產生圖像。
實驗
零樣本多模態理解
LaVIT 在圖像字幕產生(NoCaps、Flickr30k)和視覺問答(VQAv2、OKVQA、GQA、VizWiz)等零樣本多模態理解任務上取得了領先的表現。
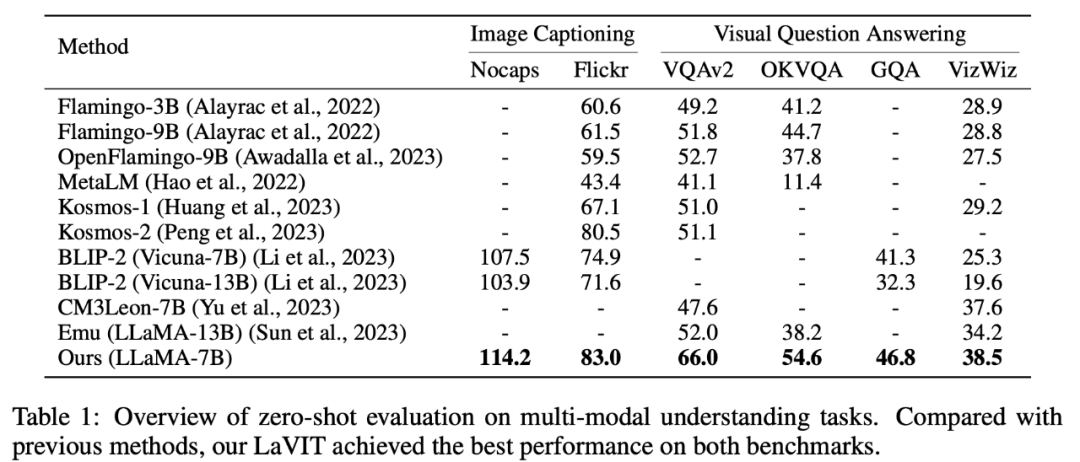
表1 零樣本的多模態理解任務評估
零樣本多模態生成
在這個實驗中,由於所提出的視覺tokenizer 能夠將圖像表示為離散化token,LaVIT 具有透過自回歸生成類似文字的視覺token 來合成圖像的能力。作者對模型進行了零樣本文本條件下的圖像合成性能的定量評估,比較結果如表 2 所示。
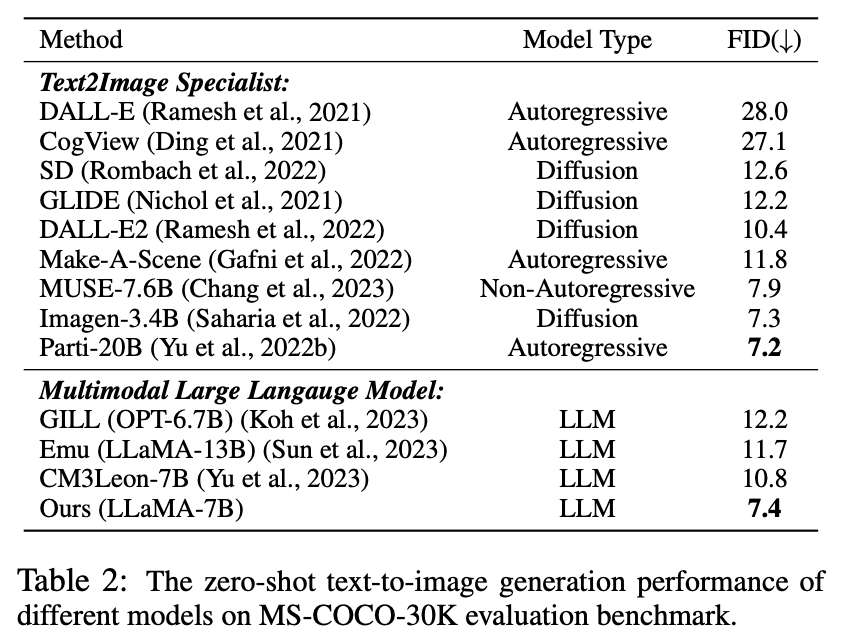
表2 不同模型的零樣本文字到影像產生效能
從表格中可以看出,LaVIT 的表現優於所有其他多模態語言模型。與 Emu 相比,LaVIT 在更小的 LLM 模型上取得了進一步改進,展現了出色的視覺 - 語言對齊能力。此外,LaVIT 在使用更少的訓練資料的情況下,實現了與最先進的文字到影像專家 Parti 可比的性能。
多模態提示影像產生
LaVIT 能夠在無需進行任何微調的情況下,無縫地接受多種模態組合作為提示,產生對應的影像,而無需進行任何微調。 LaVIT 產生的圖像能夠準確反映給定多模態提示的風格和語義。而且它可以透過輸入的多模態提示修改原始輸入影像。在沒有額外微調的下游資料的情況下,傳統的影像生成模型如 Stable Diffusion 無法達到這種能力。

多模態影像產生結果的範例
定性分析
如下圖所示,LaVIT 的動態分詞器可以根據圖像內容動態選擇最具資訊量的圖像區塊,學習到的程式碼本可以產生具有高層語義的視覺編碼。

動態視覺分詞器(左)和學習到的codebook(右)的視覺化
總結
LaVIT 的出現為多模態任務的處理又提供了一種創新範式,透過使用動態視覺分詞器將視覺和語言表示為統一的離散token 表示,繼承了LLM 成功的自回歸生成學習範式。透過在統一生成目標下進行最佳化,LaVIT 可以將圖像視為一種外語,像文字一樣理解和產生它們。這項方法的成功為未來多模態研究的發展方向提供了新的啟示,利用 LLM 強大的推理能力,實現更聰明、更全面的多模態理解和產生打開新的可能性。
以上がKuaishou と Beida のマルチモーダル大型モデル: 画像は外国語で、DALLE-3 の画期的な進歩に匹敵しますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。