
ホームページ >テクノロジー周辺機器 >AI >Apple は自己回帰言語モデルを使用して画像モデルを事前トレーニングします
Apple は自己回帰言語モデルを使用して画像モデルを事前トレーニングします

- 王林転載
- 2024-01-29 09:18:271058ブラウズ
1. 背景
GPT などの大規模モデルの出現後、次のトークンを予測する事前トレーニング タスクである Transformer の言語モデルの自己回帰モデリング手法が大きな成功を収めました。では、この自己回帰モデリング手法はビジュアル モデルでより良い結果を達成できるでしょうか?今日紹介する記事は、Apple が Transformer の自己回帰事前トレーニングに基づいてビジュアル モデルをトレーニングするという最近の記事ですので、その成果を紹介させていただきます。
 図
図
論文タイトル: 大規模な自己回帰画像モデルのスケーラブルな事前トレーニング
ダウンロード アドレス: https://arxiv.org /pdf/2401.08541v1.pdf
オープン ソース コード: https://github.com/apple/ml-aim
2. モデル構造
モデル構造は次のとおりです。 Transformer に基づいており、言語モデルの次のトークン予測を最適化目標として採用します。主な変更点は 3 つの側面です。まず、ViT とは異なり、この記事では GPT の一方向アテンションを使用します。つまり、各位置の要素は前の要素でのみアテンションを計算します。次に、モデルの言語理解能力を向上させるために、より多くのコンテキスト情報を導入します。最後に、モデルのパラメーター設定を最適化して、パフォーマンスをさらに向上させました。これらの改善により、私たちのモデルは言語タスクのパフォーマンスが大幅に向上しました。
 画像
画像
Transformer モデルでは、新しいメカニズムが導入されています。つまり、複数のプレフィックス トークンが入力シーケンスの前に追加されます。これらのトークンは双方向のアテンション メカニズムを使用します。この変更の主な目的は、事前トレーニングと下流のアプリケーション間の一貫性を強化することです。下流のタスクでは、ViT と同様の双方向注意手法が広く使用されています。事前トレーニング プロセスにプレフィックス双方向アテンションを導入することで、モデルはさまざまな下流タスクのニーズによりよく適応できます。このような改善により、モデルのパフォーマンスと一般化機能が向上します。
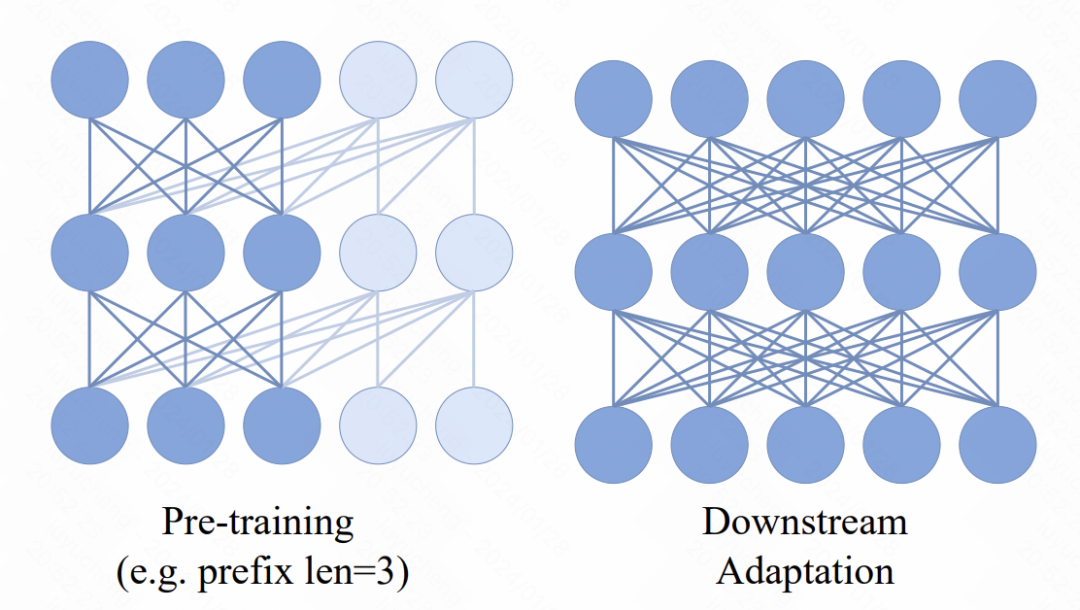 図
図
モデルの最終出力 MLP 層の最適化という点では、元の事前トレーニング方法では通常、MLP 層を破棄して、下流タスク 新しい MLP。これは、事前トレーニングされた MLP が事前トレーニング タスクに偏りすぎて、下流タスクの有効性が低下することを防ぐためです。しかし、この論文では、著者らは新しいアプローチを提案しています。彼らはパッチごとに独立した MLP を使用し、また、各パッチの表現と注意の融合を使用して従来のプーリング操作を置き換えます。このようにして、下流タスクにおける事前トレーニングされた MLP ヘッドの使いやすさが向上します。この方法により、作成者は全体的な画像の情報をより適切に保持し、事前トレーニング タスクへの過度の依存の問題を回避できます。これは、モデルの汎化能力と適応性を向上させるのに非常に役立ちます。
最適化の目標に関して、この記事では 2 つの方法を試しました。1 つ目は、パッチ ピクセルを直接フィッティングし、予測に MSE を使用することです。 2 つ目は、事前に画像パッチをトークン化し、それを分類タスクに変換し、クロスエントロピー損失を使用することです。ただし、この記事のその後のアブレーション実験では、2 番目の方法でもモデルを通常どおりにトレーニングできるものの、その効果はピクセル粒度 MSE に基づく方法ほど良くないことが判明しました。
3. 実験結果
記事の実験部分では、この自己回帰画像モデルの効果とその効果に対する各部分の影響を詳細に分析します。
まず第一に、トレーニングが進むにつれて、下流の画像分類タスクがますます良くなり、この事前トレーニング方法が確かに優れた画像表現情報を学習できることが示されています。
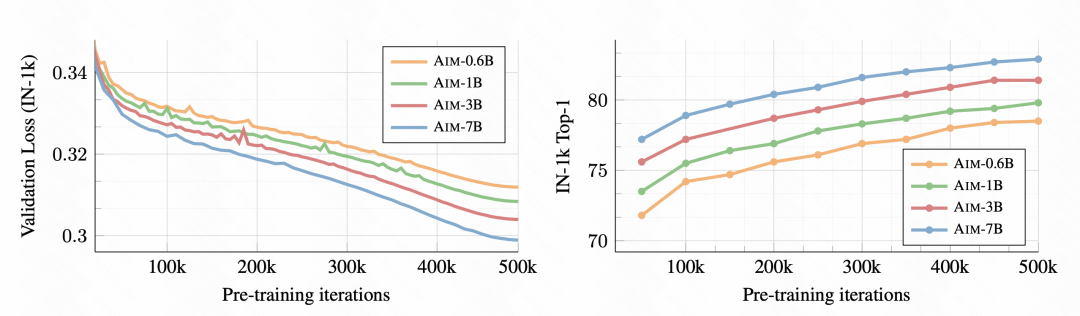 写真
写真
トレーニング データでは、小さなデータセットでトレーニングすると過学習が発生し、最初の検証セットの損失は次のとおりですが DFN-2B を使用します。は大きくなりますが、明らかな過剰適合の問題はありません。
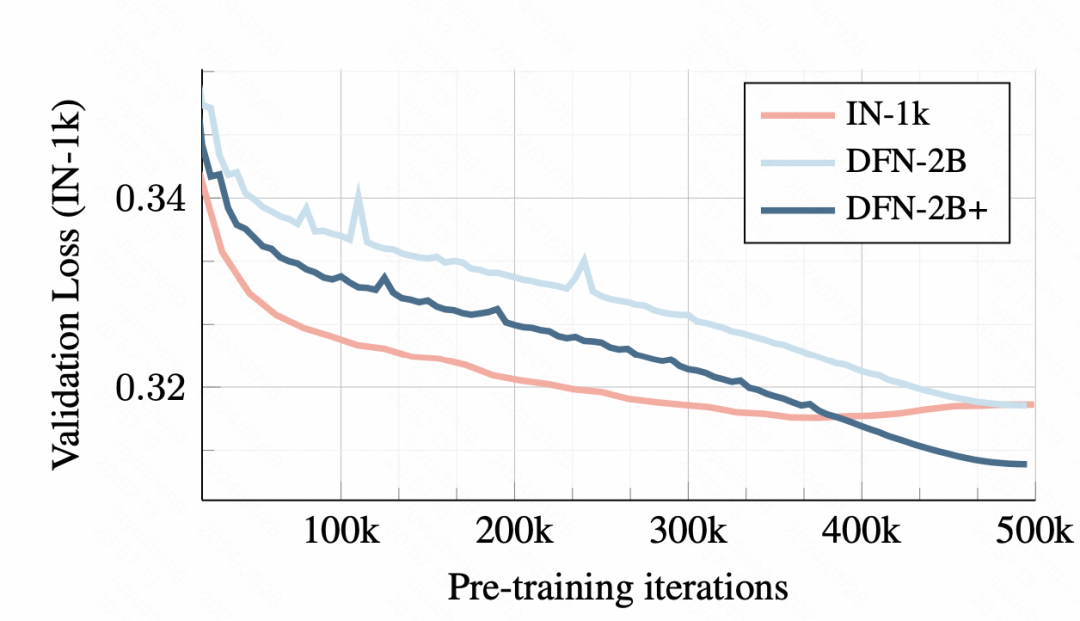 写真
写真
モデルの各モジュールの設計に関して、この記事では詳細なアブレーション実験分析も行っています。
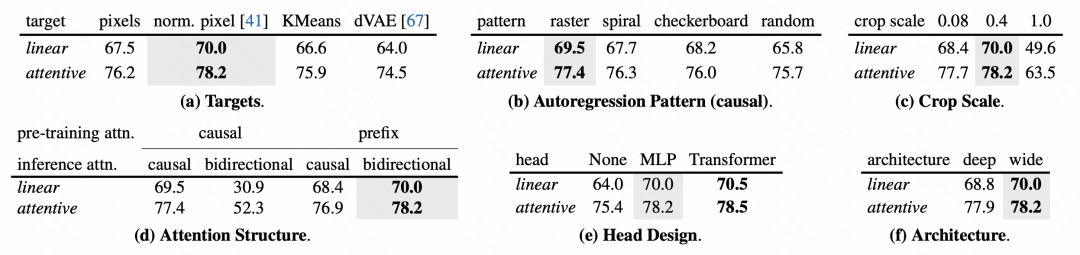 写真
写真
最後の効果比較では、AIM は非常に良い結果を達成し、この自己回帰事前トレーニング方法が効果的であることも検証されました。画像上で使用でき、後続の画像用に大規模なモデルを事前トレーニングする主な方法になる可能性があります。
############################## ###写真### #############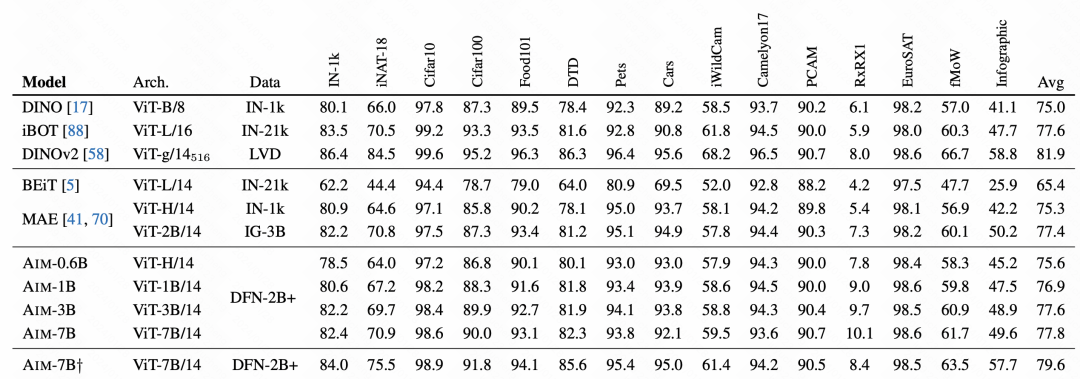
以上がApple は自己回帰言語モデルを使用して画像モデルを事前トレーニングしますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。