
ホームページ >テクノロジー周辺機器 >AI >Transformer モデルは、チャレンジ ビデオ生成で 20 億のデータ ポイントを使用して物理世界を学習することに成功しました
Transformer モデルは、チャレンジ ビデオ生成で 20 億のデータ ポイントを使用して物理世界を学習することに成功しました

- 王林転載
- 2024-01-29 09:09:261317ブラウズ
ビデオを作成できるワールド モデルの構築も Transformer を通じて実現できます。
清華大学と時事テクノロジーの研究者が協力して、ビデオ生成のための新しいユニバーサルワールドモデル WorldDreamer を立ち上げました。
Vincent ビデオ、Tu ビデオ、ビデオ編集、アクション シーケンス ビデオなど、自然シーンや自動運転シーンを含むさまざまなビデオ生成タスクを実行できます。

#チームによると、WorldDreamer は、トークンを予測することで普遍的なシナリオの世界モデルを構築した業界初の企業です。
ビデオ生成をシーケンス予測タスクに変換し、物理世界の変化と動作パターンを完全に学習できます。
視覚化実験により、WorldDreamer が世界全体の動的な変化を深く理解していることが証明されました。
それでは、どのようなビデオタスクを実行でき、その効果は何でしょうか?
さまざまなビデオ タスクをサポート
画像からビデオ (画像からビデオ)
WorldDreamer は、単一の画像に基づいて将来のフレームを予測できます。
最初の画像が入力されている限り、WorldDreamer は残りのビデオ フレームをマスクされたビジュアル トークンとして扱い、これらのトークンを予測します。
下の図に示すように、WorldDreamer には映画レベルの高品質ビデオを生成する機能があります。
結果として得られるビデオは、実際の映画のスムーズなカメラの動きと同様に、シームレスなフレームごとの動きを示します。
さらに、これらのビデオは元の画像の制約を厳密に遵守し、フレーム構成の驚くべき一貫性を保証します。

Text to Video
WorldDreamer はテキストに基づいてビデオを生成することもできます。
言語テキスト入力のみが与えられた場合、WorldDreamer はすべてのビデオ フレームをマスクされたビジュアル トークンとみなして、これらのトークンを予測します。
下の図は、さまざまなスタイル パラダイムの下でテキストからビデオを生成する WorldDreamer の機能を示しています。
生成されたビデオは入力言語にシームレスに適応し、ユーザーが入力した言語によってビデオのコンテンツ、スタイル、カメラの動きが形成されます。

ビデオ変更 (ビデオ修復)
WorldDreamer は、ビデオ修復タスクをさらに実装できます。
具体的には、ビデオに対して、ユーザーがマスク領域を指定すると、言語入力に応じてマスクされた領域のビデオ コンテンツを変更できます。
下の図に示すように、WorldDreamer はクラゲをクマに、またはトカゲをサルに置き換えることができ、置き換えられたビデオはユーザーの言語説明と非常に一致しています。

ビデオ スタイライゼーション
さらに、WorldDreamer はビデオ スタイライゼーションを実現できます。
下図のように、特定のピクセルがランダムにマスクされたビデオセグメントを入力すると、WorldDreamer は入力言語に基づいて秋をテーマにした効果を作成するなど、ビデオのスタイルを変更できます。

アクション合成ビデオ (Action to Video) に基づいて
WorldDreamer は、自動運転シナリオでの運転アクションからビデオを生成することもできます。
下の図に示すように、同じ初期フレームと異なる運転戦略 (左折、右折など) が与えられた場合、WorldDreamer は最初のフレームの制約と運転戦略との一貫性が高いビデオを生成できます。

では、WorldDreamer はどのようにしてこれらの機能を実現しているのでしょうか?
Transformer を使用したワールド モデルの構築
研究者は、最も先進的なビデオ生成方法は、主に Transformer ベースの方法と拡散モデル ベースの方法の 2 つのカテゴリに分類されると考えています。
トークン予測に Transformer を使用すると、ビデオ信号の動的情報を効率的に学習し、大規模な言語モデル コミュニティの経験を再利用できるため、Transformer に基づくソリューションは、一般的な世界モデルを学習する効果的な方法です。
拡散モデルに基づく手法は、単一モデル内に複数のモードを統合することが難しく、より大きなパラメータに拡張することが難しいため、一般世界の変化や運動法則を学習することが困難です。
現在の世界モデル研究は主にゲーム、ロボット、自動運転の分野に集中しており、一般的な世界の変化や運動法則を包括的に捉える能力が不足しています。
したがって、研究チームは、一般世界の変化と移動パターンの学習と理解を強化し、それによってビデオを生成する能力を大幅に強化するために WorldDreamer を提案しました。
大規模言語モデルの成功体験をもとに、WorldDreamer は Transformer アーキテクチャを採用して、ワールド モデル モデリング フレームワークを教師なしのビジュアル トークン予測問題に変換します。
具体的なモデル構造を以下の図に示します。
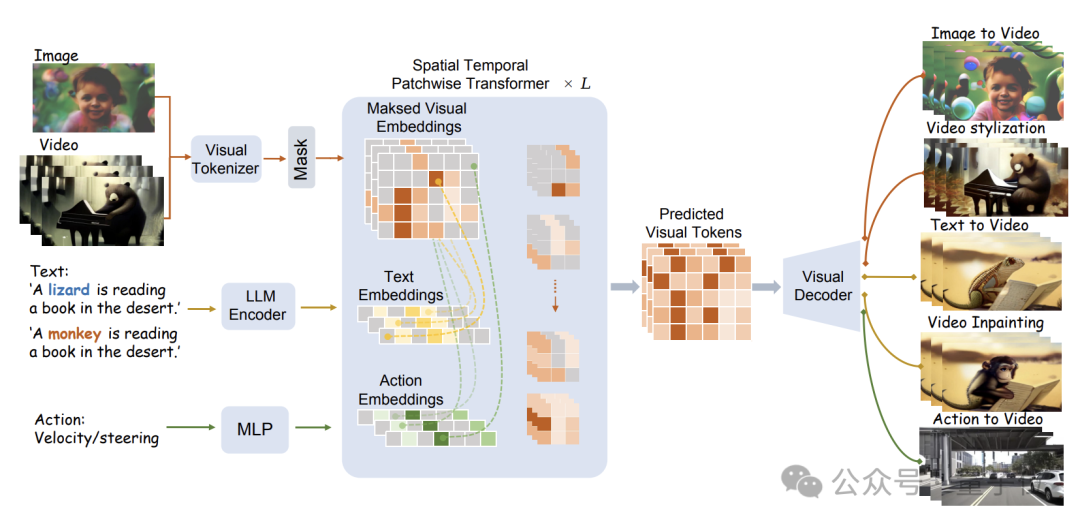
WorldDreamer は、まずビジュアル トークナイザーを使用して、ビジュアル信号 (画像とビデオ) を個別のトークンにエンコードします。 。
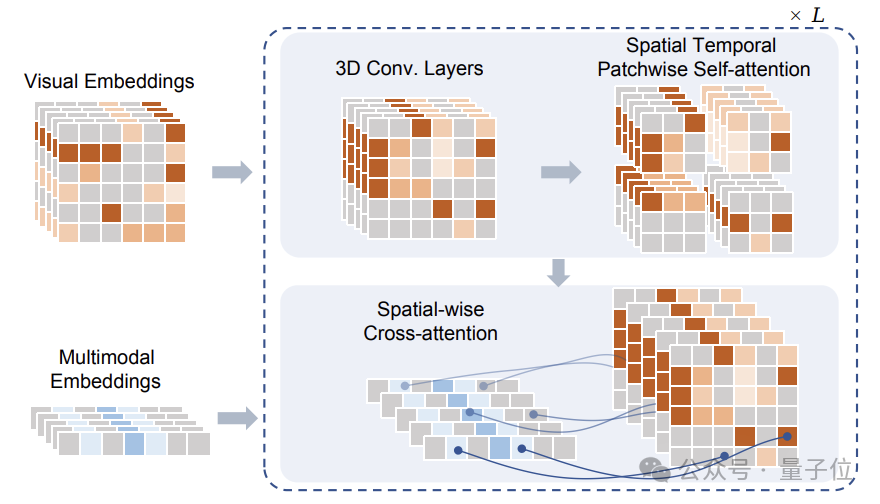
マスキング後、これらのトークンは、研究チームが提案した空間時間パッチトランスフォーマー (STPT) モジュールに入力されます。
同時に、テキスト信号とアクション信号がそれぞれ対応する特徴ベクトルにエンコードされ、マルチモーダル特徴として STPT に入力されます。
STPT は、ビジュアル、言語、アクション、その他の機能を内部的に完全にインタラクティブに学習し、マスクされた部分のビジュアル トークンを予測できます。
最終的に、これらの予測されたビジュアル トークンを使用して、さまざまなビデオ生成およびビデオ編集タスクを完了できます。
WorldDreamer をトレーニングするときに、研究チームが Visual-Text-Action (ビジュアル テキスト アクション) データのトリプレットも構築したことは注目に値します。追加の監視信号なしで、マスクされたビジュアル トークンを予測することが含まれます。
チームが提案したデータ トリプレットでは、視覚情報のみが必要です。つまり、テキストやアクション データがなくても WorldDreamer トレーニングを実行できます。
このモードでは、データ収集の難しさが軽減されるだけでなく、WorldDreamer が未知の条件または単一の条件なしでビデオ生成タスクの完了をサポートできるようになります。
研究チームは、WorldDreamer のトレーニングに大量のデータを使用しました。これには、20 億のクリーンな画像データ、一般的なシーンの 1,000 万のビデオ、50 万の高品質の言語注釈付きビデオ、約 1,000 の自動運転ビデオが含まれます。ビデオ。
チームは、10 億レベルの学習可能なパラメーターで数百万回の反復トレーニングを実施しました。収束後、WorldDreamer は物理世界の変化と移動パターンを徐々に理解し、さまざまなビデオ生成およびビデオ編集機能を備えています。
論文アドレス: https://arxiv.org/abs/2401.09985
プロジェクトのホームページ: https://world-dreamer.github.io/
以上がTransformer モデルは、チャレンジ ビデオ生成で 20 億のデータ ポイントを使用して物理世界を学習することに成功しましたの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。