
ホームページ >システムチュートリアル >Linux >SQL効率の最適化に関する研究
SQL効率の最適化に関する研究

- 王林転載
- 2024-01-28 08:09:051121ブラウズ
これは、2016 年 8 月の上海 MOORACLE カンファレンスで、教師の Chen Honyi (Old K) が共有した事例です。マージ SQL を plsql に書き換えることで、実行効率が大幅に向上しました。 Tiger Liu は、このケースを見たとき、実行計画に表示される各テーブルの実際のレコード数に最初は気づきませんでした。彼は、plsql を書き換える方法が、分析関数を記述する方法よりも効率的であるとも考えませんでした。また、彼は、チェン先生と何度か電子メールで話し合い、実行計画を詳しく調べたのはさらに後になってからでした。
元の SQL は次のとおりです:を使用して t_customer c にマージします。
(t_trade aからa.cstno、a.amountを選択してください、
(t_tradeからcstno,max(trade_date) trade_dateを選択
cstno でグループ化) b
ここで、a.cstno = b.cstno および a.trade_date=b.trade_date
)m
on(c.cstno = m.cstno)
一致した場合は
更新セット c.amount = m.amount; このSQLは、ユーザ取引詳細テーブル(t_trade)の最新の消費金額を、マージ操作によりユーザ情報テーブル(t_customer)の消費金額フィールドに更新するSQLです。
###実行計画:###
タイガー・リュー注:
元の SQL には別の隠れた危険があります。つまり、t_trade の特定の cstno に対応する最大 trade_date が繰り返される場合、この SQL は ORA-30926 エラーを報告し、実行できません。
実行計画 (2 つのテーブルの実際のデータ量情報) を注意深く確認しない場合、この種の SQL の通常の最適化方法は、分析関数を使用して次のように書き換えることです。 書き換え方法1: を使用して t_customer c にマージします。 ( a.cstno、a.amount from
を選択してください
(取引日、cstno、金額、を選択してください
row_number()over(cstno order by trade_date descによるパーティション) t_tradeからのRNO)aここで、RNO=1
)m
on(c.cstno = m.cstno)
一致した場合は
更新セット c.amount = m.amount;
この書き換え方法は元の SQL よりもはるかに効率的であり、特定の cstno に対応する最大 trade_date に関するエラー レポートが繰り返されるという問題は発生しません。
しかし、チェン先生は、分析関数の書き換え手法を使用せず、2 つのテーブルのデータ量の大きな違いに基づいて、SQL をより効率的な plsql に書き換えました。
書き換え方法2: ###宣言する###金額数;
###始める### for v in (select * from t_customer) ###ループ### 金額から金額を選択してください(t_trade から金額を選択します (cstno=v.cstno order by trade_date desc)
どこで行番号
update t_customer set amount = vamount where cstno=v.cstno;
ループの終了
###専念;### ###終わり;###/
元の SQL 実行計画によると、t_customer テーブルのレコード数は比較的少なく、わずか 1,000 件を超えるだけですが、t_trade テーブルには 1,000 万件のレコードがあり、その比率は 1:10000 であることがわかります (これが実際のデータなのかテスト データなのかはわかりません。ユーザーが 1,000 人を超え、平均的なユーザーには 10,000 件の消費詳細があり、実際のデータのようには見えません)。
2 つのテーブル間のデータが大きく異なるという特殊なケースでは、plsql 記述方法は分析関数記述方法
よりも実際に効率的です。この書き換えは非常に巧妙です
。
これら 2 つの書き換えの長所と短所を分析してみましょう:
1. plsql の書き換え方法は、t_customer テーブルが比較的小さく、t_customer テーブルと t_trade テーブルのレコード数の比率が比較的大きい場合に適しており、分析テーブルを書き換えるよりも実行効率が高くなります。関数。この例では、t_customer テーブルのレコード数が 100,000 の場合、分析関数を作成する方法は、plsql を作成する方法よりも数十倍から数百倍高速です。
3. plsql のこの書き換えの前提条件は、t_trade テーブル cstno trade_date の 2 つのフィールドの結合インデックスが存在する必要があることです。分析関数の書き換えにはインデックスのサポートは必要ありません。
4. t_trade のような数千万のレコードを持つテーブルの場合、並列処理を有効にすることで分析関数の作成を高速化できます; plsql を書き換える際の効率を向上させたい場合は、最初に t_customer テーブルを cstno でグループ化し、複数のテーブルを使用する必要があります。セッション、同時実行。
チェン先生の plsql が 1 つの SQL で実装できるかどうか見てみましょう。試してみました。SQL コードは次のとおりです: を使用して t_customer c にマージします。 (
tc.cstnoを選択,(金額を選択してください
t_trade td1より
where td1.cstno=tc.cstno および td1.trade_date = (tc.cstno = td2.cstno である t_trade td2 から max(trade_date) を選択し、rownum=1 ) を金額として指定します
t_customer tc から
)m
on(c.cstno = m.cstno)
一致した場合は
更新セット c.amount = m.amount;
実行計画はおおよそ次のとおりです:
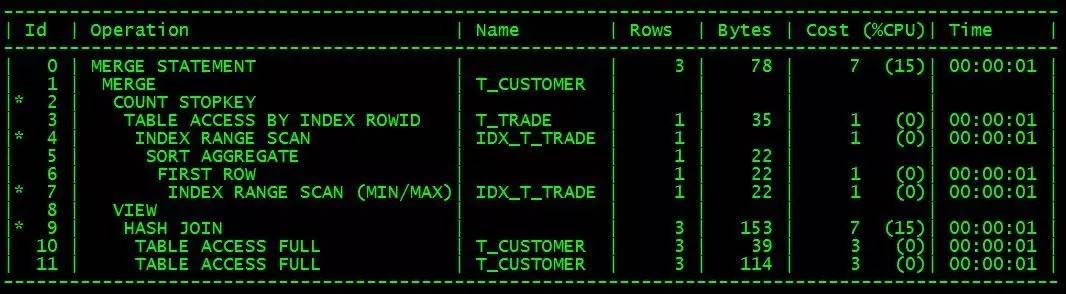
この書き込み方法では、cstno trade_date ジョイント インデックス (IDX_T_TRADE) が t_trade テーブルに存在する必要もあり、T_customer テーブルのデータ量は T_trade のデータ量よりもはるかに少なくなります。
実行計画によると、この SQL の実行効率は plsql 記述の効率と同等になるはずです。
要約:SQL の最適化は、非効率な SQL 書き込みを回避することに加えて、主にテーブルのデータ量とデータ分散に依存します。plsql の再書き込み方法は、いくつかの特殊なケースでより高い効率を示します。データ分散の場合によっては、効率は元の SQL ほど良くない可能性があります。ただし、最適化のアイデアは学ぶ価値があります。
分析関数を書き直す方法は、データがどのように分散されているかに関係なく、元の SQL よりも効率的で汎用性が高くなります。
この例が書き換えられる前の SQL を使用している開発者や DBA はまだたくさんあるはずです。分析機能の使用方法を理解した後は、元の SQL の非効率な記述方法を完全に放棄する必要があります。
最後の plsql は単一の SQL に書き換えられています。ロジックが複雑でわかりにくいようです。通常、このような書き換えは使用されません。誰でも理解できると良いでしょう。
繰り返しになりますが、最適化に明確な公式はありません。オプティマイザは死んだものの、人間の脳は生きています。原則をマスターすることによってのみ、SQL の実行効率はますます高くなります。
以上がSQL効率の最適化に関する研究の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。