




人工知能を実現するにはどうすればよいでしょうか?では、データから知恵まで、人工知能を実現するにはどうすればよいでしょうか?さらに詳しく見てみましょう。
人工知能を実現する方法
人工知能を実現するには、データ、モデル、アルゴリズム、ユーザー エクスペリエンス、倫理など、多くの側面を考慮する必要があります。現実性を実現するためのヒントをいくつか紹介します。
- 多様で高品質のデータ: 多様で高品質のデータ セットを使用してモデルをトレーニングします。モデルの一般化能力を向上させるために、データ セットにさまざまな状況、コンテキスト、および特徴が含まれていることを確認します。
- 透明性と解釈可能性: 透明性と解釈可能性を備えたモデルを設計します。ユーザーは、特に主要分野 (医療、金融など) における人工知能システムの意思決定プロセスを理解する必要があります。説明可能性は、システムに対するユーザーの信頼を構築するのに役立ちます。
- 公平性と不偏性: AI システムがさまざまなグループ間で公平であることを確認し、特定のグループに対する偏見を回避します。モデル内の潜在的なバイアスを監視して修正することが、公平性を確保する鍵となります。
- 人間と機械の共同設計: 人間に代わるのではなく、人間のユーザーと連携するツールとして人工知能システムを設計します。この種の協調設計は、人工知能テクノロジーと人間の知能をより適切に統合し、システムの実用性と受け入れやすさを向上させるのに役立ちます。
- パーソナライゼーションと適応性: ユーザーのニーズに合わせてパーソナライズできるシステムを構築します。個人差を考慮することで、システムはユーザーの期待に応え、ユーザー エクスペリエンスを向上させることができます。
- ユーザーの参加とフィードバック: ユーザーのフィードバックを吸収し、モデル改善のプロセスに組み込みます。ユーザーの参加により、システムがユーザーのニーズをより適切に満たすと同時に、システムに対するユーザーの信頼が向上します。
- リアルタイムの学習と更新: 変化する環境やニーズに適応するシステムのリアルタイムの学習と更新。これは、オンライン学習や段階的学習などの手法を通じて実現できます。
- 倫理および規制の遵守: 関連する倫理および規制を厳格に遵守し、人工知能システムの開発と使用が社会的および法定の倫理基準に準拠していることを確認します。
- セキュリティとプライバシー: 潜在的な悪用や攻撃を防ぐためにシステム セキュリティを重視します。同時に、ユーザーのプライバシー権が保護され、機密情報の取り扱いの遵守が保証されます。
- 持続可能な開発: 人工知能システムの開発と使用を持続可能な開発の範囲に組み込み、環境、社会、経済への長期的な影響を考慮します。
これらの要素を総合的に考慮することで、人工知能はより現実的なものとなり、複雑で変化し続ける現実世界と並行して発展することができます。
人工知能を現実のものにする方法 - データから知恵まで
人工知能を現実のものにするには、単純なデータ処理から深層知能のレベルにアップグレードする必要があります。これには、データの収集、処理、モデルのトレーニング、およびインテリジェントなシステム アプリケーションが含まれます。推奨される手順をいくつか示します。 1. データ収集: 構造化データと非構造化データを含む、多様で高品質のデータを収集します。 2. データ処理: データの正確性と一貫性を確保するために、データのクリーニング、統合、変換に適切なテクノロジーとアルゴリズムを使用します。 3. モデルのトレーニング: トレーニングに適切な機械学習アルゴリズムとモデルを選択し、大規模なデータセットを使用してモデルを最適化および調整します。 4. 実践的な応用: トレーニングされたモデルを実際のシナリオに適用し、既存のシステムと統合してインテリジェントな
を実現します。- データの収集とクリーニング: まず、収集されるデータの品質と多様性を確保する必要があります。これには、構造化データ (データベースの表形式データなど)、半構造化データ (ログ ファイルなど)、非構造化データ (テキスト、画像、音声など) を含むさまざまなソースから大量のデータを収集することが含まれます。データ クリーニングは、欠損値、外れ値、誤ったデータの処理など、データ品質を確保するための重要なステップです。
- 特徴エンジニアリング: 特徴エンジニアリングとは、生データを機械学習モデルで使用できる特徴に変換することを指します。これには、問題にとって意味のある特徴を抽出するためのデータの変換、スケーリング、結合などが含まれる場合があります。優れた特徴量エンジニアリングにより、モデルのパフォーマンスを向上させることができます。
- 適切なモデルを選択します: 問題の性質に基づいて、適切な機械学習モデルまたは深層学習モデルを選択します。これには、従来の教師あり学習モデル (デシジョン ツリー、サポート ベクター マシンなど)、深層学習モデル (ニューラル ネットワークなど)、またはその他のドメイン固有のモデルが含まれる場合があります。
- モデル トレーニング: 大量のラベル付きデータを使用して、選択したモデルをトレーニングします。これには、モデルのパラメーターを調整してデータをより適切に適合させ、新しいデータに一般化する機能を向上させることが含まれます。
- 継続学習: モデルが新しいデータや変更にタイムリーに適応できるように、モデルの継続学習を実現します。これは、オンライン学習手法、増分学習、または定期的なモデルの更新を通じて実現できます。
- 解釈可能性と透明性: 一部のアプリケーション シナリオのニーズを考慮して、ユーザーと関係者がアプリケーション シナリオの意思決定プロセスを理解できるように、モデルにある程度の解釈可能性と透明性が確保されていることを確認します。モデル。
- 実際のアプリケーション: モデルを実際のアプリケーション環境にデプロイし、そのパフォーマンスを監視します。これには、モデルが運用環境で新しいデータを効果的に処理できることを確認し、必要に応じてデータを更新できるようにすることが含まれます。
- 倫理と規制: 人工知能アプリケーションには機密情報が含まれる可能性があることを考慮し、モデルの開発と適用中に関連する倫理と規制が遵守されるようにし、プライバシーと公平性が保証されるようにします。
- ユーザー フィードバックと改善: ユーザー フィードバックを収集し、このフィードバックを使用してモデルを継続的に改善します。これは、AI システムがユーザーのニーズや期待に確実に適合するようにするのに役立ちます。
これらのステップを通じて、人工知能は徐々により深いインテリジェンスを実現し、単純なデータ処理から現実性とインテリジェンスを備えたアプリケーションまで開発することができます。
以上が人工知能を現実にする: データからインテリジェンスへの戦略の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 6 ChatGptは、ブランドブーストポッドキャストの招待状を取得するためのプロンプトを作成しますApr 16, 2025 am 11:16 AM
6 ChatGptは、ブランドブーストポッドキャストの招待状を取得するためのプロンプトを作成しますApr 16, 2025 am 11:16 AMポッドキャストのインタビューを受けるには戦略と一貫した行動が必要なので、多くのビジネスオーナーが到着しない招待状を待っています。今日行動を起こしてください。 これらのプロンプトはあなたを完璧なゲストとして位置づけ、それらのキャリアを獲得します
 5つの強力なAIプロンプトは、あらゆるビジネスアイデアを高めることができますApr 16, 2025 am 11:11 AM
5つの強力なAIプロンプトは、あらゆるビジネスアイデアを高めることができますApr 16, 2025 am 11:11 AM幸いなことに、これは生成的AIが非常に役立つ分野です。いいえ、完全な戦略は考えられません。しかし、それはあなたがビジネス計画をブレインストーミングし、あなたの市場を調査し、マーケティングのコンテンツとメッセージを微調整するのに役立ちます。 それはそうではありません
 卒業生スマート:AI時代のキャリアアドバイスApr 16, 2025 am 11:10 AM
卒業生スマート:AI時代のキャリアアドバイスApr 16, 2025 am 11:10 AM今年だけが違うと感じています。不確実です。 関税戦争が順調に進んでいるという事実だけではありません。 AIは、頭のひっかきと魂が最近検索するという根本的な原因です。ナショナルユースチャリティーワンサイドは最近の調査を実施しました
 効果的な加速主義または向社会的AI。 AIの未来は何ですか?Apr 16, 2025 am 11:09 AM
効果的な加速主義または向社会的AI。 AIの未来は何ですか?Apr 16, 2025 am 11:09 AMアクセラレーション主義者のビジョン:フルスピード先 略してE/ACCとして知られる効果的な加速主義は、2022年頃に、シリコンバレー以降で、その中核で著しく大幅な牽引力を獲得している技術的な最適主義運動として出現しました。
 Excelの相対的、絶対的、混合参照とは何ですか?Apr 16, 2025 am 11:03 AM
Excelの相対的、絶対的、混合参照とは何ですか?Apr 16, 2025 am 11:03 AM導入 私の最初のスプレッドシートの経験は、コピーしたときにフォーミュラの予測不可能な動作のためにイライラしていました。 私はその時のセルの参照を理解していませんでしたが、相対的、絶対的、混合された参照をマスターすることは私のスプレッドに革命をもたらしました
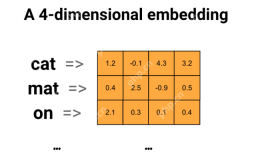 Word2vecを使用したスマートサブジェクトの電子メールラインの生成Apr 16, 2025 am 11:01 AM
Word2vecを使用したスマートサブジェクトの電子メールラインの生成Apr 16, 2025 am 11:01 AMこの記事では、Word2VECエンボードを使用して効果的な電子メールの件名を生成する方法を示しています。 セマンティックな類似性を活用して、コンテキストに関連する件名を作成し、電子メールマーケティングを改善するシステムを構築することでガイドします。
 データアナリストの将来Apr 16, 2025 am 11:00 AM
データアナリストの将来Apr 16, 2025 am 11:00 AMデータ分析:進化する風景のナビゲート データが数字だけでなく、すべての経営陣の決定の礎石を想像してください。 この動的環境では、データアナリストは不可欠であり、生データを実行可能に変換します
 Excelの等式機能は何ですか? - 分析VidhyaApr 16, 2025 am 10:55 AM
Excelの等式機能は何ですか? - 分析VidhyaApr 16, 2025 am 10:55 AMExcelの等式関数:データ分析パワーハウス 合理化されたデータ分析のためのExcelの等式関数の力のロックを解除します。この汎用性のある関数は、合計と乗算機能を簡単に組み合わせて、追加に拡張し、減算


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

Dreamweaver Mac版
ビジュアル Web 開発ツール

PhpStorm Mac バージョン
最新(2018.2.1)のプロフェッショナル向けPHP統合開発ツール

SublimeText3 英語版
推奨: Win バージョン、コードプロンプトをサポート!

DVWA
Damn Vulnerable Web App (DVWA) は、非常に脆弱な PHP/MySQL Web アプリケーションです。その主な目的は、セキュリティ専門家が法的環境でスキルとツールをテストするのに役立ち、Web 開発者が Web アプリケーションを保護するプロセスをより深く理解できるようにし、教師/生徒が教室環境で Web アプリケーションを教え/学習できるようにすることです。安全。 DVWA の目標は、シンプルでわかりやすいインターフェイスを通じて、さまざまな難易度で最も一般的な Web 脆弱性のいくつかを実践することです。このソフトウェアは、

mPDF
mPDF は、UTF-8 でエンコードされた HTML から PDF ファイルを生成できる PHP ライブラリです。オリジナルの作者である Ian Back は、Web サイトから「オンザフライ」で PDF ファイルを出力し、さまざまな言語を処理するために mPDF を作成しました。 HTML2FPDF などのオリジナルのスクリプトよりも遅く、Unicode フォントを使用すると生成されるファイルが大きくなりますが、CSS スタイルなどをサポートし、多くの機能強化が施されています。 RTL (アラビア語とヘブライ語) や CJK (中国語、日本語、韓国語) を含むほぼすべての言語をサポートします。ネストされたブロックレベル要素 (P、DIV など) をサポートします。

