
ホームページ >テクノロジー周辺機器 >AI >Jia Yangqing の高効率による大規模推論コスト ランキングが公開
Jia Yangqing の高効率による大規模推論コスト ランキングが公開

- 王林転載
- 2024-01-26 14:15:34724ブラウズ
「大規模モデルのAPIは赤字ビジネスなのか?」
大規模言語モデル技術の実用化により、多くのテクノロジー 同社は、開発者が使用できる大規模なモデル API を立ち上げました。しかし、特に OpenAI が 1 日あたり 70 万ドルを消費していることを考えると、大規模モデルに基づくビジネスが維持できるかどうか疑問に思わざるを得ません。
今週木曜日、AI スタートアップの Martian が私たちのために注意深く計算してくれました。
リーダーボードのリンク: https://leaderboard.withmartian.com/
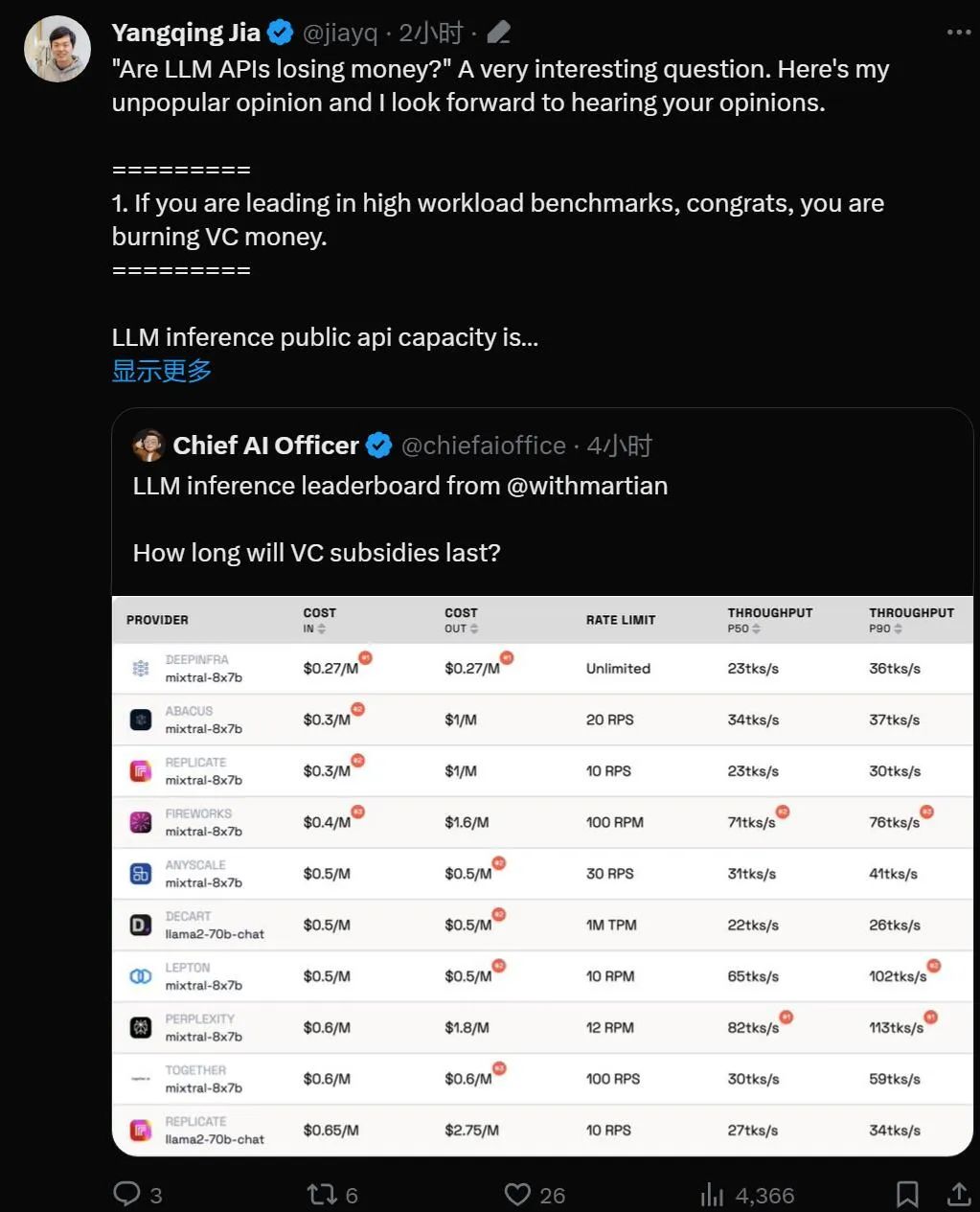
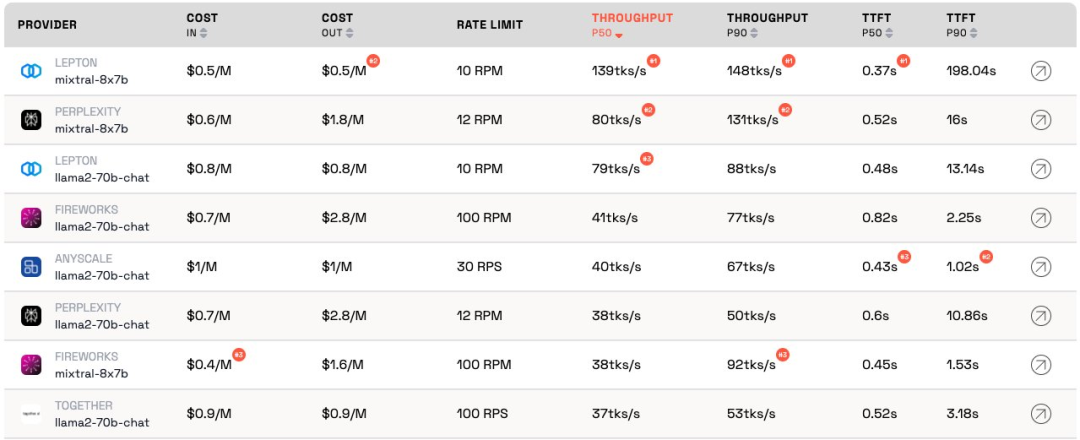
LLM 推論プロバイダーLeaderboard は、大規模モデル向けの API 推論製品のオープンソース ランキングであり、各ベンダーの Mixtral-8x7B および Llama-2-70B-Chat パブリック エンドポイントのコスト、レート制限、スループット、P50 および P90 TTFT をベンチマークします。
両社は相互に競合していますが、Martian は、各企業の大規模モデル サービスのコスト、スループット、およびレート制限に大きな違いがあることに気付きました。これらの違いは、5 倍のコストの違い、6 倍のスループットの違い、さらにはさらに大きなレート制限の違いを超えています。さまざまな API を選択することは、ビジネスの一部であっても、最高のパフォーマンスを得るために重要です。
現在のランキングによると、Anyscale が提供するサービスは、Llama-2-70B の中程度のサービス負荷の下で最高のスループットを示しています。サービス負荷が大きい場合、Togetter AI は、Llama-2-70B および Mixtral-8x7B で P50 および P90 のスループットで最高のパフォーマンスを発揮しました。
さらに、Jia Yangqing の LeptonAI は、短い入力キューと長い出力キューで小さなタスク負荷を処理する場合に最高のスループットを示しました。 130 tks/s の P50 スループットは、現在市場にあるすべてのメーカーが提供しているモデルの中で最速です。
著名な AI 学者であり、Lepton AI の創設者でもある Jia Yangqing 氏は、ランキングの発表直後にコメントしました。

Jia Yangqing 氏は、まず人工知能分野における業界の現状を説明し、次にベンチマーク テストの重要性を確認し、最後に次のように指摘しました。 LeptonAI は、ユーザーが最適な AI 基本戦略を見つけるのに役立ちます。
1. 大きなモデルの API は「お金を燃やしている」
モデルが高ワークロードのベンチマーク テストにある場合それは主導的な位置にあります、おめでとうございます、それは「お金を燃やしています」。
LLM パブリック API の容量についての推論は、レストランの経営に似ています。シェフがいて、顧客のトラフィックを見積もる必要があります。シェフを雇うとお金がかかります。レイテンシーとスループットは、「顧客のためにどれだけ速く調理できるか」として理解できます。合理的なビジネスのためには、「合理的な」数のシェフが必要です。言い換えれば、数秒以内に発生する突然のトラフィックのバーストではなく、通常のトラフィックを処理できる容量が必要です。トラフィックの急増は待つことを意味し、そうでなければ「料理人」は何もすることができません。
人工知能の世界では、GPU は「シェフ」の役割を果たします。ベースライン負荷はバースト的です。ワークロードが低い場合、ベースライン負荷は通常のトラフィックに混合され、測定値は現在のワークロード下でサービスがどのように実行されるかを正確に表します。
サービス負荷が高いシナリオは、中断が発生するため興味深いものです。ベンチマークは 1 日または週に数回しか実行されないため、予想される通常のトラフィックではありません。シェフがどれほど早く調理するかを確認するために地元のレストランに 100 人が集まることを想像してみてください。結果は素晴らしいものになるでしょう。量子物理学の用語を借りると、これは「観察者効果」と呼ばれます。干渉が強いほど(つまり、バースト負荷が大きいほど)、精度は低くなります。言い換えれば、サービスに突然高負荷をかけ、サービスが非常に速く応答することが確認できれば、そのサービスにはかなりのアイドル容量があることがわかります。投資家として、この状況を見たとき、「このお金の使い方に責任はあるのか?」と問うべきです。
#2. モデルは最終的に同様のパフォーマンスを達成します 人工知能の分野は競争が非常に好きで、確かに興味深いものです。全員が同じソリューションにすぐに集中し、最後には GPU のおかげで Nvidia が常に勝利します。これは優れたオープンソース プロジェクトのおかげであり、vLLM はその好例です。これは、プロバイダーとして、自分のモデルのパフォーマンスが他のモデルよりもはるかに悪い場合でも、オープンソース ソリューションを検討し、優れたエンジニアリングを適用することで簡単に追いつくことができることを意味します。 3. 「顧客として、プロバイダーのコストは気にしません」 人工知能の場合アプリケーションの構築 開発者にとって幸運なのは、「お金を燃やす」意欲のある API プロバイダーが常に存在することです。 AI 業界はトラフィックを獲得するために資金を浪費していますが、次のステップは利益を心配することです。 ベンチマークは退屈でエラーが発生しやすい作業です。良くも悪くも、勝者はあなたを賞賛し、敗者はあなたを非難することがよくあります。前回の畳み込みニューラル ネットワーク ベンチマークも同様でした。これは簡単な作業ではありませんが、ベンチマークは AI インフラストラクチャで次の 10 倍を達成するのに役立ちます。 人工知能フレームワークとクラウド インフラストラクチャに基づいて、LeptonAI はユーザーが最適な AI 基本戦略を見つけるのに役立ちます。
以上がJia Yangqing の高効率による大規模推論コスト ランキングが公開の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。