
ホームページ >テクノロジー周辺機器 >AI >Yancore Digital が、オフラインのデバイス側展開をサポートする大規模な非アテンション メカニズム モデルをリリース
Yancore Digital が、オフラインのデバイス側展開をサポートする大規模な非アテンション メカニズム モデルをリリース

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2024-01-26 08:24:061300ブラウズ
1月24日、上海Yanxinshuzhi Artificial Intelligence Technology Co., Ltd.は、アテンションメカニズムのない大規模な一般自然言語モデル-Yanモデルを発表しました。 Yancore Digital Intelligenceの記者会見によると、YanモデルはTransformerアーキテクチャに代わる新しい自社開発の「Yanアーキテクチャ」を採用しており、Transformerと比較してメモリ容量が3倍、速度が7倍向上したという。推論スループットを達成しながら 5 倍向上。  Yancore Digital Intelligence CEO の Liu Fanping 氏は、大規模なことで有名な Transformer は高いコンピューティング能力と実用的なアプリケーションのコストが高く、それが多くの中小企業の利用を妨げていると考えています。内部アーキテクチャの複雑さにより、意思決定プロセスの説明が難しくなり、長いシーケンスの処理の難しさと制御不能な幻覚の問題により、特定の主要分野や特殊なシナリオにおける大規模モデルの広範な適用も制限されます。クラウド コンピューティングとエッジ コンピューティングの普及に伴い、業界では高性能かつ低エネルギー消費の大規模 AI モデルに対する需要が高まっています。
Yancore Digital Intelligence CEO の Liu Fanping 氏は、大規模なことで有名な Transformer は高いコンピューティング能力と実用的なアプリケーションのコストが高く、それが多くの中小企業の利用を妨げていると考えています。内部アーキテクチャの複雑さにより、意思決定プロセスの説明が難しくなり、長いシーケンスの処理の難しさと制御不能な幻覚の問題により、特定の主要分野や特殊なシナリオにおける大規模モデルの広範な適用も制限されます。クラウド コンピューティングとエッジ コンピューティングの普及に伴い、業界では高性能かつ低エネルギー消費の大規模 AI モデルに対する需要が高まっています。
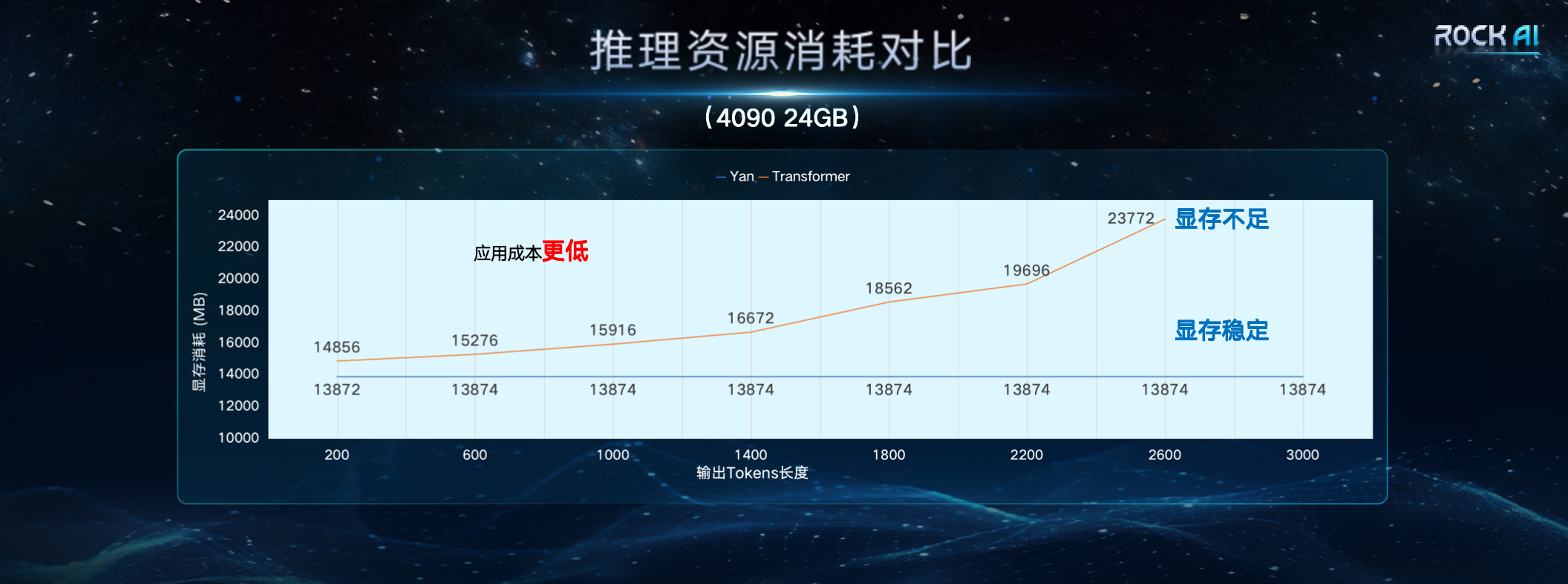
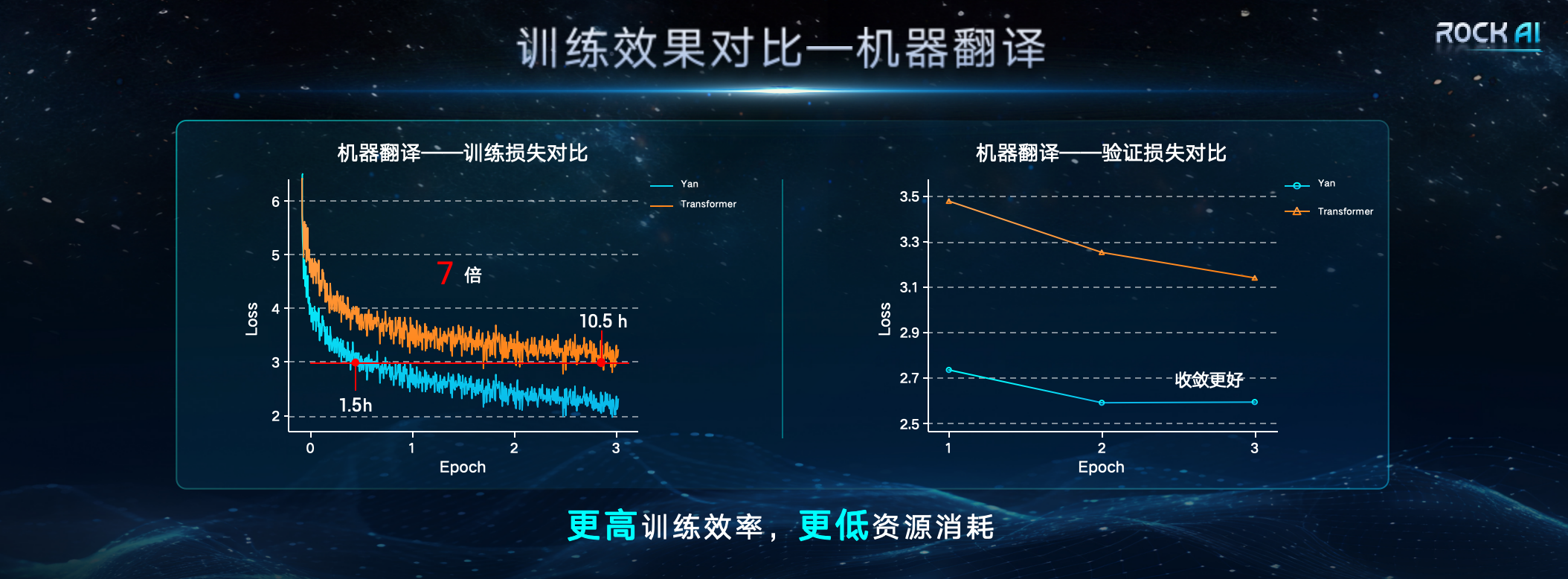
「世界中で、多くの優れた研究者が、Transformer アーキテクチャへの過度の依存を根本的に解決し、Transformer に代わるより良い方法を模索してきました。Transformer 論文の著者の 1 人である Llion Jones でさえ、「Transformer 後の可能性」を探求しています。 「Transformer」では、進化の原理に基づいた自然からインスピレーションを得たインテリジェントな手法を使用して、さまざまな角度から AI フレームワークを再定義しようとしています。」 リソース条件下では、Yan アーキテクチャ モデルのトレーニング効率と推論スループットは 7 倍ですTransformer アーキテクチャのそれぞれの 5 倍と 5 倍、メモリ容量は 3 倍向上しています。 Yan アーキテクチャの設計により、推論中の Yan モデルの空間複雑さが一定になるため、Yan モデルは、Transformer が直面する長いシーケンスの問題に対しても優れたパフォーマンスを発揮します。比較データによると、単一の 4090 24G グラフィックス カードでは、モデル出力トークンの長さが 2600 を超えると、Transformer モデルではビデオ メモリ不足が発生しますが、Yan モデルのビデオ メモリ使用量は常に約 14G で安定しています。理論的には無限長の推論が可能になります。
 さらに、研究チームは、線形計算手法と組み合わせた合理的な相関特性関数とメモリ演算子を開発し、モデルの内部構造の複雑さを軽減しました。新しいアーキテクチャの下のヤンモデルは、これまでの自然言語処理の「解釈不能なブラックボックス」を開放し、意思決定プロセスの透明性と説明可能性を徹底的に探求し、それによって高リスク分野での大規模モデルの普及を促進します。医療、金融、法律など。
さらに、研究チームは、線形計算手法と組み合わせた合理的な相関特性関数とメモリ演算子を開発し、モデルの内部構造の複雑さを軽減しました。新しいアーキテクチャの下のヤンモデルは、これまでの自然言語処理の「解釈不能なブラックボックス」を開放し、意思決定プロセスの透明性と説明可能性を徹底的に探求し、それによって高リスク分野での大規模モデルの普及を促進します。医療、金融、法律など。
以上がYancore Digital が、オフラインのデバイス側展開をサポートする大規模な非アテンション メカニズム モデルをリリースの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。