
ホームページ >システムチュートリアル >Linux >DBMSの運用・保守を自動化する機械学習アプリケーション
DBMSの運用・保守を自動化する機械学習アプリケーション

- 王林転載
- 2024-01-24 12:21:16707ブラウズ
データベース管理システム (DBMS) は、データ集約型アプリケーションの重要な部分です。大量のデータや複雑なワークロードを処理できますが、キャッシュやディスクへの書き込みに使用するメモリの量など、さまざまな要素を制御する数百または数千の「ノブ」(構成変数)があるため、管理が困難でもあります。 。 頻度。多くの場合、組織はチューニングを行うために専門家を雇わなければなりませんが、多くの組織にとって専門家は費用がかかりすぎます。カーネギー メロン大学のデータベース研究グループの学生と研究者は、DBMS の「ノブ」の適切な設定を自動的に見つける OtterTune と呼ばれる新しいツールを開発しています。このツールの目的は、データベース管理の専門知識がなくても、誰でも DBMS を導入できるようにすることです。
OtterTune は、以前の DBMS チューニングの知識を使用して新しい DBMS をチューニングするため、消費される時間とリソースが大幅に削減されるため、他の DBMS セットアップ ツールとは異なります。 OtterTune は、以前のチューニングで蓄積された知識ベースを維持することでこれを実現し、この蓄積されたデータは、さまざまな設定に対する DBMS の反応をキャプチャする機械学習 (ML) モデルの構築に使用されます。 OtterTune はこれらのモデルを使用して新しいアプリケーションの実験をガイドし、レイテンシーの削減やスループットの向上などの最終目標を向上させる構成を推奨します。
この記事では、OtterTune の各機械学習パイプライン コンポーネントと、それらがどのように相互作用して DBMS セットアップを調整するかについて説明します。次に、MySQL および Postgres での OtterTune のチューニング パフォーマンスを評価し、その最適な構成を DBA や他の自動チューニング ツールと比較します。
OtterTune は、カーネギー メロン大学のデータベース研究グループの学生と研究者によって開発されたオープン ソース ツールです。すべてのコードは Github でホストされ、Apache License 2.0 ライセンスに基づいてリリースされています。
OtterTune の仕組み下の図は、OtterTune コンポーネントとワークフローを示しています
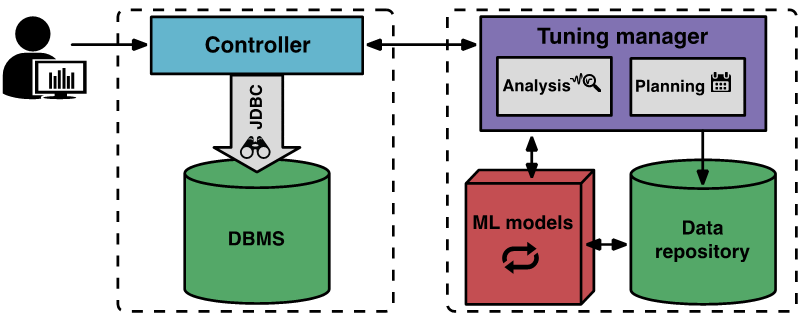
チューニング プロセスは、ユーザーが調整する最終目標 (レイテンシーやスループットなど) を OtterTune に指示したときに開始され、クライアント コントローラー プログラムがターゲット DBMS に接続して、Amazon EC2 インスタンス タイプと現在の設定を収集します。
次に、コントローラーは最終目標を観察および記録するために最初の観察期間を開始します。観察が完了すると、コントローラーは MySQL ディスク ページの読み取りおよび書き込み数などの DBMS 内部メトリックを収集します。コントローラーはこのデータをチューニング マネージャー プログラムに返します。
OtterTune のチューニング マネージャーは、受信したメトリック データをナレッジ ベースに保存します。 OtterTune はこれらの結果を使用してターゲット DBMS の次の構成を計算し、推定されたパフォーマンス向上とともにそれをコントローラーに返します。ユーザーは、チューニングプロセスを続行するか終了するかを決定できます。
###知らせ### OtterTune は、サポートされている DBMS バージョンごとに「ノブ」のブラックリストを維持します。これには、チューニングには重要ではないもの (データ ファイルを保存するパスなど)、または深刻な結果や隠れた結果 (データ損失など) があるものも含まれます。一部。 OtterTune はチューニング プロセスの開始時にこのブラックリストをユーザーに提供し、ユーザーは OtterTune に避けてもらいたい他の「ノブ」を追加できます。OtterTune には、一部のユーザーに特定の制限を引き起こす可能性のある事前に決められた前提条件がいくつかあります。たとえば、コントローラが DBMS 構成を変更するには、ユーザーが管理者権限を持っていることを前提としています。それ以外の場合、ユーザーは、OtterTune がチューニング実験を実行できるように、データベースのコピーを他のハードウェアにデプロイする必要があります。これには、ユーザーがワークロードを再現するか、クエリを運用 DBMS に転送する必要があります。完全な前提と制限については、論文を参照してください。
機械学習パイプライン
次の図は、OtterTune ML パイプライン処理データのプロセスであり、すべての観測結果はナレッジ ベースに保存されます。OtterTune は、まず観察データをワークロード特性評価コンポーネントに供給します。このコンポーネントは、さまざまなワークロードのパフォーマンスの変化と顕著な特性を最も効果的に捕捉する DBMS メトリクスの小さなセットを特定します。
次のステップでは、「ノブ識別コンポーネント」は、DBMS のパフォーマンスに最も大きな影響を与えるノブを含むノブのランキング リストを生成します。次に、OtterTune はこのすべての情報を自動チューナーに「フィード」します。自動チューナーは、ターゲット DBMS のワークロードをナレッジ ベース内の最も近いワークロードにマップし、このワークロード データを再利用してより適切な構成を生成します。
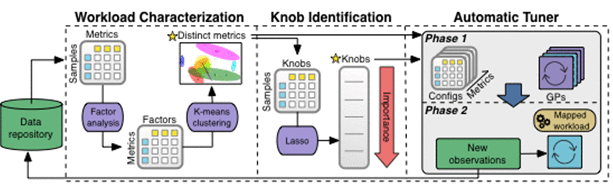 以下、機械学習パイプラインの各コンポーネントを詳しく見てみましょう。
以下、機械学習パイプラインの各コンポーネントを詳しく見てみましょう。
ワークロードの特徴付け: OtterTune は、DBMS の内部ランタイム メトリクスを利用して、特定のワークロードの動作を特徴付けます。これらのメトリクスは、ワークロードの動作の複数の側面をキャプチャするため、ワークロードを正確に表します。ただし、多くのインジケーターは冗長です。同じメジャーを異なる単位で表すものもあれば、DBMS の独立したコンポーネントを表すものもありますが、それらの値は高度に相関しています。機械学習モデルの複雑さを軽減するには、冗長な尺度を整理することが重要です。したがって、相関関係に基づいて DBMS メトリクスをクラスタリングし、最も代表的なメトリクス、特に中央値に最も近いメトリクスを選択します。機械学習の後続のコンポーネントでは、これらの手段が使用されます。
ノブの識別: DBMS には数百のノブを含めることができますが、パフォーマンスに影響を与えるのはそのうちの一部だけです。 OtterTune は、Lasso と呼ばれる一般的な機能選択テクニックを使用して、システム全体のパフォーマンスに最も大きな影響を与えるノブを決定します。この手法を使用してナレッジ ベース内のデータを処理することで、OtterTune は DBMS ノブの重要性の順序を決定することができました。
次に、OtterTune は、構成を推奨するときに使用するノブの数を決定する必要があります。ノブが多すぎると、OtterTune のチューニング時間が大幅に長くなり、使用するノブが少なすぎると、最適な構成を見つけることが困難になります。 OtterTune は増分アプローチを使用してこのプロセスを自動化し、チューニング セッション中に使用するノブの数を徐々に増やします。このアプローチにより、OtterTune は、最初に少数の最も重要なノブを使用して構成を探索して微調整し、その後、他のノブを検討するために拡張することができます。
自動チューナー: 自動チューナー コンポーネントは、2 段階の分析方法を使用して、各観察フェーズの後にどの構成を推奨するかを決定します。
まず、システムは、ワークロード特性評価コンポーネントによって検出されたパフォーマンス データを使用して、現在のターゲット DBMS ワークロードに最も近い過去のチューニング プロセスを特定し、2 つのメトリクスを比較して、さまざまなノブ設定でどの値が類似しているかを特定します。反応。
次に、OtterTune は別のノブ構成を試行し、収集されたデータとナレッジ ベース内の最も近いワークロード データに統計モデルを適用します。このモデルにより、OtterTune は考えられるあらゆる構成で DBMS がどのように動作するかを予測できます。 OtterTune は、探索 (モデルを改善するための情報の収集) と活用 (ターゲット メトリックに貪欲に近づく) を交互に行いながら、次の構成を調整します。
###成し遂げる### OtterTune は Python で書かれています。ワークロードの特性評価とノブ識別コンポーネントの場合、実行時のパフォーマンスは主要な考慮事項ではないため、scikit-learn を使用して対応する機械学習アルゴリズムを実装します。これらのアルゴリズムはバックグラウンド プロセスで実行され、新しく生成されたデータをナレッジ ベースに吸収します。
自動チューニング コンポーネントの場合、機械学習アルゴリズムは非常に重要です。 OtterTune がテストする次のノブを選択できるように、完了後に各観察フェーズを実行して新しいデータを吸収する必要があります。パフォーマンスを考慮する必要があるため、TensorFlow を使用して実装します。
DBMS ハードウェア、ノブ構成、およびランタイム パフォーマンス メトリクスを収集するために、OLTP-Bench ベンチマーク フレームワークを OtterTune のコントローラーに統合しました。
###実験計画###OtterTune の MySQL および Postgres 向けのクラス最高の構成を、評価のために次の構成オプションと比較しました。
デフォルト: DBMS 初期構成 チューニングスクリプト:オープンソースのチューニング提案ツールによる設定DBA: 人間の DBA によって選択された構成
RDS: Amazon 開発者が管理する DBMS のカスタム構成を同じ EC2 インスタンス タイプに適用します。
すべての実験は Amazon EC2 スポット インスタンスで実行されました。各実験は、タイプ m4.large および m3.xlarge の 2 つのインスタンスで実行されます。1 つは OtterTune コントローラー用で、もう 1 つはターゲット DBMS デプロイメント用です。 OtterTune チューニング マネージャーとナレッジ ベースは、20 コア 128G メモリ サーバー上にローカルに展開されます。
ワークロードでは、オンライン取引システムのパフォーマンスを評価するための業界標準である TPC-C を使用します。
###評価する###
実験では、MySQL と Postgres の各データベースのレイテンシーとスループットを測定しました。以下のグラフはその結果を示しています。最初のグラフは、トランザクションの完了にかかる「最悪の場合」の時間を表す「99 パーセンタイル レイテンシー」の数値を示しています。 2 番目のグラフは、1 秒あたりに実行されるトランザクションの平均数として測定されたスループットの結果を示しています。
MySQL の実験結果
OtterTune によって生成された最適な構成は、チューニング スクリプトと RDS の構成と比較して、OtterTune によって MySQL のレイテンシーが約 60% 削減され、スループットが 22% ~ 35% 増加しました。 OtterTune は、DBA とほぼ同等の構成も生成します。 TPC-C 負荷の下では、パフォーマンスに大きな影響を与える MySQL ノブはわずか数個だけです。 OtterTune と DBA の設定により、これらのノブが適切な値に設定されます。 1 つのノブに次善の値が割り当てられていたため、RDS のパフォーマンスがわずかに低下しました。ノブが 1 つだけ変更されたため、チューニング スクリプトのパフォーマンスは最悪でした。Postgres の実験結果
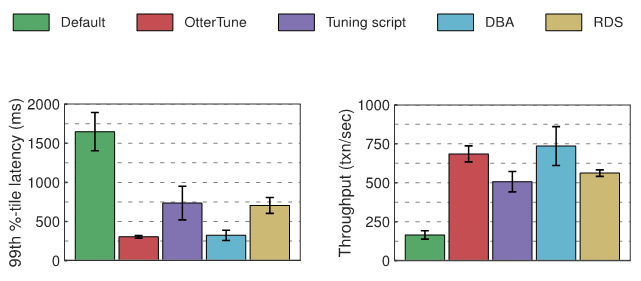
レイテンシーの点では、Postgres のデフォルト構成と比較して、OtterTune、チューニング ツール、DBA、および RDS の構成でも同様の改善が達成されています。これはおそらく、OLTP-Bench クライアントと DBMS の間のネットワーク オーバーヘッドが原因であると考えられます。スループットの点では、OtterTune で構成した場合、Postgres は DBA およびチューニング スクリプトより 12% 高く、RDS より 32% 高くなります。
###結論### OtterTune は、DBMS 構成ノブの最適な値を見つけるプロセスを自動化します。以前のチューニング プロセスで収集されたトレーニング データを再利用して、新しくデプロイされた DBMS をチューニングします。 OtterTune は機械学習モデルをトレーニングするために初期化データセットを生成する必要がないため、チューニング時間が大幅に短縮されます。 ###次は何が起こる? DBaaS (DBMS ホストへのリモート ログインが不可能な場合) の人気の高まりに合わせて、OtterTune は間もなく、リモート ログインを必要とせずにターゲット DBMS のハードウェア機能を自動的に調査できるようになります。OtterTune について詳しくは、GitHub の論文とコードをご覧ください。 OtterTune を近々オンライン チューニング サービスにする予定ですので、このサイトに注目してください。
以上がDBMSの運用・保守を自動化する機械学習アプリケーションの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。