



Pandas ライブラリは、Python でのデータ処理と分析のための重要なツールの 1 つです。データを処理するための豊富な機能と方法が提供されますが、大規模なデータセットを操作する場合は、いくつかの効率的なアプリケーションテクニックにも注意を払う必要があります。この記事では、一般的な関数の効率的な応用テクニックをいくつか紹介し、具体的なコード例を示します。
- データのロードとストレージ
データのロードとストレージは、データ分析の最初のステップです。 Pandas は、CSV、Excel、SQL などのさまざまな形式でデータを読み取り、保存するためのさまざまな関数を提供します。データのロードと保存の効率を向上させるために、次の手法を使用できます。
# 加载数据时,指定数据类型,减少内存占用
df = pd.read_csv('data.csv', dtype={'column1': 'int32', 'column2': 'float64'})
# 使用.to_csv()方法时,指定压缩格式,减小文件大小
df.to_csv('data.csv.gz', compression='gzip')- データのクリーニングと処理
データのクリーニングと処理は中心的な手順です。データ分析のこと。大規模なデータを処理する場合は、ループ反復の使用を避け、代わりに Pandas ライブラリが提供するベクトル化された操作を使用する必要があります。以下に、一般的で効率的なアプリケーションのヒントをいくつか示します。
# 使用.isin()方法,替代多个“or”条件的筛选操作
df_filtered = df[df['column'].isin(['value1', 'value2', 'value3'])]
# 使用.str.contains()方法,替代多个“or”条件的字符串匹配操作
df_match = df[df['column'].str.contains('keyword1|keyword2|keyword3')]- データの集計とグループ化の計算
データの集計とグループ化の計算は、一般的なデータ処理操作です。大規模なデータ セットに対して集計計算を実行する場合、次の手法を使用して効率を向上できます。
# 使用.groupby()方法,结合聚合函数一次性计算多个指标
df_grouped = df.groupby(['group_col'])['value_col'].agg(['sum', 'mean', 'max'])
# 使用transform()方法,一次性计算多个指标,并将结果作为新的一列添加到原数据框中
df['sum_col'] = df.groupby(['group_col'])['value_col'].transform('sum')- データの視覚化
データの視覚化はデータの重要な部分です。分析とプレゼンテーション。大規模なデータ チャートを描画する場合は、描画効率を向上させるために効率的な視覚化機能を使用することに注意を払う必要があります。
# 使用seaborn库提供的高级绘图函数,如sns.histplot()替代Pandas的.hist()方法 import seaborn as sns sns.histplot(df['column'], kde=True, bins=10)
- 並列コンピューティング
大規模なデータを処理する場合、並列コンピューティングを使用すると、マルチコア プロセッサのパフォーマンスを最大限に活用し、データ処理速度を向上できます。 Pandas ライブラリには、apply() メソッドや map() メソッドなど、並列コンピューティングをサポートする関数がいくつかあります。
import multiprocessing
# 定义并行计算函数
def parallel_func(row):
# 并行计算逻辑
# 使用multiprocessing库创建并行处理池
with multiprocessing.Pool() as pool:
# 使用apply()方法进行并行计算
df['new_column'] = pool.map(parallel_func, df['column'])要約すると、Pandas ライブラリの一般的な関数は、大規模なデータを処理するときにいくつかの効率的なアプリケーション手法に注意を払う必要があります。合理的なデータのロードと保存、ベクトル化処理、並列コンピューティング、効率的な視覚化機能の使用により、データ処理の効率が向上し、データ分析タスクを迅速に完了できます。この記事で紹介したテクニックが読者の実践に役立つことを願っています。
以上がpandas ライブラリでよく使用される関数の適用効率を向上させるヒントの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

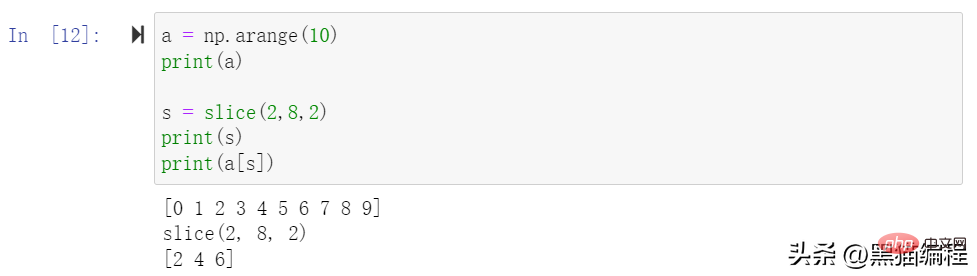 一文详解Python数据分析模块Numpy切片、索引和广播Apr 10, 2023 pm 02:56 PM
一文详解Python数据分析模块Numpy切片、索引和广播Apr 10, 2023 pm 02:56 PMNumpy切片和索引ndarray对象的内容可以通过索引或切片来访问和修改,与 Python 中 list 的切片操作一样。ndarray 数组可以基于 0 ~ n-1 的下标进行索引,切片对象可以通过内置的 slice 函数,并设置 start, stop 及 step 参数进行,从原数组中切割出一个新数组。切片还可以包括省略号 …,来使选择元组的长度与数组的维度相同。 如果在行位置使用省略号,它将返回包含行中元素的 ndarray。高级索引整数数组索引以下实例获取数组中 (0,0),(1,1
 如何利用 Go 语言进行数据分析和机器学习?Jun 10, 2023 am 09:21 AM
如何利用 Go 语言进行数据分析和机器学习?Jun 10, 2023 am 09:21 AM随着互联网技术的发展和大数据的普及,越来越多的公司和机构开始关注数据分析和机器学习。现在,有许多编程语言可以用于数据科学,其中Go语言也逐渐成为了一种不错的选择。虽然Go语言在数据科学上的应用不如Python和R那么广泛,但是它具有高效、并发和易于部署等特点,因此在某些场景中表现得非常出色。本文将介绍如何利用Go语言进行数据分析和机器学习
 数据挖掘和数据分析的区别是什么?Dec 07, 2020 pm 03:16 PM
数据挖掘和数据分析的区别是什么?Dec 07, 2020 pm 03:16 PM区别:1、“数据分析”得出的结论是人的智力活动结果,而“数据挖掘”得出的结论是机器从学习集【或训练集、样本集】发现的知识规则;2、“数据分析”不能建立数学模型,需要人工建模,而“数据挖掘”直接完成了数学建模。
 Python中的机器学习是什么?Jun 04, 2023 am 08:52 AM
Python中的机器学习是什么?Jun 04, 2023 am 08:52 AM近年来,机器学习(MachineLearning)成为了IT行业中最热门的话题之一,Python作为一种高效的编程语言,已经成为了许多机器学习实践者的首选。本文将会介绍Python中机器学习的概念、应用和实现。一、机器学习概念机器学习是一种让机器通过对数据的分析、学习和优化,自动改进性能的技术。其主要目的是让机器能够在数据中发现存在的规律,从而获得对未来
 Python量化交易实战:获取股票数据并做分析处理Apr 15, 2023 pm 09:13 PM
Python量化交易实战:获取股票数据并做分析处理Apr 15, 2023 pm 09:13 PM量化交易(也称自动化交易)是一种应用数学模型帮助投资者进行判断,并且根据计算机程序发送的指令进行交易的投资方式,它极大地减少了投资者情绪波动的影响。量化交易的主要优势如下:快速检测客观、理性自动化量化交易的核心是筛选策略,策略也是依靠数学或物理模型来创造,把数学语言变成计算机语言。量化交易的流程是从数据的获取到数据的分析、处理。数据获取数据分析工作的第一步就是获取数据,也就是数据采集。获取数据的方式有很多,一般来讲,数据来源主要分为两大类:外部来源(外部购买、网络爬取、免费开源数据等)和内部来源
 MySQL中的大数据分析技巧Jun 14, 2023 pm 09:53 PM
MySQL中的大数据分析技巧Jun 14, 2023 pm 09:53 PM随着大数据时代的到来,越来越多的企业和组织开始利用大数据分析来帮助自己更好地了解其所面对的市场和客户,以便更好地制定商业策略和决策。而在大数据分析中,MySQL数据库也是经常被使用的一种工具。本文将介绍MySQL中的大数据分析技巧,为大家提供参考。一、使用索引进行查询优化索引是MySQL中进行查询优化的重要手段之一。当我们对某个列创建了索引后,MySQL就可
 为何军事人工智能初创公司近年来备受追捧Apr 13, 2023 pm 01:34 PM
为何军事人工智能初创公司近年来备受追捧Apr 13, 2023 pm 01:34 PM俄乌冲突爆发 2 周后,数据分析公司 Palantir 的首席执行官亚历山大·卡普 (Alexander Karp) 向欧洲领导人提出了一项建议。在公开信中,他表示欧洲人应该在硅谷的帮助下实现武器现代化。Karp 写道,为了让欧洲“保持足够强大以战胜外国占领的威胁”,各国需要拥抱“技术与国家之间的关系,以及寻求摆脱根深蒂固的承包商控制的破坏性公司与联邦政府部门之间的资金关系”。而军队已经开始响应这项号召。北约于 6 月 30 日宣布,它正在创建一个 10 亿美元的创新基金,将投资于早期创业公司和
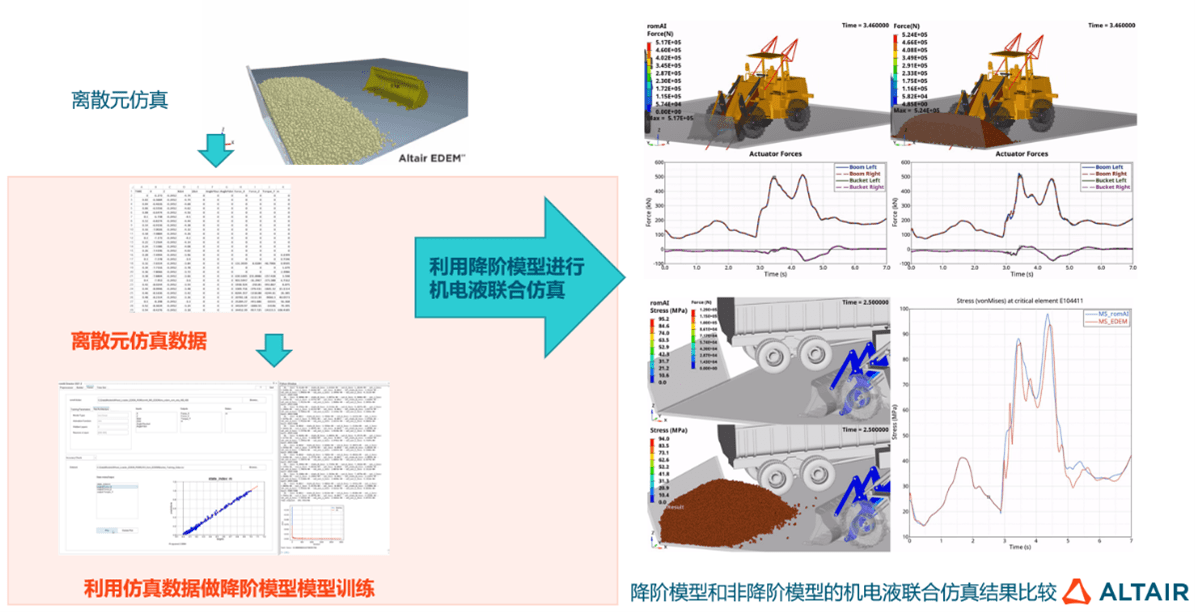 AI牵引工业软件新升级,数据分析与人工智能在探索中进化Jun 05, 2023 pm 04:04 PM
AI牵引工业软件新升级,数据分析与人工智能在探索中进化Jun 05, 2023 pm 04:04 PMCAE和AI技术双融合已成为企业研发设计环节数字化转型的重要应用趋势,但企业数字化转型绝不仅是单个环节的优化,而是全流程、全生命周期的转型升级,数据驱动只有作用于各业务环节,才能真正助力企业持续发展。数字化浪潮席卷全球,作为数字经济核心驱动,数字技术逐步成为企业发展新动能,助推企业核心竞争力进化,在此背景下,数字化转型已成为所有企业的必选项和持续发展的前提,拥抱数字经济成为企业的共同选择。但从实际情况来看,面向C端的产业如零售电商、金融等领域在数字化方面走在前列,而以制造业、能源重工等为代表的传


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)

DVWA
Damn Vulnerable Web App (DVWA) は、非常に脆弱な PHP/MySQL Web アプリケーションです。その主な目的は、セキュリティ専門家が法的環境でスキルとツールをテストするのに役立ち、Web 開発者が Web アプリケーションを保護するプロセスをより深く理解できるようにし、教師/生徒が教室環境で Web アプリケーションを教え/学習できるようにすることです。安全。 DVWA の目標は、シンプルでわかりやすいインターフェイスを通じて、さまざまな難易度で最も一般的な Web 脆弱性のいくつかを実践することです。このソフトウェアは、

SecLists
SecLists は、セキュリティ テスターの究極の相棒です。これは、セキュリティ評価中に頻繁に使用されるさまざまな種類のリストを 1 か所にまとめたものです。 SecLists は、セキュリティ テスターが必要とする可能性のあるすべてのリストを便利に提供することで、セキュリティ テストをより効率的かつ生産的にするのに役立ちます。リストの種類には、ユーザー名、パスワード、URL、ファジング ペイロード、機密データ パターン、Web シェルなどが含まれます。テスターはこのリポジトリを新しいテスト マシンにプルするだけで、必要なあらゆる種類のリストにアクセスできるようになります。

AtomエディタMac版ダウンロード
最も人気のあるオープンソースエディター

ZendStudio 13.5.1 Mac
強力な PHP 統合開発環境

