
ホームページ >テクノロジー周辺機器 >AI >Yi-VL 大型モデルはオープンソースであり、MMMU および CMMMU で 1 位にランクされています
Yi-VL 大型モデルはオープンソースであり、MMMU および CMMMU で 1 位にランクされています

- WBOY転載
- 2024-01-22 21:30:21421ブラウズ
- https://huggingface.co/01-ai
- https://www.modelscope.cn/organization/01ai
#画像とテキストの優れた理解と対話生成Yi-VL モデルは、英語のデータセット MMMU と中国語のデータセット CMMMU で優れた結果を達成しており、複雑な学際的なタスクにおいてその強力な強みを実証しています。
MMMU (正式名称 Massive Multi-discipline Multi-modal Understanding & Reasoning) データ セットには、分野 (アート & デザイン、ビジネス、科学、健康と医学、人文科学と社会科学、技術と工学など) には、非常に異質な画像タイプと絡み合ったテキストと画像情報が含まれており、モデルの高度な認識能力と推論能力に非常に高い要求が課せられます。このテスト セットでは、
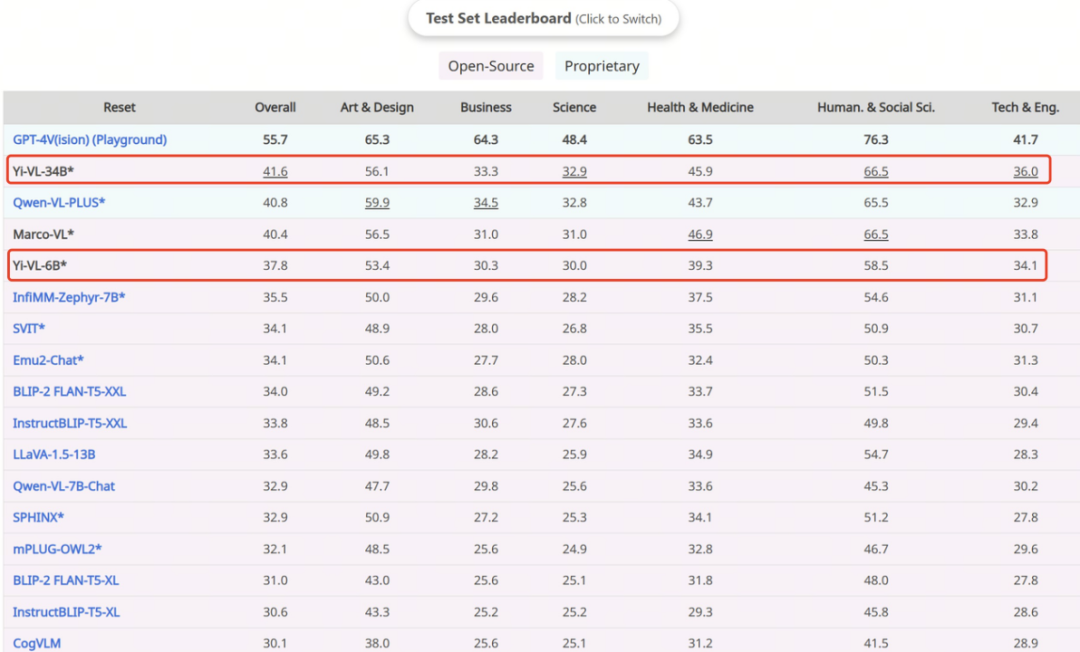
GPT-4V はこのテスト セットで 43.7% の精度を示し、Yi-VL-34B が 36.5%

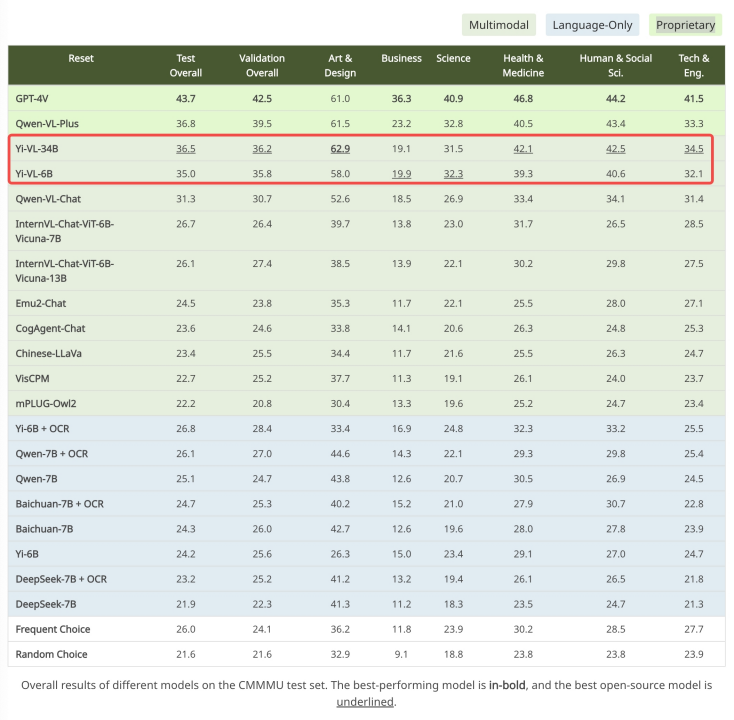 出典: https://cmmmu-benchmark.github.io/
出典: https://cmmmu-benchmark.github.io/
 ご覧のとおり, Yi 言語モデルの強力なテキスト理解機能に基づいて、画像を並べるだけで優れたマルチモーダルなビジュアル言語モデルを取得できます。これは、Yi-VL モデルの中核となるハイライトの 1 つでもあります。
ご覧のとおり, Yi 言語モデルの強力なテキスト理解機能に基づいて、画像を並べるだけで優れたマルチモーダルなビジュアル言語モデルを取得できます。これは、Yi-VL モデルの中核となるハイライトの 1 つでもあります。

- Vision Transformer (略して ViT) は、オープン ソースの OpenClip ViT-H を使用した画像エンコードに使用されます。 /14 モデルを使用してトレーニング可能なパラメーターを初期化します。大規模な「画像とテキスト」のペアから特徴を抽出する方法を学習することで、モデルは画像を処理して理解する能力を備えています。
- 投影モジュールは、画像特徴をテキスト特徴と空間的に位置合わせする機能をモデルにもたらします。このモジュールは、層正規化を含む多層パーセプトロン (MLP) で構成されます。この設計により、モデルが視覚情報とテキスト情報をより効果的に融合して処理できるようになり、マルチモーダルの理解と生成の精度が向上します。
- Yi-34B-Chat および Yi-6B-Chat 大規模言語モデルの導入により、Yi-VL に強力な言語理解および生成機能が提供されます。モデルのこの部分では、高度な自然言語処理テクノロジーを使用して、Yi-VL が複雑な言語構造を深く理解し、一貫した関連性のあるテキスト出力を生成できるようにします。
- 第一段階: Zero One Wish は、1 億個の「画像とテキスト」のペアのデータセットを使用して、ViT モジュールと投影モジュールをトレーニングします。この段階では、大規模な言語モデルとの効率的な調整を可能にしながら、特定のアーキテクチャにおける ViT の知識獲得機能を強化するために、画像解像度は 224x224 に設定されています。
- 第 2 段階: Zero One Thing により、ViT の画像解像度が 448x448 に増加します。この改善により、モデルは複雑な視覚的詳細をよりよく認識できるようになります。この段階では、約 2,500 万の画像とテキストのペアが使用されます。
- 第 3 段階: Zero One Wish は、マルチモーダル チャット インタラクションにおけるモデルのパフォーマンスを向上させることを目的として、トレーニング用にモデル全体のパラメーターを開きます。トレーニング データは、合計約 100 万の「画像とテキスト」のペアを含むさまざまなデータ ソースをカバーし、データの幅とバランスを確保しています。
ゼロワン シングスの技術チームは、強力な言語理解と生成機能に基づいて、他のマルチモーダル トレーニングを使用できることも検証しました。 BLIP、Flamingo、EVA などのメソッドは、効率的な画像理解とスムーズなグラフィックとテキストの対話を実行できるマルチモーダル グラフィックおよびテキスト モデルを迅速にトレーニングできます。 Yi シリーズ モデルはマルチモーダル モデルの基本言語モデルとして使用でき、オープン ソース コミュニティに新しいオプションを提供します。
現在、Yi-VLモデルはHugging FaceやModelScopeなどのプラットフォームで公開されており、ユーザーはこのモデルの多面的な機能をグラフィックを通じて体験することができます。次のリンクからテキスト ダイアログを利用できます。シーンでの優れたパフォーマンス。 Yi-VL マルチモーダル言語モデルの強力な機能を探索し、最先端の AI テクノロジーの成果を体験してください。
以上がYi-VL 大型モデルはオープンソースであり、MMMU および CMMMU で 1 位にランクされていますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
声明:
この記事はjiqizhixin.comで複製されています。侵害がある場合は、admin@php.cn までご連絡ください。