
ホームページ >テクノロジー周辺機器 >AI >ICLR'24 写真なしの新しいアイデア! LaneSegNet: 車線セグメンテーション認識に基づく地図学習
ICLR'24 写真なしの新しいアイデア! LaneSegNet: 車線セグメンテーション認識に基づく地図学習

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2024-01-19 11:12:151156ブラウズ
前に書いてあり、著者の個人的な理解
地図は自動運転システムの下流アプリケーションにとって重要な情報であり、通常は車線または中央線で表されます。ただし、既存の地図学習の文献は主に、車線の幾何学ベースのトポロジー関係の検出や中心線の感知に焦点を当てています。どちらの方法も、車線と中心線の間の固有の関係、つまり、車線が中心線を結合する関係を無視します。 1 つのモデルで 2 種類の車線を単純に予測することは学習目標において相互に排他的ですが、本論文では幾何学的情報と位相情報をシームレスに組み合わせる新しい表現として車線セグメンテーションを提案し、LaneSegNet を提案します。これは、車線セグメントを生成して道路構造の完全な表現を取得する最初のエンドツーエンド マッピング ネットワークです。 LaneSegNet には 2 つの重要な変更があり、1 つはレーン アテンション モジュールで、長距離特徴空間内の主要エリアの詳細をキャプチャするために使用されます。もう 1 つは、参照点の同じ初期化戦略で、レーン アテンションのための位置事前分布の学習を強化します。 OpenLane-V2 データセットでは、LaneSegNet は、マップ要素検出 (4.8 mAP)、車線中心線認識 (6.9 DETl)、および新しく定義された車線セグメント認識 (5.6 mAP) という 3 つのタスクにおいて、以前の同様の製品に比べて大きな利点があります。さらに、14.7FPSのリアルタイム推論速度を実現しました。
オープンソースリンク: https://github.com/OpenDriveLab/LaneSegNet
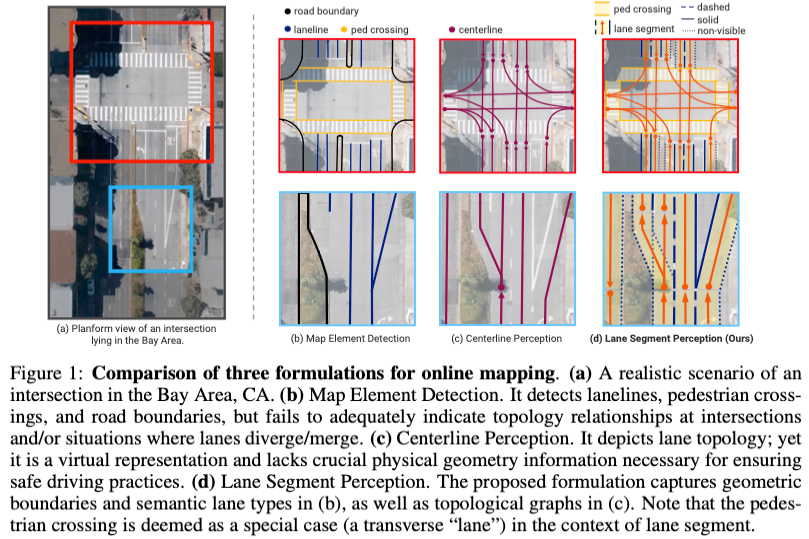
要約すると、この記事の主な貢献は次のとおりです:
- この記事では、新しい地図学習公式として、新しい車線セグメント認識を紹介します。幾何学的な要素と位相的な要素が含まれています。この分野に新たな洞察がもたらされることを期待しています。
- この記事では、車線セグメント認識のために提案されたエンドツーエンド ネットワークである LaneSegNet について提案します。長距離の注意を捕捉するための頭から領域へのメカニズムを備えた車線注意モジュールと、車線の注意に先立って位置を強化するための参照点の同じ初期化戦略を含む、2 つの新しい修正が提案されています。
関連研究のレビュー
中心線の知覚: 車載センサー データからの中心線の知覚 (この記事の車線マップ学習との比較)同紙)が最近注目を集めている。 STSU は、中心線を検出する DETR のようなネットワークを提案し、その後、その接続性を判断するために多層パーセプトロン (MLP) モジュールを提案しました。 STSU に基づいて、Can らは、重複する行の正しい順序を保証する追加の最小ループ クエリを導入しました。 CenterLineDet は中心線を頂点として扱い、模倣学習を通じて訓練されたグラフ更新モデルを設計します。注目すべきは、テスラがレーンマップを文章として表現する「レーン言語」という概念を提案したことだ。彼らの注意ベースのモデルは、車線区分線とその接続性を再帰的に予測します。これらのセグメンテーション方法に加えて、LaneGAP では、追加の変換アルゴリズムを使用してレーン マップを復元するパス方法も導入されています。 TopoNet は、完全かつ多様な運転シーンのグラフを対象とし、ネットワーク内の中心線の接続性を明示的にモデル化し、交通要素をタスクに組み込みます。本研究ではセグメント法を採用してレーングラフを構築します。ただし、中心線をレーン グラフの頂点とするのではなく、レーン セグメントをモデリングする点で以前の方法とは異なります。これにより、セグメント レベルの幾何学的情報と意味情報を簡単に統合できます。
マップ要素の検出: 以前の研究では、投影エラーを克服するために、カメラ平面から 3D 空間までのマップ要素の検出を改善することに焦点を当てていました。 BEV センシングの人気の傾向に伴い、最近の研究はセグメンテーションおよびベクトル化手法を使用した HD マップの学習に焦点を当てています。マップのセグメンテーションは、車線、横断歩道、走行可能エリアなど、純粋な BEV グリッドのセマンティクスを予測します。これらの作品は主にパースペクティブ ビュー (PV) から BEV への変換モジュールが異なります。ただし、セグメント化されたマップは、下流モジュールで使用される直接情報を提供できません。 HDMapNet は、複雑な後処理を使用してセグメンテーション マップをグループ化およびベクトル化することで、この問題に対処します。
高密度セグメンテーションはピクセルレベルの情報を提供しますが、重なり合う要素の複雑な関係にはまだ触れられません。 VectorMapNet は、車線の位置を順番にデコードするために粗いキーポイントを使用して、各マップ要素を点のシーケンスとして直接表現することを提案しています。 MapTR は、モデリングの曖昧さを排除し、パフォーマンスと効率を向上させるために、統一された順列ベースの点列モデリング アプローチを検討します。 PivotNet は、アンサンブル予測フレームワークでピボットベースの表現を使用してマップ要素をさらにモデル化し、冗長性を削減し、精度を向上させます。 StreamMapNet は、マルチポイント アテンションと時間情報を利用して、リモート マップ要素検出の安定性を向上させます。実際、ベクトル化によって車線の方向情報も強化されるため、ベクトル化ベースの方法は、交互の監視を通じて中心線の認識に簡単に適応できます。この研究では、道路上のすべての HD マップ要素に対して、統一された学習しやすい表現 (車線セグメンテーション) を提案します。
LaneSegNet の詳細な説明
車線セグメント認識タスクの説明
車線セグメントのインスタンスには、道路の幾何学的側面と意味論的な側面が含まれています。ジオメトリに関しては、ベクトル化された中心線とそれに対応する車線境界から構成される線分として表すことができます。各ラインは、3D 空間内の順序付けられた点の集合として定義されます。あるいは、ジオメトリは、その車線内の運転可能エリアを定義する閉じた多角形として記述することもできます。
セマンティクスの観点からは、車線セグメント カテゴリ C (例: 車線セグメント、横断歩道) と左右の車線境界線のスタイル (例: 非表示、実線、破線) が含まれます。{} 。これらの詳細は、自動運転車に減速要件と車線変更の実現可能性に関する重要な洞察を提供します。
さらに、トポロジ情報はパス計画において重要な役割を果たします。この情報を表すために、車線セグメントに対して車線グラフが構築され、G = (V, E) として表されます。各車線セグメントは、集合 V で表されるグラフ内のノードであり、集合 E のエッジは車線セグメント間の接続を表します。このレーン グラフを保存するには隣接行列を使用します。行列要素 (i, j) は、j 番目のレーン セグメントが i 番目のレーン セグメントに続く場合にのみ 1 に設定され、それ以外の場合は 0 のままです。
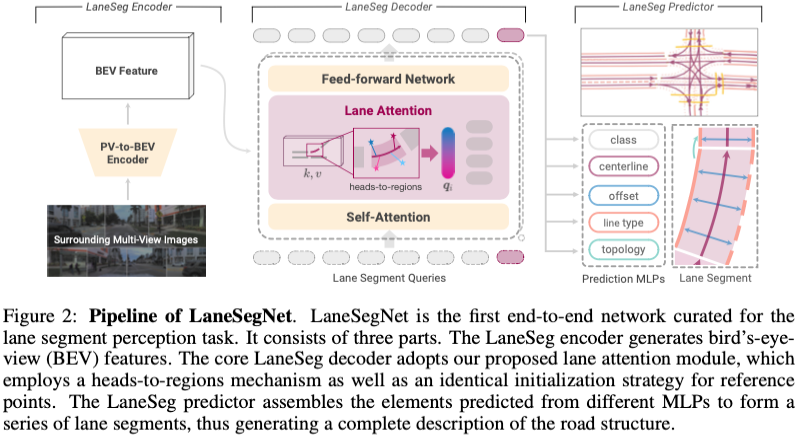
LaneSegNet フレームワーク
LaneSegNet の全体的なフレームワークを図 2 に示します。 LaneSegNet は、特定の BEV 範囲内の車線セグメントを認識するためにサラウンド画像を入力として受け取ります。このセクションでは、最初に、BEV 特徴を生成するために使用される LaneSeg エンコーダーを簡単に紹介します。次に、レーン セグメンテーション デコーダーとレーン アテンションを導入します。最後に、トレーニング損失とともにレーン セグメンテーション予測子を提案します。
車線セグメント エンコーダ
エンコーダは、車線セグメント抽出のためにサラウンド画像を BEV 特徴に変換します。標準の ResNet-50 バックボーンを利用して、生の画像から特徴マップを導き出します。次に、BEVFormer を使用した PV から BEV へのエンコーダ モジュールがビュー変換に使用されます。
LaneSeg Decoder
トランスフォーマーベースの検出方法では、デコーダーを利用して BEV 特徴から特徴を収集し、複数のレイヤーを通じてデコーダー クエリを更新します。各デコーダ層は、セルフ アテンション、クロス アテンション メカニズム、およびフィードフォワード ネットワークを利用してクエリを更新します。さらに、学習可能な位置クエリが採用されています。更新されたクエリは出力され、次のステージに供給されます。
複雑で細長い地図の形状のため、オンライン マッピング タスクでは長距離の BEV 特徴を収集することが重要です。以前の研究では、階層 (インスタンス ポイント) デコーダ クエリと変形可能なアテンションを利用して、各ポイント クエリの局所特徴を抽出しました。このアプローチでは長距離の情報の取得は回避されますが、クエリの数が増加するため、計算コストが高くなります。
レーン セグメントは、シーン グラフを構築するためのレーン インスタンス表現として、インスタンス レベルで優れた特性を備えています。私たちの目標は、マルチポイント クエリを使用することではなく、単一インスタンス クエリを使用して車線セグメントを表すことです。したがって、中心的な課題は、単一インスタンスのクエリを使用してグローバル BEV 機能に集中する方法です。
レーン アテンション : ターゲット検出では、変形可能なアテンションはターゲットの前の位置を使用し、ターゲット参照点に近いアテンション値のごく一部にのみ焦点を当てます。フィルターを使用すると、収束が高速化され、大幅に改善されます。レイヤーの反復中、参照点は予測ターゲットの中心に配置され、アテンション値のサンプリング位置が調整されます。アテンション値は、学習可能なサンプリング オフセットを介して参照点の周囲に分散されます。サンプル オフセットの意図的な初期化には、2D ターゲットに先行するジオメトリが含まれます。こうすることで、図 3a に示すように、多分岐機構は各方向の特性をうまく捉えることができます。
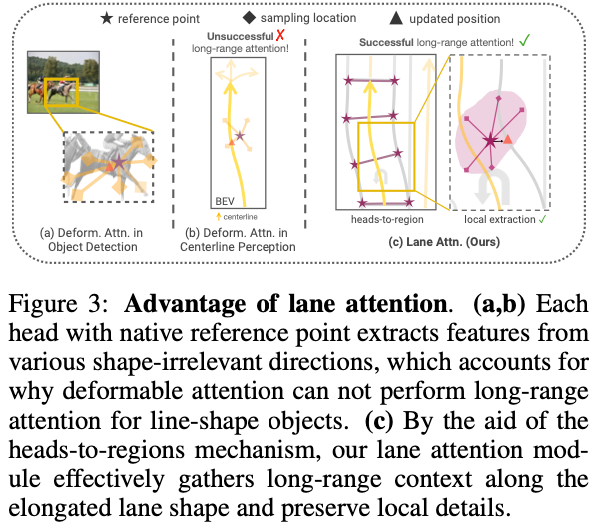
地図学習のコンテキストにおいて、Li らは単純な変形可能な注意を使用して中心線を予測しました。ただし、図 3b に示すように、基準点の配置が単純であるため、単一範囲の注意を獲得できない可能性があります。さらに、ターゲットの細長い形状と複雑な視覚的手がかり (実線と破線の間のブレークポイントを正確に予測するなど) のため、このプロセスではタスクに追加の適応設計が必要です。これらすべての特性を考慮すると、ネットワークには、長距離のコンテキスト情報に注意を払うだけでなく、ローカルの詳細を正確に抽出する機能が必要です。したがって、遠距離の情報を効果的に認識するには、サンプリング位置を広いエリアに分散させることが推奨されます。一方、重要なポイントを特定するには、局所的な詳細を簡単に区別できる必要があります。単一のアテンション ヘッド内の値特徴間には競合関係がありますが、異なるヘッド間の値特徴はアテンション プロセス中に保持される可能性があることは注目に値します。したがって、この特性を明示的に利用して、特定の地域の局所的な特徴への注目を促進することが期待されます。
この目的のために、この記事ではヘッドから地域へのメカニズムを確立することを提案します。まず、車線セグメント エリア内に複数の参照ポイントを均等に配置します。次に、サンプリング位置がローカル エリア内の各参照点の周囲で初期化されます。複雑な局所的な詳細を保存するために、図 3c に示すように、各ヘッドが局所領域内の特定のサンプリング位置セットに焦点を当てるマルチブランチ メカニズムを使用します。
車線注意モジュールの数学的説明が提供されます。 BEV 特徴、i 番目のレーン セグメント クエリ特徴 qi、および入力としての参照点 pi のセットを指定すると、レーン アテンションは次のように計算されます。
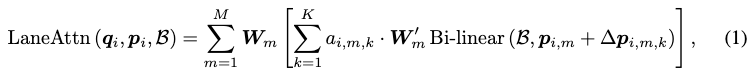
同じ初期化参照ポイント: Ref. ポイントの位置は、車線注意モジュールの機能を決定する要素です。各インスタンス クエリの対象領域を実際のジオメトリおよび位置に合わせるために、図 3c に示すように、各インスタンス クエリの参照点 p は前のレイヤーの車線セグメント予測に基づいて分散されます。そして繰り返し予測を改良します。
以前の研究では、最初の層に提供される参照ポイントは、位置クエリの埋め込みから導出された学習可能な事前確率で個別に初期化されるべきであると主張しました。ただし、位置クエリは入力画像から独立しているため、この初期化方法では、幾何学的な事前分布と位置事前分布を記憶するモデルの能力が制限される可能性があり、誤って生成された初期化位置がトレーニングに障害を引き起こす可能性もあります。
したがって、レーン セグメント デコーダーの最初の層に対して、同じ初期化戦略を提案します。最初の層では、各ヘッドは位置クエリによって生成された同じ参照点を取得します。従来の方法での参照点の分散初期化 (クエリごとに複数の参照点を初期化する) と比較して、同じ初期化により、複雑なジオメトリの干渉が除去されるため、位置事前分布の学習がより安定します。同じ初期化は直観に反しているように見えるかもしれませんが、動作することが観察されていることに注意してください。
レーンセグメント予測器
複数の予測ブランチで MLP を使用して、幾何学的、意味論的、およびトポロジー的な側面を考慮して、レーン セグメント クエリから最終的な予測レーン セグメントを生成します。 。
ジオメトリについては、まず、3 次元座標における中心線のベクトル化された点の位置を回帰する中心線回帰ブランチを設計しました。出力形式は次のとおりです。左右の車線境界が対称であるため、オフセットを予測するためにオフセット分岐を導入します。その形式は次のとおりです。したがって、左右の車線境界座標は次のように計算できます。
車線セグメントが走行可能なエリアとして概念化できると仮定して、インスタンス セグメンテーション ブランチを予測子に統合します。セマンティクスの観点からは、3 つの分類ブランチが C の分類スコアと C のスコアを並行して予測します。トポロジカル ブランチは、更新されたクエリ特徴を入力として受け取り、MLP を使用してレーン グラフ G の重み付き隣接行列を出力します。
トレーニング損失
LaneSegNet は DETR のようなパラダイムを採用し、ハンガリーのアルゴリズムを使用して予測とグラウンド トゥルース間の 1 対 1 の最適な割り当てを効率的に計算します。次に、分布結果に基づいてトレーニング損失が計算されます。損失関数は、幾何学的損失、分類損失、車線分類損失、トポロジカル損失の 4 つの部分で構成されます。
幾何学的損失は、予測された各車線セグメントの幾何学的構造を監視します。バイナリ マッチングの結果に従って、GT レーン セグメントが予測されたベクトル化された各レーン セグメントに割り当てられます。ベクトル化された幾何学的損失は、割り当てられた車線セグメントのペア間で計算されたマンハッタン距離として定義されます。
実験結果
主な実験構造
車線セグメントの認識: 表 1 では、新しく導入されたレーン セグメント対応ベンチマークで、LaneSegNet をいくつかの最先端のメソッド MapTR、MapTRv2、TopoNet と比較します。車線セグメント ラベルを使用してモデルを再トレーニングします。 LaneSegNet は、mAP において他の方法よりも最大 9.6% 優れたパフォーマンスを発揮し、平均距離誤差は相対的に 12.5% 減少します。 LaneSegNet-mini は、16.2 という高い FPS で以前の方法よりも優れたパフォーマンスを発揮します。

定性的な結果を図 4 に示します。

マップ要素の検出: 順序より公平な比較を行うために、LaneSegNet の予測車線セグメントを車線のペアに分解し、地図要素検出メトリクスを使用した最先端の方法と比較します。私たちは、分解された車線と横断歩道のラベルをいくつかの最先端の方法に入力して再トレーニングします。実験結果を表 2 に示します。これは、LaneSegNet がマップ要素検出タスクにおいて常に他の方法よりも優れていることを示しています。公平に比較すると、LaneSegNet は追加の監視により道路形状をより適切に復元します。これは、車線セグメント学習表現が道路の幾何学的情報の捕捉に優れていることを示しています。
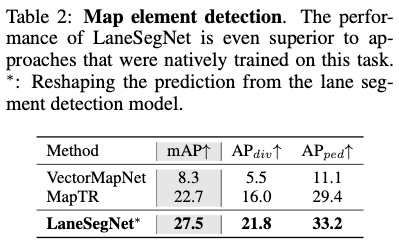
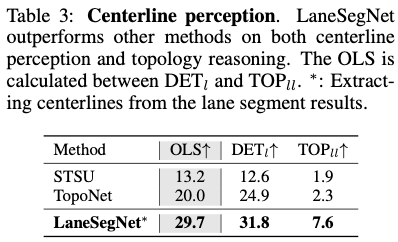
中心線認識: 表 3 では、LaneSegNet と最先端の中心線認識方法も比較しています。一貫性を保つために、再トレーニングのために中心線も車線セグメントから抽出されます。車線マップ認識タスクにおける LaneSegNet のパフォーマンスは、他の方法よりも大幅に高いと結論付けることができます。追加の地理的監視により、LaneSegNet は優れたトポロジ推論機能も実証します。推論能力は、強力な測位能力と検出能力に密接に関係していることが証明されています。
アブレーション実験
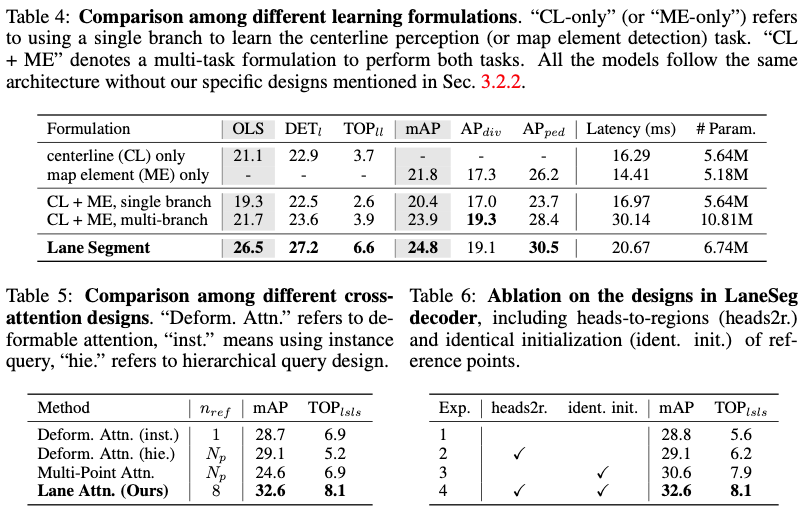
レーン セグメント式: 表 4 では、提案したレーン セグメント学習式設計の利点を検証するためにアブレーションを提供します。そしてトレーニングの効率化。最初の 2 行で個別にトレーニングされたモデルと比較して、中心線とマップ要素の共同トレーニングでは、行 4 に示すように 2 つの主要な指標で全体の平均 1.3 の改善がもたらされ、マルチタスク トレーニングの実現可能性が示されています。ただし、カテゴリを追加して単一のブランチで中心線とマップ要素をトレーニングする一般的なアプローチでは、パフォーマンスが大幅に低下します。上記の単純な単一分岐方法と比較して、車線セグメント ラベルを使用してトレーニングされたモデルは大幅なパフォーマンスの向上 (行 3 と行 5 の間の比較では、OLS で 7.2、mAP で 4.4) が得られ、マップ内のさまざまな道路情報間の正の相互作用が検証されます。学習定式化が実証されています。私たちのモデルは、特に中心線の認識(OLS 4.8)において、マルチブランチ手法よりも優れています。これは、マップ学習定式化において幾何学がトポロジカル推論を導くことができることを示しており、マルチブランチ モデルが CL のみのモデル (行 1 と 4 の間で 0.6 OLS) をわずかに上回るだけです。わずかな減少に関しては、これは予測結果の再形成プロセスから来ており、ライン分類のエラーによって引き起こされます。フォースモジュールアブレーションを表 5 に示します。公平な比較を容易にするために、フレームワーク内のレーン アテンション モジュールを別のアテンション デザインに置き換えます。慎重な設計により、レーン アテンションを備えた LaneSegNet はこれらの方法を大幅に上回り、大幅な改善を示しました (行 1 と比較して、mAP は 3.9 改善、TOPll は 1.2 改善)。さらに、階層クエリ設計と比較してクエリ数が減少するため、デコーダの遅延をさらに短縮できます (23.45 ミリ秒から 20.96 ミリ秒)。
 結論
結論
制限と今後の課題
。計算上の制限のため、提案されている LaneSegNet をさらに追加のバックボーンに拡張することはしません。レーン セグメント認識と LaneSegNet の定式化は、下流のタスクに利益をもたらす可能性があり、将来的に検討する価値があります。以上がICLR'24 写真なしの新しいアイデア! LaneSegNet: 車線セグメンテーション認識に基づく地図学習の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。