
ホームページ >テクノロジー周辺機器 >AI >Ant Group が大規模モデルの推論を 2 ~ 6 倍高速化できる新しいアルゴリズムをリリース
Ant Group が大規模モデルの推論を 2 ~ 6 倍高速化できる新しいアルゴリズムをリリース

- 王林転載
- 2024-01-17 21:33:05921ブラウズ
最近、Ant Group は、大規模モデルの推論を 2 ~ 6 倍高速化するのに役立つ一連の新しいアルゴリズムをオープンソース化し、業界で注目を集めています。
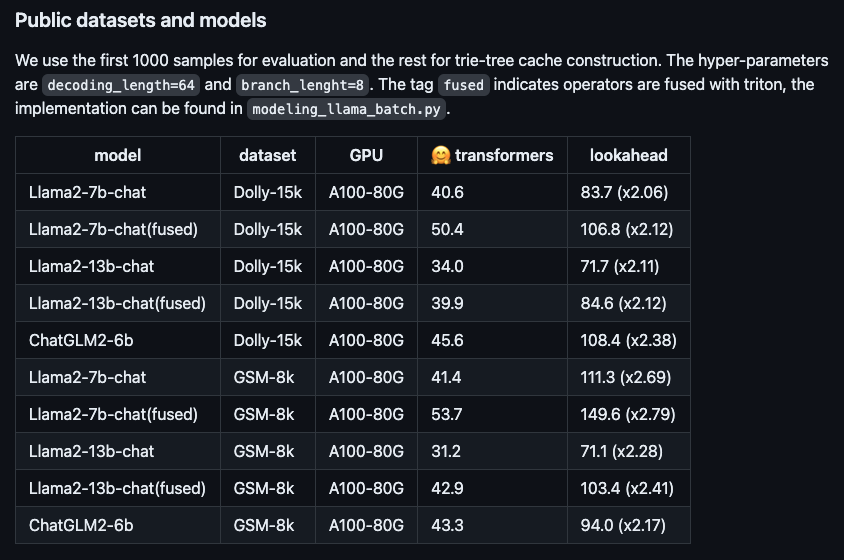
#図: さまざまなオープンソースの大規模モデルにおける新しいアルゴリズムのパフォーマンスの高速化。
この新しいアルゴリズムは Lookahead Inference Acceleration Framework と呼ばれ、ロスレス効果を実現でき、プラグアンドプレイです。このアルゴリズムは多数の ant シーンに実装されています。 、推論時間を大幅に短縮します。
Llama2-7BチャットモデルとDollyデータセットを例に実測を行ったところ、トークン生成速度が48.2/秒から112.9/秒と2.34倍に向上したことがわかりました。 Ant の内部 RAG (Retrieval Enhanced Generation) データ セットでは、Bailing 大型モデル AntGLM の 10B バージョンの加速率が 5.36 に達しました。同時に、ビデオ メモリとメモリ消費量の増加はほとんど無視できます。
現在の大規模モデルは通常、自己回帰デコードに基づいており、一度に 1 つのトークンしか生成しません。この方法では、GPU の並列処理能力が無駄になるだけでなく、ユーザー エクスペリエンスに過度の遅延が生じ、滑らかさに影響を及ぼします。この問題を改善するには、並列デコードを使用して複数のトークンを同時に生成し、効率とユーザー エクスペリエンスを向上させることができます。
たとえば、元のトークン生成プロセスは初期の中国語の入力方法と比較でき、ユーザーはテキストを入力するためにキーボードを単語ごとにタップする必要があります。ただし、Ant の高速化アルゴリズムを採用した後、トークン生成プロセスは最新の Lenovo 入力方式と同様になり、Lenovo 機能を通じて文全体を直接ポップアップできるようになりました。このような改善により、入力速度と効率が大幅に向上します。
いくつかの最適化アルゴリズムがこれまでに業界で登場しましたが、主に、より高品質のドラフトを生成する方法 (つまり、トークン シーケンスを推測して生成する方法) に焦点を当てていました。ただし、ドラフトの長さが 30 トークンを超えると、エンドツーエンドの推論の効率をさらに向上させることはできないことが実際に証明されています。明らかに、この長さでは GPU の計算能力が十分に活用されていません。
ハードウェアのパフォーマンスをさらに向上させるために、Ant Lookahead 推論高速化アルゴリズムはマルチブランチ戦略を採用しています。これは、ドラフト シーケンスにブランチが 1 つだけ含まれるのではなく、同時に検証できる複数の並列ブランチが含まれることを意味します。このようにして、転送プロセスの消費時間を基本的に変えずに、転送プロセスによって生成されるトークンの数を増やすことができます。
Ant Lookahead 推論高速化アルゴリズムは、トライ ツリーを使用してトークン シーケンスを保存および取得し、複数のドラフト内の同じ親ノードをマージすることにより、コンピューティング効率をさらに向上させます。使いやすさを向上させるために、このアルゴリズムのトライ ツリー構築は追加のドラフト モデルに依存せず、動的構築の推論プロセス中にプロンプトと生成された回答のみを使用するため、ユーザーのアクセス コストが削減されます。
このアルゴリズムは GitHub (https://www.php.cn/link/51200d29d1fc15f5a71c1dab4bb54f7c) でオープンソースになり、関連論文は ARXIV (https:/) で公開されています。 /www .php.cn/link/24a29a235c0678859695b10896513b3d)。
公開情報によると、アント グループは豊富なビジネス シナリオのニーズに基づいて人工知能への投資を継続しており、大規模モデル、ナレッジ グラフ、運用の最適化、グラフ学習、信頼できる AI などの技術分野を展開しています。 。
以上がAnt Group が大規模モデルの推論を 2 ~ 6 倍高速化できる新しいアルゴリズムをリリースの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。