



近年、大規模モデルの研究が加速しており、さまざまなタスクにおけるマルチモーダルな理解と時間的および空間的推論能力が徐々に実証されています。ロボットのさまざまな身体化された操作タスクには、言語コマンドの理解、シーンの認識、時空間プランニングに対する高い要求が当然ありますが、これは当然のことながら、「大型モデルの機能を最大限に活用してロボット工学の分野に移行できるか?」という疑問につながります。基礎となるアクションシーケンスを直接計画しますか?
ByteDance Research は、オープンソースのマルチモーダル言語ビジョン大規模モデル OpenFlamingo を使用して、スタンドアロン トレーニングのみを必要とする使いやすい RoboFlamingo ロボット操作モデルを開発しています。 VLM は、簡単な微調整によってロボット VLM に変えることができ、言語対話によるロボット操作タスクに適しています。
ロボット動作データセットCALVINについてOpenFlamingoにより検証済み。実験の結果、RoboFlamingo は言語アノテーションを含むデータのわずか 1% を使用し、一連のロボット操作タスクで SOTA パフォーマンスを達成することがわかりました。 RT-X データセットの公開により、オープンソース データで事前トレーニングされ、さまざまなロボット プラットフォームに合わせて微調整された RoboFlamingo は、シンプルで効果的な大規模ロボット モデル プロセスになることが期待されています。この論文では、さまざまな戦略ヘッド、さまざまなトレーニング パラダイム、およびロボット タスクにおけるさまざまな Flamingo 構造を使用して VLM の微調整パフォーマンスもテストし、いくつかの興味深い結論に達しました。

- プロジェクトのホームページ: https://roboflamingo.github.io
- コードアドレス: https://github.com/RoboFlamingo/RoboFlamingo
- ペーパーアドレス: https://arxiv.org/ abs /2311.01378
研究背景
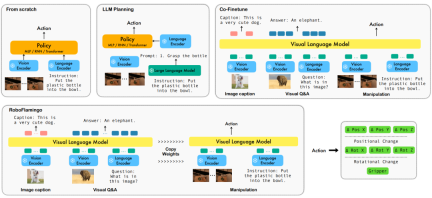
言語ベースのロボット操作は、視覚、言語、制御を含むマルチモーダル データの理解と処理を伴う、身体化知能の分野における重要なアプリケーションです。近年、ビジュアル言語ベース モデル (VLM) は、画像の説明、視覚的な質問応答、画像生成などの分野で大幅な進歩を遂げています。しかし、これらのモデルをロボットの動作に適用するには、視覚情報と言語情報をどのように統合するか、ロボット動作の時系列をどのように扱うかなどの課題がまだあります。これらの課題を解決するには、モデルのマルチモーダル表現機能の改善、より効果的なモデル融合メカニズムの設計、ロボット操作の逐次的な性質に適応するモデル構造とアルゴリズムの導入など、複数の側面での改善が必要です。さらに、これらのモデルをトレーニングおよび評価するための、より豊富なロボット工学データセットを開発する必要があります。継続的な研究と革新を通じて、言語ベースのロボット操作は実用化においてより大きな役割を果たし、よりインテリジェントで便利なサービスを人間に提供すると期待されています。
これらの問題を解決するために、ByteDance Research のロボティクス研究チームは、既存のオープンソース VLM (ビジュアル言語モデル) - OpenFlamingo を微調整し、と呼ばれる新しいビジュアル言語運用フレームワークを設計しました。ロボフラミンゴ。このフレームワークの特徴は、VLM を使用して単一ステップの視覚言語理解を実現し、追加のポリシー ヘッド モジュールを通じて履歴情報を処理することです。シンプルな微調整方法を通じて、RoboFlamingo を言語ベースのロボット操作タスクに適応させることができます。このフレームワークの導入により、現在のロボット運用における一連の課題が解決されることが期待されます。
RoboFlamingo は、言語ベースのロボット操作データセット CALVIN で検証されました。実験結果は、RoboFlamingo が言語注釈付きデータの 1% のみを利用していることを示しています。ロボット操作タスク SOTAの性能を達成(マルチタスク学習のタスクシーケンス成功率は66%、タスク平均完了数は4.09、ベースライン手法は38%、タスク平均完了数は3.06)。ゼロショット タスクの成功率は 24%、タスク完了の平均数は 2.48 (ベースライン メソッドは 1%、タスク完了の平均数は 0.67)、オープンを通じてリアルタイムの応答を実現できます。ループ制御を備えており、パフォーマンスの低いプラットフォームにも柔軟に導入できます。これらの結果は、RoboFlamingo が効果的なロボット操作方法であり、将来のロボット応用に有用な参考資料となる可能性があることを示しています。 ############方法###############
この作品では、画像とテキストのペアに基づく既存の視覚言語基本モデルを使用して、エンドツーエンドのトレーニングを通じてロボットの各ステップの相対的な動作を生成します。このモデルは、ビジョン エンコーダー、機能融合デコーダー、ポリシー ヘッドの 3 つの主要モジュールで構成されます。 Vision エンコーダ モジュールでは、現在の視覚的観察がまず ViT に入力され、次に ViT によって出力されたトークンがリサンプラーを通じてダウン サンプリングされます。このステップはモデルの入力次元を削減するのに役立ち、それによってトレーニング効率が向上します。 機能融合デコーダー モジュールはテキスト トークンを入力として受け取り、クロス アテンション メカニズムを通じてビジュアル エンコーダーの出力をクエリとして使用し、ビジュアル機能と言語機能の融合を実現します。各層で、特徴融合デコーダは最初にクロスアテンション動作を実行し、次にセルフアテンション動作を実行します。これらの操作は、言語と視覚的特徴の間の相関関係を抽出して、ロボットのアクションをより適切に生成するのに役立ちます。 フィーチャー フュージョン デコーダーによって出力された現在および過去のトークン シーケンスに基づいて、ポリシー ヘッドは、6 次元のロボット アームのエンド ポーズと 1 次元のグリッパーの開閉を含む、現在の 7 自由度の相対アクションを直接出力します。最後に、機能融合デコーダーで最大プーリングを実行し、それをポリシー ヘッドに送信して、相対アクションを生成します。 このようにして、私たちのモデルは視覚情報と言語情報を効果的に融合して、正確なロボットの動きを生成することができます。ロボット制御や自律航行などの分野で幅広い応用が期待されています。
トレーニング プロセス中、RoboFlamingo は事前トレーニングされた ViT、LLM、およびクロス アテンション パラメーターを利用し、リサンプラー、クロス アテンション、およびポリシー ヘッドのパラメーターのみを微調整します。
実験結果
データセット:

CALVIN (Composing Actions from Language and Vision) は、言語ベースの長期的な操作タスクを学習するためのオープンソース シミュレーション ベンチマークです。既存の視覚言語タスク データセットと比較して、CALVIN のタスクはシーケンスの長さ、アクション スペース、言語の点でより複雑であり、センサー入力の柔軟な仕様をサポートしています。 CALVIN は 4 つの分割 ABCD に分割されており、各分割は異なるコンテキストとレイアウトに対応しています。
定量分析:
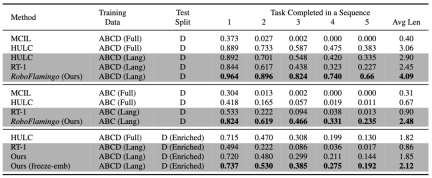
RoboFlamingo は、あらゆる設定とインジケーターで最高のパフォーマンスを示しています。強い模倣能力、視覚的一般化能力、言語一般化能力を持っています。 Full と Lang は、ペアになっていないビジュアル データ (つまり、言語ペアのないビジュアル データ) を使用してモデルがトレーニングされたかどうかを示します。Freeze-emb は、融合デコーダーの埋め込み層をフリーズすることを指します。Enriched は、GPT-4 拡張命令を使用することを示します。
アブレーション実験:
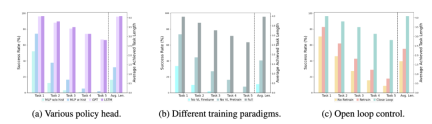
##さまざまなポリシー責任者:
実験では、4 つの異なるポリシー ヘッド (履歴なしの MLP、履歴ありの MLP、GPT、および LSTM) を調べました。このうち、履歴を持たない MLP は、現在の観測に基づいて履歴を直接予測し、そのパフォーマンスは最悪ですが、ビジョン エンコーダ側で履歴観測を融合し、行動を予測する MLP は、パフォーマンスが向上します。GPT と LSTM が明示されています。ポリシーヘッドで履歴情報を暗黙的に保持しており、そのパフォーマンスは最高であり、ポリシーヘッドによる履歴情報融合の有効性を示しています。
ビジュアル言語の事前トレーニングの影響:
事前トレーニングは、RoboFlamingo のパフォーマンスを向上させる上で重要な役割を果たします。実験では、大規模な視覚言語データセットで事前トレーニングすることにより、RoboFlamingo がロボットタスクでより優れたパフォーマンスを発揮することが示されました。
モデルのサイズとパフォーマンス:
一般的にモデルが大きいほどパフォーマンスが向上しますが、実験結果では、より小さなモデルでもより大きなモデルと競合できることが示されています。いくつかのタスクのモデルを作成します。
命令の微調整の影響:
命令の微調整は強力な手法であり、実験結果により、命令の微調整によりさらに改善できることが示されています。モデルのパフォーマンス。
定性的結果
ベースライン方法と比較すると、RoboFlamingo は 5 つの連続したサブタスクを完全に実行しただけでなく、ベースライン ページの最初の 2 つのサブタスクも正常に実行しました。手順が大幅に少なくなります。

概要
この作品は、言語対話のための新しい現実ベースのロボット操作戦略を提供します。は、簡単な微調整で優れた結果を達成できるオープンソースの VLM フレームワークです。 RoboFlamingo は、オープンソース VLM の可能性をより簡単に実現できる強力なオープンソース フレームワークをロボット研究者に提供します。この研究で得られた豊富な実験結果は、ロボット工学の実用化に貴重な経験やデータを提供し、将来の研究や技術開発に貢献する可能性があります。
以上がオープンソース VLM の可能性は RoboFlamingo フレームワークによって解き放たれますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 SQLのconcatとは何ですか? - 分析VidhyaApr 18, 2025 am 09:10 AM
SQLのconcatとは何ですか? - 分析VidhyaApr 18, 2025 am 09:10 AMSQLのconcat関数:文字列連結の包括的なガイド 構造化されたクエリ言語(SQL)concat関数は、2つ以上の文字列を単一の統合された文字列に結合するための頼りになるツールです。これは、データのフォーマットとMAにとって非常に貴重です
 2025年にフォローするトップ13のインドのgenaiリーダーApr 18, 2025 am 09:09 AM
2025年にフォローするトップ13のインドのgenaiリーダーApr 18, 2025 am 09:09 AMインドのトップ13ジェネレーティブAIリーダー:AIの未来を形作る インドの急成長する生成AI(Genai)セクターは、政府の支援と多数の企業とスタートアップの貢献に支えられた爆発的な成長を経験しています。 この記事sp
 Gemma Scope:AI'の思考プロセスを覗くためのGoogle'の顕微鏡Apr 17, 2025 am 11:55 AM
Gemma Scope:AI'の思考プロセスを覗くためのGoogle'の顕微鏡Apr 17, 2025 am 11:55 AMジェマの範囲で言語モデルの内部の仕組みを探る AI言語モデルの複雑さを理解することは、重要な課題です。 包括的なツールキットであるGemma ScopeのGoogleのリリースは、研究者に掘り下げる強力な方法を提供します
 ビジネスインテリジェンスアナリストは誰で、どのようになるか?Apr 17, 2025 am 11:44 AM
ビジネスインテリジェンスアナリストは誰で、どのようになるか?Apr 17, 2025 am 11:44 AMビジネスの成功のロック解除:ビジネスインテリジェンスアナリストになるためのガイド 生データを組織の成長を促進する実用的な洞察に変換することを想像してください。 これはビジネスインテリジェンス(BI)アナリストの力です - GUにおける重要な役割
 SQLに列を追加する方法は? - 分析VidhyaApr 17, 2025 am 11:43 AM
SQLに列を追加する方法は? - 分析VidhyaApr 17, 2025 am 11:43 AMSQLの変更テーブルステートメント:データベースに列を動的に追加する データ管理では、SQLの適応性が重要です。 その場でデータベース構造を調整する必要がありますか? Alter Tableステートメントはあなたの解決策です。このガイドの詳細は、コルを追加します
 ビジネスアナリストとデータアナリストApr 17, 2025 am 11:38 AM
ビジネスアナリストとデータアナリストApr 17, 2025 am 11:38 AM導入 2人の専門家が重要なプロジェクトで協力している賑やかなオフィスを想像してください。 ビジネスアナリストは、会社の目標に焦点を当て、改善の分野を特定し、市場動向との戦略的整合を確保しています。 シム
 ExcelのCountとCountaとは何ですか? - 分析VidhyaApr 17, 2025 am 11:34 AM
ExcelのCountとCountaとは何ですか? - 分析VidhyaApr 17, 2025 am 11:34 AMExcelデータカウントと分析:カウントとカウントの機能の詳細な説明 特に大規模なデータセットを使用する場合、Excelでは、正確なデータカウントと分析が重要です。 Excelは、これを達成するためにさまざまな機能を提供し、CountおよびCounta関数は、さまざまな条件下でセルの数をカウントするための重要なツールです。両方の機能はセルをカウントするために使用されますが、設計ターゲットは異なるデータ型をターゲットにしています。 CountおよびCounta機能の特定の詳細を掘り下げ、独自の機能と違いを強調し、データ分析に適用する方法を学びましょう。 キーポイントの概要 カウントとcouを理解します
 ChromeはAIと一緒にここにいます:毎日何か新しいことを体験してください!!Apr 17, 2025 am 11:29 AM
ChromeはAIと一緒にここにいます:毎日何か新しいことを体験してください!!Apr 17, 2025 am 11:29 AMGoogle Chrome'sAI Revolution:パーソナライズされた効率的なブラウジングエクスペリエンス 人工知能(AI)は私たちの日常生活を急速に変換しており、Google ChromeはWebブラウジングアリーナで料金をリードしています。 この記事では、興奮を探ります


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

MinGW - Minimalist GNU for Windows
このプロジェクトは osdn.net/projects/mingw に移行中です。引き続きそこでフォローしていただけます。 MinGW: GNU Compiler Collection (GCC) のネイティブ Windows ポートであり、ネイティブ Windows アプリケーションを構築するための自由に配布可能なインポート ライブラリとヘッダー ファイルであり、C99 機能をサポートする MSVC ランタイムの拡張機能が含まれています。すべての MinGW ソフトウェアは 64 ビット Windows プラットフォームで実行できます。

メモ帳++7.3.1
使いやすく無料のコードエディター

WebStorm Mac版
便利なJavaScript開発ツール

Dreamweaver Mac版
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)

