



Text-to-image (T2I) 拡散モデルは、大規模な画像とテキストのペアでの事前トレーニングにより、高解像度画像の生成に優れています。
これは自然な疑問を引き起こします: 視覚認識タスクを解決するために拡散モデルを使用できるでしょうか?
最近、ByteDance と復丹大学のチームは、視覚的なタスクを処理するための拡散モデルを提案しました。

論文アドレス: https://arxiv.org/abs/2312.14733
オープンソース プロジェクト: https://github.com/fudan-zvg/meta-prompts
チームの重要な洞察は、学習可能なメタプロンプトを事前トレーニングされた拡散モデルに導入して、適切な特性を抽出することです。特定の知覚タスクの。
技術紹介
チームは、テキストから画像への拡散モデルを特徴抽出器として視覚認識タスクに適用します。
まず、入力画像が VQVAE エンコーダによって圧縮され、解像度が元のサイズの 1/8 に低減され、潜在空間特徴表現が生成されます。 VQVAE エンコーダ パラメータは固定されており、後続のトレーニングには参加しないことに注意してください。
次のステップでは、特徴抽出のためにノイズのないデータを UNet に送信します。さまざまなタスクに適切に適応するために、UNet は変調されたタイムステップの埋め込みと複数のメタキューを同時に受信して、形状の一貫した特徴を生成します。
この手法では、特徴表現を強化するために、プロセス全体で繰り返し改良が行われます。これにより、UNet 内のさまざまな層の機能をより対話的に融合できるようになります。 2 番目のサイクルでは、UNet のパラメーターが特定の学習可能な時間変調機能によって調整されます。
最後に、UNet によって生成されたマルチスケール特徴が、ターゲット ビジョン タスク用に特別に設計されたデコーダーに入力されます。
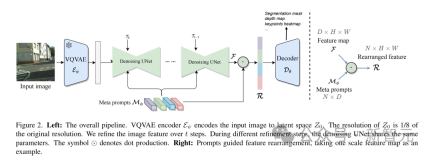
学習可能なメタ プロンプト設計
安定した普及モデルは UNet を採用アーキテクチャを構築し、クロスアテンションを通じてテキスト キューを画像特徴に統合して、ヴィンセント グラフを実現します。この統合により、画像生成が文脈的にも意味的にも正確になることが保証されます。
ただし、視覚認識タスクの多様性はこの範囲を超えています。画像理解はさまざまな課題に直面しており、多くの場合、ガイダンスとなるテキスト情報が不足しているため、テキスト駆動型の方法が非現実的な場合があります。
この課題に対処するために、技術チームのアプローチはより多様な戦略を採用しており、外部のテキスト キューに依存するのではなく、内部で学習可能なメタ キューを設計しています。メタ プロンプトは、知覚タスクに適応するために拡散モデルに統合されています。
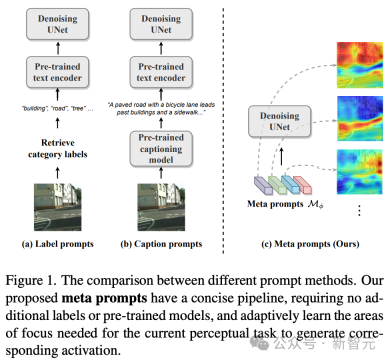
#メタ プロンプトは、メタ プロンプトの数と次元を表す行列の形式で表現されます。メタ プロンプトを備えた知覚拡散モデルでは、データセット カテゴリ ラベルや画像タイトルなどの外部テキスト プロンプトが不要になり、最終的なテキスト プロンプトを生成するために事前トレーニングされたテキスト エンコーダーは必要ありません。
メタ プロンプトは、ターゲット タスクとデータ セットに従ってエンドツーエンドでトレーニングできるため、UNet のノイズを除去するために特別にカスタマイズされた適応条件を確立できます。これらのメタ プロンプトには、特定のタスクに適合した豊富なセマンティック情報が含まれています。例:
- セマンティック セグメンテーション タスク では、メタ プロンプトはカテゴリを識別する能力を効果的に示しており、同じメタ プロンプトは同じカテゴリの機能をアクティブにする傾向があります。カテゴリー 。

- 深度推定タスク では、メタ プロンプトは深度を知覚する能力を示し、活性化値は深度に応じて変化します。一定の距離にあるオブジェクトに焦点を合わせるプロンプトを有効にします。

#- 姿勢推定 では、メタ プロンプトはさまざまな機能セット、特にキー ポイントの認識を示し、これにより人間の姿勢検出が容易になります。
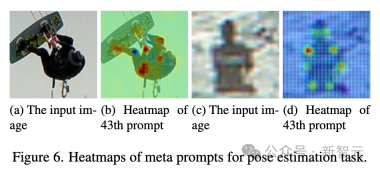
#これらの定性的結果は、さまざまなタスクにおけるタスク関連の能力を活性化する上で、技術チームによって提案されたメタ プロンプトの有効性を強調しています。
テキスト プロンプトの代替として、メタ プロンプトはテキストから画像への拡散モデルと視覚認識タスクの間のギャップをうまく埋めます。
メタキューに基づく特徴の再編成
拡散モデルは、固有の設計マルチを通じて UNet のノイズ除去で生成されます。 - 出力レイヤーに近い、より細かい低レベルの詳細に焦点を当てたスケール機能。
質感や粒度を強調するタスクにはこの低レベルの詳細で十分ですが、視覚認識タスクでは多くの場合、低レベルの詳細と高レベルの意味解釈の両方を含むコンテンツを理解する必要があります。 。
したがって、豊富な特徴を生成する必要があるだけでなく、これらのマルチスケール特徴のどの組み合わせが現在のタスクに最適な表現を提供できるかを判断することも非常に重要です。
ここでメタ プロンプトが登場します -
これらのプロンプトは、トレーニング中に使用されるデータセットに固有のコンテキストを保持します。ナレッジ。この状況に応じた知識により、メタ プロンプトが機能再結合のフィルターとして機能し、機能選択プロセスをガイドし、UNet によって生成された多くの機能からタスクに最も関連性の高い機能をフィルターで除外できるようになります。
チームは、ドット積アプローチを使用して、UNet の豊富なマルチスケール機能とメタ プロンプトのタスク適応性を組み合わせています。
マルチスケールの機能をそれぞれ検討してみます。特徴マップの高さと幅を表します。メタプロンプト。各スケールで再配置された特徴は次のように計算されます。
最後に、メタ プロンプトによってフィルター処理されたこれらの特徴がタスク固有のデコーダーに入力されます。
学習可能な時間変調特徴に基づく反復的改善
拡散モデルにノイズを追加してからマルチステップを実行します。ノイズ除去の反復プロセスにより、画像生成のフレームワークが形成されます。
このメカニズムに触発されて、技術チームは、出力特徴にノイズを追加せずに、UNet ループ入力の出力特徴を直接追加して、視覚認識タスク用の単純な反復改良プロセスを設計しました。 Uネット。
同時に、モデルがループを通過するにつれて入力特徴の分布が変化するが、UNet のパラメーターは変化しないという不整合の問題を解決するために、技術チームは各ループに学習可能な機能を導入 UNet のパラメータを調整するための独自のタイムステップ埋め込み。
これにより、ネットワークがさまざまなステップでの入力特徴の変動に適応して応答できる状態が維持され、特徴抽出プロセスが最適化され、視覚認識タスクにおけるモデルのパフォーマンスが向上します。
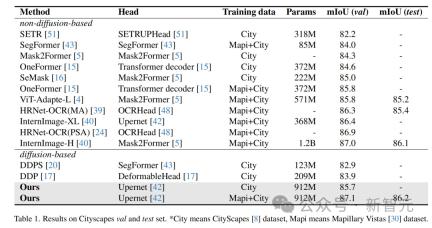
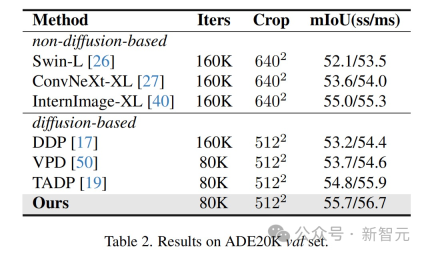
結果は、この方法が複数の知覚タスク データ セットで最適な結果を達成したことを示しています。

 #アプリケーションの実装と展望
#アプリケーションの実装と展望
インテリジェント クリエーション チームは、ByteDance の AI およびマルチメディア テクノロジー センターであり、コンピューター ビジョン、オーディオおよびビデオ編集、特殊効果処理、その他の技術をカバーしています。同社の豊富なビジネス シナリオ、インフラストラクチャ リソース、および技術コラボレーションの雰囲気を利用して、最先端のアルゴリズム、エンジニアリング システム、製品の閉ループを実現し、社内ビジネスに最先端のコンテンツの理解と提供を目的としています。さまざまな形式のコンテンツ、作成、インタラクティブな体験、消費のための機能と業界ソリューション。 現在、インテリジェント創造チームは、ByteDance が所有するクラウド サービス プラットフォームである Volcano Engine を通じて、その技術能力とサービスを企業に公開しています。大規模モデル アルゴリズムに関連するその他のポジションも募集中です。「原文を読む」 をクリックしてご覧ください。
チーム紹介
以上がByte Fudan チームの革新的な「メタチップ」戦略により、拡散モデルの画像理解のパフォーマンスが向上し、前例のないレベルに達しました。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 Microsoft Work Trend Index 2025は、職場の容量の緊張を示していますApr 24, 2025 am 11:19 AM
Microsoft Work Trend Index 2025は、職場の容量の緊張を示していますApr 24, 2025 am 11:19 AMAIの急速な統合により悪化した職場での急成長能力の危機は、増分調整を超えて戦略的な変化を要求します。 これは、WTIの調査結果によって強調されています。従業員の68%がワークロードに苦労しており、BURにつながります
 AIは理解できますか?中国の部屋の議論はノーと言っていますが、それは正しいですか?Apr 24, 2025 am 11:18 AM
AIは理解できますか?中国の部屋の議論はノーと言っていますが、それは正しいですか?Apr 24, 2025 am 11:18 AMジョン・サールの中国の部屋の議論:AIの理解への挑戦 Searleの思考実験は、人工知能が真に言語を理解できるのか、それとも真の意識を持っているのかを直接疑問に思っています。 チャインを無知な人を想像してください
 中国の「スマート」AIアシスタントは、マイクロソフトのリコールのプライバシーの欠陥をエコーしますApr 24, 2025 am 11:17 AM
中国の「スマート」AIアシスタントは、マイクロソフトのリコールのプライバシーの欠陥をエコーしますApr 24, 2025 am 11:17 AM中国のハイテク大手は、西部のカウンターパートと比較して、AI開発の別のコースを図っています。 技術的なベンチマークとAPI統合のみに焦点を当てるのではなく、「スクリーン認識」AIアシスタントを優先しています。
 Dockerは、おなじみのコンテナワークフローをAIモデルとMCPツールにもたらしますApr 24, 2025 am 11:16 AM
Dockerは、おなじみのコンテナワークフローをAIモデルとMCPツールにもたらしますApr 24, 2025 am 11:16 AMMCP:AIシステムに外部ツールにアクセスできるようになります モデルコンテキストプロトコル(MCP)により、AIアプリケーションは標準化されたインターフェイスを介して外部ツールとデータソースと対話できます。人類によって開発され、主要なAIプロバイダーによってサポートされているMCPは、言語モデルとエージェントが利用可能なツールを発見し、適切なパラメーターでそれらを呼び出すことができます。ただし、環境紛争、セキュリティの脆弱性、一貫性のないクロスプラットフォーム動作など、MCPサーバーの実装にはいくつかの課題があります。 Forbesの記事「人類のモデルコンテキストプロトコルは、AIエージェントの開発における大きなステップです」著者:Janakiram MSVDockerは、コンテナ化を通じてこれらの問題を解決します。 Docker Hubインフラストラクチャに基づいて構築されたドキュメント
 6億ドルのスタートアップを構築するために6つのAIストリートスマート戦略を使用するApr 24, 2025 am 11:15 AM
6億ドルのスタートアップを構築するために6つのAIストリートスマート戦略を使用するApr 24, 2025 am 11:15 AM最先端のテクノロジーと巧妙なビジネスの洞察力を活用して、コントロールを維持しながら非常に収益性の高いスケーラブルな企業を作成する先見の明のある起業家によって採用された6つの戦略。このガイドは、建設を目指している起業家向けのためのものです
 Googleフォトの更新は、すべての写真の見事なウルトラHDRのロックを解除しますApr 24, 2025 am 11:14 AM
Googleフォトの更新は、すべての写真の見事なウルトラHDRのロックを解除しますApr 24, 2025 am 11:14 AMGoogle Photosの新しいウルトラHDRツール:画像強化のゲームチェンジャー Google Photosは、強力なウルトラHDR変換ツールを導入し、標準的な写真を活気のある高ダイナミックレンジ画像に変換しました。この強化は写真家に利益をもたらします
 Descopeは、AIエージェント統合の認証フレームワークを構築しますApr 24, 2025 am 11:13 AM
Descopeは、AIエージェント統合の認証フレームワークを構築しますApr 24, 2025 am 11:13 AM技術アーキテクチャは、新たな認証の課題を解決します エージェントアイデンティティハブは、AIエージェントの実装を開始した後にのみ多くの組織が発見した問題に取り組んでいます。
 Google Cloud Next2025と現代の仕事の接続された未来Apr 24, 2025 am 11:12 AM
Google Cloud Next2025と現代の仕事の接続された未来Apr 24, 2025 am 11:12 AM(注:Googleは私の会社であるMoor Insights&Strategyのアドバイザリークライアントです。) AI:実験からエンタープライズ財団まで Google Cloud Next 2025は、実験機能からエンタープライズテクノロジーのコアコンポーネント、ストリームへのAIの進化を紹介しました


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

SublimeText3 英語版
推奨: Win バージョン、コードプロンプトをサポート!

ZendStudio 13.5.1 Mac
強力な PHP 統合開発環境

MinGW - Minimalist GNU for Windows
このプロジェクトは osdn.net/projects/mingw に移行中です。引き続きそこでフォローしていただけます。 MinGW: GNU Compiler Collection (GCC) のネイティブ Windows ポートであり、ネイティブ Windows アプリケーションを構築するための自由に配布可能なインポート ライブラリとヘッダー ファイルであり、C99 機能をサポートする MSVC ランタイムの拡張機能が含まれています。すべての MinGW ソフトウェアは 64 ビット Windows プラットフォームで実行できます。

SAP NetWeaver Server Adapter for Eclipse
Eclipse を SAP NetWeaver アプリケーション サーバーと統合します。

AtomエディタMac版ダウンロード
最も人気のあるオープンソースエディター
ホットトピック
 7698
7698 15164014139352128725122929
15164014139352128725122929