
ホームページ >テクノロジー周辺機器 >AI >商用利用が無条件で無料の世界最長のオープンソースモデル XVERSE-Long-256K
商用利用が無条件で無料の世界最長のオープンソースモデル XVERSE-Long-256K

- WBOY転載
- 2024-01-16 21:54:15748ブラウズ
Yuanxiang は、コンテキスト ウィンドウの長さが 256K の世界初のオープンソース大規模モデル XVERSE-Long-256K をリリースしました。漢字25万文字の入力に対応し、大規模モデルのアプリケーションでも「長文時代」への突入を可能にします。このモデルは完全にオープンソースであり、無条件で無料で商用利用でき、詳細なステップバイステップのトレーニングチュートリアルも付属しているため、多くの中小企業、研究者、開発者が「大規模な」を実現できます。先ほどのモデルの自由」。
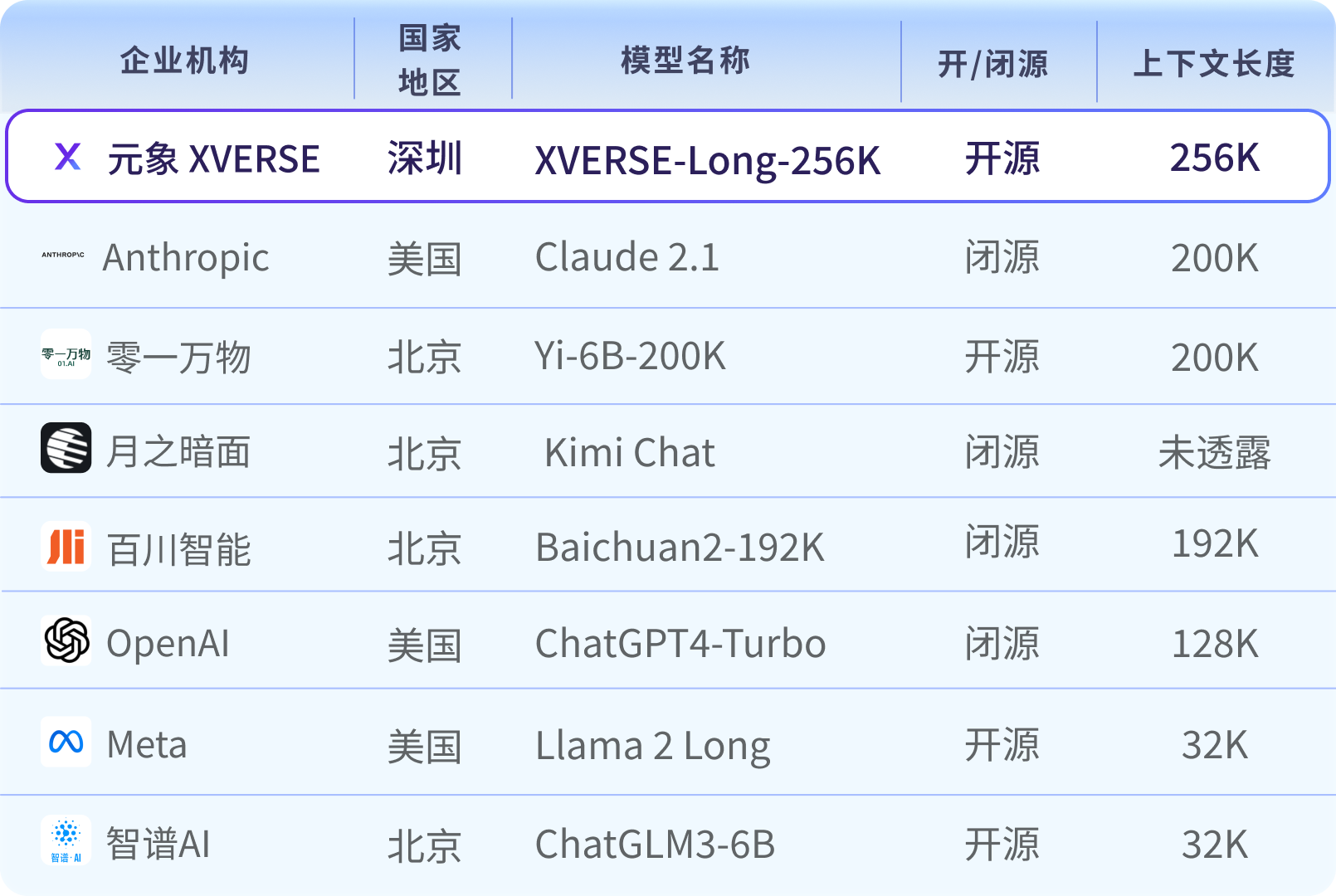 世界主流の長文大規模モデル マップ
世界主流の長文大規模モデル マップ
パラメータの量と高品質のデータの量によって、大規模モデルの計算の複雑さが決まります。長文技術(Long Context)は、大規模モデルアプリケーション開発における「殺人兵器」ですが、新しい技術と研究開発の難易度の高さから、現在はそのほとんどが有料のクローズドソースで提供されています。
XVERSE-Long-256K は超長いテキスト入力をサポートしており、大規模なデータ分析、複数文書の読解、クロスドメインの知識統合に使用でき、大規模モデルの深さと幅を効果的に向上させます。アプリケーション: 1. 弁護士および金融アナリストまたはコンサルタント、プロンプトエンジニア、科学研究者などは、長いテキストの分析および処理の作業を解決できます; 2. ロールプレイングまたはチャットアプリケーションで、モデルの「忘れる」という記憶の問題を軽減します。 「前の会話、またはナンセンスなどの「幻覚」問題」 3. AI エージェントが履歴情報に基づいて計画を立て、意思決定を行うためのサポートの向上 4. AI ネイティブ アプリケーションが一貫性のあるパーソナライズされたユーザー エクスペリエンスを維持できるように支援します。
これまでのところ、XVERSE-Long-256K はオープンソース エコシステムのギャップを埋めており、Yuanxiang の以前の 70 億、130 億、65 億ドルと「高性能ファミリー バケット」も形成しています。 10億パラメータの大規模モデルを実現し、国内のオープンソースを国際一流レベルにまで向上させます。 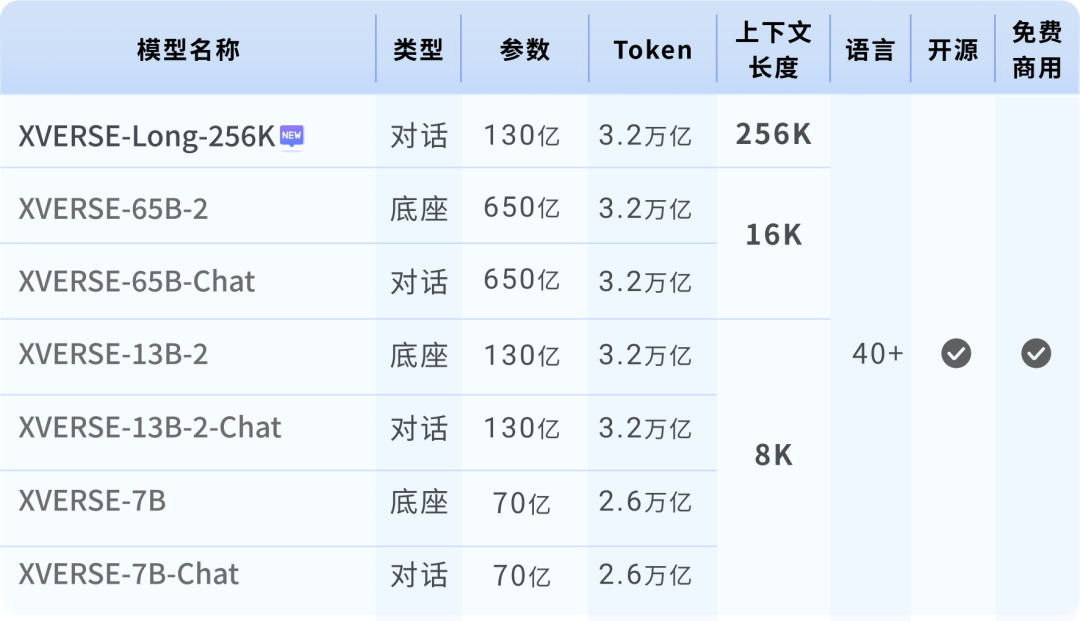 Yuanxiang 大型モデル シリーズ
Yuanxiang 大型モデル シリーズ
Yuanxiang 大型モデルの無料ダウンロード
- ##GitHub: https://github.com/xverse-ai / XVERSE-13B-256K
- お問い合わせの送信先: opensource@xverse.cn
- ユーザーは、大規模モデルの公式 Web サイト (chat.xverse.cn) またはXVERSE-Longをすぐに体験できるミニプログラム -256K。
- 高いパフォーマンスのポジショニング
優れた評価パフォーマンス
業界が Yuanxiang 大型モデルを包括的、客観的かつ長期的に理解できるようにするために、研究者は権威ある業界を参考に評価を行うため、6つの側面からなる9項目の総合評価システムを開発しました。 XVERSE-Long-256K はすべて良好なパフォーマンスを示し、他のロング テキスト モデルを上回ります。 世界主流の長文オープンソース大規模モデルの評価結果 XVERSE-Long-256K は、一般的な長文大規模モデルのパフォーマンス ストレス テスト「干し草の山の中から針を見つける」に合格しました。このテストでは、長いテキスト コーパス内の内容とは関係のない文を隠し、自然言語の質問を使用して大規模モデルに文を正確に抽出させます。 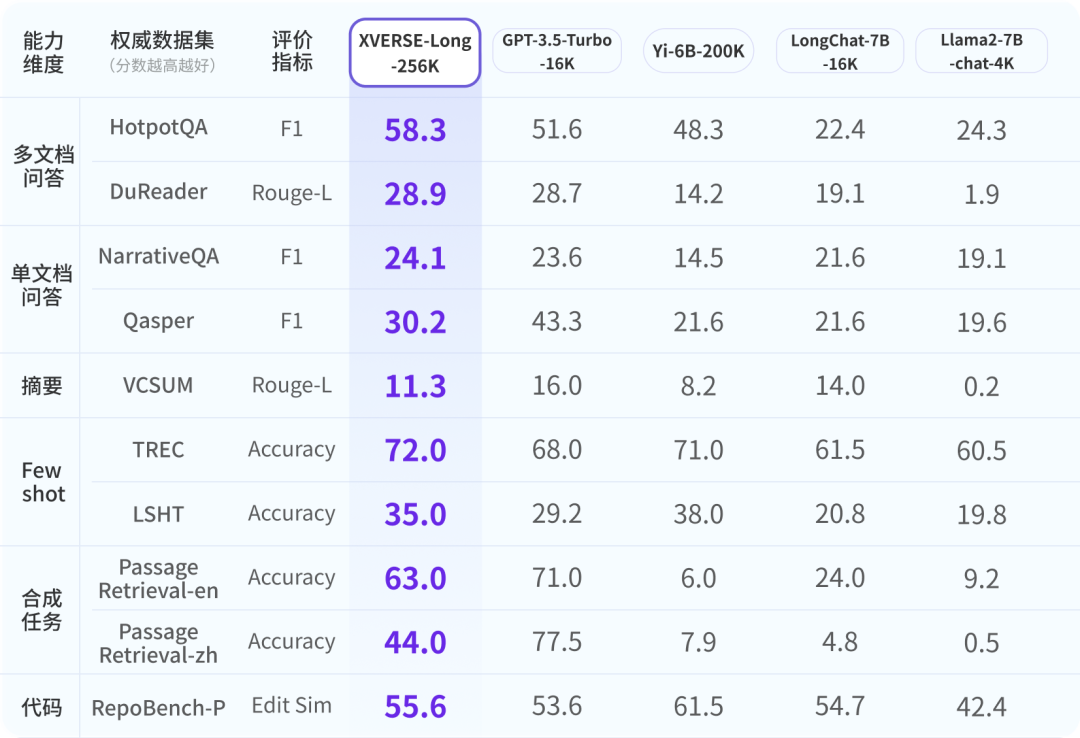 小説
小説
読解現在、中国の大規模モデルのほとんどは中国語と英語のバイリンガルのみをサポートしています。 Yuanxiang は 40 以上の言語をサポートしています。私たちは、160,000 文字のロシアの古典小説「鋼鉄の鍛え方」と、410,000 文字のドイツの歴史伝記「人類の星が輝くとき」をテストしました。 「鋼はどのように焼き戻されたのか (ロシア語版)」 テスト
「人間の星が輝くとき (ドイツ語版)」 テスト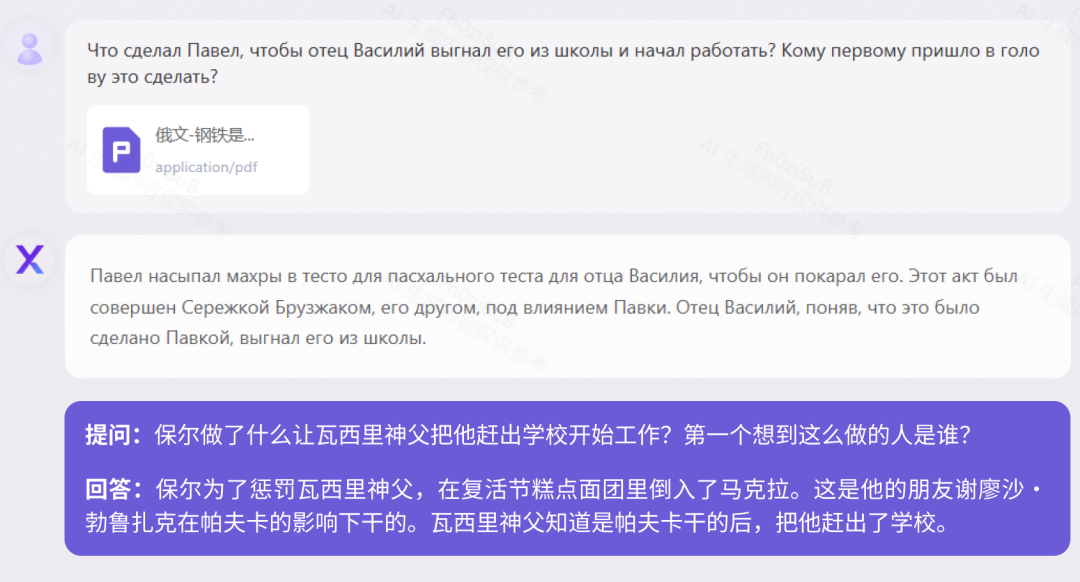
 法律記事
法律記事
正確な適用 「中華人民共和国民法典」を例として、法律用語と事例の説明を示します。論理的な分析を行い、それを実践的で柔軟なアプリケーションと組み合わせます。
## 「民法」テスト長文のトレーニング方法を段階的に教えます。大型モデル


1. 技術的課題
- モデル トレーニング: GPU メモリの使用量はシーケンスの長さの 2 乗に比例するため、トレーニング量が急激に増加します。
- モデル構造: シーケンスが長ければ長いほど、モデルの注意が分散され、モデルが前の内容を忘れやすくなります。
- 推論速度: モデル シーケンスが長くなるほど、モデル推論は遅くなります。
2. Yuanxiang Technology Route
長文大規模モデル技術は、過去 1 年間に開発された新技術であり、その主な技術ソリューションは次のとおりです。 :
- 長いシーケンスの事前トレーニングを直接実行しますが、これによりトレーニング量が 2 乗して増加します。
- 位置エンコーディングの内挿または外挿によりシーケンスの長さを拡張します。この方法では、位置エンコーディングの解像度が低下するため、大規模なモデルの出力効果が減少します。
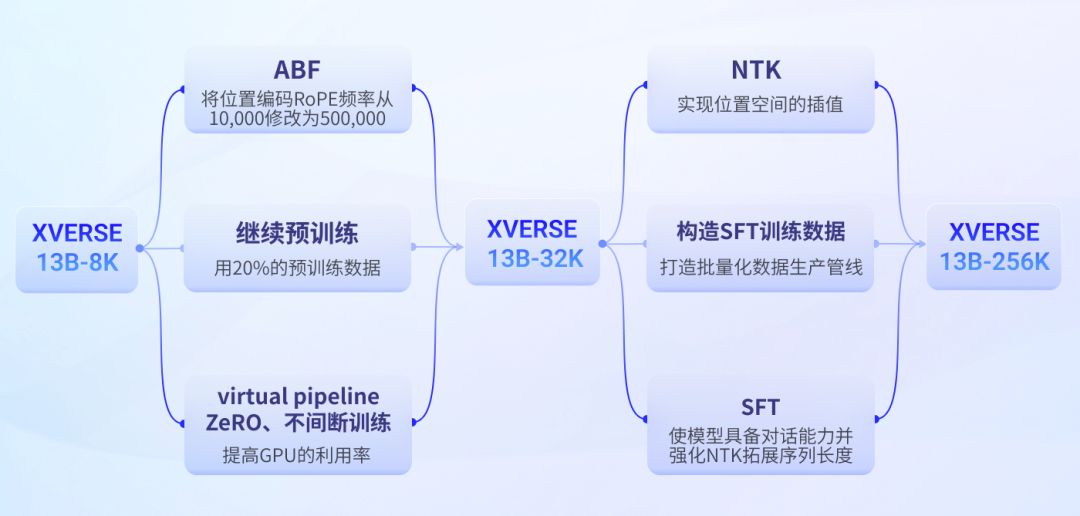
#第一段階:ABF 事前トレーニングを続行
- GitHub: https://github.com/xverse-ai/XVERSE-13B
- ハグフェイス: https://huggingface.co / xverse/XVERSE-13B-256K
- Magic: https://modelscope.cn/models/xverse/XVERSE-13B-256K
- お問い合わせについては、opensource@xverse.cn# まで送信してください。
- ##
以上が商用利用が無条件で無料の世界最長のオープンソースモデル XVERSE-Long-256Kの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。