元の意味を変えずに内容を書き直すには、言語を中国語に書き直す必要があり、元の文を表示する必要はありません
ウェブサイト編集部
PowerInferの登場でAIが動くようになる消費者グレードのハードウェアでより効率的
上海交通大学チームは、超強力な CPU/GPU LLM 高速推論である PowerInfer を立ち上げました。エンジン。 
プロジェクト アドレス: https://github.com/SJTU-IPADS/PowerInfer
紙のアドレス: https://ipads.se.sjtu.edu.cn/_media / Publications/powerinfer-20231219.pdf
どのくらい速いですか?
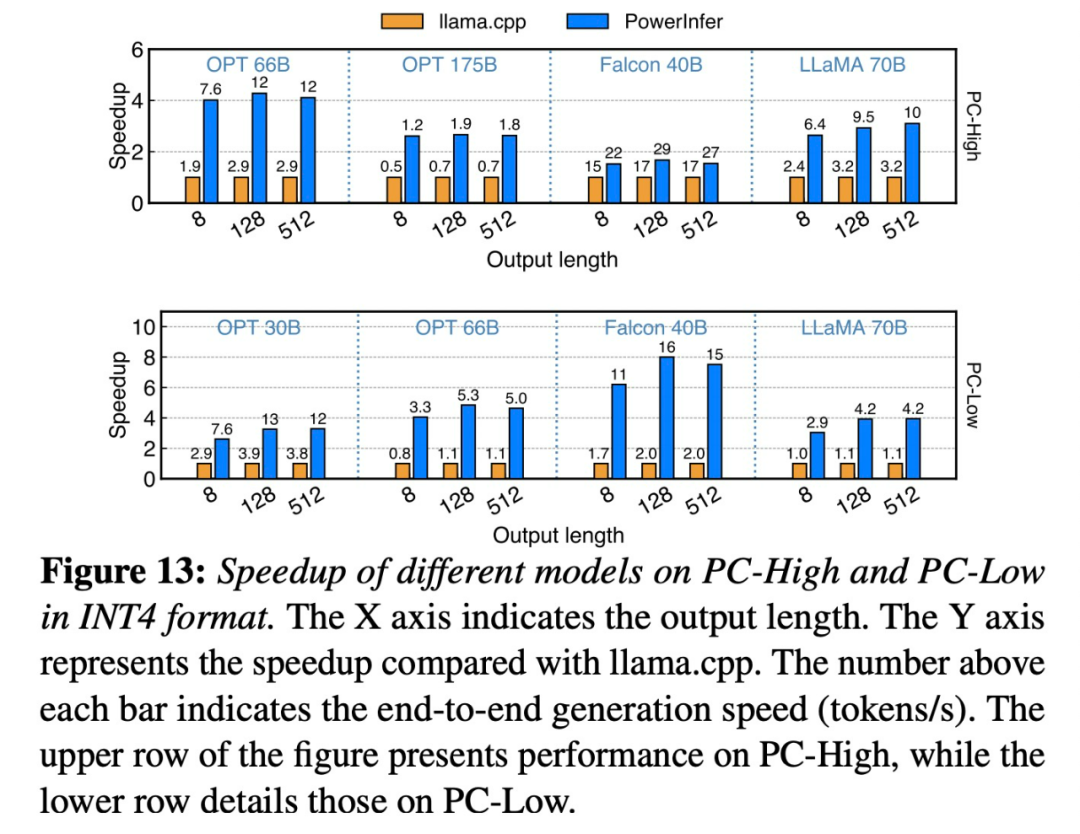
Falcon (ReLU)-40B-FP16 を実行する 1 台の RTX 4090 (24G) で、PowerInfer は llama.cpp と比較して 11 倍の高速化を達成しました。
PowerInfer と llama.cpp は両方とも同じハードウェア上で実行され、VRAM を最大限に活用します。 RTX4090で。 単一の NVIDIA RTX 4090 GPU 上のさまざまな LLM にわたって、PowerInfer の平均トークン生成速度は 13.20 トークン/秒、ピーク時は 29.08 トークン/秒です。 . 秒で、最上位のサーバーグレードの A100 GPU よりわずか 18% 低いだけです。
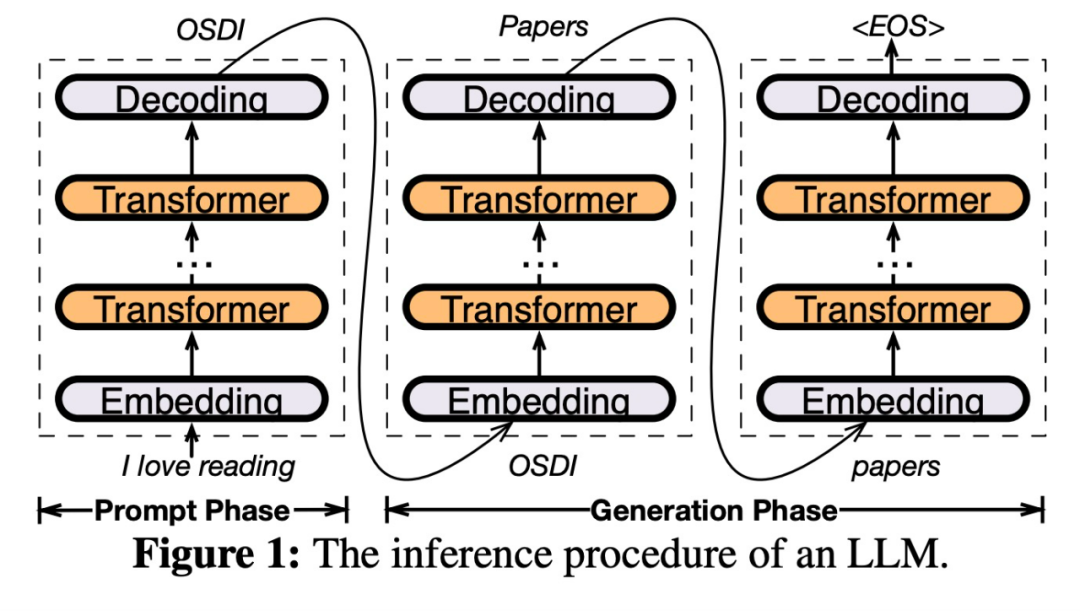
具体的には、PowerInfer は、オンプレミス LLM デプロイメント用の高速推論エンジンです。 LLM 推論の高い局所性を利用して、GPU-CPU ハイブリッド推論エンジンを設計します。ホット アクティブ化ニューロンは、素早いアクセスのために GPU にプリロードされていますが、コールド アクティブ化ニューロンは (ほとんど) CPU で計算されます。このアプローチにより、GPU メモリ要件と CPU-GPU データ転送が大幅に削減されます。 PowerInfer は、単一のコンシューマ GPU を搭載したパーソナル コンピュータ (PC) 上で大規模言語モデル (LLM) を高速に実行できます。ユーザーは Llama 2 および Faclon 40B で PowerInfer を使用できるようになり、Mistral-7B のサポートも近日中に開始されます。 #PowerInfer の設計の鍵は、LLM 推論に固有の高度な局所性を利用することです。LLM 推論は、ニューロンの活性化におけるべき乗則分布によって特徴付けられます。
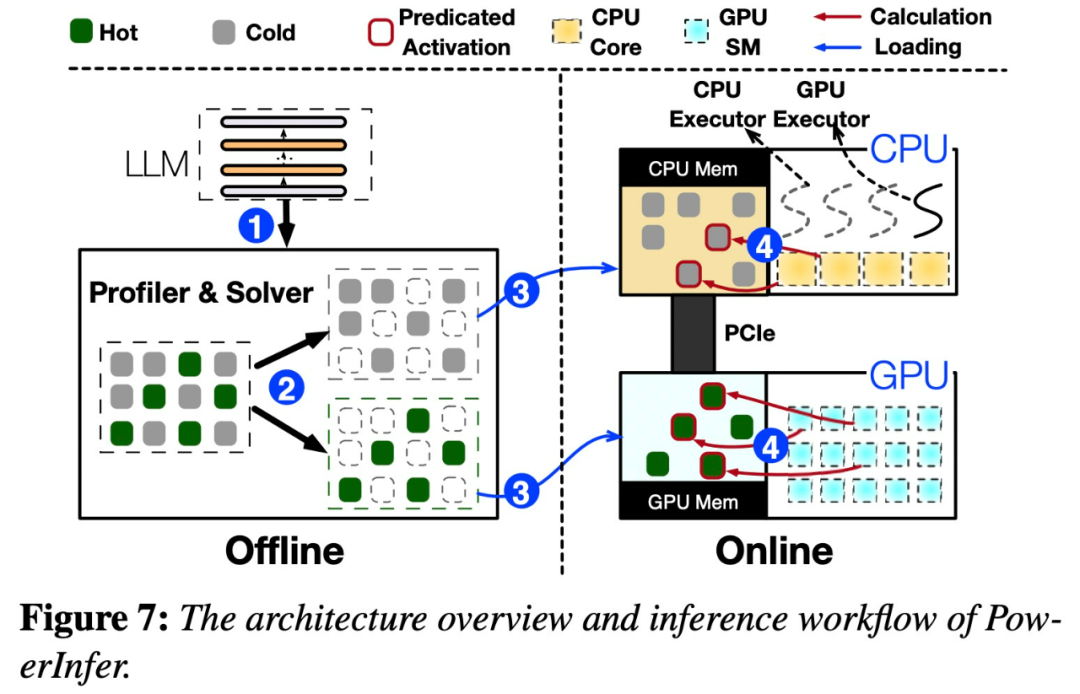
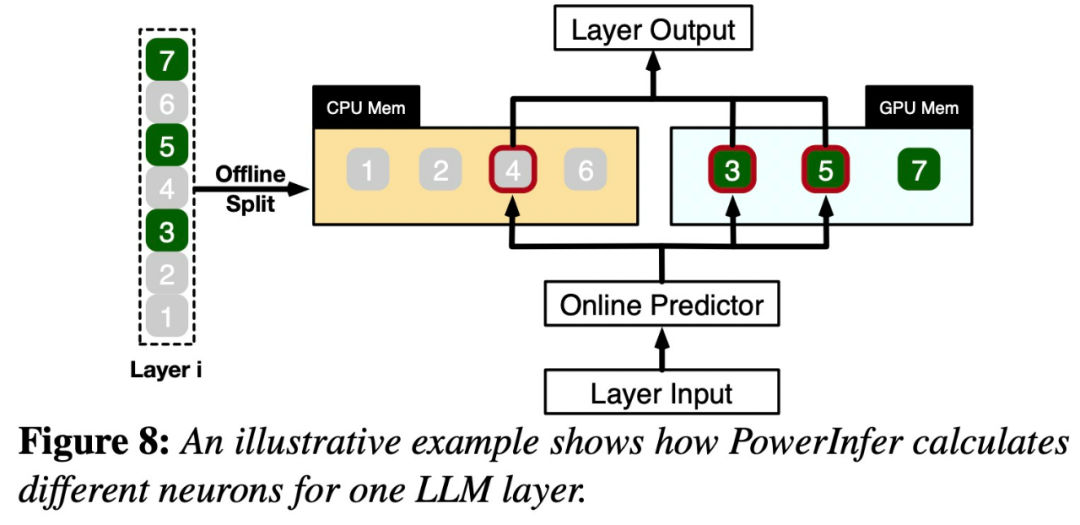
# 以下の図 7 は、オフライン コンポーネントとオンライン コンポーネントを含む PowerInfer のアーキテクチャの概要を示しています。
この分布は、ニューロンの小さなサブセット (ホット ニューロンと呼ばれる) の活性化が一貫していることを示しています。一方、ほとんどのコールド ニューロンは特定の入力に応じて変化します。 PowerInfer は、このメカニズムを利用して GPU-CPU ハイブリッド推論エンジンを設計します。
PowerInfer は、適応予測子とニューロン対応のスパース演算子をさらに統合して最適化し、効率を向上させます。ニューロンの活性化と計算の疎性の関係。
この研究を見たネチズンは、「1 枚のカード 4090 で 175B の大型モデルを実行することはもはや夢ではない」と興奮を表明しました。
以上が上海交通大学が推論エンジン PowerInfer をリリース、トークン生成率が A100 よりわずか 18% 低い、A100 の代替として 4090 を置き換える可能性がある。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。