
ホームページ >テクノロジー周辺機器 >AI >Google、AI によるエラー修正機能の向上を支援する BIG-Bench Mistake データセットを発表
Google、AI によるエラー修正機能の向上を支援する BIG-Bench Mistake データセットを発表

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2024-01-16 18:57:16759ブラウズ
Google Research は最近、独自の BIG-Bench ベンチマークと新しく確立された「BIG-Bench Mistake」データセットを使用して、一般的な言語モデルに関する評価研究を実施しました。彼らは主に、言語モデルのエラー確率とエラー訂正能力に焦点を当てました。この調査は、市場における言語モデルのパフォーマンスをより深く理解するための貴重なデータを提供します。
Googleの研究者らは、大規模な言語モデルの「エラー確率」と「自己修正能力」を評価するために、「BIG-Bench Mistake」と呼ばれる特別なベンチマークデータセットを作成したと発表した。これは、これらの重要な指標を効果的に評価およびテストするための対応するデータセットが過去に欠如していたことが原因です。
研究者らは、PaLM 言語モデルを使用して独自の BIG-Bench ベンチマーク タスクで 5 つのタスクを実行し、生成された「思考連鎖」軌跡を「ロジック エラー」部分に追加しました。モデルの精度を再テストします。
データセットの精度を向上させるために、Google の研究者は上記のプロセスを繰り返し実行し、最終的に「BIG-Bench Mistake」と呼ばれる 255 個の論理エラーを含む評価専用のベンチマーク データセットを作成しました。
研究者らは、「BIG-Bench Mistake」データセットの論理エラーは非常に明白であるため、言語モデルのテストの優れた標準として使用できると指摘しました。このデータセットは、モデルが単純なエラーから学習し、エラーを識別する能力を徐々に向上させるのに役立ちます。
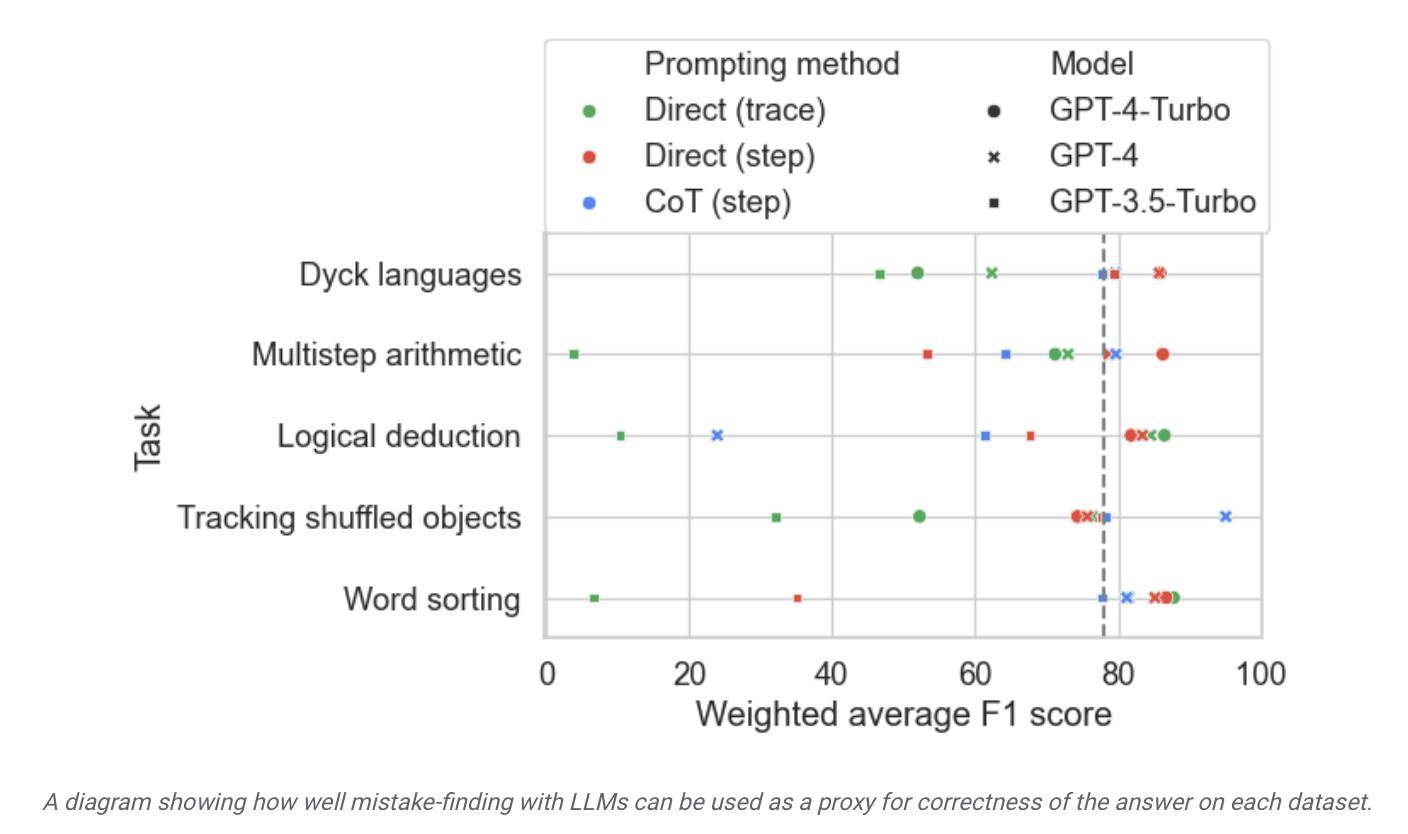
研究者らは、このデータセットを使用して市販のモデルをテストしたところ、ほとんどの言語モデルは推論プロセスの論理エラーを特定して自ら修正できるものの、このプロセスはあまり理想的ではないことがわかりました。多くの場合、モデルの出力を修正するには人間の介入も必要です。
▲ 画像出典 Google Research プレスリリース
レポートによると、Google は、これが現在最も先進的な大規模言語モデルであると考えられているが、その自己修正能力は比較的限られていると主張しています。テストでは、最もパフォーマンスの高いモデルで検出された論理エラーは 52.9% のみでした。

Google 研究者らはまた、この BIG-Bench Mistake データセットはモデルの自己修正能力の向上に役立つと主張しており、関連するテスト タスクでモデルを微調整した後、「小さなモデルであっても、通常はモデルのパフォーマンスよりも優れています」と述べています。サンプルプロンプトがゼロの大きなモデル。「より良い」。
これによると、Google は、モデルのエラー修正に関して、独自の小さなモデルを大規模なモデルの「監視」に使用できると考えています。大規模な言語モデルに「自己エラーの修正」を学習させる代わりに、専用の小さな専用モデルをデプロイします。大規模なモデルを監視することには、効率が向上し、関連する AI 導入コストが削減され、微調整が容易になるという利点があります。
以上がGoogle、AI によるエラー修正機能の向上を支援する BIG-Bench Mistake データセットを発表の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。