
ホームページ >テクノロジー周辺機器 >AI >Google、AI言語モデルの自己修正機能向上を支援するBIG-Bench Mistakeデータセットをリリース
Google、AI言語モデルの自己修正機能向上を支援するBIG-Bench Mistakeデータセットをリリース

- 王林転載
- 2024-01-16 16:39:131390ブラウズ

Google Research は、独自の BIG-Bench ベンチマークを使用して「BIG-Bench Mistake」データセットを確立し、市場で人気のある言語モデルのエラー確率とエラー修正機能を評価しました。 。この取り組みは、言語モデルの品質と精度を向上させ、インテリジェント検索と自然言語処理の分野でのアプリケーションに対するサポートを向上させることを目的としています。
Googleの研究者らは、大規模言語モデルのエラー確率と自己修正能力を評価するために「BIG-Bench Mistake」と呼ばれる特別なデータセットを作成したと発表した。このデータセットの目的は、これらの機能を評価するためのデータセットが過去に不足していたというギャップを埋めることです。
研究者らは、PaLM 言語モデルを使用して、BIG-Bench ベンチマークで 5 つのタスクを実行しました。その後、生成された「思考連鎖」の軌跡を修正し、「論理エラー」部分を追加し、モデルを再度使用して思考連鎖の軌跡のエラーを特定しました。
データセットの精度を向上させるために、Google の研究者は上記のプロセスを繰り返し、255 個の論理エラーを含む「BIG-Bench Mistake」と呼ばれる専用のベンチマーク データ セットを作成しました。
研究者らは、「BIG-Bench Mistake」データセットの論理エラーは非常に明白であるため、言語モデルが単純な論理エラーから練習を開始するのに役立つ優れたテスト標準として使用できると指摘しました。エラーを識別する能力を徐々に向上させます。
研究者らは、このデータセットを使用して市場のモデルをテストしたところ、大多数の言語モデルは推論プロセス中に発生する論理エラーを特定し、自ら修正できるものの、このプロセスは「十分ではない」ことを発見しました。理想的な" 、モデルの出力を修正するには人間の介入が必要になることがよくあります。
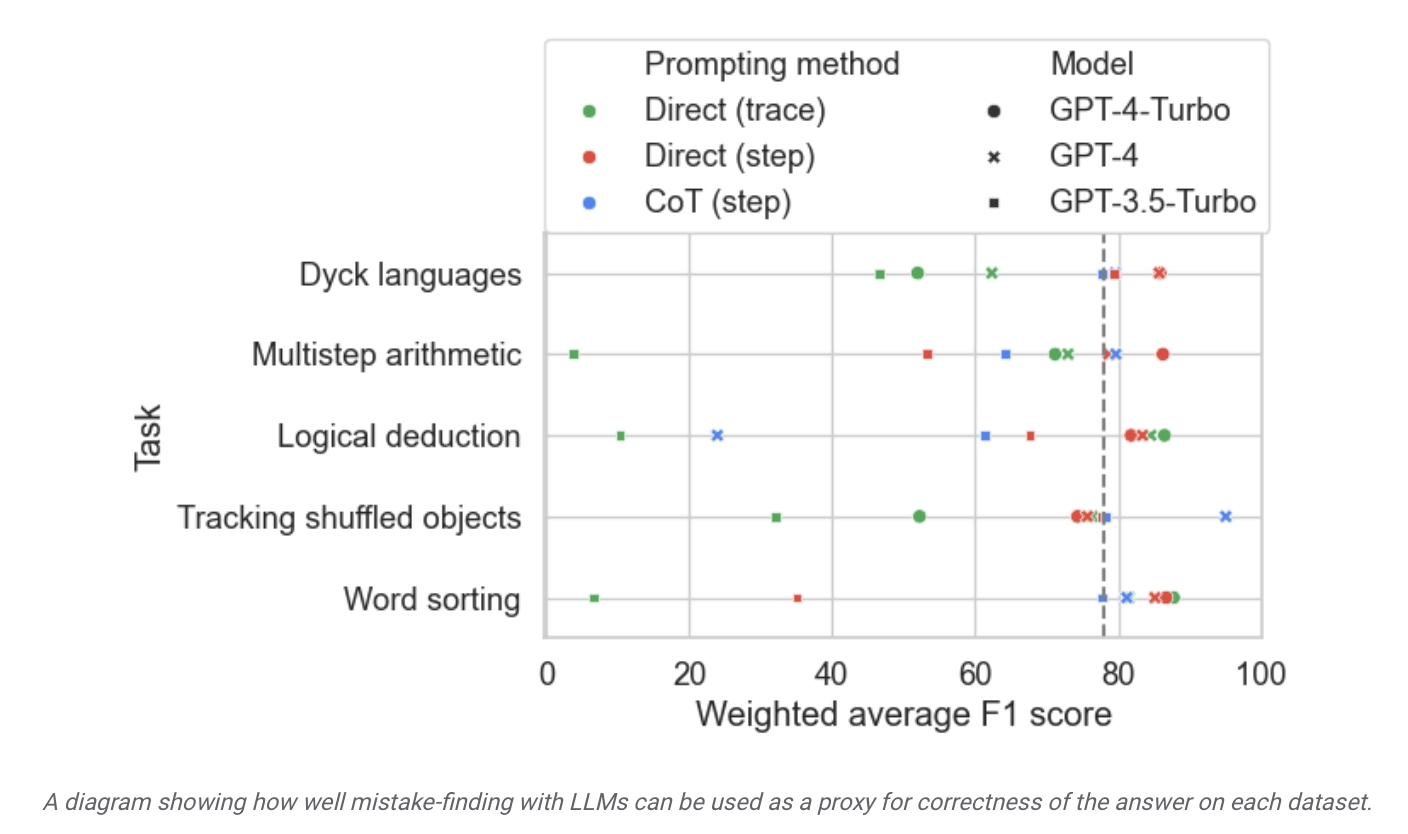
Google 研究者はまた、この BIG-Bench Mistake データセットはモデルの自己修正能力の向上に役立つと主張しました。関連するテスト タスクでモデルを微調整した後、「また、一般に、小規模なモデルは、ゼロサンプル キューを備えた大規模なモデルよりも優れたパフォーマンスを発揮します。」 
デプロイメントは大規模なモデルの監視に特化しており、小規模で特殊なモデルを使用すると、効率が向上し、関連する AI 導入コストが削減され、微調整が容易になります。
以上がGoogle、AI言語モデルの自己修正機能向上を支援するBIG-Bench Mistakeデータセットをリリースの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。