GPT-4 は、詳細かつ正確な画像記述を生成する並外れた能力を実証し、言語および視覚処理の新時代の到来を告げています。 したがって、GPT-4 に似たマルチモーダル大規模言語モデル (MLLM) が最近登場し、注目の新興研究分野となっています。 LLM は、マルチモーダルなタスクを実行するための認知フレームワークとして使用されます。 MLLM の予期せぬ優れたパフォーマンスは、従来の手法を上回るだけでなく、一般的な人工知能を実現する潜在的な方法の 1 つになります。 有用な MLLM を作成するには、大規模な画像とテキストのペア データと視覚言語微調整データを使用して、凍結された LLM (LLaMA や Vicuna など) をトレーニングする必要があります。 ) および視覚的表現 (CLIP や BLIP-2 など)。 #MLLM のトレーニングは、通常、事前トレーニング段階と微調整段階の 2 つの段階に分かれています。事前トレーニングの目的は、MLLM が大量の知識を取得できるようにすることですが、微調整は、人間の意図をより深く理解し、正確な応答を生成するようにモデルを教えることです。 視覚言語を理解し、指示に従う MLLM の能力を強化するために、指示チューニングと呼ばれる強力な微調整テクノロジが最近登場しました。このテクノロジーは、モデルを人間の好みに合わせて調整するのに役立ち、モデルがさまざまな異なる指示の下で人間が望む結果を生成できるようにします。命令微調整テクノロジの開発に関して、非常に建設的な方向性は、微調整段階で画像アノテーション、視覚的質問応答 (VQA)、および視覚的推論データ セットを導入することです。 InstructBLIP や Otter などのこれまでの技術では、一連の視覚言語データ セットを使用して視覚的な指示を微調整し、有望な結果も得ています。 ただし、一般的に使用されるマルチモーダル命令微調整データセットには、応答が不正確または無関係な低品質のインスタンスが多数含まれていることが観察されています。このようなデータは誤解を招き、モデルのパフォーマンスに悪影響を与える可能性があります。 この疑問をきっかけに、研究者は、少量の高品質な指示に従ってデータを使用して堅牢なパフォーマンスを達成する可能性を検討しました。 最近の研究では、この方向性に可能性があることを示す有望な結果が得られています。たとえば、Zhou らは、人間の専門家によって慎重に選択された高品質のデータを使用して微調整された言語モデルである LIMA を提案しました。この研究は、大規模な言語モデルが、限られた量の高品質な指示に従っても満足のいく結果を達成できることを示しています。そこで研究者らは、「調整に関しては、少ないほど良い」と結論付けました。ただし、マルチモーダル言語モデルを微調整するために適切な高品質のデータセットを選択する方法に関する明確なガイドラインはありません。 上海交通大学清源研究所とリーハイ大学の研究チームは、このギャップを埋め、堅牢で効果的なデータセレクターを提案しました。このデータ セレクターは、低品質の視覚的言語データを自動的に識別してフィルタリングし、最も関連性が高く有益なサンプルがモデルのトレーニングに使用されるようにします。 文書アドレス: https://arxiv.org/abs/2308.12067
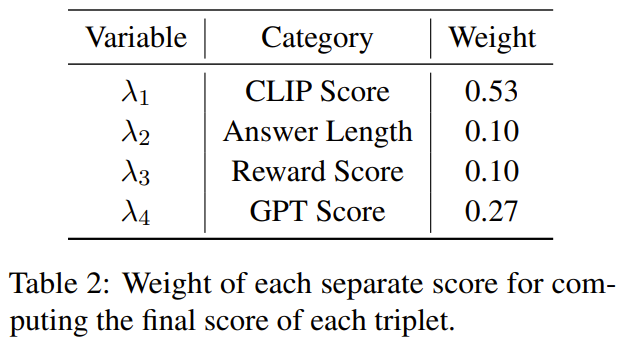
研究者らは、この研究の焦点は、マルチモーダル大規模言語モデルの微調整における、小規模だが高品質の命令微調整データの有効性を調査することであると述べた。これに加えて、このペーパーでは、マルチモーダル指示データの品質を評価するために特別に設計されたいくつかの新しい指標を紹介します。画像に対してスペクトル クラスタリングを実行した後、データ セレクターは、各視覚的言語データの CLIP スコア、GPT スコア、ボーナス スコア、および回答の長さを組み合わせた加重スコアを計算します。
研究者らは、MiniGPT-4 の微調整に使用される 3400 個の生データに対してこのセレクターを使用したところ、ほとんどのデータに低品質の問題があることがわかりました。このデータ セレクターを使用して、研究者は厳選されたデータのはるかに小さいサブセット (元のデータ セットのわずか 6% に相当するわずか 200 データ) を取得しました。次に、MiniGPT-4 と同じトレーニング構成を使用し、それを微調整して新しいモデル structGPT-4 を取得しました。
#研究者らは、視覚的・口頭による指示を微調整する際にはデータの量よりもデータの質が重要であることを示しているため、これは興味深い発見であると述べています。さらに、データ品質をより重視したこの変更により、MLLM の微調整を改善できる、新しくてより効果的なパラダイムが提供されます。
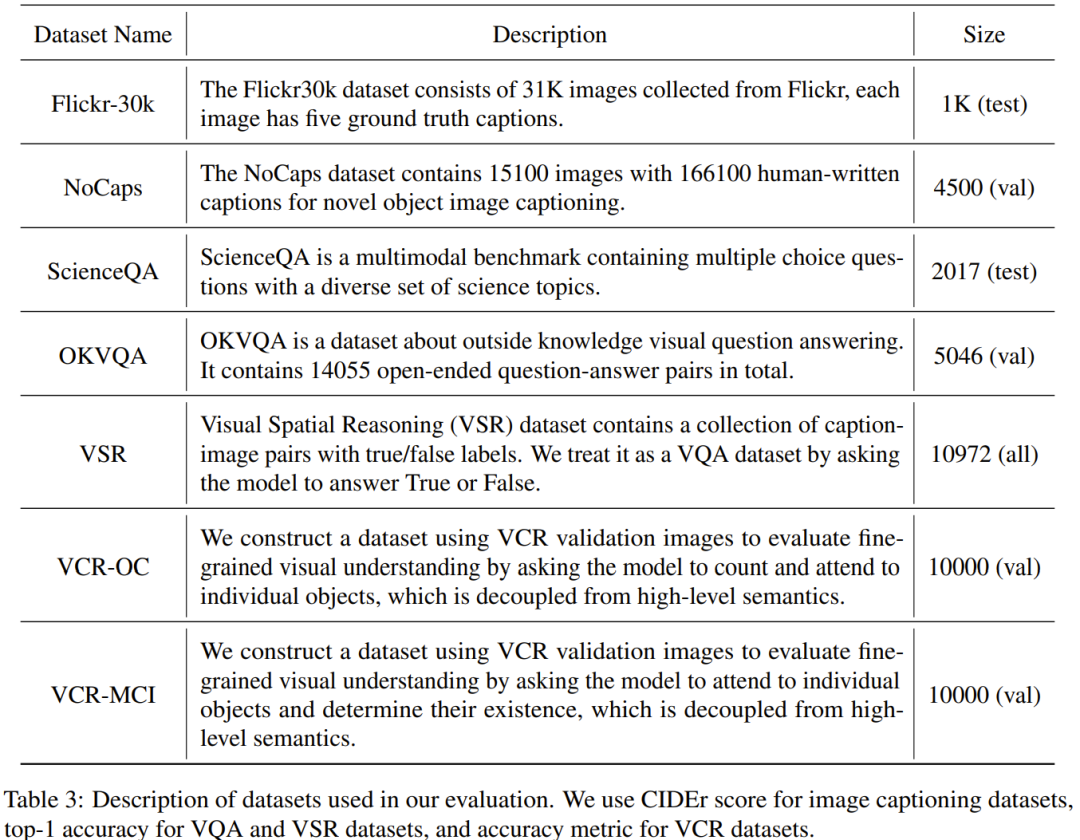
研究者らは、Flick-30k、ScienceQA を含む 7 つの多様で複雑なオープンドメイン マルチモーダル データセットに焦点を当て、厳密な実験と微調整された MLLM の実験的評価を実施しました。 、VSRなど。彼らは、さまざまなマルチモーダル タスクで、さまざまなデータセット選択方法 (データ セレクターの使用、データ セットのランダム サンプリング、完全なデータ セットの使用) を使用して微調整されたモデルの推論パフォーマンスを比較し、その結果は structGPT-4 のパフォーマンスが優れていることを示しました。 。 さらに、研究者が評価に使用した評価器は GPT-4 であることに注意してください。具体的には、研究者らはプロンプトを使用して GPT-4 を評価器に変え、LLaVA-Bench のテスト セットを使用して structGPT-4 と元の MiniGPT-4 の応答結果を比較できるようにしました。 structionGPT-4 で使用される微調整データは、MiniGPT-4 で使用される元の命令準拠データと比較してわずか 6% であることがわかりました。後者の場合、応答は 73% の確率で同じかそれ以上でした。
- 200 (約 200 個) を選択することで、 6%) 高品質の命令は、structGPT-4 をトレーニングするためのデータに従うため、研究者らは、マルチモーダル大規模言語モデルのより少ない命令データを使用して、より適切な調整を達成できることを示しています。
- この論文では、シンプルで解釈可能な原理を使用して、微調整のために高品質のマルチモーダル指示準拠データを選択するデータ セレクターを提案します。このアプローチは、データのサブセットの評価と調整における有効性と移植性を達成することを目指しています。
- 研究者らは、このシンプルなテクノロジーがさまざまなタスクをうまく処理できることを実験を通じて示しました。オリジナルの MiniGPT-4 と比較して、わずか 6% のフィルタリングされたデータを使用して微調整された struct GPT-4 は、さまざまなタスクで優れたパフォーマンスを実現します。
これ研究の目標は、元の微調整されたデータセットからサブセットを自動的に選択できる、シンプルでポータブルなデータ セレクターを提案することです。この目的を達成するために、研究者らは、マルチモーダルなデータセットの多様性と品質に焦点を当てた選択原則を定義しました。以下に簡単に紹介します。
#選択原則
##MLLM を効果的にトレーニングするには、有用なマルチモーダル命令データを選択することが重要です。最適な指導データを選択するために、研究者は多様性と品質という 2 つの重要な原則を提案しました。多様性を確保するために、研究者が採用しているアプローチは、画像の埋め込みをクラスター化してデータを異なるグループに分離することです。品質を評価するために、研究者らはマルチモーダルデータを効率的に評価するためのいくつかの重要な指標を採用しました。
視覚的および言語的な指示を与えるデータ セットと事前トレーニングされた MLLM (MiniGPT-4 や LLaVA など) を組み合わせた場合、データ セレクターの最終目標は、微調整するサブセットを特定し、このサブセットが事前トレーニングされた MLLM に改善をもたらすようにすることです。 このサブセットを選択し、その多様性を確保するために、研究者らはまずクラスタリング アルゴリズムを使用して、元のデータ セットを複数のカテゴリに分割しました。
選択されたマルチモーダル指導データの品質を保証するために、研究者は、以下の表 1 に示すように、評価用の一連の指標を開発しました。
#表 2 は、最終スコアを計算する際のさまざまなスコアの重みを示しています。
#アルゴリズム 1 は、データ セレクターのワークフロー全体を示しています。 実験評価で使用したデータ セット以下の表 3 に示します。
#ベンチマーク スコア
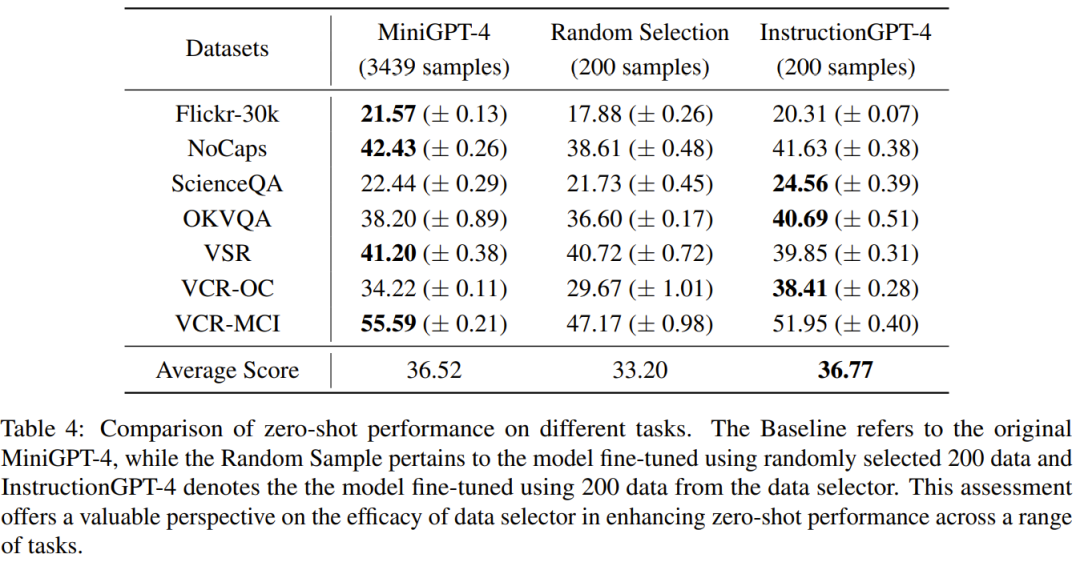
表 4 は MiniGPT-4 を比較しています。ベースライン モデルのパフォーマンス、ランダムにサンプリングされたデータを使用して微調整された MiniGPT-4、およびデータ セレクターを使用して微調整された structGPT-4。InstructionGPT-4 の平均パフォーマンスが最高であることがわかります。具体的には、structGPT-4 は、ScienceQA ではベースライン モデルを 2.12% 上回り、OKVQA と VCR-OC ではそれぞれベースライン モデルを 2.49% と 4.19% 上回っています。 さらに、struct GPT-4 は、VSR を除く他のすべてのタスクにおいて、ランダム サンプルでトレーニングされたモデルよりも優れたパフォーマンスを発揮します。さまざまなタスクでこれらのモデルを評価および比較することで、それぞれの機能を識別し、高品質のデータを効果的に識別する新しく提案されたデータ セレクターの有効性を判断することができます。 # このような包括的な分析は、賢明なデータ選択により、さまざまなタスクにおけるモデルのゼロショット パフォーマンスを向上できることを示しています。 2) 引き分け: structGPT-4 および MiniGPT-4 2 回引き分け、または 1 回勝ち、1 回負け;
3) 負け: structGPT-4 2 回負け、または 1 回負けそして一度描きます。
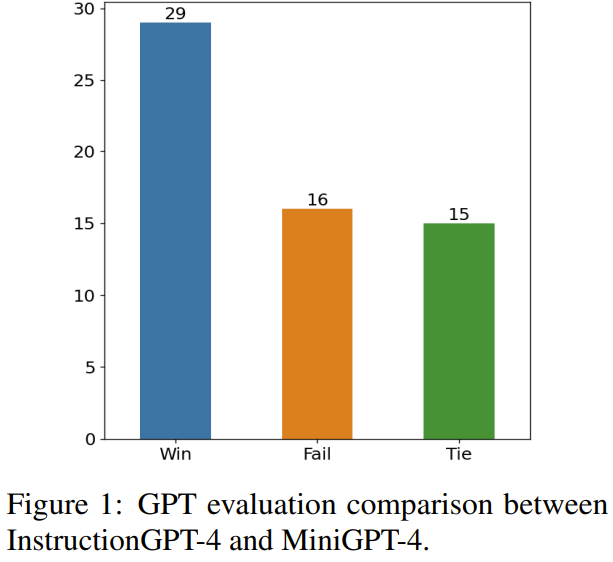
# 図 1 に、この評価方法の結果を示します。
60 の問題のうち、struct GPT-4 は 29 試合で勝ち、16 試合で負け、残りの 15 試合で引き分けました。これは、応答品質の点で、structGPT-4 が MiniGPT-4 よりも大幅に優れていることを証明するのに十分です。
#アブレーションの研究
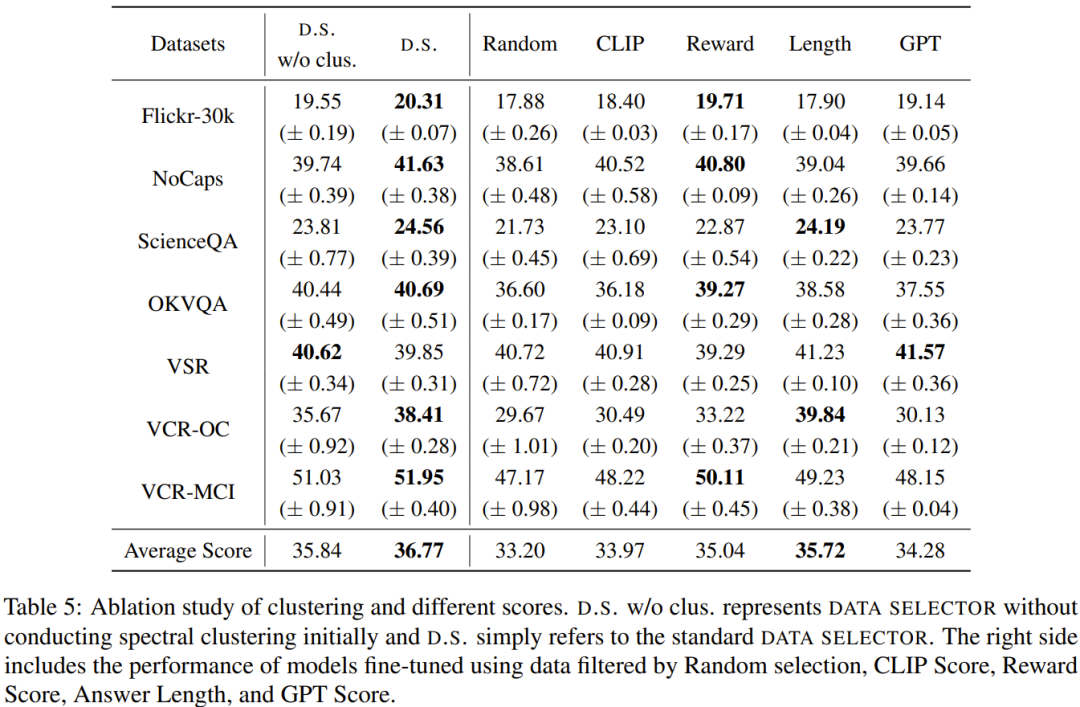
アブレーションを表 5 に示します。クラスタリングアルゴリズムの重要性と各種評価スコアがわかる実験の解析結果。 #################################デモ################ ##視覚入力を理解し、合理的な応答を生成する struct GPT-4 の能力をより深く理解するために、研究者らは、struct GPT-4 と MiniGPT の画像理解と対話能力の比較評価も実施しました。 4.この分析は、画像の説明とさらなる理解を含む顕著な例に基づいており、結果を表 6 に示します。
#命令GPT-4 は、包括的な画像の説明を提供し、画像の興味深い側面を特定することに優れています。 MiniGPT-4 と比較して、struct GPT-4 は画像内に存在するテキストを認識する能力が高くなります。ここで、structGPT-4 は、画像内に「Monday, just Monday」というフレーズがあることを正確に指摘できます。
 詳細については、元の論文を参照してください。
詳細については、元の論文を参照してください。 以上が200 個のデータを選択した後、同じモデルのマッチングで MiniGPT-4 を上回りました。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。





 詳細については、元の論文を参照してください。
詳細については、元の論文を参照してください。