最近、Transformer ベースのアルゴリズムがさまざまなコンピューター ビジョン タスクで広く使用されていますが、このタイプのアルゴリズムは、トレーニング データの量が少ない場合、過剰適合の問題が発生する傾向があります。既存のビジョン トランスフォーマーは、通常、CNN で一般的に使用されるドロップアウト アルゴリズムを正則化器として直接導入します。このアルゴリズムは、アテンション ウェイト マップ上でランダムなドロップを実行し、異なる深さのアテンション レイヤーに対して統一されたドロップ確率を設定します。 Dropout は非常にシンプルですが、このドロップ方法には主に 3 つの問題があります。 まず第一に、ソフトマックス正規化後のランダム ドロップは、アテンションの重みの確率分布を壊し、重みのピークを罰することができず、その結果、モデルは依然として過学習状態になります。情報 (図 1)。第 2 に、ネットワークのより深い層でドロップ確率が大きくなると、高レベルのセマンティック情報が欠如しますが、浅い層でドロップ確率が小さくなると、基礎となる詳細な特徴への過剰適合が生じるため、一定のドロップ確率では、トレーニングプロセスが不安定になる可能性があります。最後に、CNN で一般的に使用される構造化ドロップ手法の Vision Transformer での有効性は明らかではありません。 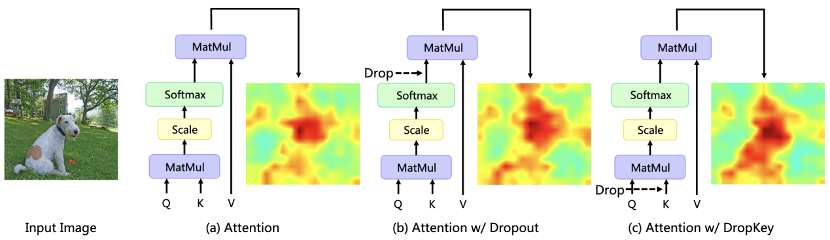
#図 1 さまざまな正則化が注意分布マップに及ぼす影響 Meitu Imaging Research Institute (MT Lab) と中国科学院大学は、CVPR 2023 で、新しいプラグアンドプレイ正則化ツール DropKey を提案する記事を発表しました。ビジョントランスフォーマーの問題。
 論文連結:https://arxiv.org/abs/2208.02646第一,在註意力層應該對什麼訊息執行了Drop 操作?與直接 Drop 注意力權重不同,此方法在計算注意力矩陣之前執行 Drop 操作,並將 Key 作為基礎 Drop 單元。該方法在理論上驗證了正則化器 DropKey 可以對高注意力區域進行懲罰並將注意力權值分配到其它感興趣的區域,從而增強模型對全局資訊的捕捉能力。 第二,如何設定 Drop 機率?與所有層共享同一個 Drop 機率相比,該論文提出了一種新穎的 Drop 機率設定方法,即隨著自註意力層的加深而逐漸衰減 Drop 機率值。 第三,是否需要像 CNN 一樣進行結構化 Drop 操作?該方法嘗試了基於區塊視窗和交叉視窗的結構化 Drop 方式,並發現這種技巧對於 Vision Transformer 來說並不重要。 #Vision Transformer(ViT)是近期電腦視覺模型中的新範式,它被廣泛地應用於影像辨識、影像分割、人體關鍵點檢測和人物互相偵測等任務中。具體而言,ViT 將圖片分割為固定數量的影像區塊,將每個影像區塊視為一個基本單位,同時引入了多頭自註意力機制來提取包含相互關係的特徵資訊。但現有 ViT 類別方法在小資料集上往往會出現過擬合問題,即僅使用目標局部特徵來完成指定任務。 為了克服以上問題,論文提出了一種即插即拔、只需要兩行程式碼便可實現的正則化器DropKey 用以緩解ViT 類別方法的過擬合問題。有別於現有的Dropout,DropKey 將Key 設定為drop 物件並從理論和實驗上驗證了該變更可以對高注意力值部分進行懲罰,同時鼓勵模型更專注於與目標相關的其他影像區塊,有幫助於捕捉全域魯棒特徵。此外,該論文還提出為不斷加深的注意力層設定遞減的 drop 機率,這可以避免模型過度擬合低階特徵並同時確保有充足的高級特徵以進行穩定的訓練。此外,論文也透過實驗證明,結構化 drop 方法對 ViT 來說不是必要的。 #為了探究引發過度適合問題的本質原因,研究首先將注意力機制形式化為一個簡單的最佳化目標並對其拉格朗日展開形式進行分析。發現當模型不斷優化時,當前迭代中註意力佔比越大的影像區塊,在下次迭代過程中會傾向於被分配更大的注意力權值。為緩解此問題,DropKey 透過隨機 drop 部分 Key 的方式來隱式地為每個注意力區塊分配一個自適應算子以約束注意力分佈從而使其變得更加平滑。值得注意的是,相對於其他根據特定任務而設計的正規化器,DropKey 無需任何手動設計。由於在訓練階段對 Key 執行隨機 drop,這將導致訓練和測試階段的輸出期望不一致,因此該方法還提出使用蒙特卡羅方法或微調技巧以對齊輸出期望。此外,此方法的實作僅需兩行程式碼,具體如圖 2 所示。
論文連結:https://arxiv.org/abs/2208.02646第一,在註意力層應該對什麼訊息執行了Drop 操作?與直接 Drop 注意力權重不同,此方法在計算注意力矩陣之前執行 Drop 操作,並將 Key 作為基礎 Drop 單元。該方法在理論上驗證了正則化器 DropKey 可以對高注意力區域進行懲罰並將注意力權值分配到其它感興趣的區域,從而增強模型對全局資訊的捕捉能力。 第二,如何設定 Drop 機率?與所有層共享同一個 Drop 機率相比,該論文提出了一種新穎的 Drop 機率設定方法,即隨著自註意力層的加深而逐漸衰減 Drop 機率值。 第三,是否需要像 CNN 一樣進行結構化 Drop 操作?該方法嘗試了基於區塊視窗和交叉視窗的結構化 Drop 方式,並發現這種技巧對於 Vision Transformer 來說並不重要。 #Vision Transformer(ViT)是近期電腦視覺模型中的新範式,它被廣泛地應用於影像辨識、影像分割、人體關鍵點檢測和人物互相偵測等任務中。具體而言,ViT 將圖片分割為固定數量的影像區塊,將每個影像區塊視為一個基本單位,同時引入了多頭自註意力機制來提取包含相互關係的特徵資訊。但現有 ViT 類別方法在小資料集上往往會出現過擬合問題,即僅使用目標局部特徵來完成指定任務。 為了克服以上問題,論文提出了一種即插即拔、只需要兩行程式碼便可實現的正則化器DropKey 用以緩解ViT 類別方法的過擬合問題。有別於現有的Dropout,DropKey 將Key 設定為drop 物件並從理論和實驗上驗證了該變更可以對高注意力值部分進行懲罰,同時鼓勵模型更專注於與目標相關的其他影像區塊,有幫助於捕捉全域魯棒特徵。此外,該論文還提出為不斷加深的注意力層設定遞減的 drop 機率,這可以避免模型過度擬合低階特徵並同時確保有充足的高級特徵以進行穩定的訓練。此外,論文也透過實驗證明,結構化 drop 方法對 ViT 來說不是必要的。 #為了探究引發過度適合問題的本質原因,研究首先將注意力機制形式化為一個簡單的最佳化目標並對其拉格朗日展開形式進行分析。發現當模型不斷優化時,當前迭代中註意力佔比越大的影像區塊,在下次迭代過程中會傾向於被分配更大的注意力權值。為緩解此問題,DropKey 透過隨機 drop 部分 Key 的方式來隱式地為每個注意力區塊分配一個自適應算子以約束注意力分佈從而使其變得更加平滑。值得注意的是,相對於其他根據特定任務而設計的正規化器,DropKey 無需任何手動設計。由於在訓練階段對 Key 執行隨機 drop,這將導致訓練和測試階段的輸出期望不一致,因此該方法還提出使用蒙特卡羅方法或微調技巧以對齊輸出期望。此外,此方法的實作僅需兩行程式碼,具體如圖 2 所示。

一般而言,ViT 会叠加多个注意力层以逐步学习高维特征。通常,较浅层会提取低维视觉特征,而深层则旨在提取建模空间上粗糙但复杂的信息。因此,该研究尝试为深层设置较小的 drop 概率以避免丢失目标对象的重要信息。具体而言,DropKey 并不在每一层以固定的概率执行随机 drop,而是随着层数的不断加深而逐渐降低 drop 的概率。此外,该研究还发现这种方法不仅适用于 DropKey,还可以显著提高 Dropout 的性能。虽然在 CNN 中对结构化 drop 方法已有较为详细的研究,但还没有研究该 drop 方式对 ViT 的性能影响。为探究该策略会不会进一步提升性能,该论文实现了 DropKey 的两种结构化形式,即 DropKey-Block 和 DropKey-Cross。其中,DropKey- Block 通过对以种子点为中心的正方形窗口内连续区域进行 drop,DropKey-Cross 则通过对以种子点为中心的十字形连续区域进行 drop,如图 3 所示。然而,该研究发现结构化 drop 方法并不会带来性能提升。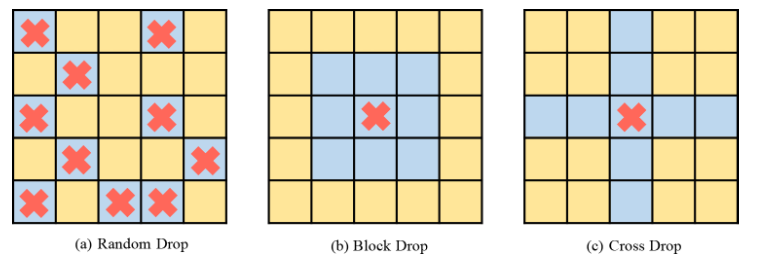
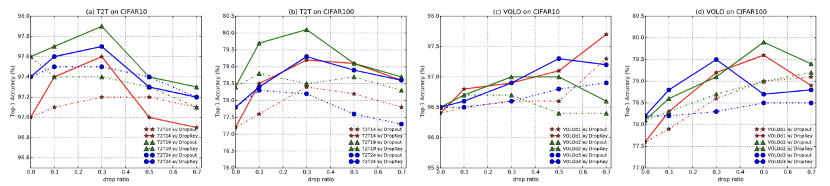
图 4 DropKey 和 Dropout 在 CIFAR10/100 上的性能比较
图 5 DropKey 和 Dropout 在 CIFAR100 上的注意力图可视化效果比较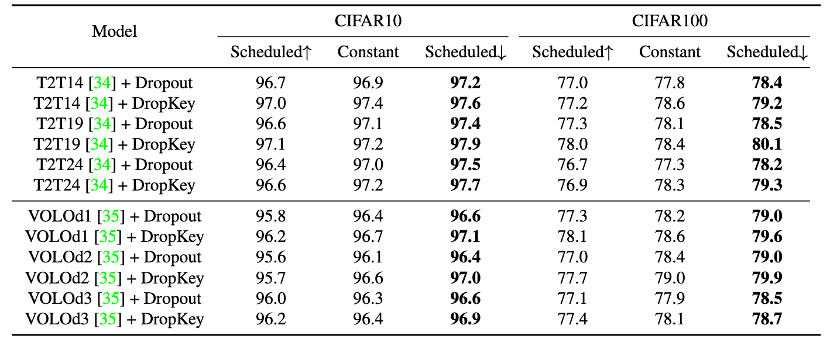
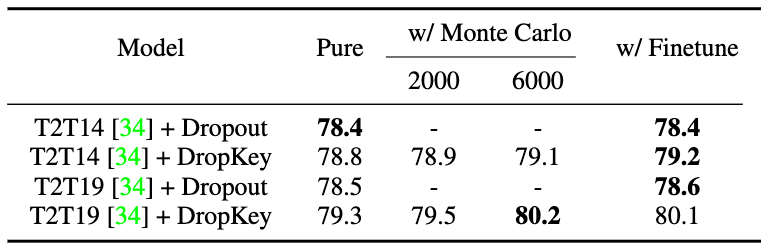
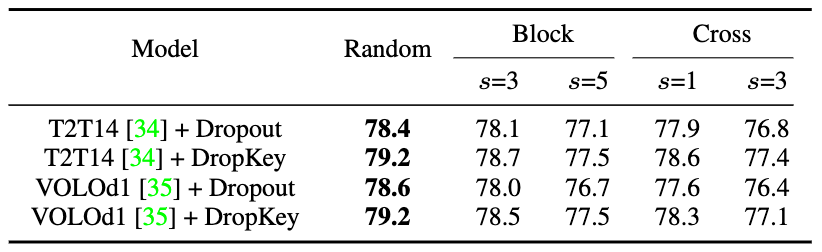
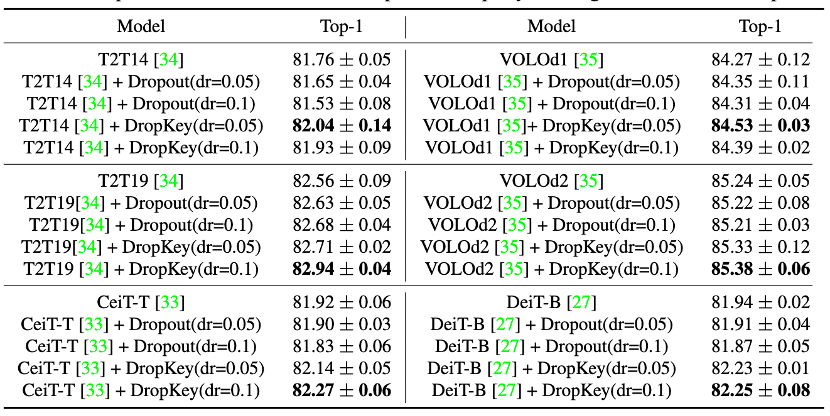
图 9 DropKey 和 Dropout 在 ImageNet 上的性能比较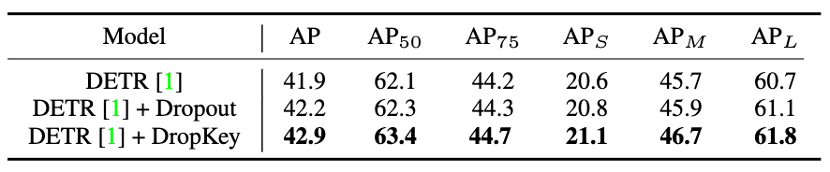
图 10 DropKey 和 Dropout 在 COCO 上的性能比较
图 11 DropKey 和 Dropout 在 HICO-DET 上的性能比较
图 12 DropKey 和 Dropout 在 HICO-DET 上的性能比较
圖13 DropKey 與Dropout 在HICO-DET 上的注意力圖視覺化比較這篇論文創新地提出了一個用於ViT 的正規化器,用於緩解ViT 的過度擬合問題。與現有的正則化器相比,此方法可以透過簡單地將 Key 置為 drop 對象,從而為注意力層提供平滑的注意力分佈。另外,論文也提出了一種新穎的 drop 機率設定策略,成功地在有效緩解過度擬合的同時穩定訓練過程。最後,論文也探討了結構化 drop 方式對模型的表現影響。 以上がCVPR 2023|Meitu と国立科学技術大学が共同で DropKey 正則化手法を提案:2 行のコードを使用して視覚的な Transformer の過学習問題を効果的に回避の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。


