
ホームページ >テクノロジー周辺機器 >AI >Google MIT の最新調査によると、高品質のデータを取得するのは難しくなく、大規模なモデルが解決策となります
Google MIT の最新調査によると、高品質のデータを取得するのは難しくなく、大規模なモデルが解決策となります

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2024-01-14 20:30:251328ブラウズ
現在の大規模モデルのトレーニングでは、高品質のデータを取得することが大きなボトルネックになっています。
数日前、OpenAI はニューヨーク タイムズ紙から訴訟を起こされ、数十億ドルの賠償を求められました。訴状にはGPT-4による盗作の複数の証拠が列挙されている。
ニューヨーク・タイムズでさえ、GPTなどのほとんどすべての大型モデルの破壊を要求しました。

AI 業界の多くの大手企業は、「合成データ」がこの問題に対する最良の解決策である可能性があると長い間信じてきました。

# 以前、Google チームは、LLM を使用して人間のラベル設定を置き換える方法である RLAIF も提案しましたが、その効果はそれよりも劣りません。人間。
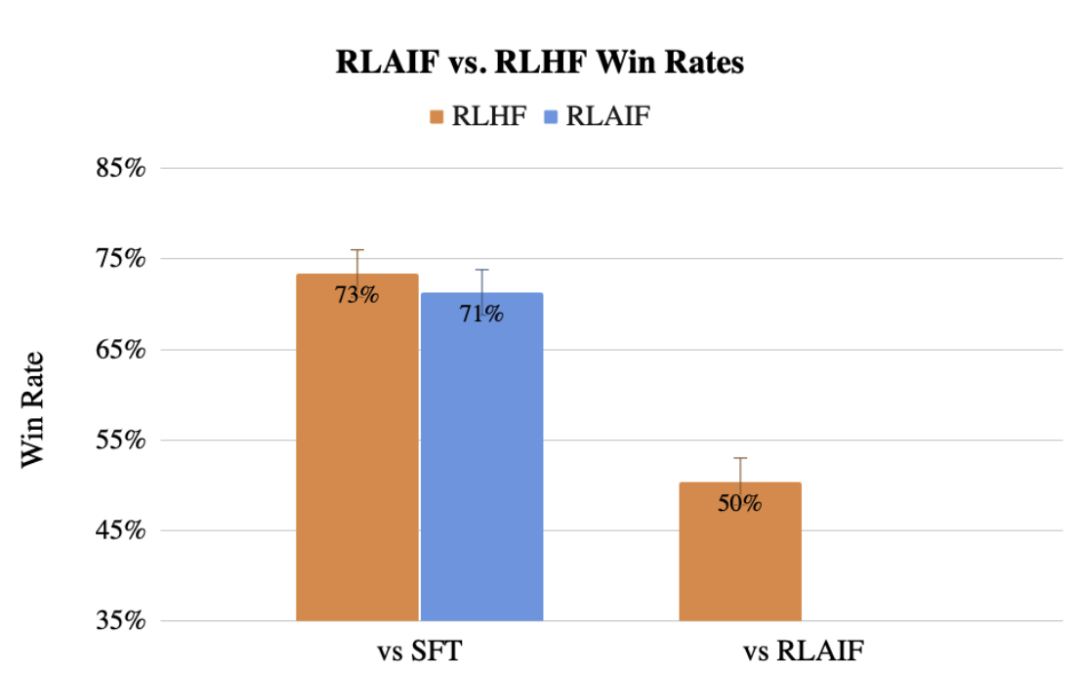
Google と MIT の研究者は、大規模なモデルから学習することで、実際のデータを使用してトレーニングされた最適なモデルを表現できることを発見しました。
この最新の方法は SynCLR と呼ばれ、実際のデータを一切使用せずに、合成画像と合成記述から完全に仮想表現を学習する方法です。

論文アドレス: https://arxiv.org/abs/2312.17742
実験結果SynCLR メソッドを通じて学習された表現は、ImageNet 上の OpenAI の CLIP の送信効果と同じくらい優れていることがわかります。
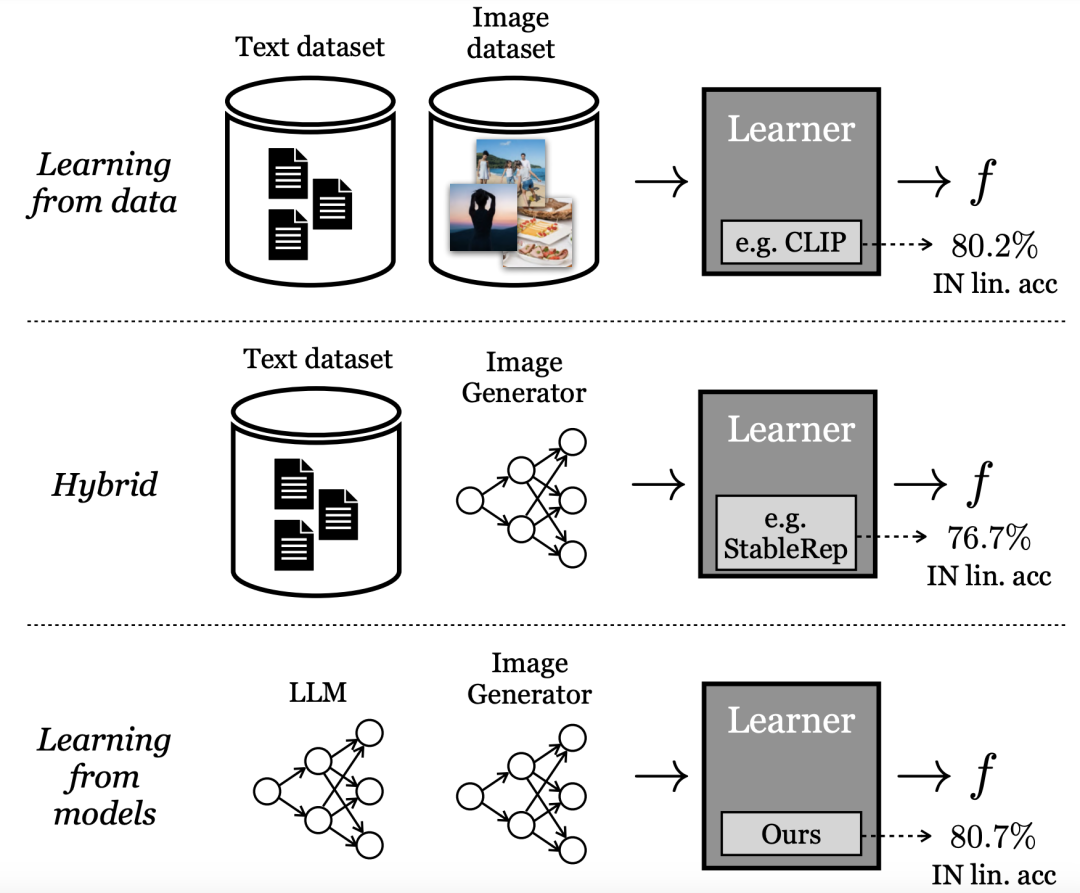
生成モデルからの学習
現在、最もパフォーマンスの高い「視覚的表現」学習方法は、大規模な実際のデータセットに依存しています。しかし、実際のデータを収集するには多くの困難があります。
データ収集コストを削減するために、この記事の研究者は次のような質問を投げかけます:
既製のものからサンプリングする生成モデル 合成データは、最先端の視覚表現をトレーニングするために大規模なデータセットをキュレーションするための実行可能な手段でしょうか?
データから直接学習するのとは異なり、Google 研究者はこのモデルを「モデルからの学習」と呼んでいます。大規模なトレーニング セットを構築するためのデータ ソースとして、モデルにはいくつかの利点があります。
- 潜在変数、条件変数、ハイパーパラメーターを通じてデータ管理のための新しい制御方法を提供します。
- モデルは共有や保存も簡単で (モデルはデータよりも圧縮しやすいため)、無制限の数のデータ サンプルを生成できます。
下流モデルをトレーニングするためのデータ ソースとしての生成モデルのこれらの特性やその他の利点と欠点を検討する文献が増えています。
これらの方法の一部は、ハイブリッド モデルを採用しています。つまり、実際のデータセットと合成データセットを混合するか、別の合成データセットを生成するために 1 つの実際のデータセットを必要とします。
他の方法は純粋に「合成データ」から表現を学習しようとしますが、最高のパフォーマンスを発揮するモデルには大きく遅れをとります。
論文では、研究者によって提案された最新の方法では、生成モデルを使用して視覚化クラスの粒度を再定義しています。
図 2 に示すように、2 つのヒントを使用して 4 つの写真が生成されました。「サングラスとビーチハットをかぶって自転車に乗っているゴールデン レトリバー」と「かわいいゴールデン レトリバー」です。お寿司でできた家で」。
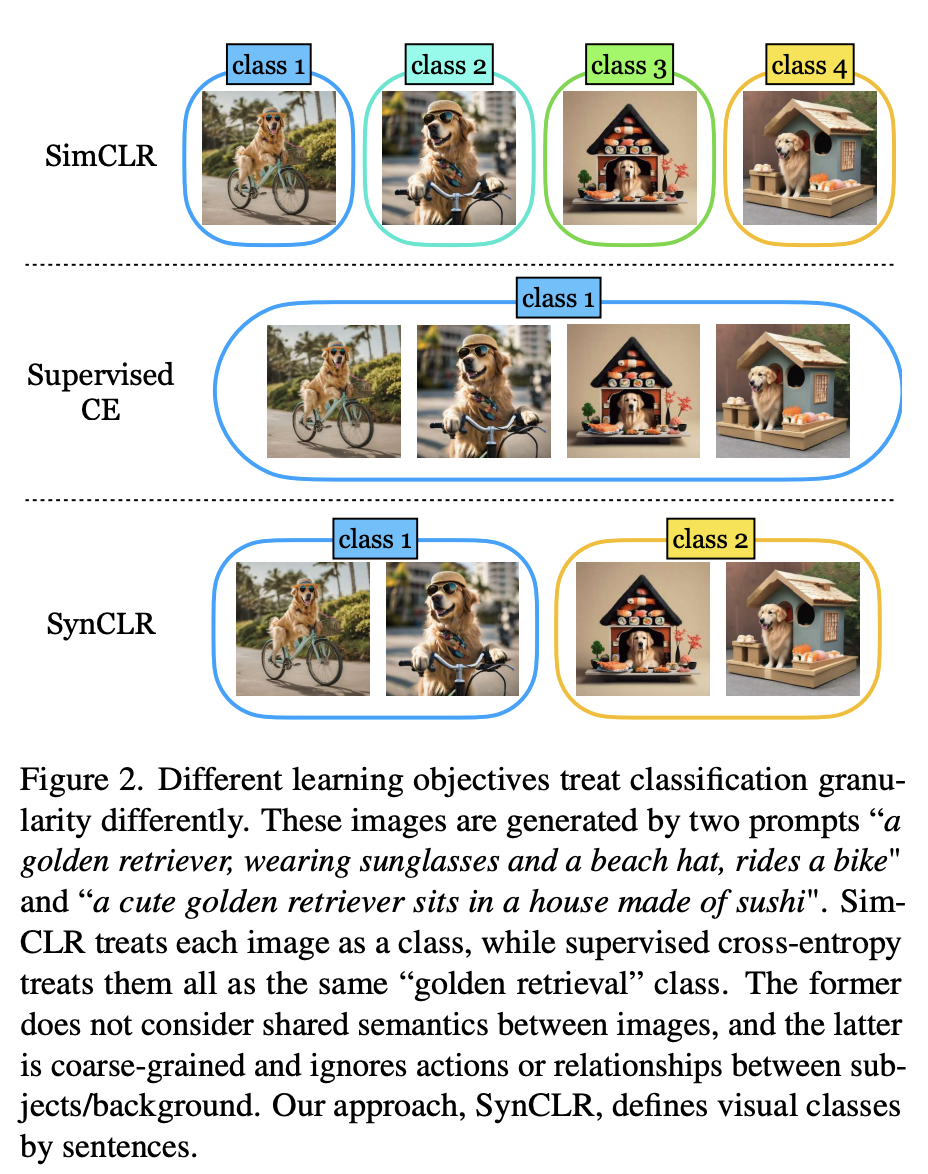
従来の自己教師ありメソッド (Sim-CLR など) は、これらのイメージを異なるクラスとして扱い、イメージ間の共有セマンティクスを明示的に考慮せずに、異なるイメージの埋め込みを分離します。
もう一方の極端な場合、教師あり学習方法 (つまり SupCE) は、これらすべての画像を 1 つのクラス (「ゴールデン レトリバー」など) として扱います。これは、ある画像では自転車に乗っている犬、別の画像では寿司屋に座っている犬など、画像の意味上のニュアンスを無視しています。
対照的に、SynCLR アプローチは説明をクラス、つまり説明ごとに 1 つのビジュアル クラスとして扱います。
このように、「自転車に乗っている」と「寿司屋に座っている」という 2 つのコンセプトに従って写真をグループ化できます。
この種の粒度を実際のデータでマイニングすることは困難です。これは、特定の説明によって複数の画像を収集するのが簡単ではないためです。特に説明の数が増加した場合にはそうであるからです。
ただし、テキストから画像への拡散モデルには基本的にこの機能があります。
同じ説明に基づいて条件付けし、異なるノイズ入力を使用するだけで、テキストから画像への拡散モデルは、同じ説明に一致する異なる画像を生成できます。
具体的には、著者らは実際の画像やテキスト データを使用せずにビジュアル エンコーダを学習する問題を研究しています。
最新の手法は、言語生成モデル (g1)、テキストから画像への生成モデル (g2)、視覚的概念の精選されたリストという 3 つの主要なリソースの利用に依存しています。 (c)。
前処理には 3 つのステップが含まれます:
(1) (g1) を使用して、包括的な画像記述 T のセットを合成します。 C のさまざまな視覚的概念;
#(2) T のタイトルごとに、(g2) を使用して複数の画像を生成し、最終的に広範な合成画像データセット X を生成します。 #(3) X をトレーニングして視覚表現エンコーダー f を取得します。
次に、推論速度が速い llama-27b を (g1) として、Stable Diffusion 1.5 を (g2) として使用します。
合成説明
強力なテキストから画像へのモデルの力を利用して大量のデータを生成するためトレーニング画像データ セットを使用するには、まず、画像を正確に記述するだけでなく、広範囲の視覚概念を包含する多様性を示す一連の記述が必要です。
これに応えて、著者らは、大規模モデルのコンテキスト学習機能を活用して、このような大規模な記述セットを作成するためのスケーラブルな方法を開発しました。
次に、合成テンプレートの 3 つの例を示します。
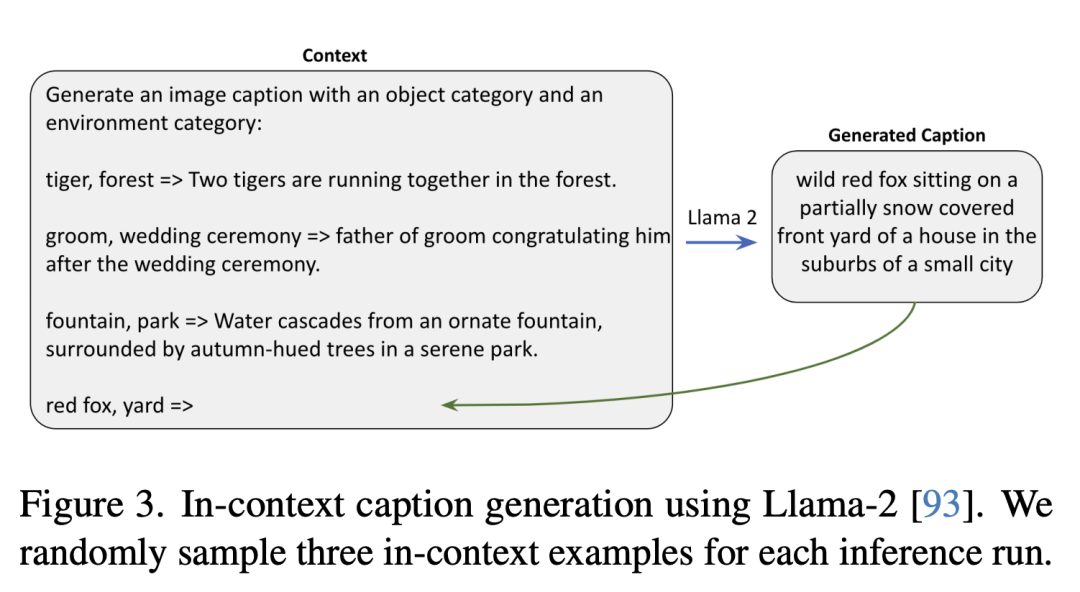
 次は、Llama-2 を使用して生成されたコンテキストの説明です。研究者は、推論の実行ごとに 3 つのコンテキストの例をランダムにサンプリングしました。
次は、Llama-2 を使用して生成されたコンテキストの説明です。研究者は、推論の実行ごとに 3 つのコンテキストの例をランダムにサンプリングしました。
 #合成画像
#合成画像
各テキストの説明について、研究者-拡散プロセスはさまざまなランダムノイズで開始され、さまざまな画像が生成されます。
このプロセスでは、分類子を使用しないブートストラップ (CFG) 比率が重要な要素となります。
CFG スケールが高いほど、サンプルの品質とテキストと画像の間の一貫性が向上します。一方、スケールが低いほど、サンプルの多様性は大きくなります。指定されたテキストに基づいた画像の元の条件付き分布に近づきます。
#表現学習
論文では、表現学習方法は次のとおりです。に基づく StableRep に基づく
著者らによって提案された方法の重要なコンポーネントは、同じ記述から生成された画像を (埋め込み空間内で) 整列させることによって機能するマルチポジティブ コントラスト学習損失です。
さらに、他の自己教師あり学習法のさまざまなテクニックも研究で組み合わせられました。
OpenAI の CLIP と比較可能
実験的評価では、研究者らはまずアブレーション研究を実施してパイプライン内のさまざまな設計とモジュールの有効性を評価し、その後合成量を拡大し続けました。データ。
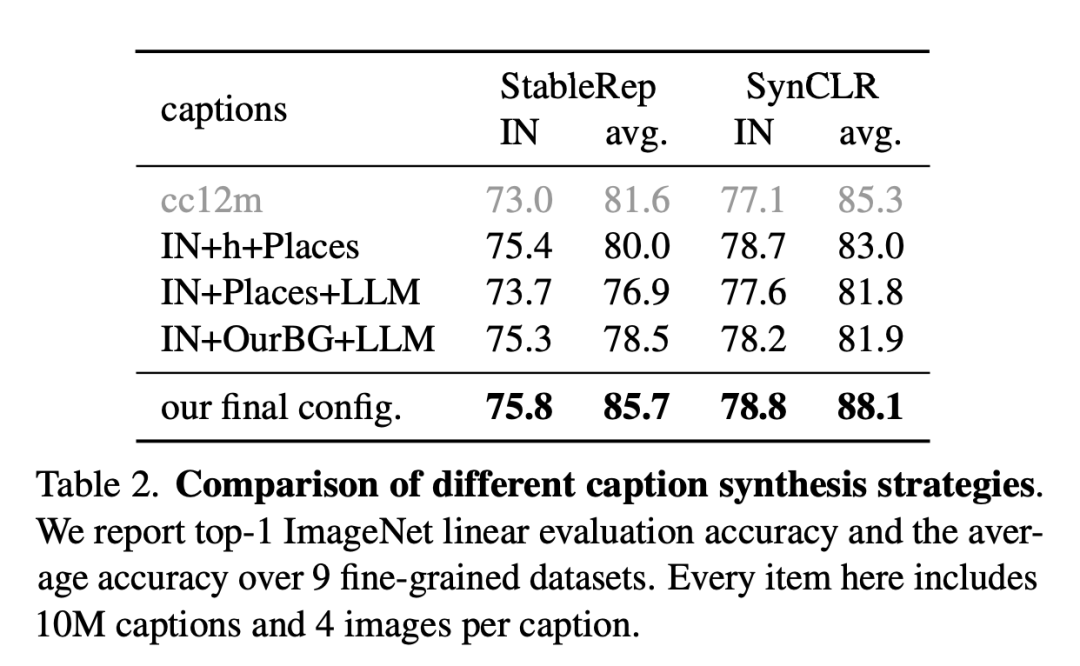
次の図は、さまざまな記述合成戦略の比較です。
研究者らは、9 つのきめ細かいデータセットに関する ImageNet の線形評価精度と平均精度を報告しています。ここの各アイテムには 1,000 万件の説明と、説明ごとに 4 枚の写真が含まれています。
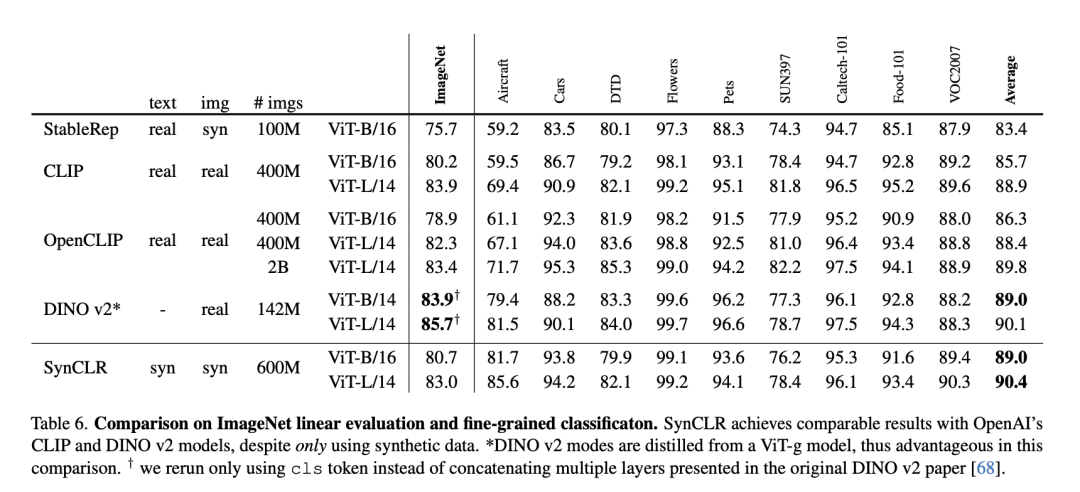
#次の表は、ImageNet の線形評価と詳細な分類の比較です。
SynCLR は、合成データのみを使用しているにもかかわらず、OpenAI の CLIP および DINO v2 モデルと同等の結果を達成しました。
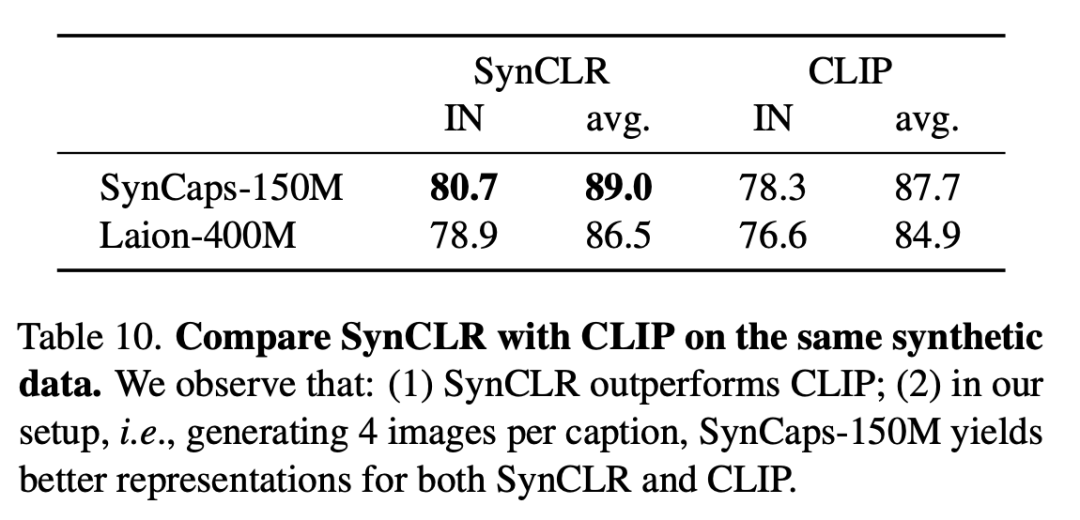
次の表では、同じ合成データに対する SynCLR と CLIP を比較しています。SynCLR が CLIP よりも大幅に優れていることがわかります。
具体的な設定は、タイトルごとに 4 つの画像を生成することです。SynCaps-150M は、SynCLR と CLIP の表現を向上させます。
DINO v2 と比較すると、SynCLR は車や飛行機の描画の精度が高くなりますが、描画可能な描画の精度は若干劣ります。
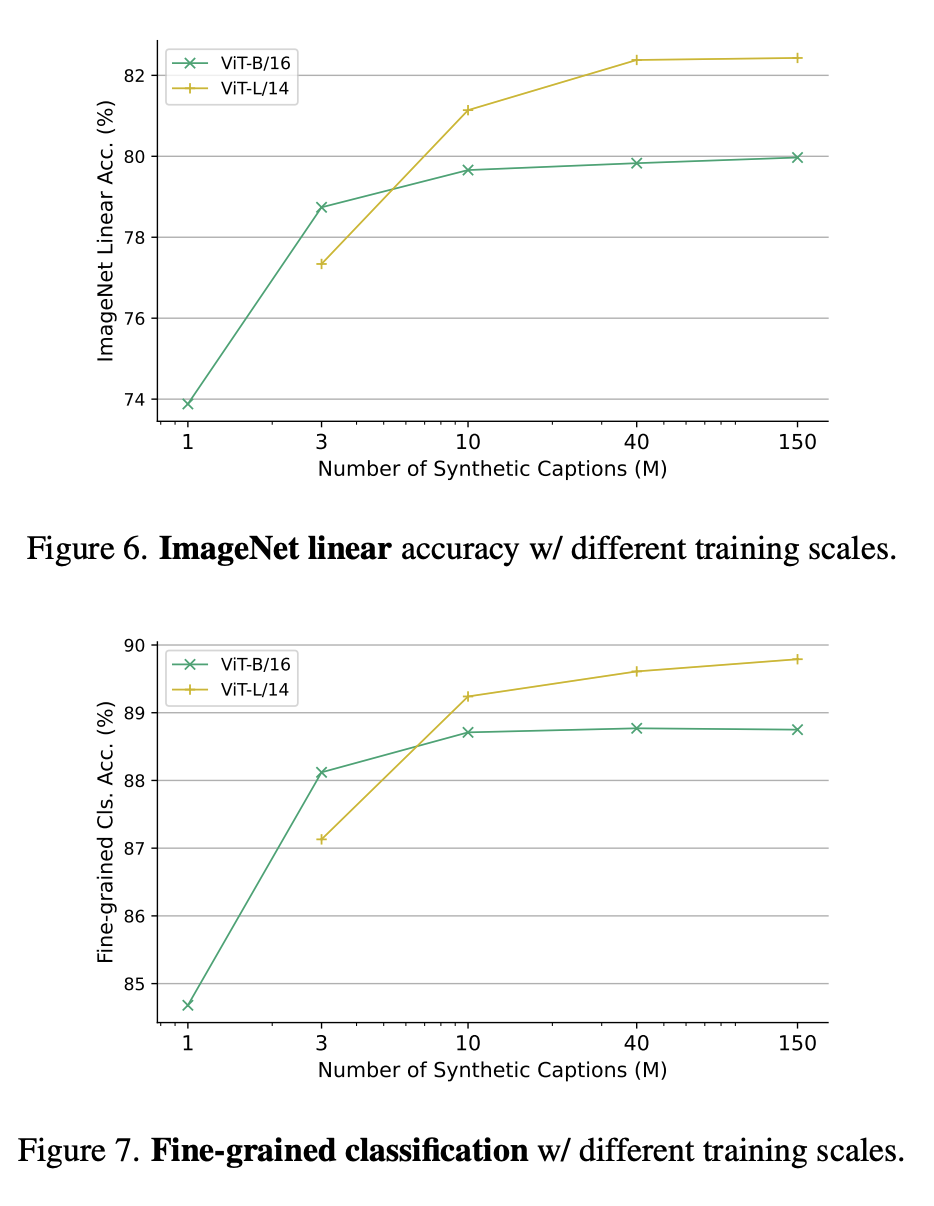
 # 図 6 と図 7 は、それぞれ、異なるトレーニング スケールでの ImageNet の線形精度と、異なるトレーニング パラメーター スケールでの詳細な分類を示しています。
# 図 6 と図 7 は、それぞれ、異なるトレーニング スケールでの ImageNet の線形精度と、異なるトレーニング パラメーター スケールでの詳細な分類を示しています。
 なぜ生成モデルから学ぶのでしょうか?
なぜ生成モデルから学ぶのでしょうか?
説得力のある理由の 1 つは、生成モデルは数百のデータ セットを同時に操作でき、トレーニング データを厳選する便利で効率的な方法を提供することです。
要約すると、最新の論文は、視覚表現学習の新しいパラダイム、つまり生成モデルからの学習を調査しています。
SynCLR は、実際のデータを一切使用せずに、最先端の汎用視覚表現学習器によって学習される視覚表現と同等の視覚表現を学習します。
以上がGoogle MIT の最新調査によると、高品質のデータを取得するのは難しくなく、大規模なモデルが解決策となりますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。