


ビデオ シーン グラフ生成 (VidSGG) は、ビジュアル シーン内のオブジェクトを識別し、オブジェクト間の視覚的な関係を推測することを目的としています。
このタスクでは、シーン全体に散在する各オブジェクトを包括的に理解するだけでなく、時間の経過に伴うそれらの動きや相互作用についての徹底的な研究も必要です。
最近、中山大学の研究者らは、人工知能のトップジャーナル IEEE T-IP に論文を発表しました。彼らは関連するタスクを調査し、次のことを発見しました。オブジェクトの組み合わせの各ペアと、それらの間の関係には、各画像内での空間的共起相関と、異なる画像間の時間的一貫性/翻訳相関があります。

論文リンク: https://arxiv.org/abs/2309.13237
これらに基づくまず、事前知識に基づいて、研究者らは、より代表的な視覚的関係表現を学習するために、事前の時空間知識をマルチヘッドクロスアテンションメカニズムに組み込むための、時空間知識埋め込みに基づくトランスフォーマー(STKET)を提案しました。
具体的には、空間的共起と時間的変換相関が最初に統計的に学習され、次に、時空間知識埋め込み層が視覚的表現と知識の間の相互作用を完全に探索するように設計されています。空間的および時間的な知識が埋め込まれた視覚的関係表現、最後に著者はこれらの特徴を集約して、最終的な意味ラベルとその視覚的関係を予測します。
広範な実験により、この記事で提案されているフレームワークが現在の競合アルゴリズムよりも大幅に優れていることが示されています。現在、論文は受理されました。
論文概要
シーン理解の分野の急速な発展に伴い、多くの研究者がシーンを解決するためにさまざまなフレームワークを使用しようと試み始めています。グラフ生成 (Scene Graph Generation (SGG) タスク) は大幅に進歩しました。
しかし、これらの手法は多くの場合、単一の画像の状況のみを考慮し、時系列に存在する大量のコンテキスト情報を無視するため、既存のシーン グラフ生成アルゴリズムのほとんどが機能しなくなります。特定のビデオに含まれる動的な視覚的関係を正確に識別します。
したがって、多くの研究者は、この問題を解決するためにビデオ シーン グラフ生成 (VidSGG) アルゴリズムの開発に取り組んでいます。
現在の研究は、空間的および時間的観点からオブジェクトレベルの視覚情報を集約して、対応する視覚的関係表現を学習することに焦点を当てています。
ただし、さまざまなオブジェクトやインタラクティブなアクションの視覚的な外観には大きなばらつきがあり、ビデオ収集によって引き起こされる視覚的な関係の大幅なロングテール分布のため、視覚情報だけを使用するだけでは、モデル予測につながりやすい 誤った視覚的関係。
上記の問題に対応して、研究者は次の 2 つの側面から作業を行いました。
まず、以前のデータをマイニングすることが提案されています。トレーニング サンプルに含まれる時空間に関する知識は、ビデオ シーン グラフ生成の分野を進歩させるために使用されます。その中で、アプリオリな時空間知識には次のものが含まれます。
1) 空間的共起相関: 特定のオブジェクト カテゴリ間の関係は、特定の相互作用を引き起こす傾向があります。
2) 時間的一貫性/遷移の相関: 特定の関係のペアは、連続するビデオ クリップ全体で一貫している傾向があるか、別の特定の関係に遷移する可能性が高くなります。
第二に、時空間知識埋め込みに基づく新しいトランスフォーマー (空間時間知識埋め込みトランスフォーマー、STKET) フレームワークが提案されます。
このフレームワークは、より代表的な視覚的関係表現を学習するために、事前の時空間知識をマルチヘッド相互注意メカニズムに組み込んでいます。テストベンチマークで得られた比較結果によると、研究者によって提案された STKET フレームワークが以前の最先端の方法よりも優れていることがわかります。

#図 1: 視覚的な外観の変化と視覚的な関係のロングテール分布により、ビデオ シーン グラフの生成は課題に満ちています
時空間知識埋め込みに基づくトランスフォーマー空間的および時間的知識表現
視覚的な関係を推論するとき、人間は視覚的な手がかりだけを使用するわけではありませんだけでなく、蓄積された事前知識、経験的知識も使用します [1、2]。これに触発されて、研究者らは、ビデオ シーン グラフの生成タスクを容易にするために、トレーニング セットから事前の時空間知識を直接抽出することを提案しています。
このうち、空間共起相関は、ある物体を組み合わせると、その視覚的関係の分布が大きく偏ることに具体的に現れます(例えば、「人」と「人」との視覚的関係の分布)。 「カップ」は「犬」と「おもちゃ」の分布とは明らかに異なります)と時間転移相関は、直前の瞬間の視覚関係が与えられると、それぞれの視覚関係の遷移確率が大きく変化するという点で具体的に現れます(たとえば、例えば、直前の瞬間の視覚関係がわかっている場合(「食べる」の場合、次の瞬間に視覚関係が「書く」に移行する確率は大幅に低くなる)。
図 2 に示すように、特定のオブジェクトの組み合わせや以前の視覚的な関係を直感的に感じることができるようになると、予測スペースを大幅に縮小できます。

#図 2: 視覚的関係の空間的共起確率 [3] と時間的遷移確率
# # 具体的には、i 型オブジェクトと j 型オブジェクトの組み合わせと、直前の i 型オブジェクトと j 型オブジェクトの関係について、対応する空間的共起確率を行列 E^{i,j はまず統計的に求められます } と時間遷移確率行列 Ex^{i,j} が求められます。
次に、それを全結合層に入力して対応する特徴表現を取得し、対応する目的関数を使用して、モデルによって学習された知識表現に対応する事前の時空間知識が含まれていることを確認します。 . .

図 3: 空間 (a) および時間 (b) の知識表現を学習するプロセス
知識の埋め込み注: フォース レイヤー空間知識には、通常、エンティティ間の位置、距離、関係に関する情報が含まれています。一方、時間的知識には、アクションの順序、期間、間隔が含まれます。
それらの固有の特性を考慮すると、それらを個別に扱うことで、特殊なモデリングで固有のパターンをより正確に捉えることができます。
したがって、研究者らは、視覚表現と時空間知識の間の相互作用を徹底的に調査するために、時空間知識埋め込み層を設計しました。
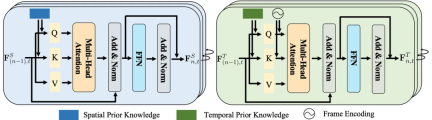
図 4: 空間 (左) と時間 (右) 知識埋め込み層
時空間集約モジュール上で述べたように、空間知識埋め込み層は各画像内の空間的共起相関を調査し、時間知識埋め込み層は異なる画像間の時間伝達相関を調査することで、視覚間の相互作用を完全に調査します。表現と時空間知識。
にもかかわらず、これら 2 つのレイヤーは長期的なコンテキスト情報を無視します。これは、最も動的に変化する視覚的な関係を識別するのに役立ちます。
この目的を達成するために、研究者らはさらに、各オブジェクト ペアの表現を集約して最終的な意味ラベルとその関係を予測する時空間集約 (STA) モジュールを設計しました。これは、異なるフレーム内の同じ被写体とオブジェクトのペアの空間的および時間的に埋め込まれた関係表現を入力として受け取ります。
具体的には、研究者らは、同じオブジェクトのペアのこれらの表現を連結して、コンテキスト表現を生成しました。
次に、異なるフレームで同じ被写体とオブジェクトのペアを見つけるために、予測されたオブジェクト ラベルと IoU (つまり和集合の交差) が採用され、フレーム内で検出された同じ被写体とオブジェクトのペアと一致します。フレーム。
最後に、フレーム内の関係がバッチごとに異なる表現を持つことを考慮して、スライディング ウィンドウ内の最も古い表現が選択されます。
実験結果提案されたフレームワークのパフォーマンスを総合的に評価するために、研究者らは既存のビデオシーングラフ生成手法(STTran)と比較しました。 、TPI、APT)、高度な画像シーングラフ生成方法(KERN、VCTREE、ReIDN、GPS-Net)も比較のために選択されました。
その中で、公平な比較を保証するために、画像シーングラフ生成方法は、画像の各フレームを識別することによって、特定のビデオに対応するシーングラフを生成するという目標を達成します。
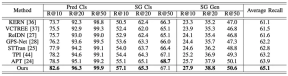
図 5: アクション ゲノム データ セットの評価指標として再現率を使用した実験結果

図 6: アクション ゲノム データ セットの評価指標として平均再現率を使用した実験結果
以上が中山大学の新しい時空間知識埋め込みフレームワークは、TIP '24 で公開されたビデオ シーン グラフ生成タスクの最新の進歩を推進しますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 解读CRISP-ML(Q):机器学习生命周期流程Apr 08, 2023 pm 01:21 PM
解读CRISP-ML(Q):机器学习生命周期流程Apr 08, 2023 pm 01:21 PM译者 | 布加迪审校 | 孙淑娟目前,没有用于构建和管理机器学习(ML)应用程序的标准实践。机器学习项目组织得不好,缺乏可重复性,而且从长远来看容易彻底失败。因此,我们需要一套流程来帮助自己在整个机器学习生命周期中保持质量、可持续性、稳健性和成本管理。图1. 机器学习开发生命周期流程使用质量保证方法开发机器学习应用程序的跨行业标准流程(CRISP-ML(Q))是CRISP-DM的升级版,以确保机器学习产品的质量。CRISP-ML(Q)有六个单独的阶段:1. 业务和数据理解2. 数据准备3. 模型
 人工智能的环境成本和承诺Apr 08, 2023 pm 04:31 PM
人工智能的环境成本和承诺Apr 08, 2023 pm 04:31 PM人工智能(AI)在流行文化和政治分析中经常以两种极端的形式出现。它要么代表着人类智慧与科技实力相结合的未来主义乌托邦的关键,要么是迈向反乌托邦式机器崛起的第一步。学者、企业家、甚至活动家在应用人工智能应对气候变化时都采用了同样的二元思维。科技行业对人工智能在创建一个新的技术乌托邦中所扮演的角色的单一关注,掩盖了人工智能可能加剧环境退化的方式,通常是直接伤害边缘人群的方式。为了在应对气候变化的过程中充分利用人工智能技术,同时承认其大量消耗能源,引领人工智能潮流的科技公司需要探索人工智能对环境影响的
 找不到中文语音预训练模型?中文版 Wav2vec 2.0和HuBERT来了Apr 08, 2023 pm 06:21 PM
找不到中文语音预训练模型?中文版 Wav2vec 2.0和HuBERT来了Apr 08, 2023 pm 06:21 PMWav2vec 2.0 [1],HuBERT [2] 和 WavLM [3] 等语音预训练模型,通过在多达上万小时的无标注语音数据(如 Libri-light )上的自监督学习,显著提升了自动语音识别(Automatic Speech Recognition, ASR),语音合成(Text-to-speech, TTS)和语音转换(Voice Conversation,VC)等语音下游任务的性能。然而这些模型都没有公开的中文版本,不便于应用在中文语音研究场景。 WenetSpeech [4] 是
 条形统计图用什么呈现数据Jan 20, 2021 pm 03:31 PM
条形统计图用什么呈现数据Jan 20, 2021 pm 03:31 PM条形统计图用“直条”呈现数据。条形统计图是用一个单位长度表示一定的数量,根据数量的多少画成长短不同的直条,然后把这些直条按一定的顺序排列起来;从条形统计图中很容易看出各种数量的多少。条形统计图分为:单式条形统计图和复式条形统计图,前者只表示1个项目的数据,后者可以同时表示多个项目的数据。
 自动驾驶车道线检测分类的虚拟-真实域适应方法Apr 08, 2023 pm 02:31 PM
自动驾驶车道线检测分类的虚拟-真实域适应方法Apr 08, 2023 pm 02:31 PMarXiv论文“Sim-to-Real Domain Adaptation for Lane Detection and Classification in Autonomous Driving“,2022年5月,加拿大滑铁卢大学的工作。虽然自主驾驶的监督检测和分类框架需要大型标注数据集,但光照真实模拟环境生成的合成数据推动的无监督域适应(UDA,Unsupervised Domain Adaptation)方法则是低成本、耗时更少的解决方案。本文提出对抗性鉴别和生成(adversarial d
 数据通信中的信道传输速率单位是bps,它表示什么Jan 18, 2021 pm 02:58 PM
数据通信中的信道传输速率单位是bps,它表示什么Jan 18, 2021 pm 02:58 PM数据通信中的信道传输速率单位是bps,它表示“位/秒”或“比特/秒”,即数据传输速率在数值上等于每秒钟传输构成数据代码的二进制比特数,也称“比特率”。比特率表示单位时间内传送比特的数目,用于衡量数字信息的传送速度;根据每帧图像存储时所占的比特数和传输比特率,可以计算数字图像信息传输的速度。
 数据分析方法有哪几种Dec 15, 2020 am 09:48 AM
数据分析方法有哪几种Dec 15, 2020 am 09:48 AM数据分析方法有4种,分别是:1、趋势分析,趋势分析一般用于核心指标的长期跟踪;2、象限分析,可依据数据的不同,将各个比较主体划分到四个象限中;3、对比分析,分为横向对比和纵向对比;4、交叉分析,主要作用就是从多个维度细分数据。
 聊一聊Python 实现数据的序列化操作Apr 12, 2023 am 09:31 AM
聊一聊Python 实现数据的序列化操作Apr 12, 2023 am 09:31 AM在日常开发中,对数据进行序列化和反序列化是常见的数据操作,Python提供了两个模块方便开发者实现数据的序列化操作,即 json 模块和 pickle 模块。这两个模块主要区别如下:json 是一个文本序列化格式,而 pickle 是一个二进制序列化格式;json 是我们可以直观阅读的,而 pickle 不可以;json 是可互操作的,在 Python 系统之外广泛使用,而 pickle 则是 Python 专用的;默认情况下,json 只能表示 Python 内置类型的子集,不能表示自定义的


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

VSCode Windows 64 ビットのダウンロード
Microsoft によって発売された無料で強力な IDE エディター

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)

MantisBT
Mantis は、製品の欠陥追跡を支援するために設計された、導入が簡単な Web ベースの欠陥追跡ツールです。 PHP、MySQL、Web サーバーが必要です。デモおよびホスティング サービスをチェックしてください。

メモ帳++7.3.1
使いやすく無料のコードエディター

SAP NetWeaver Server Adapter for Eclipse
Eclipse を SAP NetWeaver アプリケーション サーバーと統合します。
ホットトピック
 7443
7443 15137152
15137152