



あなたと友達が冷たいモバイル画面越しにチャットしているときは、相手の口調を推測する必要があります。彼が話すとき、彼の表情や行動さえもあなたの心に現れます。もちろんビデオ通話ができれば一番良いのですが、実際はいつでもビデオ通話ができるわけではありません。
遠隔地の友人とチャットしている場合、それは冷たい画面のテキストや表情のないアバターではなく、リアルでダイナミックで表現力豊かなデジタル仮想人物です。この仮想人物は、友人の笑顔、目、微妙な体の動きさえも完璧に再現することができます。もっと優しくて温かい気持ちになれるでしょうか?これはまさに「ネットワークケーブルに沿って這ってあなたを見つけます」という文を体現しています。
これは SF の空想ではなく、現実に実現可能なテクノロジーです。
表情や体の動きには多くの情報が含まれており、内容の意味に大きく影響します。例えば、常に相手の目を見ながら話すのと、目を合わせずに話すのでは全く違う印象を与えますし、相手のコミュニケーション内容の理解にも影響します。私たちは、コミュニケーション中にこれらの微妙な表情や動作を検出し、それらを使用して会話相手の意図、快適さのレベル、理解度を高度に理解する非常に鋭い能力を持っています。したがって、これらの微妙な点を捉えた非常に現実的な会話アバターを開発することは、インタラクションにとって重要です。
この目的を達成するために、Meta とカリフォルニア大学の研究者は、2 人の会話の音声に基づいて現実的な仮想人間を生成する方法を提案しました。音声と密接に同期したさまざまな高周波ジェスチャーや表情豊かな顔の動きを合成できます。体と手には、自己回帰 VQ ベースのアプローチと拡散モデルの利点が活用されています。顔については、音声を条件とした拡散モデルを使用します。予測された顔、体、手の動きは、現実的な仮想人間にレンダリングされます。我々は、拡散モデルにガイド付きジェスチャー条件を追加すると、以前の研究よりも多様で合理的な会話ジェスチャーを生成できることを実証します。

- 論文アドレス: https://huggingface.co/papers/2401.01885
- # プロジェクトのアドレス: https://people.eecs.berkeley.edu/~ebonne_ng/projects/audio2photoreal/
研究者らは、対人会話のためのリアルな顔、体、手の動きを生成する方法を研究した最初のチームであると述べています。以前の研究と比較して、研究者らは VQ と拡散法に基づいて、より現実的で多様なアクションを合成しました。
方法の概要
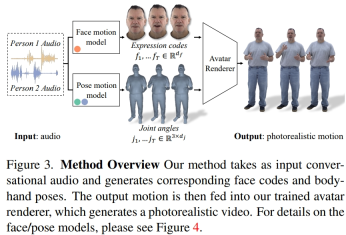
研究者らは、記録されたマルチビューデータから潜在的な表情コードを抽出して顔を表現し、運動学的骨格の関節角度を使用して、体の姿勢を表現します。図 3 に示すように、本システムは 2 人の会話音声を入力すると表情コードと体位系列を生成する 2 つの生成モデルから構成されます。表情コードと体のポーズ シーケンスは、ニューラル アバター レンダラーを使用してフレームごとにレンダリングでき、特定のカメラ ビューから顔、体、手を備えた完全にテクスチャ化されたアバターを生成できます。
顔の動きモデルは、入力オーディオと、事前にトレーニングされた唇のリグレッサーによって生成された唇の頂点に条件付けされた拡散モデルです (図 4a)。手足の動きのモデルについて、研究者らは、音声のみを条件とした純粋な拡散モデルによって生成された動きは多様性に欠けており、時系列で十分に調整されていないことを発見しました。しかし、研究者がさまざまな指導姿勢を条件にすると、品質は向上しました。したがって、彼らは身体運動モデルを 2 つの部分に分割しました。まず、自己回帰オーディオ コンディショナーが 1 fp で粗い誘導ポーズを予測し (図 4b)、次に拡散モデルがこれらの粗い誘導ポーズを利用して、きめの細かい高精度の誘導ポーズを埋めます。周波数の動き(図4c)。メソッド設定の詳細については、元の記事を参照してください。 研究者らは、実際の音声に基づいてリアルな対話アクションを生成する Audio2Photoreal の有効性を定量的に評価しました。データ能力。定量的な結果を裏付け、特定の会話コンテキストでジェスチャを生成する際の Audio2Photoreal の適切性を測定するために、知覚評価も実行されました。実験結果は、ジェスチャが 3D メッシュではなく現実的なアバター上で提示された場合に、評価者が微妙なジェスチャに対してより敏感になることを示しました。 研究者らは、この手法の生成結果を、トレーニング セット内のランダム モーション シーケンスに基づく 3 つのベースライン手法 (KNN、SHOW、および LDA) と比較しました。アブレーション実験は、音声またはガイド付きジェスチャーなし、ガイド付きジェスチャーなしで音声に基づく、音声なしでガイド付きジェスチャーに基づく Audio2Photoreal の各コンポーネントの有効性をテストするために実施されました。 定量的結果 表 1 は、以前の研究と比較して、この方法が世代の多様性が最も高いことを示しています。 FD スコアは運動時に最も低くなります。ランダムは GT と一致する優れた多様性を持っていますが、ランダム セグメントは対応する会話のダイナミクスと一致しないため、FD_g が高くなります。 # 図 5 は、私たちの方法によって生成された誘導ポーズの多様性を示しています。 VQ ベースのトランスフォーマー P サンプリングにより、同じオーディオ入力で非常に異なるジェスチャを生成できます。
対話におけるジェスチャーの一貫性により、定量的に評価することは難しいため、研究者らは評価に定性的な方法を使用しました。彼らは MTurk で 2 セットの A/B テストを実施しました。具体的には、評価者に、私たちの手法とベースライン手法で生成された結果、または私たちの手法と実際のシーンのビデオのペアを見て、どのビデオの動きがより合理的に見えるかを評価するように依頼しました。 図 8 に示すように、この方法は以前のベースライン方法 LDA よりも大幅に優れており、レビュー担当者の約 70% がグリッドとリアリズムの点で Audio2Photoreal を好みます。 図 8 の上部のグラフに示すように、LDA と比較して、この手法に対する評価者の評価は「やや好き」から「非常に好き」に変化しました。現実と比較しても同様の評価が示されている。それでも、評価者はリアリズムに関しては、Audio2Photoreal よりも本物を支持しました。 技術的な詳細については、元の論文をお読みください。 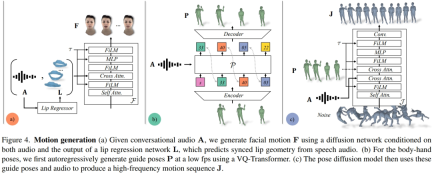
実験と結果


 # 図 7 は、LDA によって生成されたモーションにはエネルギーが不足しており、動きが少ないことを示しています。対照的に、この方法によって合成された動きの変化は、実際の状況とより一致しています。
# 図 7 は、LDA によって生成されたモーションにはエネルギーが不足しており、動きが少ないことを示しています。対照的に、この方法によって合成された動きの変化は、実際の状況とより一致しています。 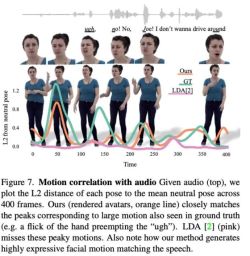 さらに、研究者らは、唇の動きを生成する際のこの方法の精度も分析しました。表 2 の統計が示すように、Audio2Photoreal はベースライン メソッド SHOW を大幅に上回っており、アブレーション実験で事前学習された唇リグレッサーを除去した後のパフォーマンスも大幅に上回っています。この設計により、話すときの口の形状の同期が改善され、話していないときの口のランダムな開閉の動きが効果的に回避され、モデルがより適切に唇の動きを再構築できるようになり、同時に顔のメッシュ頂点 (グリッド L2) のエラーが減少します。 。
さらに、研究者らは、唇の動きを生成する際のこの方法の精度も分析しました。表 2 の統計が示すように、Audio2Photoreal はベースライン メソッド SHOW を大幅に上回っており、アブレーション実験で事前学習された唇リグレッサーを除去した後のパフォーマンスも大幅に上回っています。この設計により、話すときの口の形状の同期が改善され、話していないときの口のランダムな開閉の動きが効果的に回避され、モデルがより適切に唇の動きを再構築できるようになり、同時に顔のメッシュ頂点 (グリッド L2) のエラーが減少します。 。  #定性的評価
#定性的評価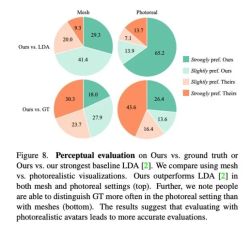
以上がネットワークケーブルに沿って登るのが現実となり、対話を通じてリアルな表現や動きを生成できるAudio2Photorealの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 服装無料ポルノAIツールWebサイトMay 13, 2025 am 11:26 AM
服装無料ポルノAIツールWebサイトMay 13, 2025 am 11:26 AMhttps://undressaitool.ai/は、アダルトコンテンツ向けの高度なAI機能を備えた強力なモバイルアプリです。今すぐAIに生成されたポルノ画像やビデオを作成してください!
 服装を使用してポルノ画像/ビデオを作成する方法May 13, 2025 am 11:26 AM
服装を使用してポルノ画像/ビデオを作成する方法May 13, 2025 am 11:26 AM服を使用してポルノ写真/ビデオを作成するためのチュートリアル:1。対応するツールWebリンクを開きます。 2。[ツール]ボタンをクリックします。 3.ページプロンプトに従って、生産に必要なコンテンツをアップロードします。 4.結果を保存してお楽しみください。
 AIの公式ウェブサイトの入り口のウェブサイトの住所May 13, 2025 am 11:26 AM
AIの公式ウェブサイトの入り口のウェブサイトの住所May 13, 2025 am 11:26 AM脱衣AIの公式アドレスは次のとおりです。https://undressaitool.ai/; Undressaiは、成人コンテンツの高度なAI機能を備えた強力なモバイルアプリです。今すぐAIに生成されたポルノ画像やビデオを作成してください!
 服装はどのようにポルノ画像/ビデオを生成しますか?May 13, 2025 am 11:26 AM
服装はどのようにポルノ画像/ビデオを生成しますか?May 13, 2025 am 11:26 AM服を使用してポルノ写真/ビデオを作成するためのチュートリアル:1。対応するツールWebリンクを開きます。 2。[ツール]ボタンをクリックします。 3.ページプロンプトに従って、生産に必要なコンテンツをアップロードします。 4.結果を保存してお楽しみください。
 服装ポルノAI公式ウェブサイトの住所May 13, 2025 am 11:26 AM
服装ポルノAI公式ウェブサイトの住所May 13, 2025 am 11:26 AM脱衣AIの公式アドレスは次のとおりです。https://undressaitool.ai/; Undressaiは、成人コンテンツの高度なAI機能を備えた強力なモバイルアプリです。今すぐAIに生成されたポルノ画像やビデオを作成してください!
 服装使用チュートリアルガイド記事May 13, 2025 am 10:43 AM
服装使用チュートリアルガイド記事May 13, 2025 am 10:43 AM服を使用してポルノ写真/ビデオを作成するためのチュートリアル:1。対応するツールWebリンクを開きます。 2。[ツール]ボタンをクリックします。 3.ページプロンプトに従って、生産に必要なコンテンツをアップロードします。 4.結果を保存してお楽しみください。
 【AIでジブリ風画像】ChatGPTで無料の画像生成のやり方と著作権を紹介May 13, 2025 am 01:57 AM
【AIでジブリ風画像】ChatGPTで無料の画像生成のやり方と著作権を紹介May 13, 2025 am 01:57 AMOpenAIがリリースした最新のモデルGPT-4Oは、テキストを生成できるだけでなく、広範囲にわたる注目を集めている画像生成関数も備えています。最も人目を引く機能は、「ギブリスタイルのイラスト」の生成です。写真をChatGptにアップロードし、簡単な指示を提供して、Studio Ghibliで作品のような夢のような画像を生成します。この記事では、実際の操作プロセス、効果エクスペリエンス、および注意が必要なエラーと著作権の問題について詳しく説明します。 Openaiがリリースした最新モデル「O3」の詳細については、ここをクリックしてください Openai O3(ChatGpt O3)の詳細な説明:機能、価格設定システム、O4-Miniはじめに Ghibliスタイルの記事の英語版については、ここをクリックしてください⬇ chatgptでjiを作成します
 自治体におけるChatGPTの活用・導入事例を解説!禁止した自治体も紹介May 13, 2025 am 01:53 AM
自治体におけるChatGPTの活用・導入事例を解説!禁止した自治体も紹介May 13, 2025 am 01:53 AM新しいコミュニケーション手法として、自治体におけるChatGPTの活用・導入が注目を集めています。 幅広い地域でその動きが進む一方で、中にはChatGPTの利用を見送った自治体もあります。 本記事では、自治体でのChatGPT導入事例を紹介していきます。文書作成の支援や市民との対話等、多彩な改革事例を通じて、自治体サービスの質的向上及び効率化をいかに実現しているかについて掘り下げていきます。 職員の業務負担軽減や市民の利便性向上を目指す自治体担当者はもちろん、先進的な活用事例に関心のあるすべての


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

EditPlus 中国語クラック版
サイズが小さく、構文の強調表示、コード プロンプト機能はサポートされていません

PhpStorm Mac バージョン
最新(2018.2.1)のプロフェッショナル向けPHP統合開発ツール

SublimeText3 Linux 新バージョン
SublimeText3 Linux 最新バージョン

WebStorm Mac版
便利なJavaScript開発ツール

ZendStudio 13.5.1 Mac
強力な PHP 統合開発環境

