


大型モデルの優れた性能は誰の目にも明らかであり、これらがロボットに統合されれば、ロボットの頭脳がより賢くなり、自動運転や家庭用ロボットなど、ロボティクス分野に新たな可能性をもたらすことが期待されます。 、産業用ロボット、支援ロボット、医療用ロボット、フィールドロボット、マルチロボットシステム。
事前トレーニング済みの大規模言語モデル (LLM)、大規模視覚言語モデル (VLM)、大規模音声言語モデル (ALM)、および大規模ビジュアル ナビゲーション モデル (VNM) を使用して、ロボットのさまざまなタスクをより適切に処理できます。現場で。基本モデルをロボット工学に統合することは急速に成長している分野であり、ロボット工学コミュニティは最近、認識、予測、計画、制御といった書き換えが必要なロボット工学分野でこれらの大規模モデルの使用を検討し始めています。
最近、スタンフォード大学、プリンストン大学、NVIDIA、Google DeepMind などの企業で構成される共同研究チームが、ロボット研究分野における基本モデルの開発と将来をまとめたレビューレポートを発表しました。

- 論文アドレス: https://arxiv.org/pdf/2312.07843.pdf
- 書き換えられた内容は次のとおりです。 : 論文ライブラリ: https://github.com/robotics-survey/Awesome-Robotics-Foundation-Models
基本モデルから知識を転送すると、タスク固有のモデルと比較してトレーニング時間とコンピューティング リソースを削減できる可能性があります。特にロボット関連の分野では、マルチモーダルベースモデルは、さまざまなセンサーから収集されたマルチモーダルな異種データを融合して整列させ、ロボットの理解と推論に必要なコンパクトな均質な表現にすることができます。学習した表現は、認識、意思決定、制御など、書き換えが必要なものを含め、自動化テクノロジー スタックのあらゆる部分で使用できます。 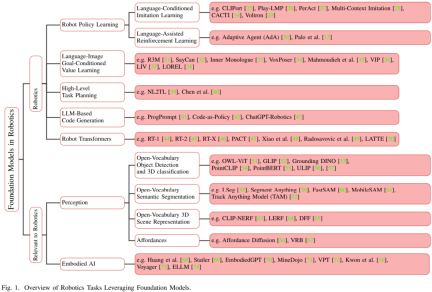
操作、ナビゲーション、インタラクションに関連する言語の手がかりを活用することで、ロボットはより複雑なタスクを実行できます。たとえば、模倣学習や強化学習などのロボットポリシー学習技術の場合、基本モデルにはデータ効率とコンテキスト理解を向上させる機能があるようです。特に、言語駆動型の報酬は、成形された報酬を提供することで強化学習エージェントを導くことができます。
さらに、研究者たちはすでに言語モデルを使用して戦略学習テクノロジーにフィードバックを提供しています。いくつかの研究では、VLM モデルのビジュアル質問応答 (VQA) 機能がロボット工学のユースケースに使用できることが示されています。たとえば、研究者は VLM を使用して視覚コンテンツに関連する質問に答え、ロボットがタスクを完了できるようにしました。さらに、一部の研究者は VLM を使用してデータの注釈を支援し、ビジュアル コンテンツの説明ラベルを生成します。視覚および言語処理における基本モデルの変革的な機能にもかかわらず、現実世界のロボットタスクのための基本モデルの一般化と微調整は依然として困難です。
これらの課題には以下が含まれます:
1) データ不足: ロボットの操作、位置決め、ナビゲーションなどのタスクをサポートするインターネット規模のデータを取得する方法、およびこれらのデータを自分自身で使用する方法-教師ありトレーニング;
2) 巨大な多様性: 基盤となるモデルに必要な一般性を維持しながら、物理環境、物理的なロボット プラットフォーム、および潜在的なロボット タスクの巨大な多様性にどのように対処するか;
3) 不確実な定量的問題: インスタンスレベルの不確実性 (言語の曖昧さ、LLM の錯覚など)、分布レベルの不確実性、および分布シフト問題、特に閉ループロボットの導入によって引き起こされる分布シフト問題を解決する方法。
4) 安全性評価: 導入前、更新プロセス中、および作業プロセス中に、基本モデルに基づいてロボット システムを厳密にテストする方法。
5) リアルタイム パフォーマンス: 一部の基本モデルの長い推論時間に対処する方法 - これはロボットへの基本モデルの展開の妨げになります、および基本モデルの推論を高速化する方法 - これはオンラインでの意思決定の鍵が必要です。
このレビュー ペーパーは、ロボット工学の分野における基本モデルの現在の使用法を要約しています。研究者は現在の方法、応用、課題を調査し、これらの課題に対処するための将来の研究の方向性を提案します。また、ロボットの自律性を実現するためにベース モデルを使用する場合に存在する可能性がある潜在的なリスクも指摘しました。
ベース モデルの背景知識
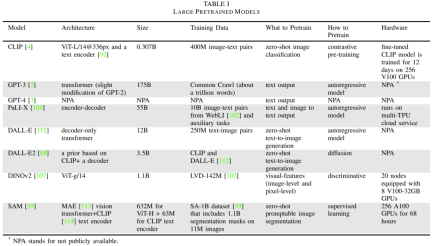
ベース モデルには数十億のパラメータがあります。 、インターネットレベルの大規模データを事前トレーニングに使用します。このような大規模で複雑なモデルのトレーニングには非常に費用がかかります。データの取得、処理、管理のコストも高額になる可能性があります。そのトレーニング プロセスには、大量のコンピューティング リソースが必要であり、GPU や TPU などの専用ハードウェアの使用が必要であり、モデル トレーニング用のソフトウェアとインフラストラクチャも必要であり、これらすべてに財政的投資が必要です。さらに、ベースモデルのトレーニング時間も非常に長く、コストも高くなります。したがって、これらのモデルはプラグイン可能なモジュールとしてよく使用されます。つまり、基本モデルは大規模なカスタマイズ作業なしでさまざまなアプリケーションに統合できます。
表 1 に、一般的に使用される基本モデルの詳細を示します。
このセクションでは、LLM、ビジュアル Transformer、VLM、具体化されたマルチモーダル言語モデル、およびビジュアル生成モデルに焦点を当てます。さらに、ベース モデルのトレーニングに使用されるさまざまなトレーニング方法も紹介されます。
最初に、トークン化、生成モデル、識別モデル、Transformer アーキテクチャ、自己回帰モデル、マスクされた自動など、関連する用語と数学的知識が紹介されます。エンコーディング、対照学習、拡散モデル。
その後、大規模言語モデル (LLM) の例と歴史的背景を紹介します。その後、ビジュアル Transformer、マルチモーダル ビジョン言語モデル (VLM)、具体化されたマルチモーダル言語モデル、ビジュアル生成モデルが強調されました。
ロボット研究
このセクションでは、ロボットの意思決定、計画、制御に焦点を当てます。この分野では、大規模言語モデル (LLM) と視覚言語モデル (VLM) の両方がロボットの機能を強化するために使用される可能性があります。たとえば、LLM はタスク仕様プロセスを容易にし、ロボットが人間から高レベルの指示を受け取って解釈できるようにします。
VLM もこの分野への貢献が期待されています。 VLM は視覚データの分析に優れています。ロボットが情報に基づいた意思決定を行い、複雑なタスクを実行するには、視覚的な理解が不可欠です。現在、ロボットは自然言語の合図を使用して、操作、ナビゲーション、インタラクションに関連するタスクを実行する能力を強化できるようになりました。
目標ベースの視覚言語政策学習 (模倣学習または強化学習による) は、基本モデルによって改善されることが期待されます。言語モデルは、ポリシー学習手法へのフィードバックも提供できます。ロボットは LLM から受け取るフィードバックに基づいて動作を最適化できるため、このフィードバック ループはロボットの意思決定能力を継続的に向上させるのに役立ちます。
このセクションでは、ロボットの意思決定の分野における LLM と VLM の応用に焦点を当てます。
このセクションは 6 つの部分に分かれています。最初の部分では、言語ベースの模倣学習と言語支援強化学習を含む、意思決定と制御のためのポリシー学習とロボットを紹介します。
2 番目の部分は、目標に基づいた言語イメージ価値学習です。
3 番目のパートでは、ロボット タスクを計画するための大規模な言語モデルの使用について紹介します。これには、言語命令によるタスクの説明と、言語モデルを使用したタスク計画用のコードの生成が含まれます。
4 番目の部分は、意思決定のための文脈学習 (ICL) です。
次に紹介するのは、ロボットトランスフォーマーです。
6 番目のパートは、ロボットのナビゲーションとオープンボキャブラリーライブラリの操作です。
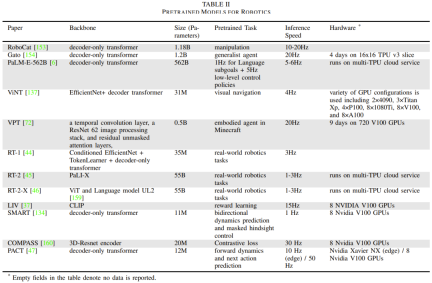
表 2 は、いくつかの基本的なロボット固有のモデル、レポート モデルのサイズとアーキテクチャ、事前トレーニング タスク、推論時間、およびハードウェア セットアップを示しています。
書き直す必要があるのは、認識です。
周囲の環境と対話するロボットは、画像、ビデオ、音声、言語などのさまざまな形式で感覚情報を受け取ります。この高次元データは、ロボットが環境を理解し、推論し、対話するために不可欠です。基本モデルは、これらの高次元の入力を、解釈と操作が容易な抽象構造化表現に変換できます。特に、マルチモーダル基本モデルにより、ロボットはさまざまな感覚からの入力を、意味論的、空間的、時間的、およびアフォーダンスの情報を含む統一された表現に統合できます。これらのマルチモーダル モデルには、クロスモーダルな相互作用が必要であり、多くの場合、一貫性と相互対応を確保するために、さまざまなモダリティの要素を調整する必要があります。たとえば、画像説明タスクでは、テキストと画像データの位置合わせが必要です。
このセクションでは、ロボットが書き換える必要があるもの、つまり基本モデルを使用してモダリティを調整することで改善できる知覚に関連する一連のタスクに焦点を当てます。視覚と言語に重点が置かれています。
このセクションは 5 つの部分に分かれており、最初はオープンボキャブラリーのターゲット検出と 3D 分類、次にオープンボキャブラリーのセマンティックセグメンテーション、次にオープンボキャブラリーの 3D シーンとターゲット表現です。次に学習されたアフォーダンス、そして最後に予測モデルです。
身体化 AI
最近、LLM が身体化 AI の分野でうまく使用できることがいくつかの研究で示されています。ここでの「身体化」とは、通常、仮想化された AI を指します。物理的なロボットの体を持つのではなく、世界のシミュレーターです。
この分野では、いくつかの興味深いフレームワーク、データセット、モデルが登場しています。特に注目すべきは、肉体を持ったエージェントを訓練するためのプラットフォームとして Minecraft ゲームを使用していることです。たとえば、Voyager は GPT-4 を使用して、Minecraft 環境を探索するエージェントをガイドします。 GPT-4 のモデル パラメーターを微調整することなく、コンテキスト プロンプト設計を通じて GPT-4 と対話できます。
強化学習は、ロボット学習の分野における重要な研究方向です。研究者は、基本モデルを使用して報酬関数を設計し、強化学習を最適化しようとしています。
ロボットが高レベルの計画を実行できるように、研究者は、基本的なモデルを使用して探索を支援してきました。さらに、一部の研究者は、思考連鎖ベースの推論およびアクション生成手法を身体化された知能に適用しようとしています
課題と今後の方向性
このセクションでは、思考連鎖ベースの推論およびアクション生成方法を身体化知能に適用しようとしています。ロボット工学の基本モデルが提供されます。チームはまた、これらの課題に対処する可能性のある将来の研究の方向性を模索する予定です。
最初の課題は、ロボットのベース モデルをトレーニングする際のデータ不足の問題を克服することです:
1. 非構造化ゲーム データとラベルのない人間のビデオを使用してロボットの学習を拡張する
2. 画像修復 (Inpainting) を使用してデータを強化する
##3. 3D 基本モデルをトレーニングする際の 3D データ不足の問題を克服する##4. 高忠実度シミュレーションによる合成データの生成
5. データ拡張に VLM を使用する データ拡張に VLM を使用することは効果的な方法です
6. ロボットの身体的スキルはスキルの配分によって制限されます
2 番目の課題はリアルタイム パフォーマンスに関連しており、そのうちの 1 つは、キーは基礎モデルの推論時間です。
3 番目の課題には、マルチモーダル表現の制限が含まれます。
4 番目の課題は、インスタンス レベルやディストリビューション レベルなど、さまざまなレベルで不確実性を定量化する方法であり、ディストリビューションのシフトをどのように調整して対処するかという問題も伴います。
5 番目の課題には、展開前のセキュリティ テストや実行時の監視、配布外状況の検出などのセキュリティ評価が含まれます。
6 番目の課題には、ロボットの既存のベース モデルを使用するか、それとも新しいベース モデルを構築するかを選択する方法が含まれます。
7 番目の課題には、ロボットのセットアップのばらつきが大きいことが関係します。
8 番目の課題は、ロボット設定でベンチマークを実行し、再現性を確保する方法です。
研究の詳細については、元の論文を参照してください。
以上が大型モデル + ロボット、多くの中国の学者の参加による詳細なレビューレポートはこちらの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 AI内部展開の隠された危険:ガバナンスのギャップと壊滅的なリスクApr 28, 2025 am 11:12 AM
AI内部展開の隠された危険:ガバナンスのギャップと壊滅的なリスクApr 28, 2025 am 11:12 AMApollo Researchの新しいレポートによると、高度なAIシステムの未確認の内部展開は、重大なリスクをもたらします。 主要なAI企業の間で一般的なこの監視の欠如は、Uncontに及ぶ潜在的な壊滅的な結果を可能にします
 AIポリグラフの構築Apr 28, 2025 am 11:11 AM
AIポリグラフの構築Apr 28, 2025 am 11:11 AM従来の嘘検出器は時代遅れです。リストバンドで接続されたポインターに依存すると、被験者のバイタルサインと身体的反応を印刷する嘘発見器は、嘘を識別するのに正確ではありません。これが、嘘の検出結果が通常裁判所で採用されない理由ですが、多くの罪のない人々が投獄されています。 対照的に、人工知能は強力なデータエンジンであり、その実用的な原則はすべての側面を観察することです。これは、科学者がさまざまな方法で真実を求めるアプリケーションに人工知能を適用できることを意味します。 1つのアプローチは、嘘発見器のように尋問されている人の重要な符号応答を分析することですが、より詳細かつ正確な比較分析を行います。 別のアプローチは、言語マークアップを使用して、人々が実際に言うことを分析し、論理と推論を使用することです。 ことわざにあるように、ある嘘は別の嘘を繁殖させ、最終的に
 AIは航空宇宙産業の離陸のためにクリアされていますか?Apr 28, 2025 am 11:10 AM
AIは航空宇宙産業の離陸のためにクリアされていますか?Apr 28, 2025 am 11:10 AMイノベーションの先駆者である航空宇宙産業は、AIを活用して、最も複雑な課題に取り組んでいます。 近代的な航空の複雑さの増加は、AIの自動化とリアルタイムのインテリジェンス機能を必要とします。
 北京の春のロボットレースを見ていますApr 28, 2025 am 11:09 AM
北京の春のロボットレースを見ていますApr 28, 2025 am 11:09 AMロボット工学の急速な発展により、私たちは魅力的なケーススタディをもたらしました。 NoetixのN2ロボットの重量は40ポンドを超えており、高さは3フィートで、逆流できると言われています。 UnitreeのG1ロボットの重量は、N2のサイズの約2倍で、高さは約4フィートです。また、競争に参加している多くの小さなヒューマノイドロボットがあり、ファンによって前進するロボットさえあります。 データ解釈 ハーフマラソンは12,000人以上の観客を惹きつけましたが、21人のヒューマノイドロボットのみが参加しました。政府は、参加しているロボットが競争前に「集中トレーニング」を実施したと指摘したが、すべてのロボットが競争全体を完了したわけではない。 チャンピオン - 北京ヒューマノイドロボットイノベーションセンターによって開発されたティアンゴニ
 ミラートラップ:AI倫理と人間の想像力の崩壊Apr 28, 2025 am 11:08 AM
ミラートラップ:AI倫理と人間の想像力の崩壊Apr 28, 2025 am 11:08 AM人工知能は、現在の形式では、真にインテリジェントではありません。既存のデータを模倣して洗練するのに熟達しています。 私たちは人工知能を作成するのではなく、人工的な推論を作成しています。情報を処理するマシン、人間は
 新しいGoogleリークは、便利なGoogle写真機能の更新を明らかにしますApr 28, 2025 am 11:07 AM
新しいGoogleリークは、便利なGoogle写真機能の更新を明らかにしますApr 28, 2025 am 11:07 AMレポートでは、更新されたインターフェイスがGoogle Photos Androidバージョン7.26のコードに隠されていることがわかり、写真を見るたびに、新しく検出された顔のサムネイルの行が画面の下部に表示されます。 新しいフェイシャルサムネイルには名前タグが欠落しているため、検出された各人に関する詳細情報を見るには、個別にクリックする必要があると思います。今のところ、この機能は、Googleフォトが画像で見つけた人々以外の情報を提供しません。 この機能はまだ利用できないため、Googleが正確にどのように使用するかはわかりません。 Googleはサムネイルを使用して、選択した人のより多くの写真を見つけるためにスピードアップしたり、編集して個人を選択するなど、他の目的に使用することもできます。待って見てみましょう。 今のところ
 補強能力のガイド - 分析VidhyaApr 28, 2025 am 09:30 AM
補強能力のガイド - 分析VidhyaApr 28, 2025 am 09:30 AM補強能力は、人間のフィードバックに基づいて調整するためにモデルを教えることにより、AI開発を揺さぶりました。それは、監督された学習基盤と報酬ベースの更新をブレンドして、より安全で、より正確に、そして本当に助けます
 踊りましょう:私たちの人間のニューラルネットを微調整するための構造化された動きApr 27, 2025 am 11:09 AM
踊りましょう:私たちの人間のニューラルネットを微調整するための構造化された動きApr 27, 2025 am 11:09 AM科学者は、彼らの機能を理解するために、人間とより単純なニューラルネットワーク(C. elegansのものと同様)を広く研究してきました。 ただし、重要な疑問が生じます。新しいAIと一緒に効果的に作業するために独自のニューラルネットワークをどのように適応させるのか


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

DVWA
Damn Vulnerable Web App (DVWA) は、非常に脆弱な PHP/MySQL Web アプリケーションです。その主な目的は、セキュリティ専門家が法的環境でスキルとツールをテストするのに役立ち、Web 開発者が Web アプリケーションを保護するプロセスをより深く理解できるようにし、教師/生徒が教室環境で Web アプリケーションを教え/学習できるようにすることです。安全。 DVWA の目標は、シンプルでわかりやすいインターフェイスを通じて、さまざまな難易度で最も一般的な Web 脆弱性のいくつかを実践することです。このソフトウェアは、

Dreamweaver Mac版
ビジュアル Web 開発ツール

SecLists
SecLists は、セキュリティ テスターの究極の相棒です。これは、セキュリティ評価中に頻繁に使用されるさまざまな種類のリストを 1 か所にまとめたものです。 SecLists は、セキュリティ テスターが必要とする可能性のあるすべてのリストを便利に提供することで、セキュリティ テストをより効率的かつ生産的にするのに役立ちます。リストの種類には、ユーザー名、パスワード、URL、ファジング ペイロード、機密データ パターン、Web シェルなどが含まれます。テスターはこのリポジトリを新しいテスト マシンにプルするだけで、必要なあらゆる種類のリストにアクセスできるようになります。

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7781
7781 15164414139952129625123429
15164414139952129625123429