###導入###
| 「プール」という概念は私たちの開発では珍しいことではなく、データベース接続プール、スレッド プール、オブジェクト プール、定数プールなどがあります。以下では主にスレッド プールに焦点を当て、スレッド プールのベールを段階的に明らかにしていきます。
|
スレッドプールを使用する利点
1. リソース消費の削減
作成されたスレッドを再利用して、スレッドの作成と破棄による消費を削減できます。
2. 応答速度の向上
タスクが到着すると、スレッドの作成を待たずにすぐにタスクを実行できます。
3. スレッドの管理性の向上
スレッドは希少なリソースです。制限なしで作成すると、システム リソースを消費するだけでなく、システムの安定性も低下します。スレッド プールは、統合された割り当て、チューニング、監視に使用できます
スレッドプールの仕組み
まず、新しいタスクがスレッド プールに送信された後、スレッド プールがそれをどのように処理するかを見てみましょう
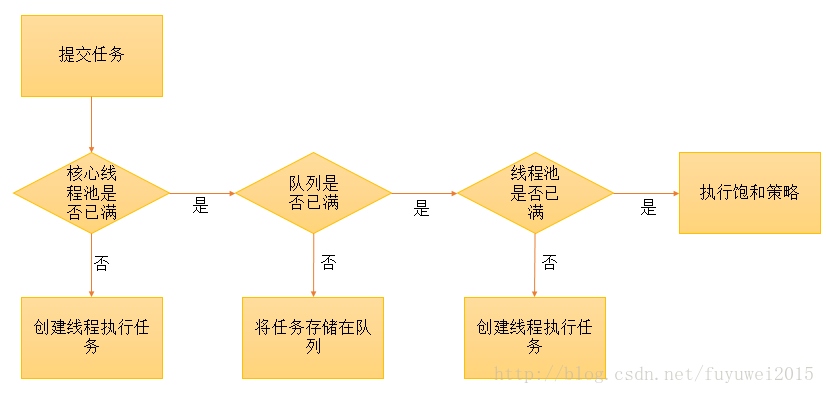
1. スレッド プールは、コア スレッド プール内のすべてのスレッドがタスクを実行しているかどうかを決定します。そうでない場合は、タスクを実行するために新しいワーカー スレッドが作成されます。コア スレッド プール内のすべてのスレッドがタスクを実行している場合は、2 番目の手順を実行します。
2. スレッド プールは、ワーク キューがいっぱいかどうかを判断します。ワーク キューがいっぱいでない場合、新しく送信されたタスクはこのワーク キューに格納され、待機されます。ワークキューがいっぱいの場合は、3 番目のステップを実行します
3. スレッド プールは、スレッド プール内のすべてのスレッドが動作状態にあるかどうかを判断します。そうでない場合は、タスクを実行するために新しいワーカー スレッドが作成されます。いっぱいの場合は、このタスクを処理するために飽和戦略に渡します
スレッドプール飽和戦略
スレッド プールの飽和戦略についてはここで説明されているので、飽和戦略を簡単に紹介しましょう:
ポリシーの中止
は、Java スレッド プールのデフォルトのブロック戦略です。このタスクは実行されず、ランタイム例外が直接スローされます。ThreadPoolExecutor.execute には try catch が必要であることに注意してください。そうでない場合は、プログラムが直接終了します。
ポリシー破棄
直接破棄するとタスクは実行されず、空のメソッドです
最も古いポリシーを破棄
先頭のタスクをキューから破棄し、再度タスクを実行します。
発信者実行ポリシー
execute を呼び出すスレッドでこのコマンドを実行すると、エントリがブロックされます
ユーザー定義の拒否ポリシー (最も一般的に使用される)
RejectedExecutionHandler を実装し、独自の戦略モードを定義します
ThreadPoolExecutor を例として、スレッド プールのワークフロー図を示します。
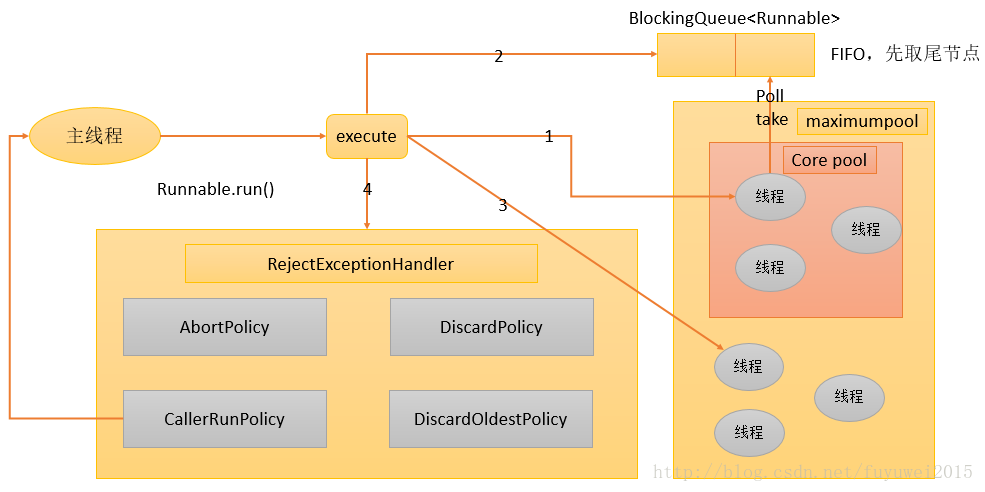
1. 現在実行中のスレッドの数が corePoolSize より少ない場合は、タスクを実行するための新しいスレッドを作成します (このステップを実行するにはグローバル ロックを取得する必要があることに注意してください)。
2. 実行中のスレッドが corePoolSize 以上の場合、タスクを BlockingQueue に追加します。
3. タスクを BlockingQueue に追加できない (キューがいっぱいである) 場合は、非コアプールに新しいスレッドを作成してタスクを処理します (この手順を実行するにはグローバル ロックを取得する必要があることに注意してください)。
4. 新しいスレッドを作成することにより、現在実行中のスレッドが MaximumPoolSize を超える場合、タスクは拒否され、RejectedExecutionHandler.rejectedExecution() メソッドが呼び出されます。
ThreadPoolExecutor が上記の手順を実行する全体的な設計上の考え方は、execute() メソッドの実行時にグローバル ロックの取得をできる限り回避することです (これは、スケーラビリティの重大なボトルネックになります)。 ThreadPoolExecutor がウォームアップを完了すると (現在実行中のスレッドの数が corePoolSize 以上になると)、ほとんどすべてのexecute() メソッド呼び出しでステップ 2 が実行され、ステップ 2 ではグローバル ロックを取得する必要がありません。
主要メソッドのソースコード分析
次のように実行されるスレッド プール メソッドに追加されたコア メソッドのソース コードを見てみましょう:
リーリー
addWorker がどのように実装されるかを見てみましょう:
リーリー
AddWorker の後に runWorker が続きます。初めて起動すると、初期化中に渡されたタスク firstTask が実行されます。その後、workQueue からタスクを取得して実行します。キューが空の場合は、 keepAliveTime
まで待ちます
リーリー
getTask がどのように実行されるかを見てみましょう
リーリー
processWorkerExit がどのように機能するかを見てみましょう
リーリー
tryTerminate
processWorkerExit メソッドは、tryTerminate を呼び出してスレッド プールを終了しようとします。このメソッドは、wwerCount の削減や SHUTDOWN 状態のキューからのタスクの削除など、スレッド プールの終了を引き起こす可能性のあるアクションの後に実行されます。
リーリー
shutdown このメソッドは runState を SHUTDOWN に設定し、アイドル状態のスレッドをすべて終了します。 shutdownNow メソッドは runState を STOP に設定します。 shutdown メソッドとの違いは、このメソッドはすべてのスレッドを終了することです。主な違いは、shutdown はinterruptIdleWorkers メソッドを呼び出すのに対し、shutdownNow は実際には Worker クラスのinterruptIfStarted メソッドを呼び出すことです。
その実装は次のとおりです:
リーリー
スレッドプールの使用
スレッドプールの作成
ThreadPoolExecutor を通じてスレッド プールを作成できます
/**
* @param corePoolSize 线程池基本大小,核心线程池大小,活动线程小于corePoolSize则直接创建,大于等于则先加到workQueue中,
* 队列满了才创建新的线程。当提交一个任务到线程池时,线程池会创建一个线程来执行任务,即使其他空闲的基本线程能够执行新任务也会创建线程,
* 等到需要执行的任务数大于线程池基本大小时就不再创建。如果调用了线程池的prestartAllCoreThreads()方法,
* 线程池会提前创建并启动所有基本线程。
* @param maximumPoolSize 最大线程数,超过就reject;线程池允许创建的最大线程数。如果队列满了,
* 并且已创建的线程数小于最大线程数,则线程池会再创建新的线程执行任务
* @param keepAliveTime
* 线程池的工作线程空闲后,保持存活的时间。所以,如果任务很多,并且每个任务执行的时间比较短,可以调大时间,提高线程的利用率
* @param unit 线程活动保持时间的单位):可选的单位有天(DAYS)、小时(HOURS)、分钟(MINUTES)、
* 毫秒(MILLISECONDS)、微秒(MICROSECONDS,千分之一毫秒)和纳秒(NANOSECONDS,千分之一微秒)
* @param workQueue 工作队列,线程池中的工作线程都是从这个工作队列源源不断的获取任务进行执行
*/
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue) {
// threadFactory用于设置创建线程的工厂,可以通过线程工厂给每个创建出来的线程设置更有意义的名字
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), defaultHandler);
}
向线程池提交任务
可以使用两个方法向线程池提交任务,分别为execute()和submit()方法。execute()方法用于提交不需要返回值的任务,所以无法判断任务是否被线程池执行成功。通过以下代码可知execute()方法输入的任务是一个Runnable类的实例。
threadsPool.execute(new Runnable() {
@Override
public void run() {
}
});
submit()方法用于提交需要返回值的任务。线程池会返回一个future类型的对象,通过这个future对象可以判断任务是否执行成功,并且可以通过future的get()方法来获取返回值,get()方法会阻塞当前线程直到任务完成,而使用get(long timeout,TimeUnit unit)方法则会阻塞当前线程一段时间后立即返回,这时候有可能任务没有执行完。
Future<Object> future = executor.submit(harReturnValuetask);
try
{
Object s = future.get();
}catch(
InterruptedException e)
{
// 处理中断异常
}catch(
ExecutionException e)
{
// 处理无法执行任务异常
}finally
{
// 关闭线程池
executor.shutdown();
}
关闭线程池
可以通过调用线程池的shutdown或shutdownNow方法来关闭线程池。它们的原理是遍历线程池中的工作线程,然后逐个调用线程的interrupt方法来中断线程,所以无法响应中断的任务可能永远无法终止。但是它们存在一定的区别,shutdownNow首先将线程池的状态设置成STOP,然后尝试停止所有的正在执行或暂停任务的线程,并返回等待执行任务的列表,而shutdown只是将线程池的状态设置成SHUTDOWN状态,然后中断所有没有正在执行任务的线程。
只要调用了这两个关闭方法中的任意一个,isShutdown方法就会返回true。当所有的任务都已关闭后,才表示线程池关闭成功,这时调用isTerminaed方法会返回true。至于应该调用哪一种方法来关闭线程池,应该由提交到线程池的任务特性决定,通常调用shutdown方法来关闭线程池,如果任务不一定要执行完,则可以调用shutdownNow方法。
合理的配置线程池
要想合理地配置线程池,就必须首先分析任务特性,可以从以下几个角度来分析。
1、任务的性质:CPU密集型任务、IO密集型任务和混合型任务。
2、任务的优先级:高、中和低。
3、任务的执行时间:长、中和短。
4、任务的依赖性:是否依赖其他系统资源,如数据库连接。
性质不同的任务可以用不同规模的线程池分开处理。CPU密集型任务应配置尽可能小的线程,如配置Ncpu+1个线程的线程池。由于IO密集型任务线程并不是一直在执行任务,则应配置尽可能多的线程,如2*Ncpu。混合型的任务,如果可以拆分,将其拆分成一个CPU密集型任务和一个IO密集型任务,只要这两个任务执行的时间相差不是太大,那么分解后执行的吞吐量将高于串行执行的吞吐量。如果这两个任务执行时间相差太大,则没必要进行分解。可以通过Runtime.getRuntime().availableProcessors()方法获得当前设备的CPU个数。优先级不同的任务可以使用优先级队列PriorityBlockingQueue来处理。它可以让优先级高的任务先执行
如果一直有优先级高的任务提交到队列里,那么优先级低的任务可能永远不能执行。执行时间不同的任务可以交给不同规模的线程池来处理,或者可以使用优先级队列,让执行时间短的任务先执行。依赖数据库连接池的任务,因为线程提交SQL后需要等待数据库返回结果,等待的时间越长,则CPU空闲时间就越长,那么线程数应该设置得越大,这样才能更好地利用CPU。
境界付きキューを使用することをお勧めします。境界付きキューにより、システムの安定性と早期警告機能が向上し、必要に応じて数千などの大きなキューに設定できます。システムのバックグラウンド タスクのスレッド プールのキューとスレッド プールがいっぱいになることがあり、放棄されたタスクの例外が常にスローされることがあります。トラブルシューティングの結果、データベースに問題があることが判明し、SQL の実行が非常に遅くなりました。バックグラウンド タスクのスレッド プールには、すべてのタスクでクエリとデータベースへのデータの挿入が必要なため、スレッド プール内のすべての作業スレッドがブロックされ、タスクがスレッド プールにバックログされるため、低速です。そのときに無制限のキューに設定すると、スレッド プール内のキューがますます増えてメモリがいっぱいになり、バックグラウンド タスクだけでなくシステム全体が使用できなくなる可能性があります。もちろん、システム内のすべてのタスクは別々のサーバーにデプロイされ、さまざまなタイプのタスクを完了するためにさまざまなサイズのスレッド プールを使用しますが、そのような問題が発生すると、他のタスクも影響を受けます。
スレッドプールの監視
システムで多数のスレッド プールが使用されている場合は、問題が発生したときにスレッド プールの使用状況に基づいて問題を迅速に特定できるように、スレッド プールを監視する必要があります。スレッド プールが提供するパラメータを通じて監視できます。スレッド プールを監視する場合は、次の属性を使用できます。
taskCount: スレッド プールが実行する必要があるタスクの数。 -
completedTaskCount: スレッド プールが操作中に完了したタスクの数。taskCount 以下です。 -
largestPoolSize: スレッド プール内にこれまでに作成されたスレッドの最大数。このデータを通じて、スレッド プールがこれまでにいっぱいになったかどうかを知ることができます。この値がスレッド プールの最大サイズと等しい場合は、スレッド プールがいっぱいであることを意味します。 -
getPoolSize: スレッド プール内のスレッドの数。スレッド プールが破棄されない場合、スレッド プール内のスレッドは自動的に破棄されないため、サイズは増加するだけで減少しません。 -
getActiveCount: アクティブなスレッドの数を取得します。 -
スレッドプールを拡張して監視します。スレッド プールを継承したり、スレッド プールの beforeExecute、afterExecute、およびterminated メソッドを書き換えたりすることによって、スレッド プールをカスタマイズしたり、スレッド プールが閉じる前、後、および前に監視用のコードを実行したりすることができます。たとえば、タスクの平均実行時間、最大実行時間、最小実行時間を監視します。

