


BEV 汎化パフォーマンスにおける NeRF の画期的な進歩: 初のクロスドメイン オープン ソース コードで Sim2Real の実装に成功

前書き&筆者個人のまとめ
バードアイズビュー(BEV)検出は、複数のサラウンドビューカメラを融合して検出する方法です。現在のアルゴリズムのほとんどは同じデータ セットでトレーニングおよび評価されているため、これらのアルゴリズムは変更されていないカメラの内部パラメータ (カメラ タイプ) と外部パラメータ (カメラの配置) にオーバーフィットします。この論文では、未知の領域での物体検出の問題を解決できる、暗黙的レンダリングに基づく BEV 検出フレームワークを提案します。このフレームワークは暗黙的レンダリングを使用して、オブジェクトの 3D 位置と単一ビューの遠近位置の間の関係を確立し、遠近バイアスの修正に使用できます。この方法により、ドメイン汎化 (DG) と教師なしドメイン適応 (UDA) のパフォーマンスが大幅に向上します。この方法は、実際のシナリオでの BEV 検出のトレーニングと評価に仮想データ セットのみを使用する初めての試みであり、仮想と現実の間の障壁を打ち破って閉ループ テストを完了できます。
- 論文リンク: https://arxiv.org/pdf/2310.11346.pdf
- コードリンク: https://github.com/EnVision-Research/Generalizable-BEV

#BEV 検出ドメインの一般化問題の背景
マルチカメラ検出とは、複数のカメラを使用してオブジェクトを検出することを指します。 3 次元空間、物体検出および位置特定タスク。マルチカメラ 3D オブジェクト検出では、さまざまな視点からの情報を組み合わせることで、特に特定の視点からのターゲットが遮られたり部分的に見えたりする状況で、より正確で堅牢なオブジェクト検出結果を提供できます。近年、マルチカメラ検出タスクにおいて Bird eye's view (BEV) 手法が大きな注目を集めています。これらの方法はマルチカメラ情報融合において利点がありますが、テスト環境がトレーニング環境と大きく異なる場合、これらの方法のパフォーマンスが大幅に低下する可能性があります。 現在、ほとんどの BEV 検出アルゴリズムは同じデータセットでトレーニングおよび評価されているため、これらのアルゴリズムは内部および外部カメラのパラメーターや都市部の道路状況の変化に敏感になりすぎ、深刻なオーバーフィッティングの問題が発生します。 。ただし、実際のアプリケーションでは、BEV 検出アルゴリズムをさまざまな新しいモデルや新しいカメラに適応させる必要があることが多く、これがこれらのアルゴリズムの失敗につながります。したがって、BEV 検出の一般化可能性を研究することが重要です。 また、閉ループシミュレーションも自動運転には非常に重要ですが、現状ではCarlaなどの仮想エンジンでしか評価できません。したがって、仮想エンジンと実シーンとの間のドメインの差異の問題を解決する必要があり、その分布シフトを緩和する方法として、ドメイン汎化 (DG) と教師なしドメイン適応 (UDA) という 2 つの方向性が期待されます。 DG メソッドは多くの場合、ドメイン固有の機能を分離して排除するため、目に見えないドメインでの汎化パフォーマンスが向上します。 UDA の場合、最近の方法では、擬似ラベルまたは潜在特徴量分布の調整を生成することでドメイン シフトを軽減します。ただし、異なる視点、カメラ パラメーター、環境からのデータを使用せずに、純粋な視覚認識のための視点や環境に依存しない特徴を学習することは非常に困難です。 観察によると、図に示すように、単一の視点 (カメラ平面) からの 2D 検出は、複数の視点からの 3D ターゲット検出よりも強力な一般化機能を備えていることがよくあります。一部の研究では、2D 情報を 3D 検出器に融合したり、2D-3D の一貫性を確立したりするなど、2D 検出を BEV 検出に統合することが検討されています。 2D 情報融合は機構モデリング手法ではなく学習ベースの手法であり、依然としてドメイン移行の影響を大きく受けています。既存の 2D-3D 一貫性手法は、3D 結果を 2 次元平面に投影し、一貫性を確立します。この制約は、ターゲット ドメインの幾何学的情報を変更するのではなく、ターゲット ドメインの意味情報を損なう可能性があります。さらに、この 2D-3D 一貫性アプローチにより、すべての検出ヘッドに対する統一アプローチが困難になります。#この論文の貢献の概要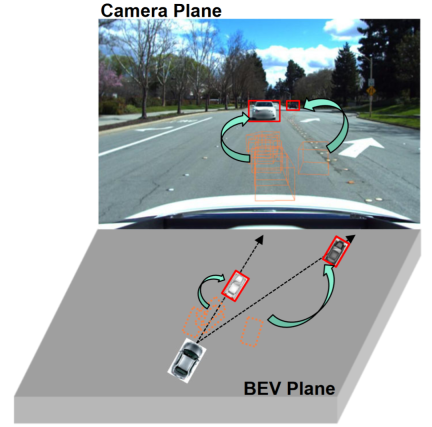
この論文では、パースペクティブ ディバイアス フレームワークに基づいた一般化された BEV 検出を提案します。これは、モデルがソース ドメインの遠近感とコンテキスト不変の特徴を学習するのに役立つだけでなく、2D 検出器を利用してターゲット ドメインの偽の幾何学的特徴をさらに修正します。
この論文は、BEV 検出における教師なしドメイン適応を研究する最初の試みであり、ベンチマークを確立します。 UDA プロトコルと DG プロトコルの両方で最先端の結果が得られます。- このペーパーでは、現実世界の BEV 検出タスクを実現するために、実際のシーンのアノテーションを使用しない仮想エンジンでのトレーニングを初めて検討します。
- BEV 検出ドメインの一般化問題の定義
問題の定義
研究は主に、BEV 検出ドメインの一般化を強化することに焦点を当てています。 BEV検出の変更。この目標を達成するために、この文書では、広く実用化されている 2 つのプロトコル、つまりドメイン一般化 (DG) と教師なしドメイン適応 (UDA) を検討します。
BEV 検出のドメイン一般化 (DG):既存のデータ セット (ソース ドメイン) で BEV 検出アルゴリズムをトレーニングし、未知のデータ セット (ターゲット ドメイン) での検出パフォーマンスを向上させます。たとえば、特定の車両またはシナリオで BEV 検出モデルをトレーニングすると、さまざまな異なる車両やシナリオに直接一般化できます。
BEV 検出のための教師なしドメイン アダプテーション (UDA): 既存のデータ セット (ソース ドメイン) で BEV 検出アルゴリズムをトレーニングし、ターゲット ドメインでラベルなしのデータを使用して検出パフォーマンスを向上させます。たとえば、新しい車両や都市では、教師なしデータを収集するだけで、新しい車両や新しい環境におけるモデルのパフォーマンスを向上させることができます。なお、DG と UDA の唯一の違いは、対象ドメインのラベルなしデータを利用できるかどうかです。
視野角偏差の定義
物体の未知の L=[x,y,z] を検出するために、ほとんどの BEV 検出には 2 つの重要な部分があります ( 1) さまざまな視野角からの画像特徴の取得; (2) これらの画像特徴を BEV 空間に融合し、最終的な予測結果を取得します:
上記の式は、ドメインの偏差が特徴抽出段階またはBEV融合ステージ。次に、この記事は付録に進み、2D 結果に投影された最終的な 3D 予測結果の視野角偏差を取得しました。
ここで、k_u、b_u、k_v、および b_v は、BEV のドメイン オフセットに関連しています。エンコーダでは、d(u,v) はモデルの最終予測深度情報です。 c_u と c_v は、UV イメージ平面上のカメラの光学中心の座標を表します。上の方程式は、いくつかの重要な帰結を示しています。 (1) 最終位置オフセットの存在は遠近バイアスをもたらします。これは、遠近バイアスの最適化がドメイン オフセットの軽減に役立つことを示しています。 (2) 単眼結像面上のカメラの光学中心光線上の点の位置も移動します。
直観的には、ドメイン シフトにより BEV 特徴の位置が変更されますが、これはトレーニング データの視点とカメラ パラメーターが制限されているために過学習になります。この問題を軽減するには、BEV の特徴から新しいビュー イメージを再レンダリングすることが重要です。これにより、ネットワークがビューや環境に依存しない特徴を学習できるようになります。そこで本研究では、レンダリング視点の違いによる視点のずれを解決し、モデルの汎化能力を向上させることを目的としています。合計 #PD-BEV 図 1 に示すように、セマンティック レンダリング、ソース ドメインのバイアス除去、ターゲット ドメインのバイアス除去の 3 つの部分に分かれています。セマンティック レンダリングでは、BEV 機能を通じて 2D と 3D の間の遠近関係を確立する方法を説明します。ソース ドメインのバイアス除去では、ソース ドメインでのセマンティック レンダリングを通じてモデルの一般化機能を向上させる方法について説明します。ターゲット ドメインのバイアス軽減とは、セマンティック レンダリングを通じてモデルの一般化機能を向上させるために、ターゲット ドメイン内のラベルのないデータを使用することを指します。
セマンティック レンダリング
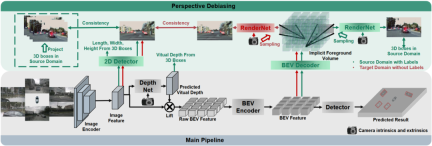 多くのアルゴリズムは BEV ボリュームを 2D 特徴に圧縮するため、最初に BEV デコーダを BEV 特徴に使用します。
多くのアルゴリズムは BEV ボリュームを 2D 特徴に圧縮するため、最初に BEV デコーダを BEV 特徴に使用します。
上記の式は実際に BEV 平面を改善し、高さの寸法を追加します。次に、カメラの内部パラメータと外部パラメータをこのボリューム内でサンプリングして 2D 特徴マップにすることができ、その後、2D 特徴マップとカメラの内部パラメータと外部パラメータを RenderNet に送信して、ヒートマップとオブジェクト プロパティを予測します。対応する視点。このようなナーフと同様の操作により、2D と 3D の間の架け橋が確立されます。
ソース ドメインのバイアス解消モデルの汎化パフォーマンスを向上させるには、ソース ドメインで改善する必要がある重要な点がいくつかあります。まず、ソース ドメインの 3D ボックスを利用して、新しくレンダリングされたビューのヒートマップとプロパティを監視し、遠近感のバイアスを軽減できます。第 2 に、正規化された奥行き情報を使用して、画像エンコーダが幾何学的情報をより適切に学習できるようにすることができます。これらの改善は、モデルの汎化パフォーマンスの向上に役立ちます。
パースペクティブ セマンティック監視: セマンティック レンダリングに基づいて、ヒートマップと属性がさまざまなパースペクティブ (RenderNet の出力) からレンダリングされます。同時に、カメラの内部パラメータと外部パラメータがランダムにサンプリングされ、これらの内部パラメータと外部パラメータを使用して、オブジェクトのボックスが 3D 座標から 2D カメラ平面に投影されます。次に、焦点損失と L1 損失を使用して、投影された 2Dbox とレンダリング結果を制約します:
この操作により、カメラの内部パラメータと外部パラメータのオーバーフィッティングを軽減し、新しい視点に対するロバスト性を向上させることができます。この論文では、無人運転の分野における新しい視点の RGB 監視の欠如という欠点を回避するために、RGB 画像からの教師あり学習をオブジェクト中心のヒート マップに変換していることは言及する価値があります。
ジオメトリ監視:明確な深度情報を提供すると、マルチカメラ 3D オブジェクト検出のパフォーマンスを効果的に向上させることができます。ただし、ネットワーク予測の深さは、固有パラメーターをオーバーフィットする傾向があります。したがって、この論文では、仮想深度メソッドを利用します。
ここで、BCE() はバイナリ クロスエントロピー損失を表し、D_{pre} は DepthNet の予測深度を表します。 f_u と f_v はそれぞれ像面の u と v の焦点距離であり、U は定数です。ここでの深度は、点群ではなく 3D ボックスを使用して提供される前景の深度情報であることに注意してください。これを行うことで、DepthNet は前景オブジェクトの深度に焦点を当てる可能性が高くなります。最後に、実際の深度情報を使用して意味論的特徴が BEV 平面に持ち上げられると、仮想深度は実際の深度に変換されます。
ターゲット ドメインのバイアスの除去
ターゲット ドメインにはアノテーションがないため、3D ボックス監視を使用してモデルの汎化能力を向上させることはできません。したがって、この論文では、2D 検出結果は 3D 結果よりも堅牢であると説明します。したがって、この論文では、レンダリングされたパースペクティブの監視としてソース ドメインの 2D 事前トレーニング済み検出器を使用し、また、疑似ラベル メカニズムも使用します。
この操作では、正確な 2D 検出を効果的に利用して、ターゲット ドメインの教師なし正則化である BEV 空間の前景ターゲット位置を修正できます。 2D 予測の補正能力をさらに高めるために、擬似手法を使用して予測ヒート マップの信頼性を高めます。このペーパーでは、3.2 の数学的証明と、3D 結果における 2D 投影エラーの原因を説明する補足資料を提供します。なぜこのようにバイアスを除去できるのかについても説明していますので、詳しくは原論文を参照してください。
全体的な監視
この記事ではトレーニングを支援するためにいくつかのネットワークが追加されていますが、これらのネットワークは推論中には必要ありません。言い換えれば、私たちの方法は、ほとんどの BEV 検出方法が遠近不変の特徴を学習する状況に適用できます。フレームワークの有効性をテストするために、評価に BEVDepth を使用することを選択します。 BEVDepth の元の損失は、ソース ドメインでメインの 3D 検出監視として使用されます。つまり、アルゴリズムの最終的な損失は次のとおりです。
クロスドメイン実験結果
表 1 は、ドメイン一般化 (DG) および教師なしにおけるさまざまな手法のパフォーマンスを示しています。ドメイン適応 (UDA) ) 協定に基づく効果の比較。その中で、Target-Free は DG プロトコルを表し、Pseudo Label、Coral、AD はいくつかの一般的な UDA メソッドです。グラフからわかるように、これらの方法はすべて、ターゲット ドメインで大幅な改善を達成しています。これは、セマンティック レンダリングが、ドメイン シフトに対する視点不変の特徴を学習するのに役立つ橋渡しとして機能することを示唆しています。さらに、これらの方法はソース ドメインのパフォーマンスを犠牲にすることはなく、ほとんどの場合に何らかの改善をもたらします。特に、DeepAccident は Carla 仮想エンジンに基づいて開発されており、DeepAccident でトレーニングした後、アルゴリズムは満足のいく汎化機能を達成しました。さらに、他の BEV 検出方法もテストされていますが、特別な設計がなければ一般化のパフォーマンスは非常に悪いです。ターゲットドメインで教師なしデータセットを利用する能力をさらに検証するために、UDA ベンチマークも確立され、UDA 手法 (Pseudo Label、Coral、AD を含む) が DG-BEV に適用されました。実験によれば、これらの方法ではパフォーマンスが大幅に向上します。暗黙的レンダリングでは、より優れた汎化パフォーマンスを備えた 2D 検出器を最大限に活用して、3D 検出器の誤った幾何学的情報を修正します。さらに、ほとんどのアルゴリズムはソース ドメインのパフォーマンスを低下させる傾向があるのに対し、私たちの方法は比較的穏やかであることがわかりました。 AD と Coral は、仮想データセットから実際のデータセットに移行すると大幅な改善が見られますが、実際のテストではパフォーマンスの低下が見られることに言及する価値があります。これは、これら 2 つのアルゴリズムがスタイルの変更を処理するように設計されているためですが、スタイルの変更が小さいシーンでは、セマンティック情報が破壊される可能性があります。 Pseudo Label アルゴリズムに関しては、いくつかの比較的良好なターゲット ドメインの信頼度を高めることでモデルの汎化パフォーマンスを向上させることができますが、ターゲット ドメインの信頼度をやみくもに高めると、実際にはモデルが悪化します。実験結果は、この論文のアルゴリズムが DG と UDA で大幅なパフォーマンス向上を達成したことを証明しています。3 つの主要コンポーネントに関するアブレーション実験結果を表 2 に示します: 2D 検出 デバイス事前トレーニング (DPT)、ソース ドメイン デバイアス (SDB) ) およびターゲット ドメインのバイアス除去 (TDB)。実験結果は、各コンポーネントが改善され、SDB と TDB が比較的顕著な効果を示していることを示しています。
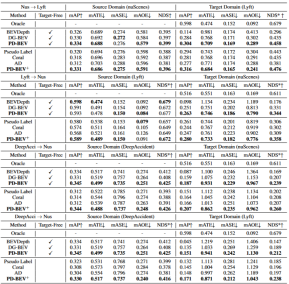
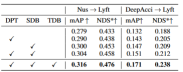
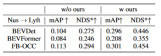
表 3 は、BEVFormer および FB に移行できるアルゴリズムを示しています。 OCCアルゴリズム。このアルゴリズムは画像特徴と BEV 特徴に対する追加操作のみを必要とするため、BEV 特徴を備えたアルゴリズムを改善できます。
概要
この論文では、未知の分野での物体検出問題を解決できる、透視偏光解消に基づく一般的なマルチカメラ 3D 物体検出フレームワークを提案します。このフレームワークは、3D 検出結果を 2D カメラ平面に投影し、遠近法のバイアスを補正することで、一貫した正確な検出を実現します。さらに、このフレームワークでは、さまざまな視点から画像をレンダリングすることでモデルの堅牢性を強化する視点偏り解消戦略も導入されています。実験結果は、この方法がドメインの一般化と教師なしドメインの適応において大幅なパフォーマンスの向上を達成することを示しています。さらに、このメソッドは、実際のシーンの注釈を必要とせずに仮想データ セットでトレーニングすることもできるため、リアルタイム アプリケーションや大規模な展開に便利です。これらのハイライトは、マルチカメラ 3D オブジェクト検出を解決する際のこの方法の課題と可能性を示しています。この論文は、Nerf のアイデアを使用して BEV の汎化能力を向上させることを試みており、ラベル付きソース ドメイン データとラベルなしターゲット ドメイン データも使用できます。さらに、自動運転閉ループの潜在的価値を持つ Sim2Real の実験パラダイムが試みられました。定性的および定量的結果の両方から非常に優れた結果が得られており、オープンソース コードは一見の価値があります

元のリンク: https://mp.weixin.qq.com / s/GRLu_JW6qZ_nQ9sLiE0p2g
以上がBEV 汎化パフォーマンスにおける NeRF の画期的な進歩: 初のクロスドメイン オープン ソース コードで Sim2Real の実装に成功の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 生成エンジン最適化に関するビジネスリーダーのガイド(GEO)May 03, 2025 am 11:14 AM
生成エンジン最適化に関するビジネスリーダーのガイド(GEO)May 03, 2025 am 11:14 AMGoogleはこのシフトをリードしています。その「AIの概要」機能はすでに10億人以上のユーザーにサービスを提供しており、誰もがリンクをクリックする前に完全な回答を提供しています。[^2] 他のプレイヤーも速く地位を獲得しています。 ChatGpt、Microsoft Copilot、およびPE
 このスタートアップは、AIエージェントを使用して悪意のある広告となりすましアカウントと戦っていますMay 03, 2025 am 11:13 AM
このスタートアップは、AIエージェントを使用して悪意のある広告となりすましアカウントと戦っていますMay 03, 2025 am 11:13 AM2022年、彼はソーシャルエンジニアリング防衛のスタートアップDoppelを設立してまさにそれを行いました。そして、サイバー犯罪者が攻撃をターボチャージするためのより高度なAIモデルをハーネスするにつれて、DoppelのAIシステムは、企業が大規模に戦うのに役立ちました。
 世界モデルがどのように生成AIとLLMの未来を根本的に再形成しているかMay 03, 2025 am 11:12 AM
世界モデルがどのように生成AIとLLMの未来を根本的に再形成しているかMay 03, 2025 am 11:12 AM出来上がりは、適切な世界モデルとの対話を介して、生成AIとLLMを実質的に後押しすることができます。 それについて話しましょう。 革新的なAIブレークスルーのこの分析は、最新のAIで進行中のForbes列のカバレッジの一部であり、
 2050年5月:私たちは祝うために何を残しましたか?May 03, 2025 am 11:11 AM
2050年5月:私たちは祝うために何を残しましたか?May 03, 2025 am 11:11 AM労働者2050年。全国の公園は、ノスタルジックなパレードが街の通りを通り抜ける一方で、伝統的なバーベキューを楽しんでいる家族でいっぱいです。しかし、お祝いは現在、博物館のような品質を持っています。
 あなたが聞いたことがないディープフェイク検出器はそれが98%正確ですMay 03, 2025 am 11:10 AM
あなたが聞いたことがないディープフェイク検出器はそれが98%正確ですMay 03, 2025 am 11:10 AMこの緊急かつ不安な傾向に対処するために、TEM Journalの2025年2月版の査読済みの記事は、その技術のディープフェイクが現在存在する場所に関する最も明確でデータ駆動型の評価の1つを提供します。 研究者
 Quantum Talent Wars:The Hidden Crisis Treatenting Tech'の次のフロンティアMay 03, 2025 am 11:09 AM
Quantum Talent Wars:The Hidden Crisis Treatenting Tech'の次のフロンティアMay 03, 2025 am 11:09 AM新薬を策定するのにかかる時間を大幅に短縮することから、より環境に優しいエネルギーを生み出すまで、企業が新境地を破る大きな機会があります。 しかし、大きな問題があります:スキルを持っている人々が深刻な不足があります
 プロトタイプ:これらの細菌は電気を生成できますMay 03, 2025 am 11:08 AM
プロトタイプ:これらの細菌は電気を生成できますMay 03, 2025 am 11:08 AM数年前、科学者は、特定の種類のバクテリアが酸素を摂取するのではなく、電気を生成することで呼吸するように見えることを発見しましたが、どのようにしたのかは謎でした。 Journal Cellに掲載された新しい研究は、これがどのように起こるかを特定しています:微生物
 AIとサイバーセキュリティ:新政権の100日間の計算May 03, 2025 am 11:07 AM
AIとサイバーセキュリティ:新政権の100日間の計算May 03, 2025 am 11:07 AM今週のRSAC 2025会議で、SNYKは「The First 100 Days:How AI、Policy&Cybersecurity Collide」というタイトルのタイムリーなパネルを開催しました。ニコール・ペルロス、元ジャーナリストとパートネ


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

Dreamweaver Mac版
ビジュアル Web 開発ツール

MinGW - Minimalist GNU for Windows
このプロジェクトは osdn.net/projects/mingw に移行中です。引き続きそこでフォローしていただけます。 MinGW: GNU Compiler Collection (GCC) のネイティブ Windows ポートであり、ネイティブ Windows アプリケーションを構築するための自由に配布可能なインポート ライブラリとヘッダー ファイルであり、C99 機能をサポートする MSVC ランタイムの拡張機能が含まれています。すべての MinGW ソフトウェアは 64 ビット Windows プラットフォームで実行できます。

PhpStorm Mac バージョン
最新(2018.2.1)のプロフェッショナル向けPHP統合開発ツール

SublimeText3 英語版
推奨: Win バージョン、コードプロンプトをサポート!

SAP NetWeaver Server Adapter for Eclipse
Eclipse を SAP NetWeaver アプリケーション サーバーと統合します。
ホットトピック
 7943
7943 15165214141252130325125029
15165214141252130325125029