
ホームページ >テクノロジー周辺機器 >AI >ガイダンスを必要とせず、一般化された視覚化モデルで使用できる、家具および家電製品用の初のユニバーサル 3D グラフィックスおよびテキスト モデル システム
ガイダンスを必要とせず、一般化された視覚化モデルで使用できる、家具および家電製品用の初のユニバーサル 3D グラフィックスおよびテキスト モデル システム

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2024-01-09 19:30:25799ブラウズ
最近では家事はすべてロボットがやってくれます。
スタンフォードからポットが使えるロボットが登場し、コーヒーマシンが使えるロボットも登場しました、Figure-01。

#図-01 デモンストレーション ビデオを見て、コーヒー マシンを上手に操作できるように 10 時間のトレーニングを実施するだけです。コーヒーカプセルの挿入からスタートボタンを押すまで、すべてが一度に完了します。
しかし、ロボットがさまざまな家具や家電製品に出会ったときに、デモンストレーションビデオなしでその使い方を自主的に学習できるようにするのは難しい問題です。そのためには、ロボットには、正確な操作スキルだけでなく、強力な視覚認識と意思決定計画能力も必要です。

論文リンク: https://arxiv.org/abs/2312.01307
プロジェクト ホームページ: https://geometry.stanford.edu/projects/ sage/
コード: https://github.com/geng-haoran/SAGE
研究問題の概要

#図 1: 人間の指示に従って、ロボット アームは指示なしでさまざまな家電製品を使用できます。
最近、PaLM-E と GPT-4V はロボットのタスク計画における大規模なグラフィック モデルの適用を推進しており、視覚言語による汎用ロボット制御が人気の研究分野となっています。
以前は 2 層のシステムを構築するのが一般的で、上位層の大型グラフィック モデルが計画とスキルのスケジューリングを行い、下位層の制御スキル戦略モデルが物理的なアクションの実行を担当します。しかし、ロボットがこれまで見たことのないさまざまな家電製品に直面し、家事において多段階の操作が必要となると、既存の手法の上層部も下層部も無力になってしまいます。
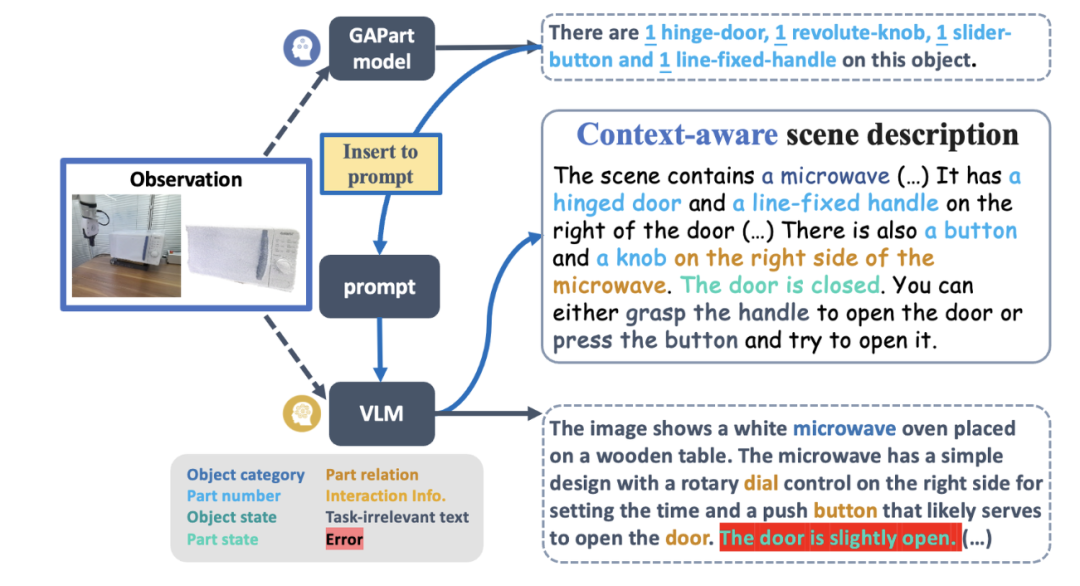
最新鋭のグラフィックモデル GPT-4V を例にとると、1 枚の絵を文字で表現することはできますが、操作可能な部品の検出、カウント、位置決め、状態推定に関しては、まだ完全な機能を備えています。間違いの。図 2 の赤いハイライトは、タンス、オーブン、およびスタンディング キャビネットの写真を記述する際に GPT-4V が犯したさまざまなエラーです。誤った説明に基づくと、ロボットのスキルのスケジュール設定は明らかに信頼できません。

#図 2: GPT-4V はカウント、検出などをあまり処理しません##まあ #位置決め、状態推定、およびその他の汎用制御に重点を置いたタスク。 下位レベルの制御スキル戦略モデルは、さまざまな実際の状況において、上位レベルのグラフィックおよびテキスト モデルによって与えられたタスクを実行する責任を負います。既存の研究成果の多くは、既知の物体の把持点や操作方法をルールに基づいて厳密にコード化したものであり、これまでに見たことのない新たな物体カテゴリーには一般的に対応できていない。ただし、エンドツーエンドの操作モデル (RT-1、RT-2 など) は RGB モダリティのみを使用し、距離の正確な認識に欠け、高さなどの新しい環境の変化に対する一般化が不十分です。
Wang He 教授のチームによる以前の CVPR ハイライト作品 GAPartNet [1] に触発されて、研究チームはさまざまなカテゴリの家電製品の共通部品 (GAPart) に焦点を当てました。家電製品は常に変化していますが、不可欠な部品は常にいくつかあり、各家電製品とこれらの共通部品の間には、同様の形状と相互作用パターンがあります。
その結果、研究チームは論文 GAPartNet [1] で GAPart の概念を導入しました。 GAPart は、一般化可能な対話型コンポーネントを指します。 GAPart は、さまざまなカテゴリのヒンジ付きオブジェクトに表示されます。たとえば、開き戸は、金庫、ワードローブ、冷蔵庫に見られます。図 3 に示すように、GAPartNet [1] は、さまざまなタイプのオブジェクトの GAPart のセマンティクスとポーズに注釈を付けます。

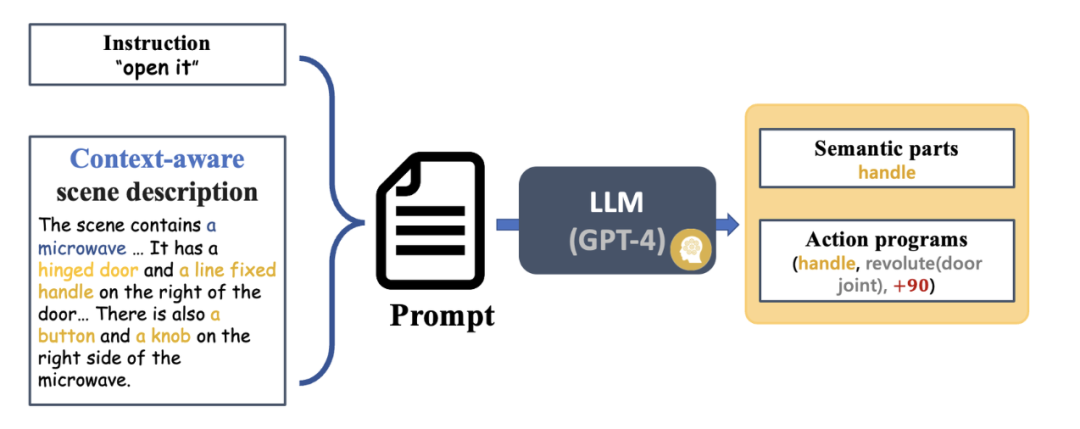
図 3: GAPart: 一般化可能な対話型コンポーネント [1]。 先行研究に基づいて、研究チームは、3次元視覚に基づくGAPartをロボットの物体操作システムSAGEに創造的に導入しました。 SAGE は、一般化可能な 3D パーツ検出と正確な姿勢推定を通じて、VLM と LLM に情報を提供します。この新手法は、意思決定レベルでは、2次元グラフィックモデルの正確な計算と推論能力が不十分であるという問題を解決し、実行レベルでは、新手法は、 GAパーツのポーズ。 SAGE は、初の三次元具現化グラフィックとテキストの大規模モデル システムを構成し、知覚、物理的相互作用からフィードバックに至るロボットのリンク全体に新しいアイデアを提供し、ロボットが家具や家具をインテリジェントかつユニバーサルに制御できるようにします。家電製品など。複雑なオブジェクトが可能なパスを探索します。 システムの紹介 図 4 は、SAGE の基本プロセスを示しています。まず、コンテキストを解釈できる命令解釈モジュールが、ロボットに入力された命令とその観察結果を解析し、これらの解析結果を次のロボットの動作プログラムとそれに関連する意味部分に変換します。次に、SAGE はセマンティック部分 (コンテナなど) を操作する必要がある部分 (スライダー ボタンなど) にマッピングし、タスクを完了するためのアクション (ボタンの「押す」アクションなど) を生成します。 # 図 4: メソッドの概要。 概要SAGE は、家具や家具などの複雑な関節オブジェクトに対する一般的な操作命令を生成できる初の 3 次元視覚言語モデル フレームワークです。家電。オブジェクトのセマンティクスと操作性の理解を部品レベルで結びつけることにより、言語で指示されたアクションを実行可能な操作に変換します。 さらに、この記事では、一般的な大規模な視覚/言語モデルとドメイン エキスパート モデルを組み合わせて、ネットワーク予測の包括性と正確性を強化する方法についても研究しています。これらのタスクを適切に処理して、最先端のパフォーマンスを実現します。実験結果は、このフレームワークが強力な一般化機能を備えており、さまざまなオブジェクト カテゴリやタスクで優れたパフォーマンスを実証できることを示しています。さらに、この記事は、多関節オブジェクトの言語ガイドによる操作の新しいベンチマークを提供します。 SAGE この研究結果は、スタンフォード大学のレオニダス・ギバス教授の研究室、スタンフォード大学のワン・ヘ教授の身体的知覚および相互作用(EPIC研究室)から得られたものです。北京大学および知能知能研究所出典人工知能研究所。論文の著者は北京大学の学生でスタンフォード大学客員研究員の耿浩然氏(共著者)、北京大学博士課程の学生魏松林氏(共著者)、スタンフォード大学博士課程の学生鄧相悦氏と沈博毅氏、監修者はレオニダス教授です。ギバスと王鶴教授。
[1] Haoran Geng、Helin Xu、Chengyang Zhao、Chao Xu、Li Yi 、黄思源と王何。 Gapartnet: 一般化可能で実行可能な部分を介した、カテゴリを超えたドメインの一般化可能なオブジェクトの認識と操作。 arXiv プレプリント arXiv:2211.05272、2022。 [2] Kirillov、Alexander、Eric Mintun、Nikhila Ravi、Hanzi Mao、Chloe Rolland、Laura Gustafson、Tete Xiao他。 「何でもセグメント化します。」 arXiv プレプリント arXiv:2304.02643 (2023). [3] チャン、ハオ、フェン リー、シロン リウ、レイ チャン、ハン スー、ジュン ジュー、ライオネル M.ニーさんとフンヨン・シュムさん。 「Dino: エンドツーエンドの物体検出のための改善されたノイズ除去アンカー ボックスを備えた Detr。」 arXiv プレプリント arXiv:2203.03605 (2022). [4] Xiang 、ファンボ、Yuzhe Qin、Kaichun Mo、Yikuan Xia、Hao Zhu、Fangchen Liu、Minghua Liu 他。 「Sapien: シミュレートされたパーツベースのインタラクティブ環境」。コンピュータ ビジョンとパターン認識に関する IEEE/CVF 会議議事録、pp. 11097-11107.2020.
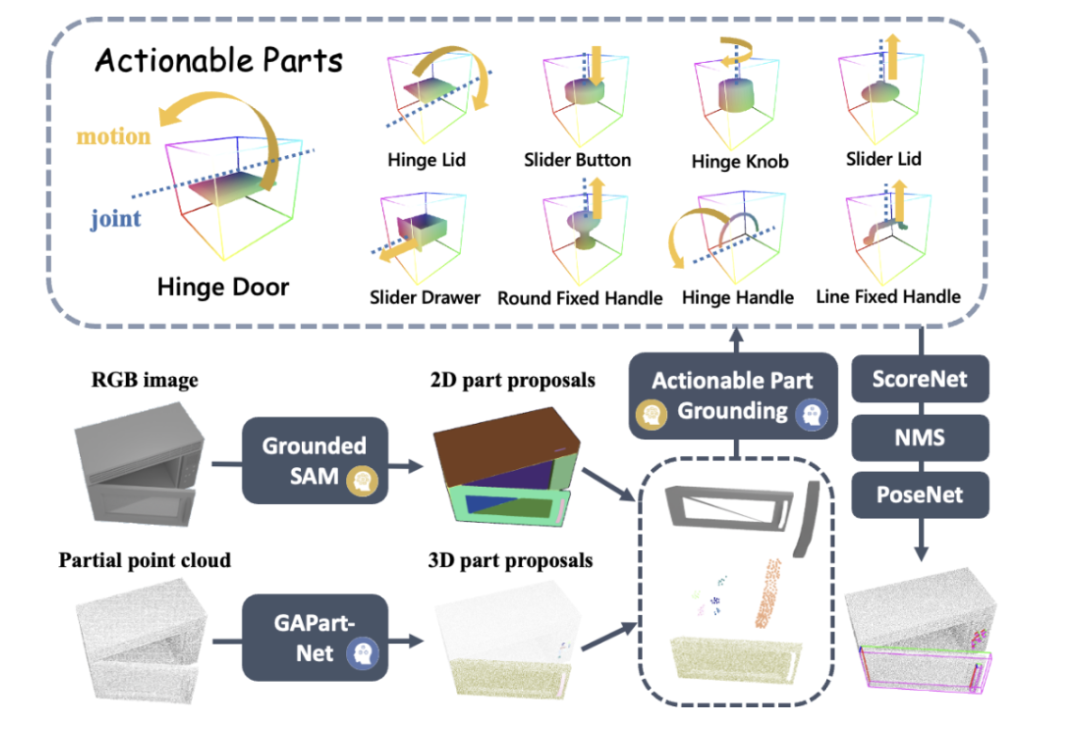
観測値を入力するプロセスで、SAGE は、GroundedSAM からの 2 次元 (2D) キューと GAPartNet からの 3 次元 (3D) キューを組み合わせます。これらの手がかりは、操作可能な部分の特定の位置決めとして使用されます。研究チームは、ScoreNet、非最大抑制 (NMS)、および PoseNet を使用して、新しい方法の知覚結果を実証しました。
その中には: (1) 部分を意識した評価ベンチマークについては、この記事では SAM [2] を直接使用しています。ただし、操作フローでは、この記事では、セマンティック部分も入力として考慮される、GroundedSAM を使用します。 (2) ラージ言語モデル (LLM) が操作可能な部分のターゲットを直接出力する場合、位置決めプロセスはバイパスされます。 
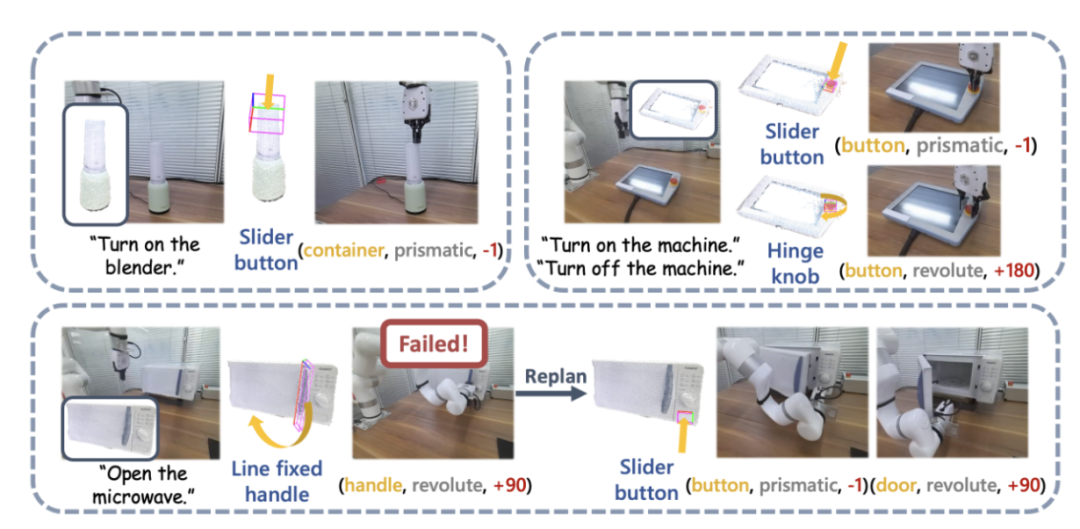
#アクション生成
インタラクティブなフィードバック

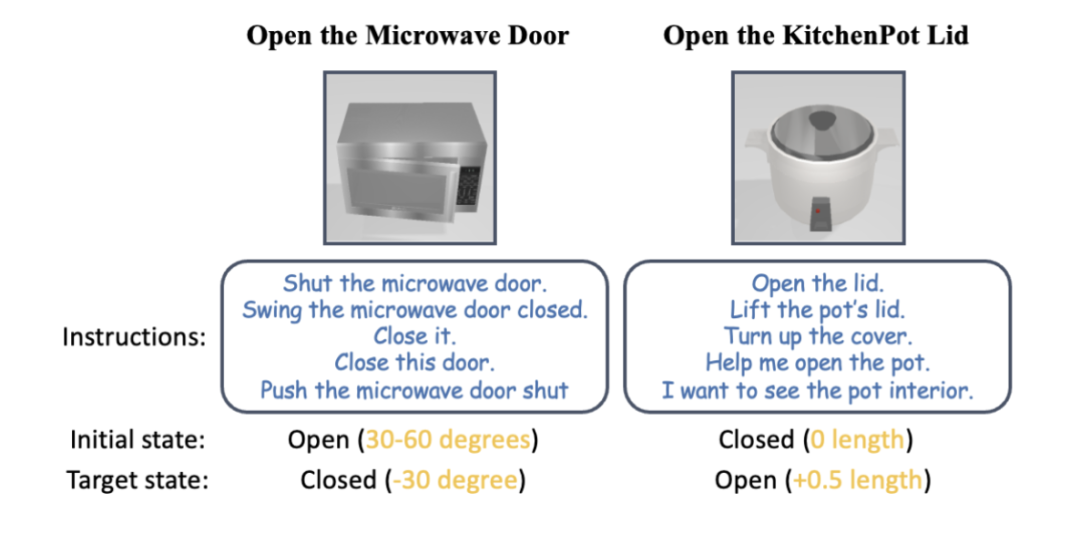
 チーム紹介
チーム紹介
以上がガイダンスを必要とせず、一般化された視覚化モデルで使用できる、家具および家電製品用の初のユニバーサル 3D グラフィックスおよびテキスト モデル システムの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。