
ホームページ >テクノロジー周辺機器 >AI >清華大学の新しい方法は、正確なビデオクリップの位置を特定することに成功しました。 SOTA を超えてオープンソース化
清華大学の新しい方法は、正確なビデオクリップの位置を特定することに成功しました。 SOTA を超えてオープンソース化

- WBOY転載
- 2024-01-09 15:26:221233ブラウズ
たった 1 文の説明で、大きなビデオ内の対応するクリップを見つけることができます。
## たとえば、「階段を下りながら水を飲む人」を説明する場合、ビデオ画像と足音を照合することで、新しい方法は対応する開始タイムスタンプと終了タイムスタンプをすぐに見つけることができます。 

Adaptive と呼ばれます。清華大学の研究チームによって提案されたデュアル ブランチ プロモーション ネットワーク (ADPN)。
具体的には、ADPN は、ビデオ クリップの位置決め(Temporal Sentence Grounding、TSG) と呼ばれる視覚言語クロスモーダル タスクを完了するために使用されます。つまり、クエリ テキストに基づいて、ビデオ 関連するセグメントを見つけます。
ADPN は、ビデオ内のビジュアルおよびオーディオ モダリティの一貫性 と 相補性 を効率的に利用して、ビデオ クリップの位置決めパフォーマンスを向上させる機能を特徴としています。
オーディオを使用する他の TSG 作品 PMI-LOC および UMT と比較して、ADPN 方式はオーディオ モードからの大幅なパフォーマンス向上を実現し、複数のテストで新しい SOTA を獲得しました。 この作品は ACM Multimedia 2023 に承認されており、完全にオープンソースです。
( Temporal Sentence Grounding (TSG) は、視覚と言語を横断する重要なタスクです。
その目的は、自然言語クエリに基づいて、未編集のビデオ内で意味的に一致するセグメントの開始タイムスタンプと終了タイムスタンプを見つけることです。このメソッドには、強力な時間的クロスモーダル推論機能が必要です。 しかし、既存の TSG 手法のほとんどは、RGB、オプティカル フロー、深さ (深度) などのビデオ内の視覚情報のみを考慮し、自然に付随する音声情報を無視します。ビデオ。 音声情報には多くの場合、豊富なセマンティクスが含まれており、視覚情報と一貫性があり、補完的です。以下の図に示すように、これらのプロパティは TSG タスクに役立ちます。
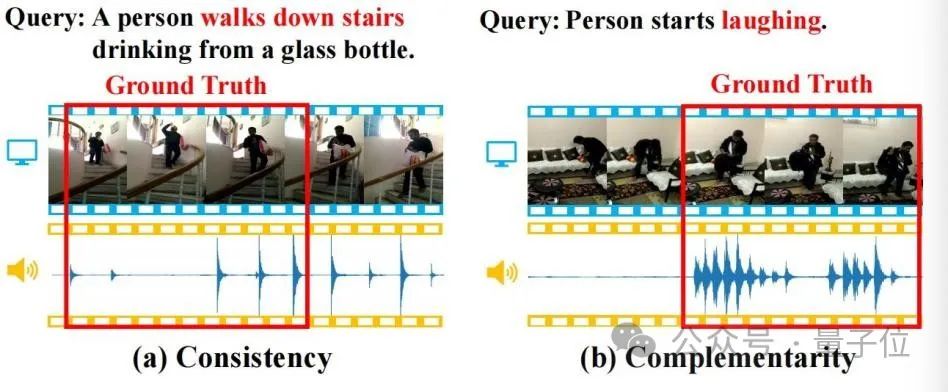 △図 1
△図 1
(a) 一貫性: ビデオ画像と足音は、クエリ セマンティクスの「階段を降りる」と一貫して一致します。 (b) 相補性: クエリ内の「笑い」の意味を特定するためにビデオ画像内の特定の動作を識別することは困難ですが、笑いの出現は強力な相補的な位置決めの手がかりを提供します。 したがって、研究者は、視覚と音声の位置決め手がかりのキャプチャをより適切に組み合わせるために、音声強化されたビデオクリップの位置決めタスク
(音声強化された時間的センテンス グランディング、ATSG)を徹底的に研究しました。ただし、モーダルではオーディオ モーダルの導入により、次の課題も生じます。
オーディオ モダリティとビジュアル モダリティの一貫性と相補性はクエリ テキストに関連付けられているため、オーディオとビジュアルの一貫性と相補性を把握することは困難です。テキスト、ビジュアル、オーディオの 3 つのモーダル インタラクションのモデリングが必要です。- 聴覚と視覚の間には大きなモードの違いがあり、両者の情報密度とノイズ強度が異なるため、視聴覚学習のパフォーマンスに影響します。
- 上記の課題を解決するために、研究者らは新しい ATSG 手法「
」(Adaptive Dual-branch Prompted Network、ADPN) を提案しました。 。 デュアルブランチ モデル構造設計を通じて、この方法はオーディオと視覚の間の一貫性と相補性を適応的にモデル化し、コース学習に基づいたノイズ除去最適化戦略を使用してノイズをさらに除去できます。ビデオ検索における音声信号の重要性が明らかになりました。
ADPN の全体構造を次の図に示します。
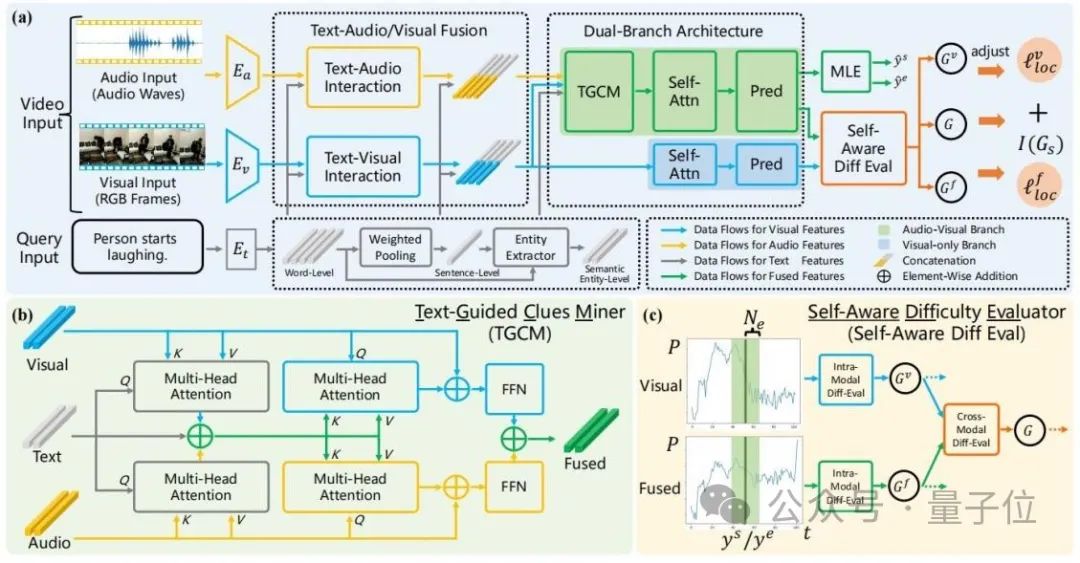 △図 2: Adaptive Dual Branch Promotion Network (ADPN) の全体構成図
△図 2: Adaptive Dual Branch Promotion Network (ADPN) の全体構成図
主に 3 つの設計が含まれます:
1. 2 分岐ネットワーク構造設計# オーディオのノイズがより顕著であることを考慮し、TSG 向けタスクでは、音声は通常、より冗長な情報があるため、音声モダリティと視覚モダリティの学習プロセスには異なる重要性を与える必要があります。したがって、この記事では、マルチモーダル学習に音声と視覚を使用するデュアルブランチ ネットワーク構造が含まれます。視覚情報の扱いを強化する。
具体的には、図 2(a) を参照すると、ADPN は視覚情報のみを使用するブランチ (ビジュアル ブランチ) と視覚情報と音声情報の両方を使用するブランチ (ジョイント ブランチ)## を同時に学習します。 #。 2 つのブランチは類似した構造を持ち、結合ブランチにはテキストガイド付き手がかりマイニング ユニットが追加されています
(TGCM)テキスト、視覚、音声のモーダル インタラクションをモデリングします。トレーニング プロセス中、2 つのブランチはパラメーターを同時に更新し、推論フェーズでは結合ブランチの結果をモデル予測結果として使用します。
2. テキストガイド付き手がかりマイニング ユニット(テキストガイド付き手がかりマイナー、TGCM)音声と視覚のモダリティの一貫性の検討セックスと相補性は特定のテキスト クエリに基づいて条件付けされるため、研究者らはテキスト、ビジュアル、オーディオの 3 つのモダリティ間の相互作用をモデル化する TGCM ユニットを設計しました。
図 2(b) を参照すると、TGCM は「抽出」と「伝播」の 2 つのステップに分かれています。
まず、テキストをクエリ条件として、映像モダリティと音声モダリティから関連情報を抽出して統合し、その後、映像モダリティと音声モダリティをクエリ条件として、統合された情報を拡散する視覚と聴覚のそれぞれのモードに注意を払い、最後にFFNによる機能の融合を実現します。
3. コース学習の最適化戦略研究者らは、音声にはマルチモーダル学習の効果に影響を与えるノイズが含まれていることを観察したため、音声の強度を使用しました。サンプルの難易度を参照するために、最適化プロセスのノイズを除去するためにカリキュラム学習 (CL)
が導入されています (図 2(c) を参照)。彼らは、2 つのブランチの予測出力の差に基づいてサンプルの難易度を評価します。難しすぎるサンプルは、そのオーディオに多すぎるノイズが含まれている可能性が高く、適切ではないと考えています。 TSG タスクでは、スコアに基づいてサンプルの難易度を評価します。トレーニング プロセスの損失関数項は、オーディオ内のノイズによって引き起こされる悪い勾配を破棄するために再重み付けされます。
(残りのモデル構造とトレーニングの詳細については、原文を参照してください。)
新しい SOTA の複数のテスト
ベンチマーク データTSG タスクの研究者の数 Charades-STA と ActivityNet Captions について実験評価を実施し、ベースライン手法との比較を表 1 に示します。 ADPN 方式は SOTA パフォーマンスを達成できます。特に、オーディオを利用する他の TSG ワーク PMI-LOC および UMT と比較して、ADPN 方式はオーディオ モードからより大幅なパフォーマンス向上が得られます。これは、ADPN 方式がオーディオモダリティはTSGの優位性を促進します。△表 1: Charades-STA と ActivityNet のキャプションの実験結果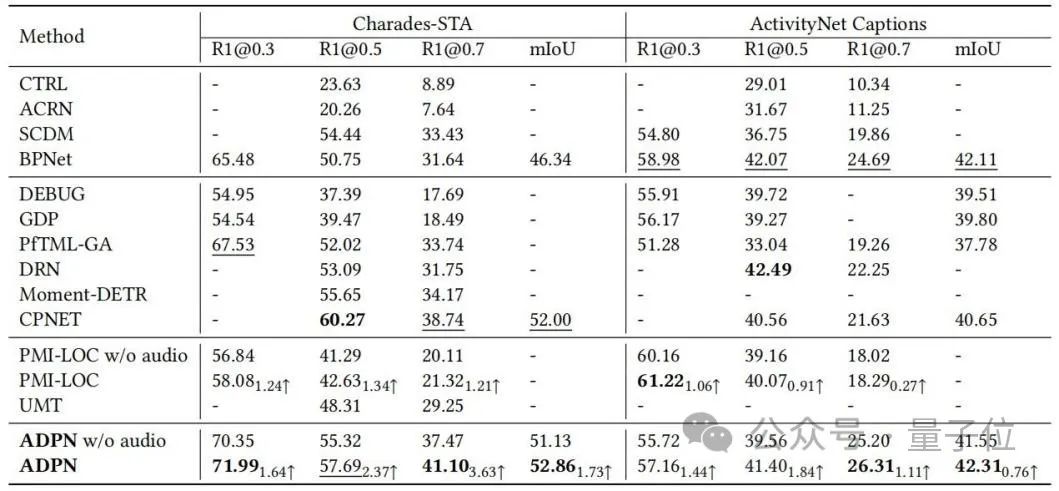
研究者らは、アブレーション実験を通じて、ADPN におけるさまざまな設計単位の有効性をさらに実証しました。 、表 2 に示すとおり。
△表 2: Charades-STA でのアブレーション実験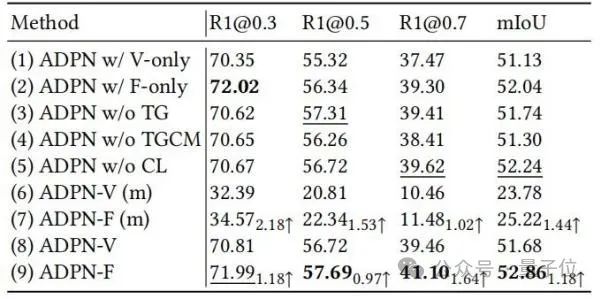
研究者らは視覚化するためにいくつかのサンプルの予測結果を選択し、TGCM を描画しました。図 3 に示すように、「ステップ」における「テキストからビジョン」(T→V) と「テキストからオーディオ」(T→A) の注意の重み配分。 オーディオ モダリティの導入により、予測結果が改善されることがわかります。 「人はそれを笑う」の事例から、T→Aの注目の重み分布がGround Truthに近く、T→Vの重み分布によってモデル予測の誤った誘導が修正されることがわかります。
△図 3: ケースの表示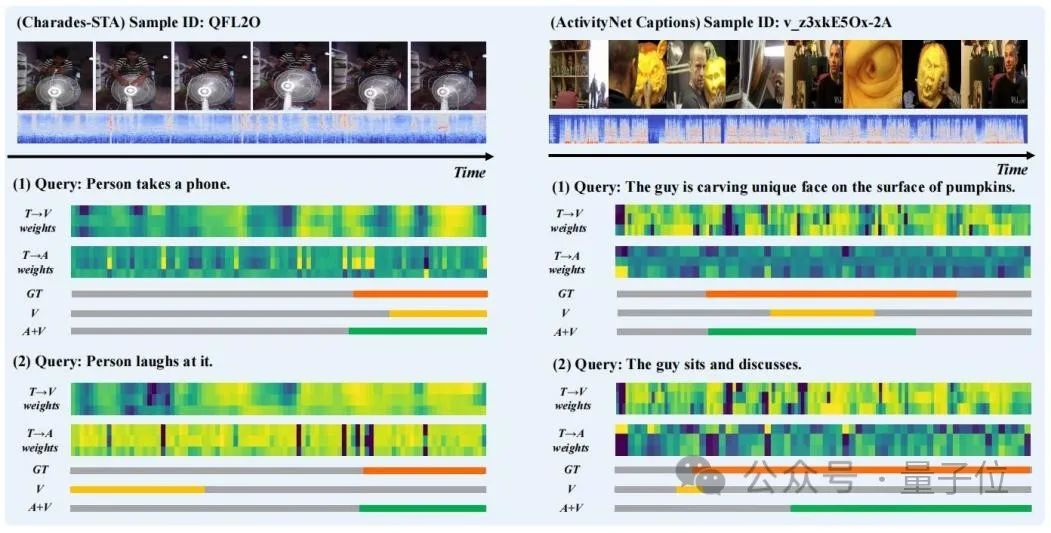
一般に、この記事の研究者は、新しい適応型デュアルブランチ プロモーション ネットワーク(ADPN) を提案しました。
オーディオ拡張ビデオ クリップの位置決め(ATSG) の問題を解決します。 彼らは、聴覚モダリティと視覚モダリティの間の情報の違いを解決するために、視覚ブランチと視聴覚結合ブランチを共同でトレーニングするためのデュアルブランチ モデル構造を設計しました。
彼らはまた、テキストのセマンティクスをガイドとして使用して、テキストと音声と視覚のインタラクションをモデル化する、テキストガイド付き手がかりマイニング ユニット(TGCM)
も提案しました。最後に、研究者らは、音声ノイズをさらに除去し、ノイズ強度の尺度としてサンプルの難易度を自己認識的な方法で評価し、最適化プロセスを適応的に調整するためのコース学習ベースの最適化戦略を設計しました。
彼らはまず、オーディオ モダリティのパフォーマンス向上効果をさらに向上させるために、ATSG のオーディオの特性について徹底的な研究を実施しました。 将来的には、ATSG のより適切な評価ベンチマークを構築し、この分野でのより詳細な研究を促進したいと考えています。論文リンク: https://dl.acm.org/doi/pdf/10.1145/3581783.3612504
ウェアハウス リンク: https://github.com/hlchen23 /ADPN-MM
以上が清華大学の新しい方法は、正確なビデオクリップの位置を特定することに成功しました。 SOTA を超えてオープンソース化の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。