
ホームページ >テクノロジー周辺機器 >AI >大規模モデル アプリケーションの探索 - Enterprise Knowledge Steward
大規模モデル アプリケーションの探索 - Enterprise Knowledge Steward

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2024-01-08 08:49:431452ブラウズ

1. 従来のナレッジ マネジメントの背景と課題
1. エンタープライズ ナレッジ マネジメントの必要性
現代の企業では、ナレッジ マネジメントが重要です。は重要なリンクです。企業が社内外の知識リソースを効果的に整理して活用できるようにすることで、企業の効率と競争力を向上させることができます。ナレッジをより適切に管理するために、多くの企業はナレッジ スチュワードの概念を導入しています。ナレッジ スチュワードは、企業の知識の管理と普及を特に担当する役割またはシステムです。ナレッジ スチュワードを通じて、企業は
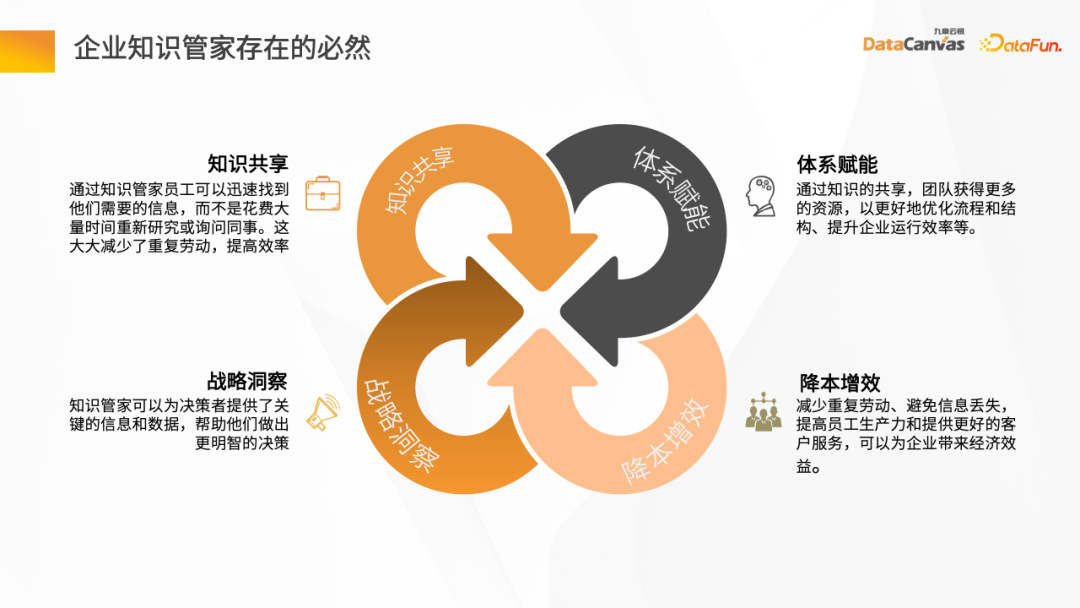
##急速な発展と知識の爆発的な増加に伴い、より適切に情報を収集し、整理することができます。企業は知識を共有するという課題に直面しています。企業内で知識を効果的に伝達し、共有する方法が重要な課題となっています。知識の共有により、企業は作業効率を向上させるだけでなく、作業の重複を回避することができます。
もう 1 つの方法は、知識共有モデルを採用して企業に力を与えるメカニズムを確立し、それによってプロセスと結果をより最適化し、企業の業務効率を向上させることです。このモデルにより、企業内の従業員が知識や経験を共有できるようになり、チームの全員が利益を得られるようになります。知識を共有することで、企業は努力の重複を避け、間違いや間違いを減らし、課題や変化によりよく対応できるようになります。この
さらに、ナレッジ スチュワードとして、重要な情報とデータを意思決定者に提供して、より多くの情報に基づいた意思決定を支援することもできます。 Knowledge Butlerは強力な情報検索・分析機能を備えており、膨大なデータから有用な情報を抽出し、統合・分析することができます。この情報とデータには、市場動向、競合他社の分析、消費者に関する洞察、技術開発などが含まれます。
さらに、非常に重要な要素は、企業従業員の作業負荷を軽減し、情報漏えいを防止することです。損失を削減し、従業員の作業効率と顧客サービスレベルを向上させ、コストの削減と効率の向上という目標を達成します。
2. エンタープライズ ナレッジ マネジメントの課題大規模なモデルが存在する前は、ナレッジ スチュワードを構築するロジックは非常に複雑でした。通常、私たちはナレッジ ベースの概念を使用して、エンタープライズ ナレッジ グラフや企業の内部データを利用してナレッジ ベースを構築します。しかし、この建設プロセスでは多くの課題に直面しています。 まず、知識ベースの構築には多大な人的資源と時間の投資が必要です。企業内の知識や情報を収集、整理、要約することは、退屈で時間のかかる作業です。このデータを処理および管理し、
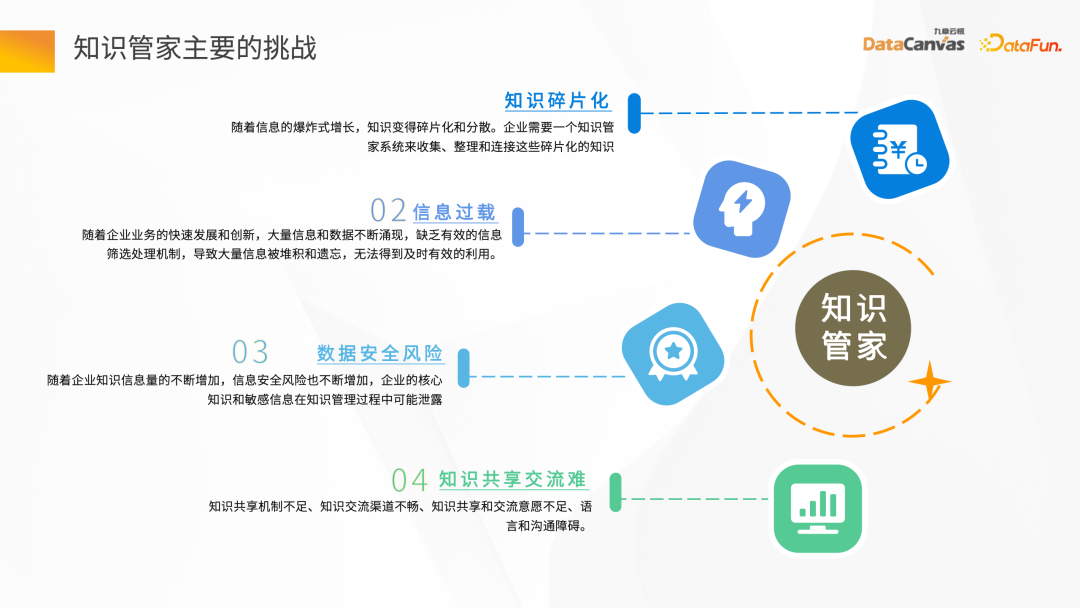
- #知識の断片化を確実にするには専門チームが必要です 知識の断片化は、主に 2 つの側面に反映されています。1 つの側面は、企業のデータが非常に分散していることです。たとえば、OA システムのデータにはさまざまな部門やさまざまなチームが存在します。一方、これらのデータは基本的にWord、PDF、写真、動画などの非構造化形式で提供されます。ナレッジ スチュワードを構築するプロセスでは、断片化された情報を迅速に一元化する方法が最初の課題です。
#情報過多
- ##エンタープライズ ビジネスの急速な発展の中で、企業は次のような問題に直面しています。大量の情報とデータ 増え続ける状況下では、情報の正確性と適時性を確保するために、大量のデータのスクリーニングメカニズムをどのように確立するかも大きな課題です。
データ セキュリティ リスク
- 企業は通常、自社の個人データを他の機関と共有しません。または、組織は通常、企業のプライベート ドメイン データのデータ セキュリティにより注意を払うため、データ セキュリティのリスクにも対処する必要があります。
知識の共有とコミュニケーションの難しさ
- 企業によって組織構造が異なります。より技術的なもの、ビジネス指向のもの、テクノロジーとビジネスが混合したものもありますが、ビジネスとテクノロジーの間のコミュニケーションの過程において、コミュニケーション不足はあらゆる企業が知識共有において直面する問題です。
2. ナレッジ スチュワード ソリューション
1. エンタープライズ ナレッジ スチュワードとは
エンタープライズ ナレッジ スチュワードは、知識全体の保存と理解を支援する人間の脳に似ています。そして知識を創造します。
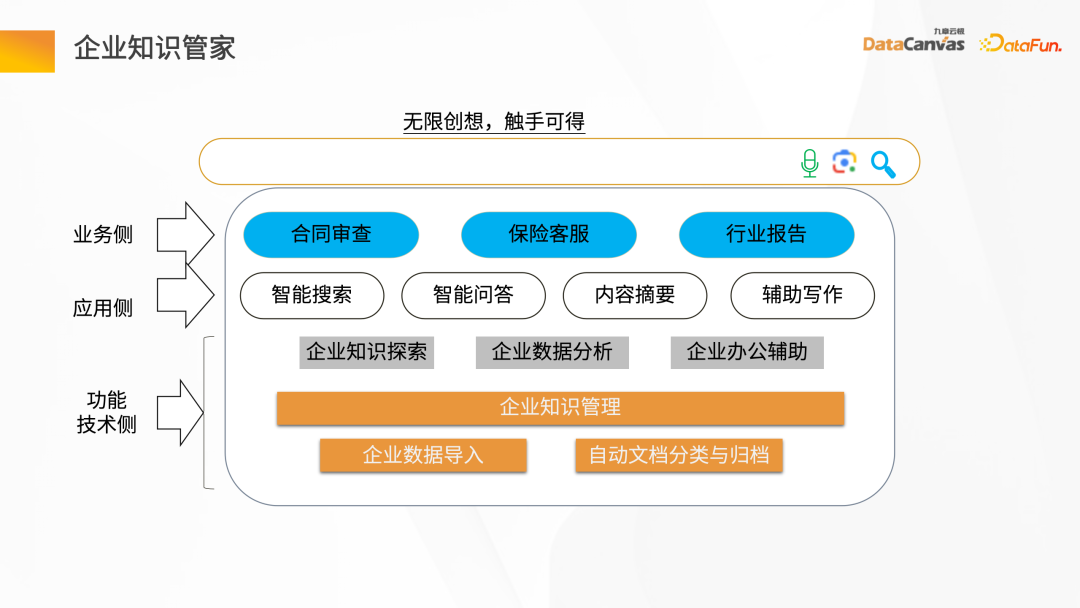
エンタープライズ ナレッジ スチュワードは通常 3 つのレベルに分かれています。最初のレベルは機能的および技術的なニーズであり、主にエンタープライズ ナレッジの管理を担当します。エンタープライズ データのインポート、ドキュメントの自動分類とアーカイブ、その他の基本的な機能要件が含まれます。中間層は、インテリジェントな質問と回答、インテリジェントな検索、概要の生成、補助的な書き込み、その他の機能の提供を含むアプリケーション側の要件です。上位層は、契約レビュー、保険顧客サービス、業界レポートの作成など、ビジネス側の要件です。
通常、Knowledge Butler によって提供されるインターフェイスには 3 つのモードがあります。最初のインターフェイスはテキスト ボックスに似ており、ナレッジの探索と分析を提供します。もう 1 つは API トークンを使用してインテリジェント エージェントに提供します。さまざまなアプリケーション シナリオに関与する情報は、企業のビジネス システムと統合するために API トークンとして公開されます。3 番目の方法は、会話モードを通じて知識を探索および分析するインテリジェント エージェントです。
#2. エンタープライズ ナレッジ スチュワード ソリューションエンタープライズ ナレッジ スチュワードは、主に次のビジネス シナリオを含む、エンタープライズ固有のナレッジ管理と作成を担当します。

- インテリジェントな Q&A
企業独自のプライベート ドメイン データと組み合わせる、ベクトル化後、ベクトル データベースに保存され、質問と回答モードを使用してインテリジェントな質問と回答のシナリオを作成します。これらのシナリオを通じて、より多くの具体的なビジネス ニーズを導き出すことができます。
- #セルフサービス ドキュメント分析 ## ドキュメントを通じて調査と分析を実行します。論文を探索するには、論文の内容について質問することができます。また、文書全体のセグメント化されたプレビュー、状況に応じた検索、概要の概要などの機能を提供して、文書の独立した分析を実行することもできます。
#カスタマイズされたロール シナリオ
- 内部のさまざまなロールのプライベート ドメイン データと組み合わせます。エンタープライズ向けに、プロンプト ワード モードと組み合わせることで、文書の作成支援やインテリジェントな会議議事録など、いくつかのカスタマイズされたシナリオのデザインを提供します。
#契約レビュー
- は、人間とコンピューターの対話モードを採用し、さまざまな監査を実施します。企業 いくつかの重要な条件に関する契約情報を検討し、対応する情報が正確であるかどうかを確認します。
Enterprise Knowledge Butler 製品の主な機能は次のとおりです。
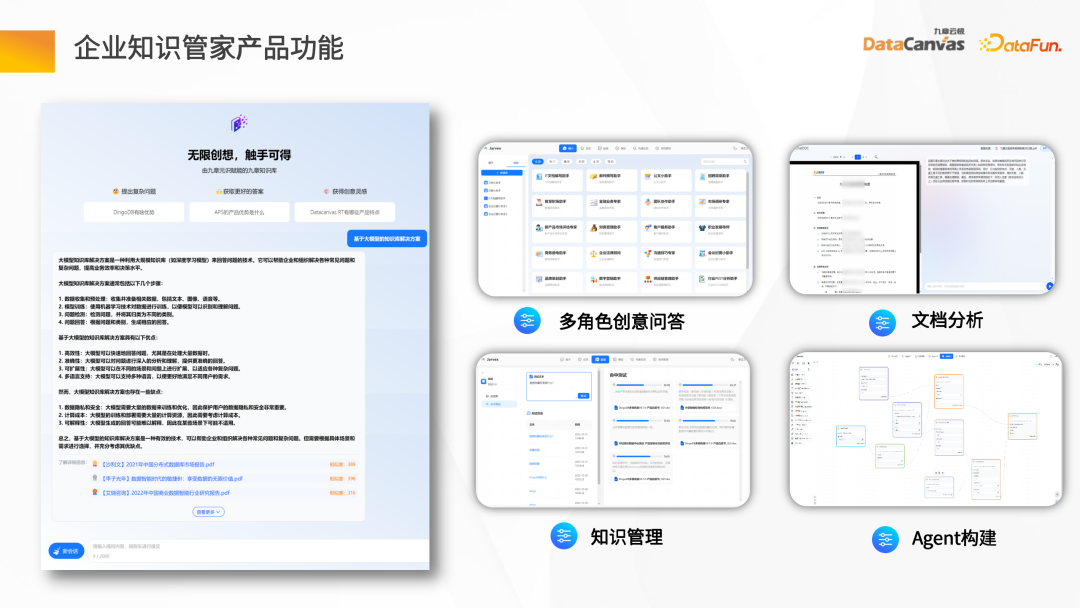 インテリジェントな Q&A : 特定の質問を組み合わせ、コンテキストを取得することでソースベースの回答を取得します。
インテリジェントな Q&A : 特定の質問を組み合わせ、コンテキストを取得することでソースベースの回答を取得します。
- マルチロールクリエイティブ Q&A: プロンプトワードと企業のプライベートドメインデータを通じてインテリジェントなアプリケーションシナリオを構築します。
- #ドキュメント分析: 概要分析または探索的分析のためにドキュメント全体をインポートします。
- ナレッジ管理: 企業データはナレッジ マネージャーを通じて完全に自動的に管理され、プロセス全体は非常にシンプルなモデルを採用しています。
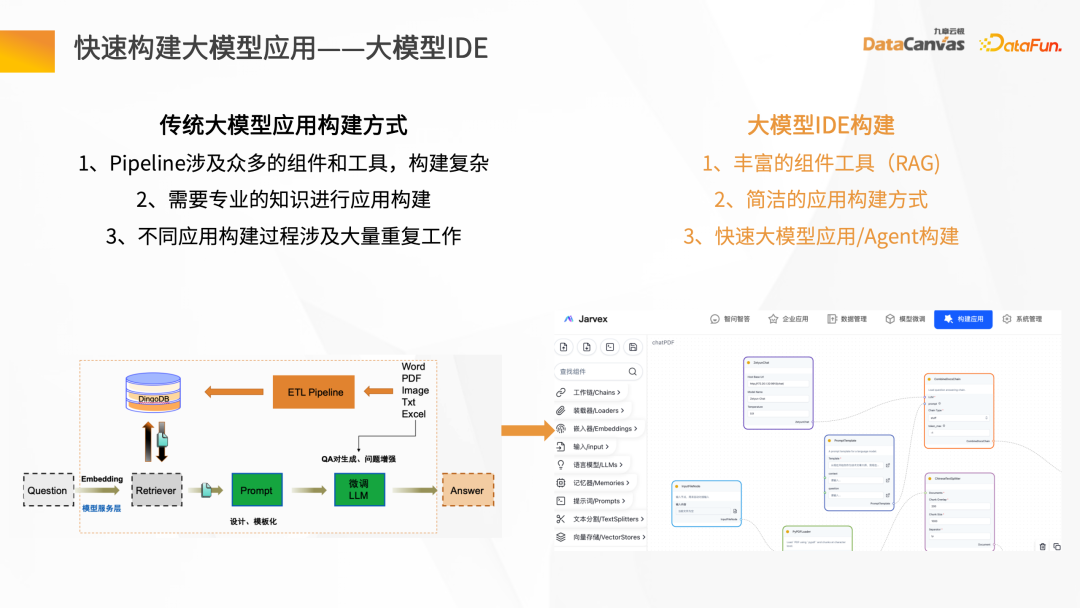
- #エージェント ビルド: 開発プラットフォーム、つまり大規模モデル IDE 機能。
- Knowledge Butler の機能アーキテクチャ:
下部は GPU計算パワーには 2 つのカテゴリがあり、1 つは推論コンピューティング パワー、もう 1 つは微調整コンピューティング パワーです。中間層は、安全で信頼できるエンタープライズ プライベート ドメイン データ メモリである DingoDB マルチモード ベクトル データベースです。
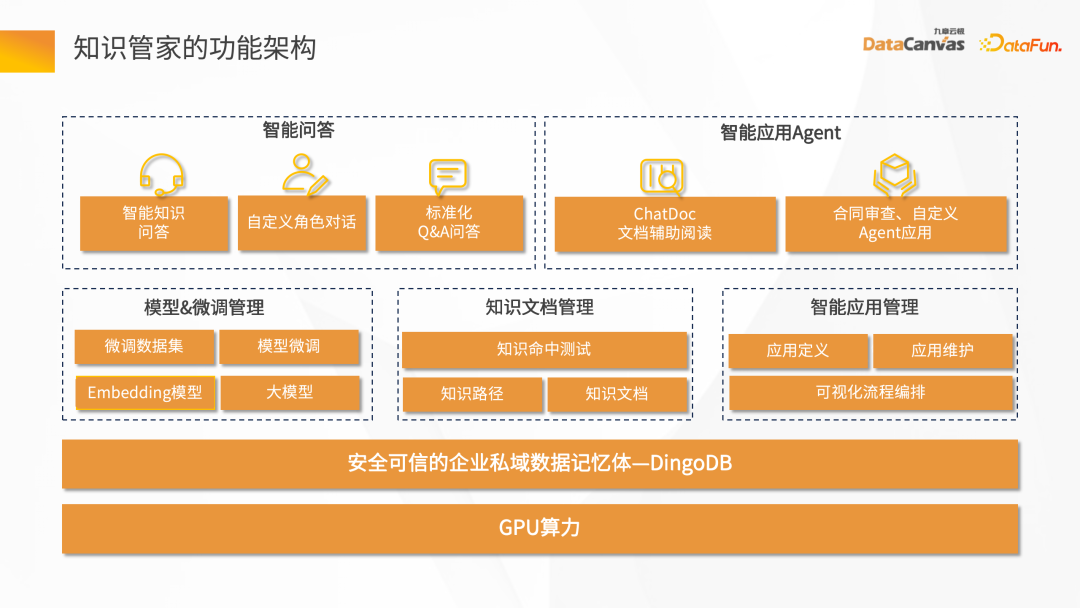
次の層は、モデル微調整管理、ナレッジ ドキュメント管理、インテリジェント アプリケーション管理など、技術層全体の機能ポイントです。
一番上のものはビジネス シナリオのニーズ向けです。インテリジェント Q&A では、役割の一部のダイアログ、標準の QA Q&A、およびインテリジェント アプリケーション、ドキュメントベースの補助読み取り、契約レビュー、および保険のエージェントをカスタマイズできます。アシスタント。
3. ナレッジ スチュワードのコア技術の探索1. ナレッジ スチュワード構築プロセス
次に、インテリジェントな質疑応答シナリオを通じて、ナレッジ スチュワード構築プロセス全体を紹介します。
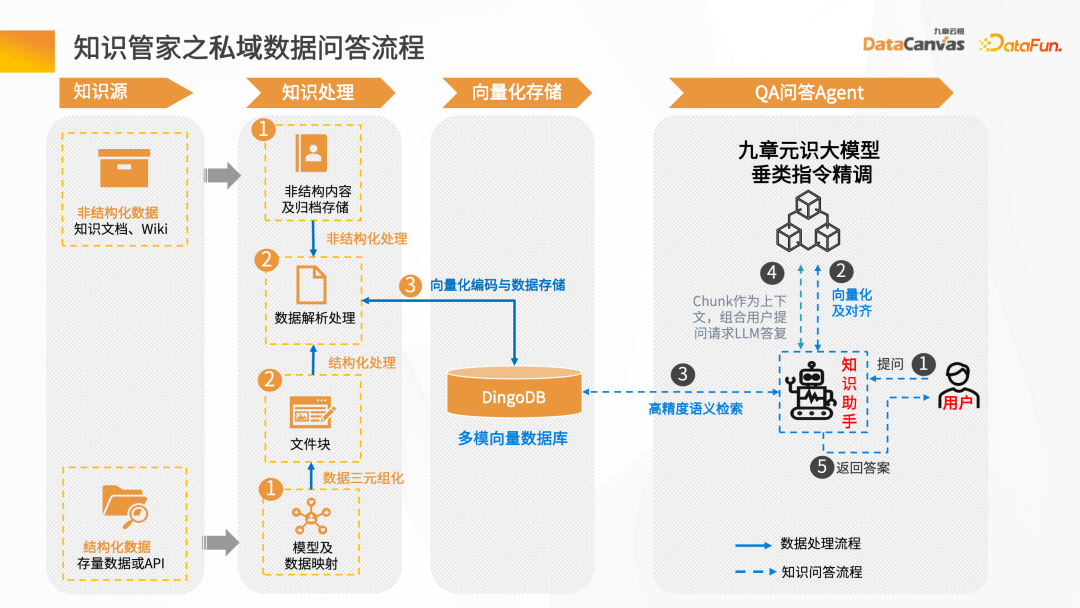
まず第一に、データ ソースが必要です。構造化データと非構造化データが存在する可能性があります。一般的に、ナレッジ ベースの構築は次のとおりです。 Word、PDF、Excelを中心に、エンタープライズシステム、Jira、ナレッジマネジメントプラットフォームなどの非構造化データをベースとしています。
これらのデータは知識処理リンクを通過し、ベクトルに変換されてデータベースに保存されます。まずドキュメントをロードし、次にドキュメントのレイアウト情報または構造情報を指定し、ドキュメント ベクトル解析を実行してファイル ブロックを生成し、ファイル ブロックに基づいて対応する埋め込みモデルを呼び出してベクトルに変換し、ベクトルを保存する必要があります。 。
インテリジェントな質問と回答の対話のプロセス: ユーザーが質問をした後、まずインテリジェント アシスタントを使用して質問をベクトル化し、次にデータベースにアクセスしてセマンティック検索を実行して次の情報を取得します。同様の意味論を持つ記事のコンテキストをプロンプトの単語と組み合わせ、大規模なモデルを通じて推論することで、最終的に答えが返されます。
プロセス全体は、継続的な反復とフィードバックの最適化のプロセスです。この方法でのみ、企業のプライベート ドメイン データに基づいた独占的なインテリジェント エキスパートの役割を獲得できます。
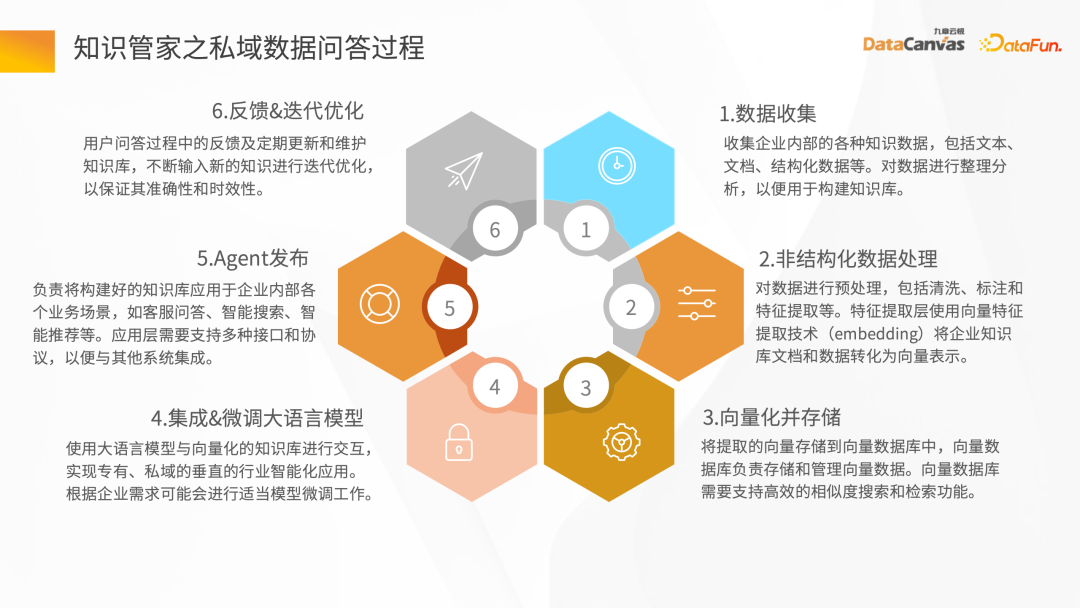
- 非構造化データ処理
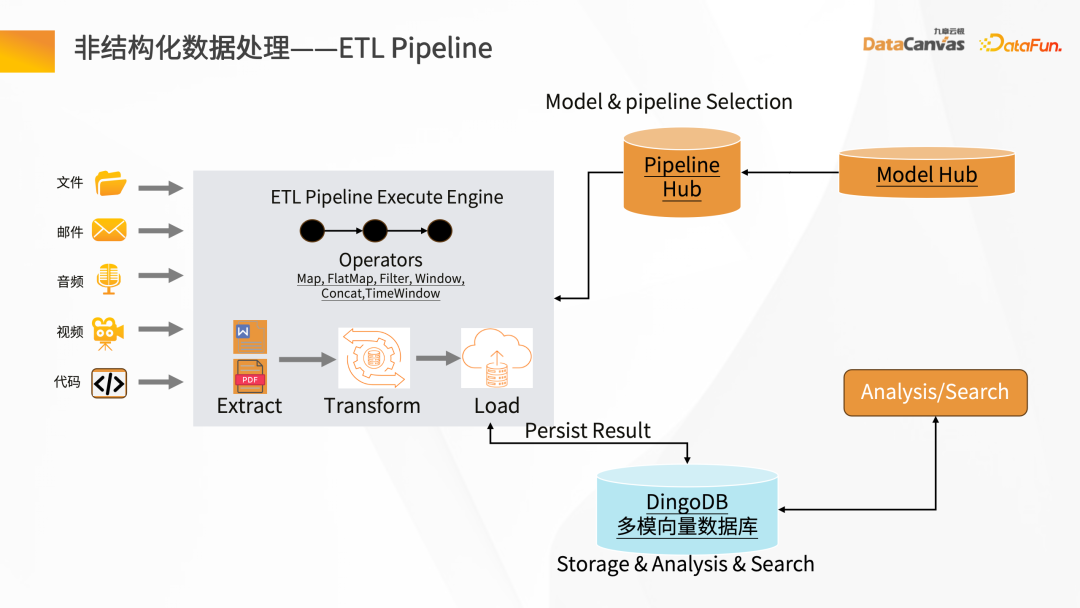
非構造化データ ETL 処理には、いくつかのツールの助けが必要です。 Knowledge Manager は、技術モデルからいくつかの特別な演算子を提供します。これらの演算子は、マップ、フィルター、ウィンドウベースの変更全体をクリーンアップし、ETL パイプライン全体を通じてデータを変換できます。
さまざまなファイル (PDF パーサーなど) を解析し、中間層に対応するさまざまなアプリケーション シナリオのハブ オペレーターを通過することにより、パイプライン ハブを迅速に構築できます。データはクリーンアップおよび変換された後、埋め込まれ、最終的にベクトル データベースに保存されます。
- データの正確性と整合性の保証 - 損失のないデータ解析
良い To を取得するにはモデルのデバッグ効果を向上させるには、正確で完全なデータを確保し、良好なデータ処理品質を確保する必要があります。
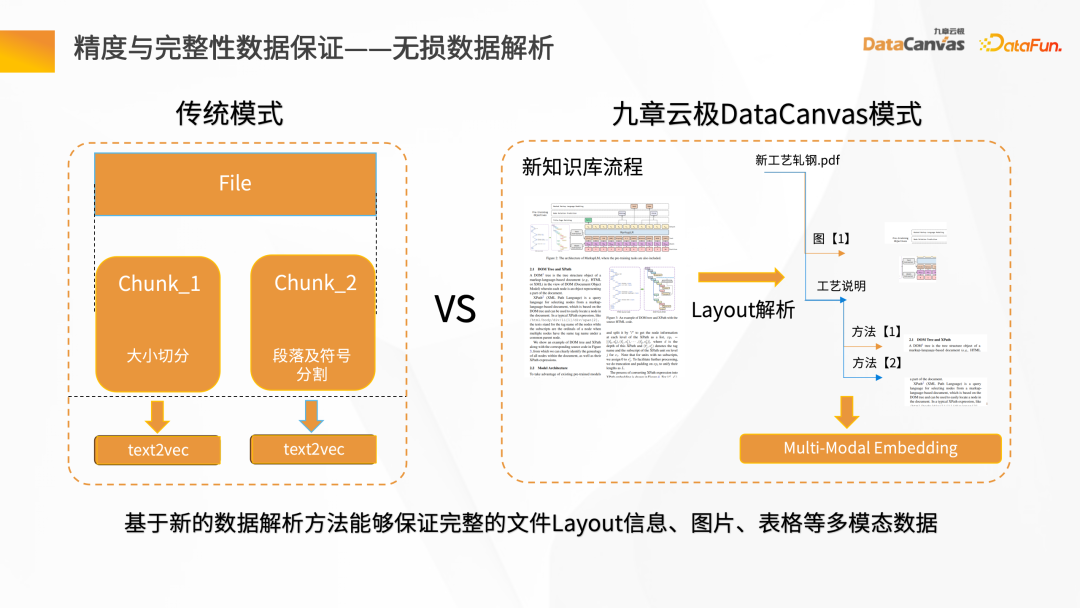
従来のデータ検索の構築は非常に簡単ですが、実際の知識はさらに複雑です。テキスト自体の情報に加えて、次のような情報があります。画像や表データ、段落情報なども含まれます。この点において、Jiuzhang Yunji DataCanvas は、レイアウト情報、テーブル、写真などのマルチモーダル データの完全な保存を実現できるレイアウト解析モードを提供し、データ解析プロセスの品質を包括的に向上させます。
- #強い相関の取得 - 二次フィルタリングの再ランキング
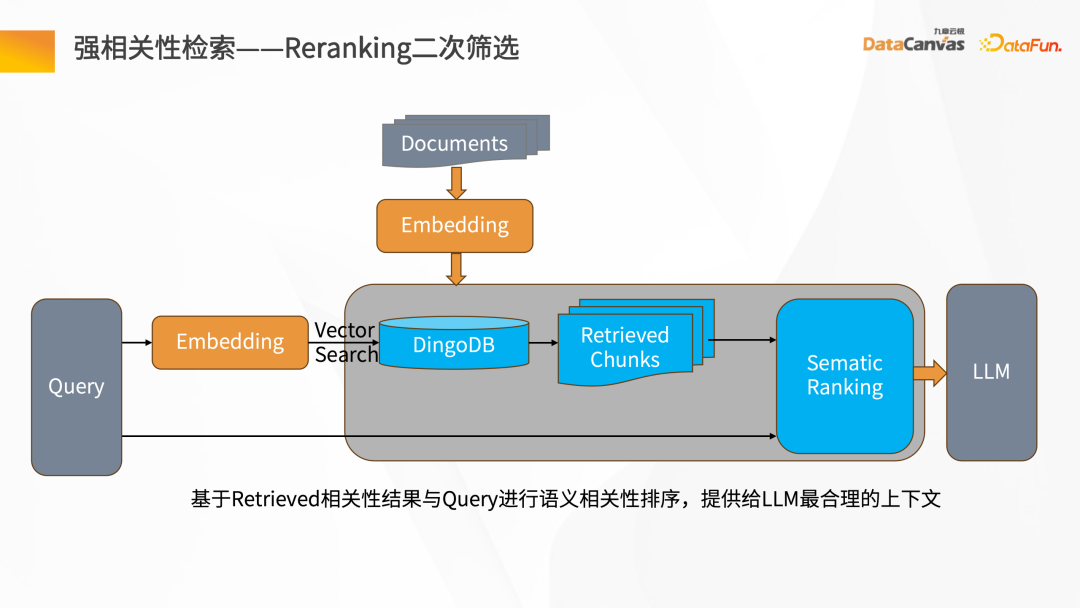
回答生成プロセスのセキュリティと信頼性を確保するために、Jiuzhang Yunji DataCanvas は一般的な大規模音声モデルに基づいており、呼び出されるデータのプロンプト ワードを制限し、企業のプライベートな音声を組み合わせています。大規模モデルによるドメイン データの垂直方向の知識の微調整と風向制御メカニズムの追加により、高い精度の回答生成が保証されます。 DingoDB が提供できる保存機能と取得機能標準化された API は、SQL および Python ツールキットを介したデータ クエリをサポートし、構造化および非構造化結合クエリを実装するための統合された方法も提供します。リアルタイム シナリオの場合、DingoDB はリアルタイムでの書き込みによりリアルタイムでクエリを実行する機能を提供し、データのインポート中にリアルタイムで取得を実行できます。
4. 概要と展望
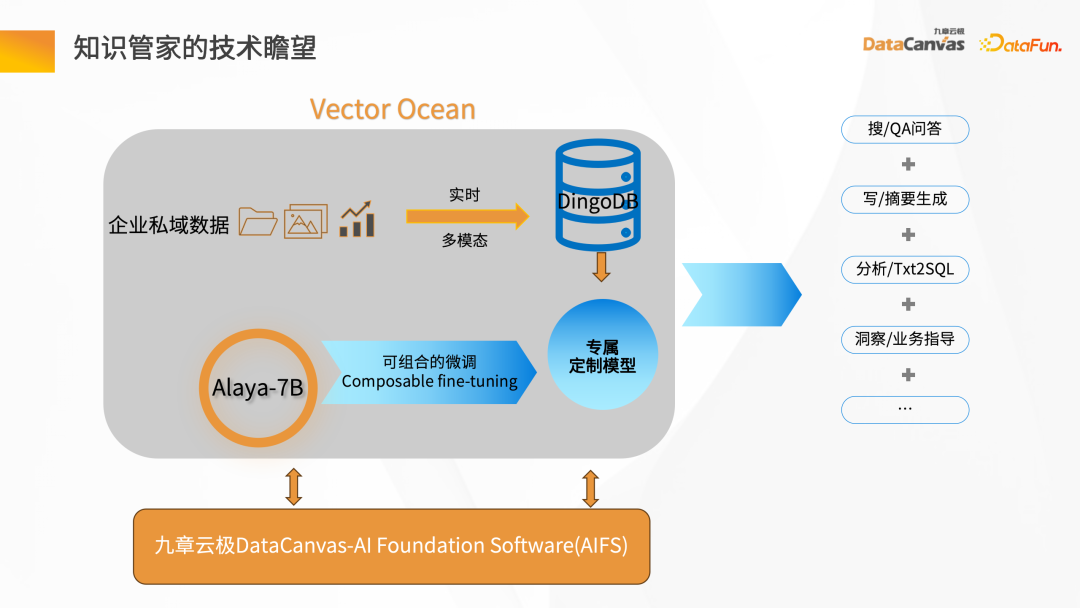
Knowledge Manager は、Jiuzhang Yunji DataCanvas に基づく AIFS で、ベアメタルからそれ以上の GPU コンピューティング能力とモデル スケジューリングの完全なセットを提供し、モデルの微調整を実現します。パイプラインモード。一般的な言語モデルと企業のプライベート ドメイン データを使用して組み合わせと微調整を実行し、企業独自の大規模な言語モデルを形成します。大規模な言語モデルのスケーラビリティに基づいて、DingoDB マルチモーダル ベクトル データベースと組み合わせることで、企業内での検索 Q&A、要約生成、その他のアプリケーションを実現し、企業のナレッジ管理を実行できます。 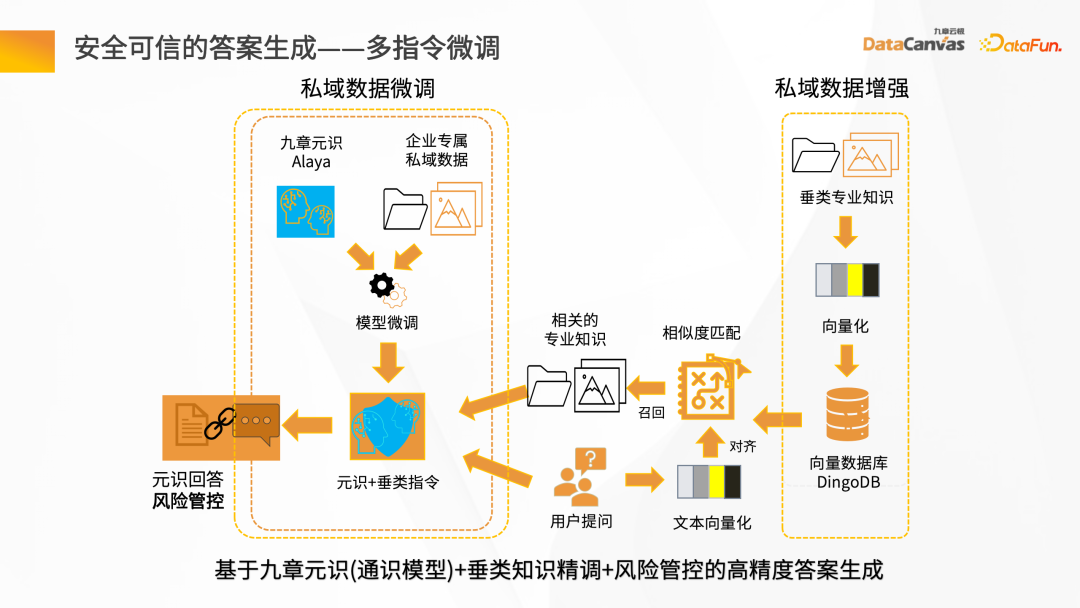
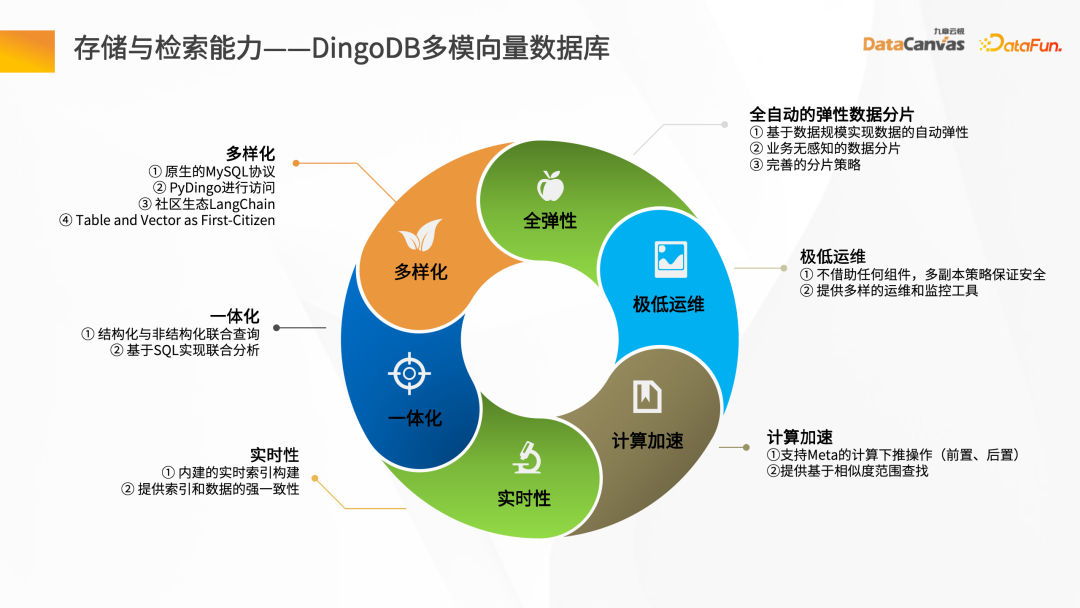
エンタープライズ プライベート ドメイン内データ 一般的なシナリオでは、特定のシナリオで企業専用の大規模な言語モデルを構築するには微調整が必要です。ナレッジ マネージャーは、微調整プロセス全体の問題点を要約し、製品内でツールベースのアプローチを提供します。すべての問題に関するデータは、ドキュメントをアップロードすることで取得できます。データを取得した後、パラメータを設定することでインターフェイス上で直接微調整を実行できると同時に、微調整の結果を評価するためのいくつかの微調整データインジケーターも提供します。 
#大規模モデル アプリケーションを迅速に構築する - 大規模モデル IDE
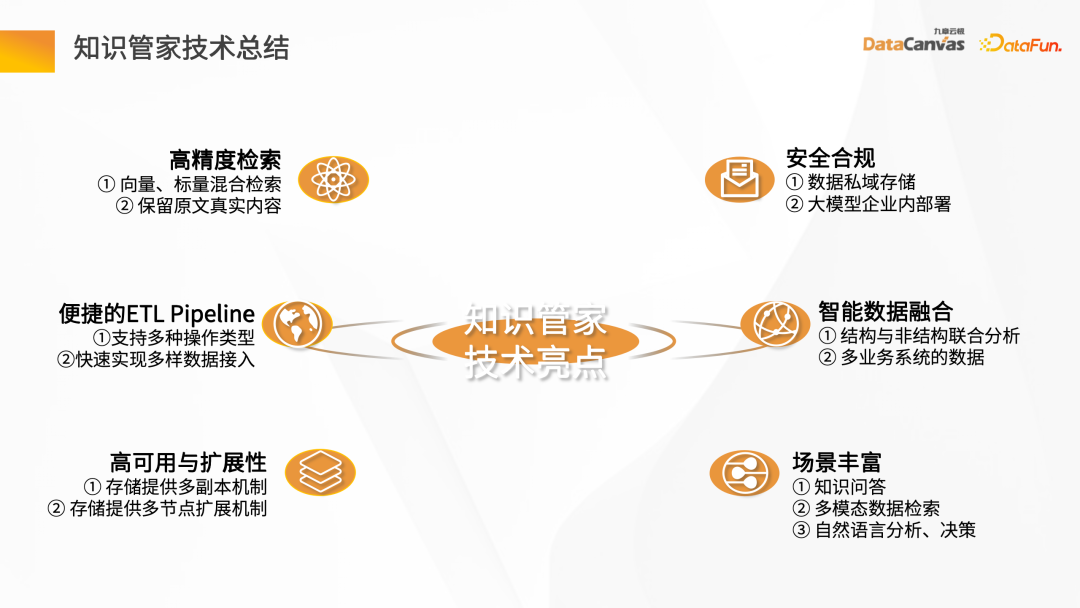
Knowledge Butler の技術的なハイライトには、主に次の 6 つの側面が含まれます: 高精度の取得、便利な ETL パイプライン、高可用性とスケーラビリティ、セキュリティ コンプライアンス、インテリジェントなデータ融合、豊富なシナリオ。
 Knowledge Butler の中核となる価値には、ナレッジ管理の基本機能とインテリジェントなインスピレーションの提供、および安全で信頼できるプライベート アプリケーションの提供が含まれます。導入モードには企業のすべてのデータが含まれており、知識の統合とインテリジェントな対話が可能になります。インテリジェント ベースとして、柔軟な拡張機能を提供し、Knowledge Manager 上の大規模なモデルに基づいて新しいエージェントを開発できます。
Knowledge Butler の中核となる価値には、ナレッジ管理の基本機能とインテリジェントなインスピレーションの提供、および安全で信頼できるプライベート アプリケーションの提供が含まれます。導入モードには企業のすべてのデータが含まれており、知識の統合とインテリジェントな対話が可能になります。インテリジェント ベースとして、柔軟な拡張機能を提供し、Knowledge Manager 上の大規模なモデルに基づいて新しいエージェントを開発できます。 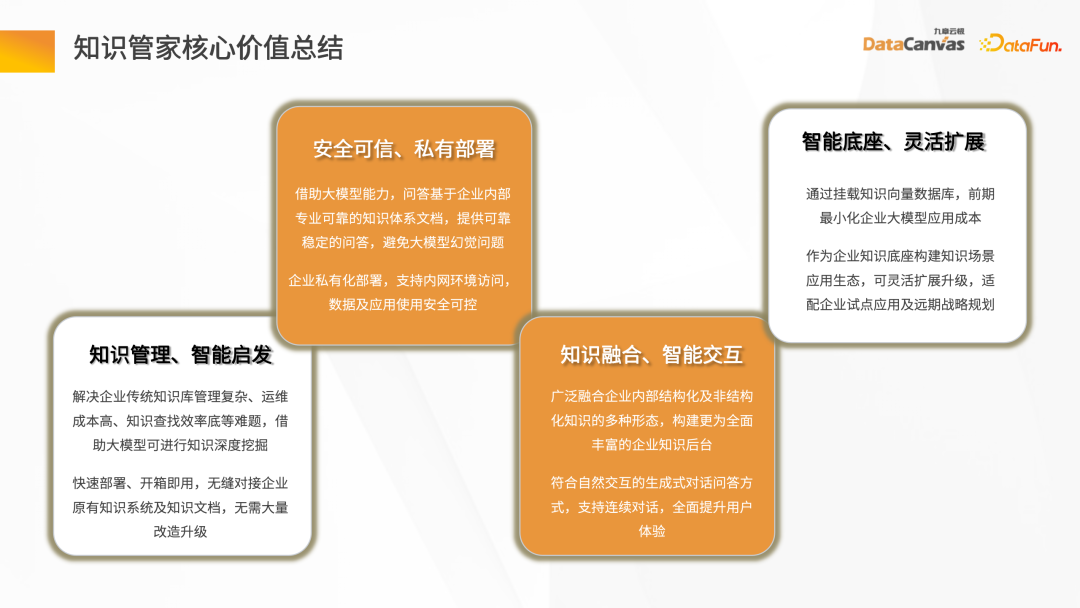
2. 今後の展望
以上が大規模モデル アプリケーションの探索 - Enterprise Knowledge Stewardの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。