###導入###
| インターネットの継続的な発展に伴い、日常生活におけるますます多くのニーズがインターネットを通じて実現されており、衣食住、交通手段から金融教育、ポケットからアイデンティティに至るまで、人々はすべてインターネットに依存しています。人々は自分のニーズを満たすためにインターネットを使用します。
|
顧客からのリクエストに直接対応する Web サーバーとして、同時により多くのリクエストに耐え、ユーザーにより良いエクスペリエンスを提供する必要があることは間違いありません。現時点では、Web側のパフォーマンスが事業展開のボトルネックとなることが多く、パフォーマンスの向上が急務となっています。この記事の著者は、開発プロセス中に Web サーバーのパフォーマンスを向上させたいくつかの経験を要約し、全員と共有しました。
問題分析
Web サーバーのパフォーマンスについては、まず関連する指標を分析します。ユーザーの観点から見ると、ユーザーが Web サービスを呼び出すとき、リクエストが返される時間が短いほど、ユーザー エクスペリエンスは向上します。サーバーの観点から見ると、同時に処理できるユーザー要求の数が多いほど、サーバーのパフォーマンスは向上します。 2 つの側面を組み合わせて、パフォーマンス最適化の 2 つの方向を要約します。
1. サーバーがサポートできる同時リクエストの最大数を増やします;
2. 各リクエストの処理速度を向上させます。
最適化の方向性を明確にする まず、サーバー側に共通のアーキテクチャ パターンを導入します。つまり、ブラウザまたはアプリからの Web リクエストは、サーバー側のいくつかの層の構造を介して処理され、返されます。
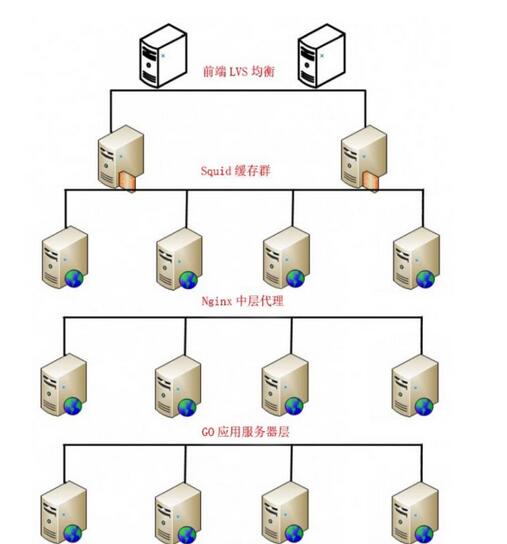
アーキテクチャ モード: IP ロード バランシング -> キャッシュ サーバー -> リバース プロキシ -> アプリケーション サーバー -> データベース
図 1 に示すように、説明の便宜上、LVS(Keepalived)->Squid->nginx->Go->MySQL
という実際的な例を示します。

図 1: サーバー アーキテクチャ
リクエストを各レイヤーに分散することで、下位レベルの構造の複数のブランチが同時に動作して全体の最大同時実行数を増やすことができます。
アーキテクチャと組み合わせて、通常どのような問題がパフォーマンスを妨げているかを分析し、対応する解決策を見つけます。
通常の状況では、主にクラスターの安定性の問題は IP ロード バランシング、キャッシュ サーバー、および nginx プロキシです。パフォーマンスのボトルネックが発生しやすい場所は、多くの場合、アプリケーション サーバー層とデータベース層です。いくつかの例を挙げてみましょう:
1. ブロックの影響
(1) 質問:
ほとんどの Web リクエストは本質的にブロッキングです。リクエストが処理されると、リクエストが完了するまでプロセスは一時停止されます (CPU を占有します)。ほとんどの場合、Web リクエストはすぐに完了するため、この問題は問題になりません。ただし、完了までに時間がかかるリクエスト (大量のデータや外部 API を返すリクエストなど) の場合、処理が終了するまでアプリケーションがロックされ、この間、他のリクエストは処理されなくなります。待機時間が無駄になり、システム リソースが占有され、許容できる同時リクエストの数に深刻な影響を及ぼします。
(2) 解決策:
Web サーバーが前のリクエストの処理を待っている間、処理が完了するまで I/O ループを開いて他のアプリケーション リクエストを処理し、リクエストを待つ代わりにリクエストを開始してフィードバックを与えることができます。プロセスは中断されます。このようにして、不必要な待ち時間を節約し、その時間をより多くのリクエストの処理に使用できるため、リクエストのスループットを大幅に向上させることができます。これは、処理できる同時リクエストの数が巨視的に増加することを意味します。
(3) 例
ここでは、Python Web フレームワークである Tornado を使用して、同時実行パフォーマンスを向上させるためにブロック方法を変更する方法を具体的に説明します。
シナリオ: HTTP リクエストをリモート エンド (非常に安定した Web サイト) に送信する単純な Web アプリケーションを構築します。この期間中、ネットワーク伝送は安定しているため、ネットワークへの影響は考慮されていません。
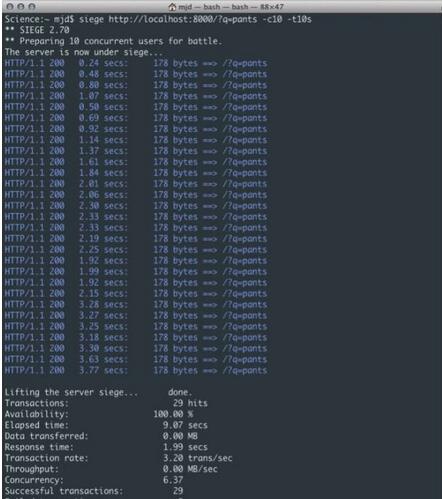
この例では、Siege (ストレス テスト ソフトウェア) を使用して、サーバー上で 10 秒以内に約 10 個の同時リクエストを実行します。
図 2 に示すように、ここでの問題は、各リクエスト自体がどれほど速く返されたとしても、プロセスが待機しないため、サーバーによるリモート アクセス リクエストへのラウンドトリップで十分な遅延が発生することであることが簡単にわかります。リクエストが完了するまで、データは処理されるまで強制中断状態になります。 1 つまたは 2 つのリクエストではまだ問題はありませんが、ユーザーが 100 人 (または 10 人) になると、全体的な速度の低下を意味します。図に示すように、10 秒未満の類似ユーザー 10 人の平均応答時間は 1.99 秒に達し、合計 29 回に達しました。この例では、非常に単純なロジックのみを示しています。他のビジネス ロジックやデータベース呼び出しを追加すると、結果はさらに悪化します。さらに多くのユーザー リクエストが追加されると、同時に処理できるリクエストの数は徐々に増加し、一部のリクエストがタイムアウトになったり失敗したりする場合もあります。
図 2: ブロック応答
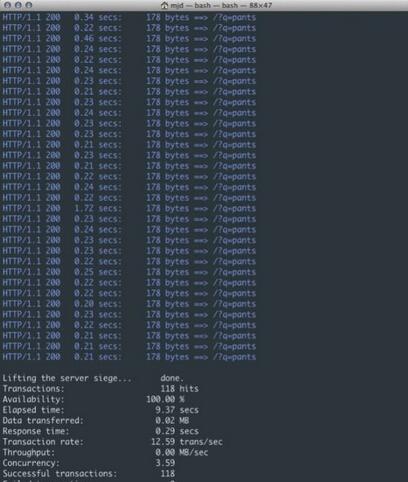
以下では、Tornado を使用してノンブロッキング HTTP リクエストを実行します。
図 3 に示すように、トランザクション数は 1 秒あたり 3.20 から 12.59 に増加し、同じ期間に合計 118 のリクエストに対応しました。これは本当に大きな改善です!ご想像のとおり、ユーザーのリクエストが増加し、テスト時間が増加しても、上記のバージョンで発生した速度低下に悩まされることなく、より多くの接続に対応できるようになります。これにより、ロードできる同時リクエストの数が着実に増加します。
Web サーバーのパフォーマンス向上の実践
図 3: ノンブロッキング応答
2. 応答時間と同時実行数に対するコンピューティング効率の影響
まず基本的な知識を紹介しましょう: アプリケーションはマシン上で実行されるプロセスであり、プロセスは独自のメモリ アドレス空間で実行される独立した実行本体です。プロセスは 1 つ以上のオペレーティング システム スレッドで構成されており、これらのスレッドは実際には連携して動作し、同じメモリ アドレス空間を共有する実行本体です。
(1) 質問
従来のコンピューティング手法はシングル スレッドで実行されるため、効率が低く、コンピューティング能力も弱くなります。
(2) 解決策
解決策の 1 つは、スレッドの使用を完全に避けることです。たとえば、複数のプロセスを使用して、オペレーティング システムへの負担を軽減できます。ただし、欠点は、すべてのプロセス間通信を処理する必要があることであり、通常、共有メモリ同時実行モデルよりもオーバーヘッドが大きくなります。
もう 1 つの方法は、マルチスレッドを使用して機能することです。ただし、マルチスレッドを使用するアプリケーションでは、異なるスレッドを同期し、データをロックして、1 つのスレッドだけが変更できるようにすることは困難であることが認識されています。同時にデータも。しかし、過去のソフトウェア開発の経験から、これによりコードがより複雑になり、エラーが発生しやすくなり、パフォーマンスが低下することがわかっています。
主な問題はメモリ内のデータの共有であり、これは複数のスレッドによって予測不可能な方法で操作され、再現不可能またはランダムな結果 (「競合状態」と呼ばれます) が発生します。したがって、この古典的なアプローチは、現代のマルチコア/マルチプロセッサ プログラミングには明らかに適していません。接続ごとのスレッド モデルは十分に効率的ではありません。多くの適切なパラダイムの中に、Communicating Sequential Processes (CSP、C. Hoare によって発明) と呼ばれるパラダイムと、メッセージ パッシング モデル (Erlang など、他の言語で既に使用されている) と呼ばれるものがあります。
ここで使用する方法は、並列アーキテクチャを使用してタスクを処理することです。同時プログラムは複数のスレッドを使用してプロセッサまたはコア上でタスクを実行できますが、複数のコアまたは特定の時点で同じプログラムのみを実行できます。実際の並列処理は複数のプロセッサ上で可能です。
並列処理は、複数のプロセッサを使用して速度を向上させる機能です。したがって、同時プログラムは並列であってもなくてもかまいません。
パラレル モードでは、マルチスレッド、マルチコア、マルチプロセッサ、さらには複数のコンピュータを同時に使用できます。これにより、間違いなくより多くのリソースが動員され、応答時間が短縮され、コンピューティング効率が向上し、パフォーマンスが大幅に向上します。サーバー。
(3) 例
ここではGo言語のGoroutineを使って具体的に説明します。
Go 言語では、アプリケーションの同時処理部分はゴルーチン (コルーチン) と呼ばれ、より効率的な同時操作を実行できます。コルーチンとオペレーティング システム スレッドの間には 1 対 1 の関係はありません。コルーチンは、可用性に基づいて 1 つ以上のスレッドにマップ (多重化、実行) されます。コルーチン スケジューラ Go ランタイムは、このジョブを非常にうまく実行します。コルーチンは軽量であり、スレッドよりも軽いです。これらは非常に目立ちません (そして少量のメモリとリソースを使用します)。4K のスタック メモリのみを使用してヒープ内に作成できます。作成コストが非常に低いため、必要に応じて多数のコルーチン (同じアドレス空間内の 100,000 個の連続コルーチン) を簡単に作成して実行できます。また、スタックを分割してメモリ使用量を動的に増加 (または削減) します。スタック管理は自動ですが、ガベージ コレクターによって管理されず、コルーチンの終了後に自動的に解放されます。コルーチンは、複数のオペレーティング システム スレッド間またはスレッド内で実行できるため、少ないメモリ フットプリントで多数のタスクを処理できます。オペレーティング システム スレッドでのコルーチン タイム スライスのおかげで、少数のオペレーティング システム スレッドを使用して、必要なだけサービスを提供するコルーチンを持つことができ、Go ランタイムはどのコルーチンがブロックされて保留されているかを賢明に把握し、他のコルーチンを処理できます。コルーチン。プログラムであっても、異なるプロセッサやコンピュータ上で異なるコード セグメントを同時に実行できます。
通常、長い計算プロセスをいくつかの部分に分割し、各 goroutine に 1 つの作業を担当させて、1 つのリクエストに対する応答時間を 2 倍にしたいと考えています。
たとえば、3 つのステージに分かれたタスクがあり、ステージ a はデータベース a に行ってデータを取得し、ステージ b はデータベース b に行ってデータを取得し、ステージ c はデータをマージして返します。ゴルーチンを開始すると、フェーズ a とフェーズ b を同時に実行できるため、応答時間が大幅に短縮されます。
端的に言えば、計算処理の一部をシリアルからパラレルに変換することで、関係のない他のタスクの実行終了を待つ必要がなくなり、実際の計算ではプログラムを並列実行した方が有利になります。
ここでは裏付けデータのこの部分についてはあまり詳しく説明しませんが、興味のある学生は自分でこの情報を確認してください。たとえば、Web サーバーを Ruby から Go に切り替えたところ、パフォーマンスが 15 倍向上したという古い話があります (Ruby はグリーン スレッドを使用します。つまり、CPU が 1 つだけ使用されます)。この話は少し誇張されているかもしれませんが、並列処理によってパフォーマンスが向上することは疑いの余地がありません。 (Ruby から Go への切り替え: http://www.vaikan.com/how-we-went-from-30-servers-to-2-go/)。
3. ディスク I/O のパフォーマンスへの影響
(1) 質問
ディスクのデータ読み取りは機械的な動作に依存します。データの読み取りにかかる時間は、シーク時間、回転遅延、転送時間の 3 つの部分に分けられます。シーク時間とは、指定されたトラックへの磁気アームの移動を指します。主流のディスクに必要な時間は、一般に 5ms 未満です。回転遅延とは、よく聞くディスクの速度です。たとえば、7200 rpm のディスクは、1 分間に 7200 回回転できることを意味します。つまり、1 秒間に 120 回回転できることになります。回転遅延は 1/120/2 = 4.17 ミリ秒です。送信時間は、ディスクからの読み取りまたはディスクへのデータの書き込みにかかる時間を指し、通常は 10 分の数ミリ秒ですが、最初の 2 回の時間と比較すると無視できます。ディスクにアクセスする時間、つまりディスク I/O の時間は約 9 ミリ秒 (5 ミリ秒 4.17 ミリ秒) で、これはかなり良いように思えますが、500 MIPS のマシンは 5 億の命令を実行できることを知っておく必要があります。命令は電気の性質に依存しているため、1 秒あたり 400,000 の命令を実行できます。言い換えると、1 つの I/O を実行するのにかかる時間で 400,000 の命令を実行できます。データベースには、多くの場合、数十万、数百万、さらには数千万のデータが含まれています。 9 ミリ秒かかるたびに、明らかに大惨事になります。
(2) 解決策
ディスクを廃棄して別のものと交換しない限り、ディスク I/O がサーバーのパフォーマンスに及ぼす影響に対する根本的な解決策はありません。さまざまな記憶媒体の応答速度や価格はネットで調べることができるので、お金があれば記憶媒体を自由に変更できます。
記憶媒体を変更せずに、キャッシュの設定など、アプリケーションによるディスク アクセスの数を減らすことができます。また、キューやスタックを使用するなど、一部のディスク I/O をリクエスト サイクルの外に置くこともできます。プロセスデータ、I/Oなど
4. データベース クエリの最適化
ビジネス開発モデルの変化に伴い、アジャイル開発が採用されるチームが増え、そのサイクルはますます短くなっています。多くのデータベース クエリ ステートメントはビジネス ロジックに従って記述されています。時間が経つにつれて、SQL クエリは無視されることが多くなります。フォーマットの問題により、データベースへの負荷が増大し、データベース クエリへの応答が遅くなります。ここでは、MySQL データベースで無視されてきたいくつかの一般的な問題と最適化方法を簡単に紹介します。
左端のプレフィックス マッチングの原則は非常に重要な原則です。MySQL は、a = 1、b = 2、c などの範囲クエリ (>、 3 および d = 4 (a、b、c、d) の順序でインデックスを作成すると、d はそのインデックスを使用しません。(a、b、d、c) でインデックスを作成すると、 a、b、dの順序は任意に調整できます。
区別性の高い列をインデックスとして選択するようにしてください。区別の式は count(distinctcol)/count(*) で、これは繰り返されないフィールドの割合を表します。比率が大きいほど、スキャンするレコードは少なくなります。一意のキーの数は 1 です。一部のステータスおよび性別フィールドは、ビッグ データに直面すると 0 の区別を持つ可能性があります。では、この比率には経験的な価値があるのかと尋ねる人がいるかもしれません。使用シナリオが異なると、この値を決定するのが難しくなります。通常、結合する必要があるフィールドは 0.1 より大きい必要があります。つまり、1 つあたり平均 10 レコードがスキャンされます。
数値フィールドを使用するようにしてください。フィールドに数値情報のみが含まれる場合は、文字フィールドとして設計しないようにしてください。これにより、クエリと接続のパフォーマンスが低下し、ストレージのオーバーヘッドが増加します。これは、エンジンがクエリや接続を処理するときに文字列内の各文字を 1 つずつ比較し、数値型の場合は 1 回の比較だけで十分であるためです。
インデックス列は計算に参加できません。列を「クリーン」に保ってください。たとえば、from_unixtime(create_time) = '2014-05-29' の場合、インデックスは使用できません。理由は非常に簡単です。B ツリーにはすべてのフィールドが格納されます。データテーブルの値を取得しますが、取得する場合は、比較するすべての要素に関数を適用する必要があり、明らかにコストがかかりすぎます。したがって、ステートメントは create_time = unix_timestamp(’2014-05-29’); のように記述する必要があります。where 句でフィールドの null 値を判断しないようにしてください。そうしないと、エンジンがその使用を断念します。
次のようなインデックスを使用してテーブル全体のスキャンを実行します。
select id from t (num は null)
num にデフォルト値 0 を設定し、テーブルの num 列に null 値がないことを確認してから、次のようにクエリを実行できます。
select id from t where num=0
条件をリンクするために where 句で または を使用しないようにしてください。そうしないと、エンジンはインデックスの使用を断念し、次のようなテーブル全体のスキャンを実行します。
num=10 または num=20
の t から ID を選択します
次のようにクエリできます:
select id from t where num=10 Union all select id from t where num=20
次のクエリでも、テーブル全体のスキャンが行われます (先頭にパーセント記号はありません):
'�c%'
のような名前の t から ID を選択します
効率を向上させるには、全文検索を検討してください。
in と not in も注意して使用する必要があります。そうしないと、次のようなテーブル全体のスキャンが発生します。
select id from t where num in(1,2,3)
連続値の場合、 between を使用できる場合は in を使用しないでください:
select id from t where num は 1 ~ 3